目录
- 前言
- 一、分治
-
- [1.1 逆序对](#1.1 逆序对)
- [1.2 求第 k 小的数](#1.2 求第 k 小的数)
- [1.3 最大子段和](#1.3 最大子段和)
- [1.4 地毯填补问题](#1.4 地毯填补问题)
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、分治
1.1 逆序对
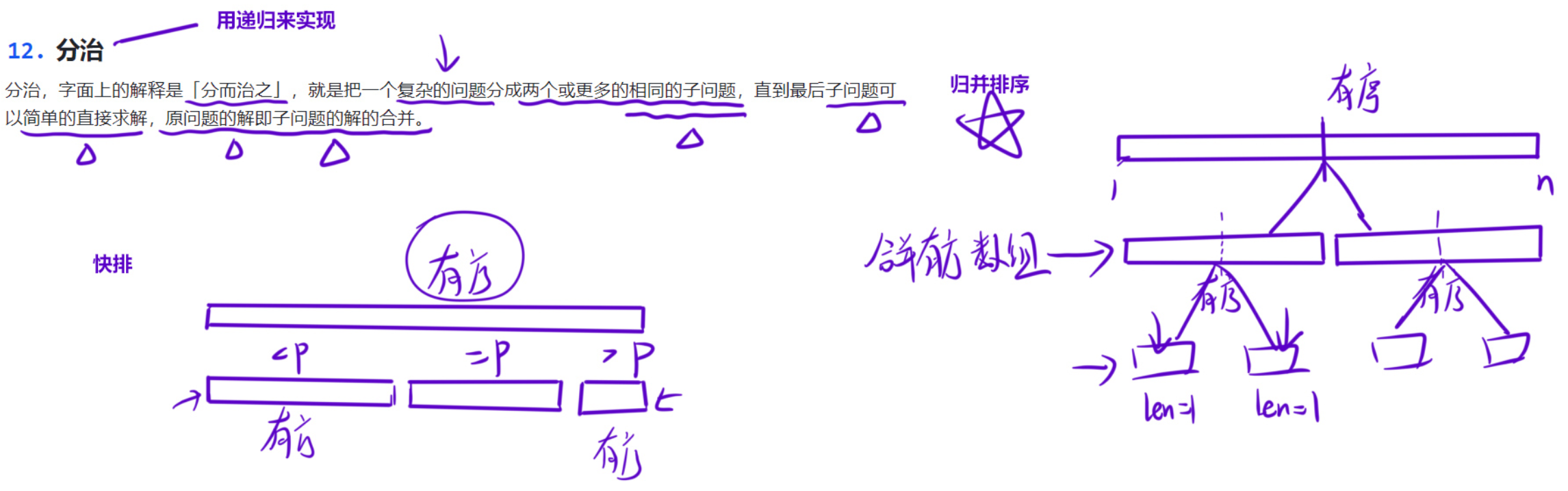
分治,字面上的解释是「分而治之」,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
【解法】
「分治」是解决「逆序对」非常经典的解法,后续主播也会出文章利用「树状数组」或「线段树」解决逆序对问题。
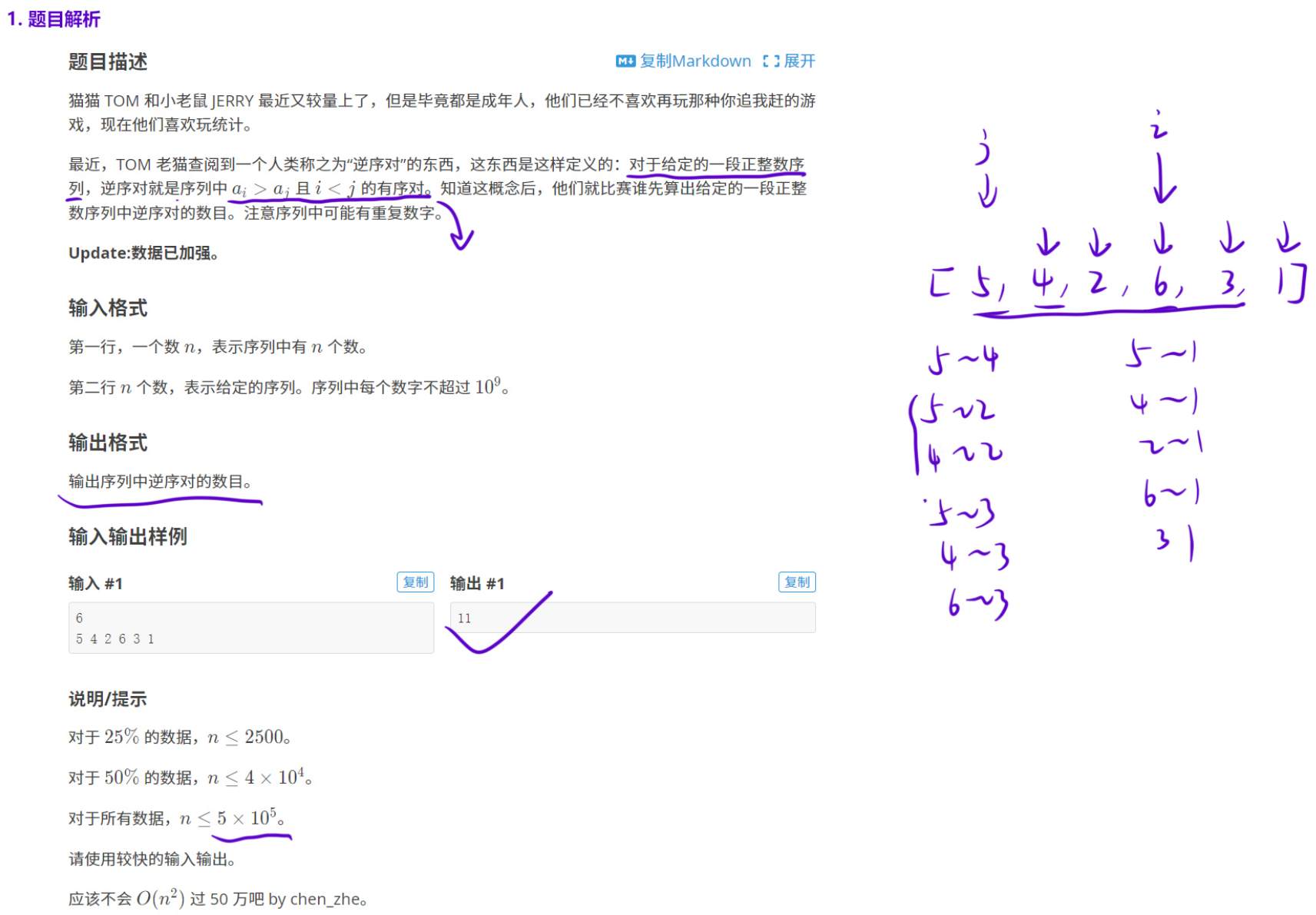
如果把整个序列 l,r 从中间 mid 位置分成两部分,那么逆序对个数可以分成三部分:
- l,mid 区间内逆序对的个数 c1;
- mid+1,r 区间内逆序对的个数 c2;
- 从 l,mid 以及 mid+1,r 各选一个数,能组成的逆序对的个数 c3
