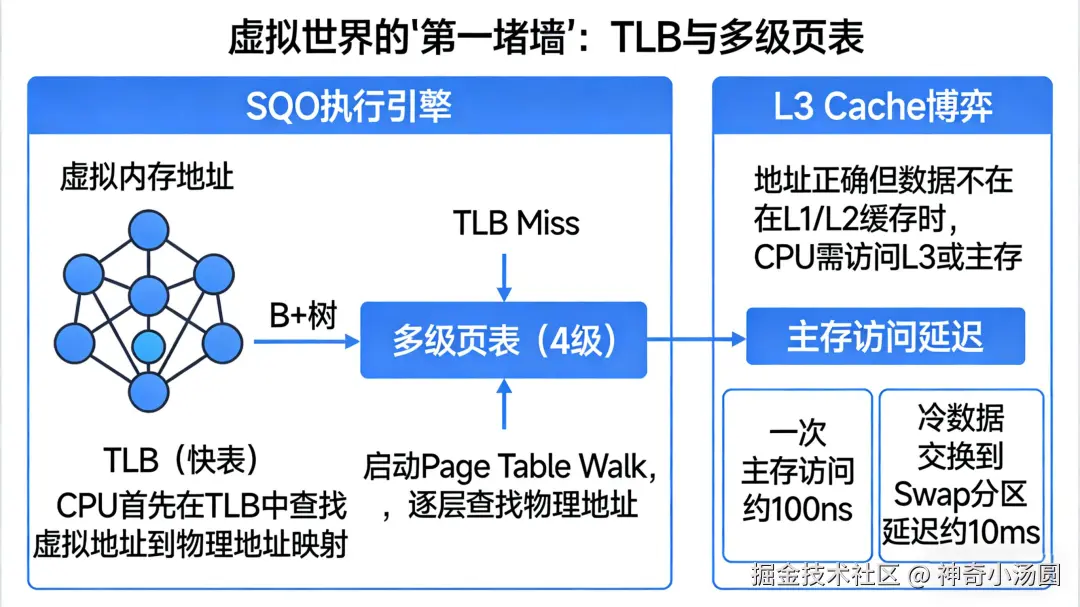
一、 虚拟世界的"第一堵墙":TLB 与多级页表
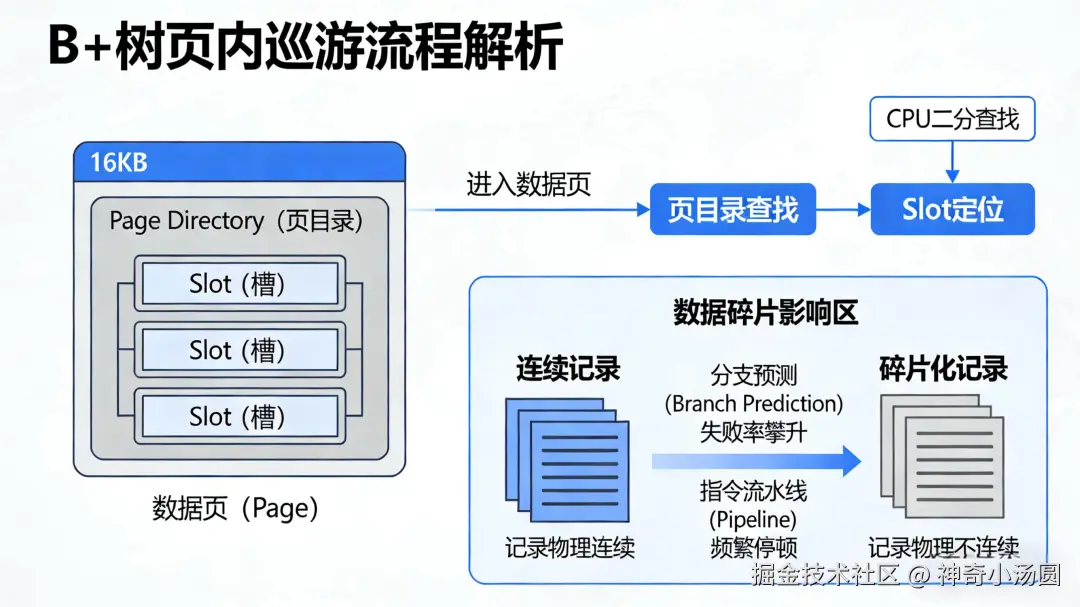
二、 B+ 树页内巡游:Slot 的二分查找
进入 16KB 的数据页(Page)后,并不是直接找到了记录。
Page Directory(页目录):InnoDB 为了加速页内查找,维护了一个 Slot(槽)结构。
指令周期消耗:CPU 在页内进行二分查找。如果 Page 内部的数据由于频繁更新产生了大量的碎片,导致记录在物理存储上不再连续,CPU 的分支预测失败率会攀升,指令流水线(Pipeline)会频繁停顿。
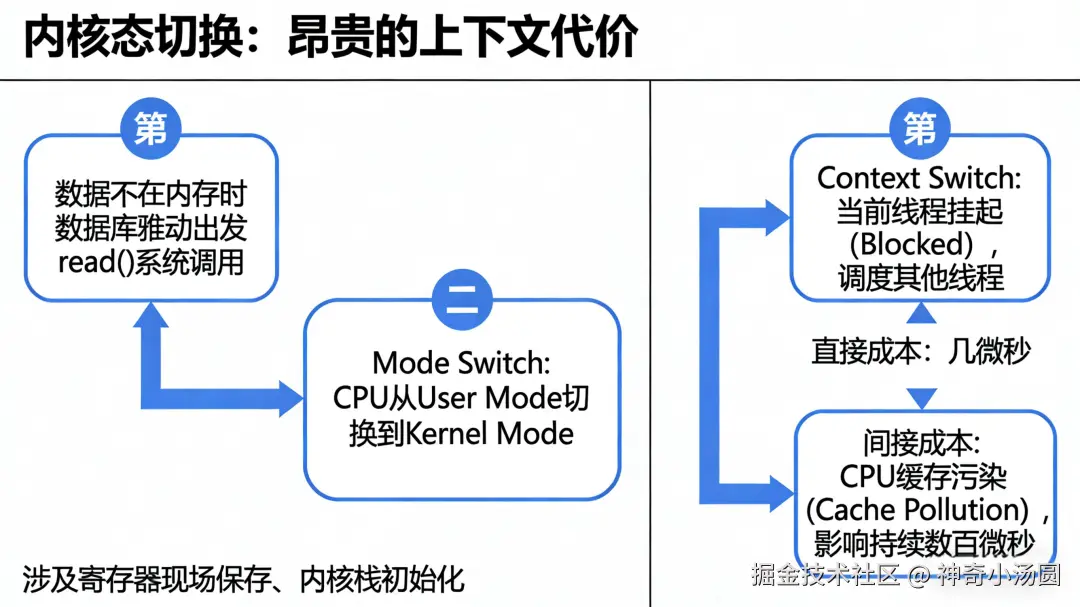
三、 内核态切换:昂贵的上下文代价
如果数据不在内存,数据库进程必须向内核申请 I/O,这时会触发 read() 系统调用。
Mode Switch:CPU 从User Mode(用户态)切换到内核态。这涉及到寄存器现场保存、内核栈初始化。