那么逆序对的总数就是 c1+c2+c3。其中求解 c1,c2 的时候跟原问题是一样的,可以交给「递归」去处理,那我们重点处理「一左一右」的情况。
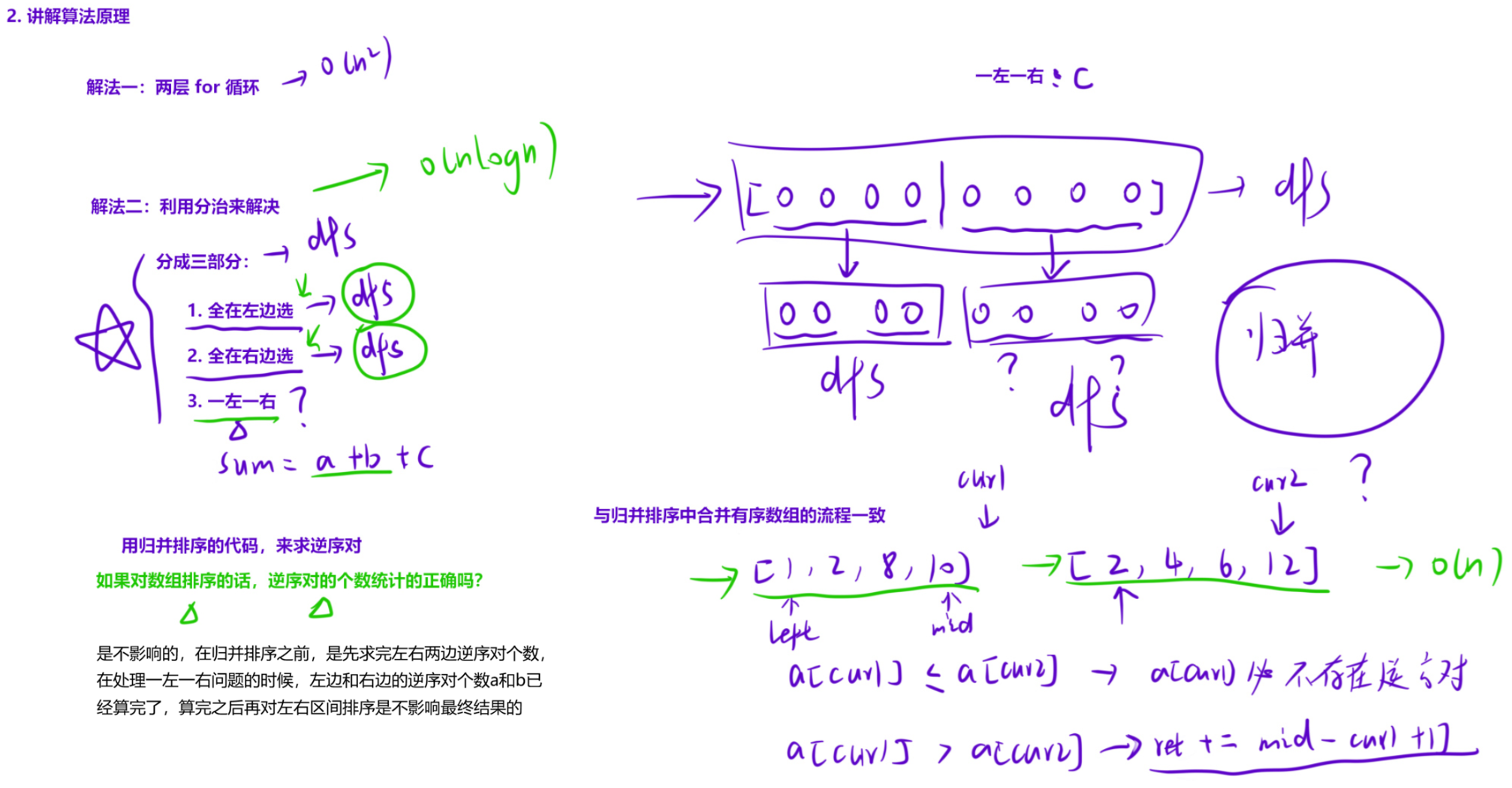
如果在处理一左一右的情况时,两个数组「无序」,找逆序对的时候只能两层for循环,因为数组无序,右边序列固定一个数,在左边序列找比其大的数需要从前往后遍历,我们的时间复杂度其实并没有优化到哪去,每分一层需要在两个序列来两个for循环,整体时间复杂度为n^2logn,因为分治的整个过程其实是和归并是一样的,一共可以分logn层,每一层都是一个n2级别的时间复杂度,甚至还「不如暴力解法」。但是如果两个数组有序的话,我们就可以快速找出逆序对的个数。
先不管怎么求逆序对,我们能让左右两个数组有序嘛?当然可以,这不就是「归并排序」么。因此,我们能做到在求完 c1,c2 之后,然后让「左右两个区间有序」。
那么接下来问题就变成,已知两个「有序数组」,如何求出左边选一个数,右边选一个数的情况下的逆序对的个数。核心思想就是找到右边选一个数之后,左边区间内「有多少个比我大的」。
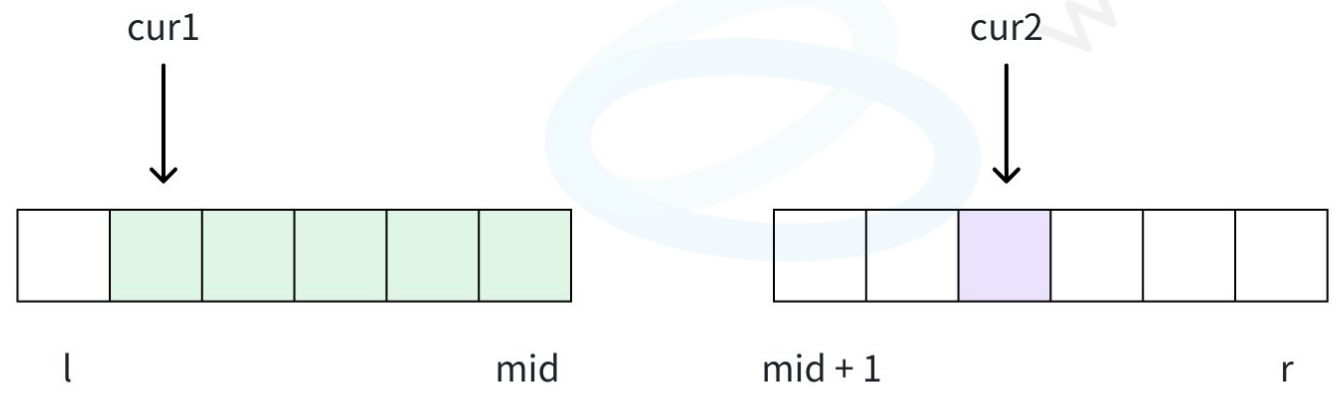
定义两个「指针」扫描两个有序数组:此时会有下面三种情况:
- acur1≤acur2:acur1 不会与 cur2,r 区间内任何一个元素构成逆序对,cur1++;