Context Switch:如果 I/O 无法立即完成,内核会将当前线程挂起,并调度其他线程。一次上下文切换的直接成本在几微秒,但间接成本------导致 CPU 缓存污染的影响可能持续数百微秒。
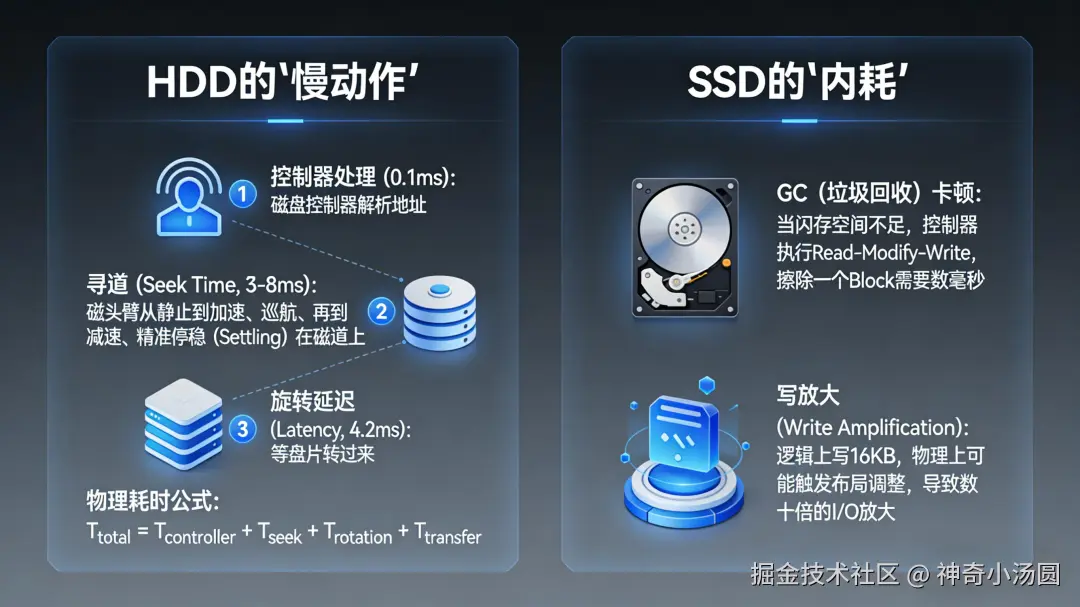
四、 10ms 的重头戏:物理界的"降维打击"
现在,请求通过I/O 调度器(如 Deadline 或 CFQ)来到了硬件层。
1. 机械硬盘(HDD)的"慢动作"
如果你还在用 HDD,那 10ms 几乎全部耗费在磁头的机械惯性上:
寻道 (Seek Time, 3-8ms):磁头臂从静止到加速、巡航、再到减速、精准停稳在磁道上。
旋转延迟 (Latency, 4.2ms):等盘片转过来。
物理耗时公式:

2. 固态硬盘(SSD)的"内耗"
即便是 SSD,10ms 的异常波动通常源于:
GC(垃圾回收)卡顿:当闪存空间不足,控制器执行Read-Modify-Write,擦除一个 Block 需要数毫秒。
写放大:逻辑上写 16KB,物理上可能触发布局调整,导致数十倍的 I/O 放大。
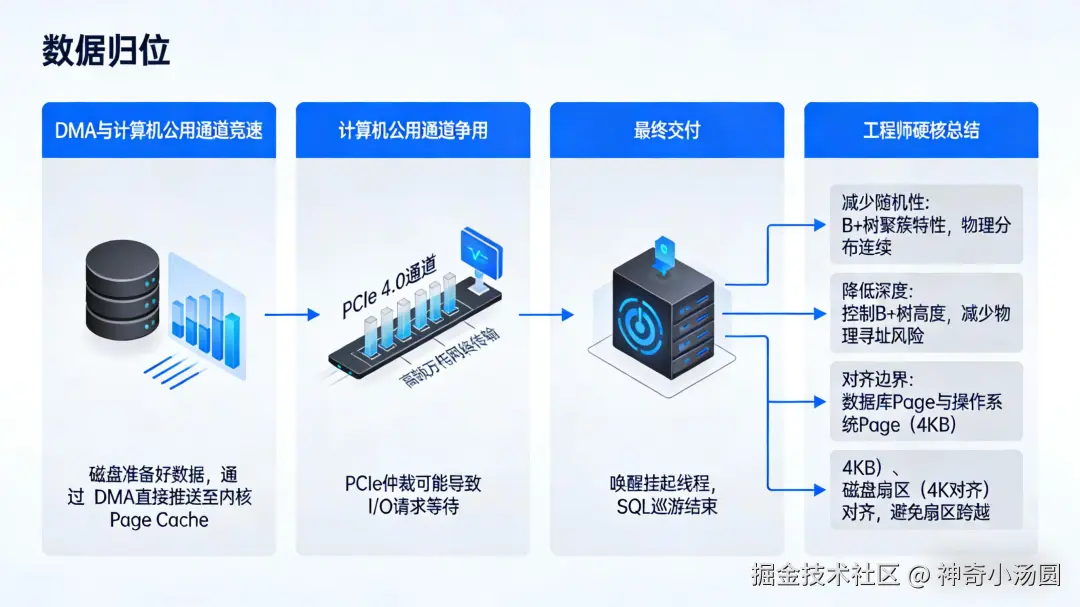
五、 数据归位:DMA 与总线竞速
当磁盘准备好数据,它不会麻烦 CPU 去搬运,而是通过DMA。
DMA 拷贝:磁盘将数据直接推送到内核的Page Cache。
总线争用:在 PCIe 4.0 总线上,数据以每秒数十 GB 的速度狂奔。但如果此时服务器正进行高频万兆网络传输,总线仲裁可能会让 I/O 请求稍作等待。
最终交付:内核将数据从 Page Cache 拷贝到数据库的 Buffer Pool,唤醒挂起的线程,SQL 巡游结束。
总结
一条 SQL 的 10ms 延迟,本质上是电子速度(CPU/内存)与机械速度或硅片物理极限之间的结构性矛盾。
作为高级工程师,我们要做的不仅是加索引,而是要:
- 减少随机性:利用 B+ 树的聚簇特性,让物理分布尽量连续,减少磁头跳跃。
- 降低深度:控制 B+ 树高度,每一层增加,都意味着多一次物理寻址的风险。
- 对齐边界:让数据库 Page 与操作系统 Page(通常 4KB)、甚至磁盘扇区(4K 对齐)对齐,避免扇区跨越导致的额外 I/O。