- acur1>acur2:此时 cur1,mid 区间内所有元素都会与 acur2 构成逆序对,逆序对个数增加 mid−cur1+1,此时 cur2 已经统计过逆序对了,cur2++;
重复上面两步,我们就可以在 O(N) 的时间内处理完「一左一右」时,逆序对的个数。而且,我们会发现,这跟我们「归并排序的过程」是高度一致的。所以可以一边排序,一边计算逆序对的个数。
cpp
#include<iostream>
using namespace std;
const int N = 5e5 + 10;
typedef long long LL;
LL n;
LL a[N];
//辅助数组,帮助合并有序数组
LL tmp[N];
//求对应区间的逆序对个数+归并排序
LL merge(LL left, LL right)
{
//区间不存在或只有一个元素
if(left >= right) return 0;
//标记逆序对个数
LL ret = 0;
LL mid = (left + right) / 2;
ret += merge(left, mid);
ret += merge(mid + 1, right);
//一左一右的情况,在合并有序数组的过程中完成
LL cur1 = left, cur2 = mid + 1, i = left;
while(cur1 <= mid && cur2 <= right)
{
if(a[cur1] <= a[cur2]) tmp[i++] = a[cur1++];
else{
ret += mid - cur1 + 1;
tmp[i++] = a[cur2++];
}
}
//cout << "1" << endl;
//在上面的循环跳出的时候,左右两个区间必有一个是合并完成的
//所以下面两个循环只会进入一个
while(cur1 <= mid) tmp[i++] = a[cur1++];
while(cur2 <= right) tmp[i++] = a[cur2++];
//cout << "1" << endl;
//将辅助数组中的内容拷贝到原始数组当中
for(int j = left; j <= right; j++) a[j] = tmp[j];
return ret;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
//1~n区间之间的逆序对个数
cout << merge(1, n) << endl;
return 0;
}这里再分享一个调试技巧,主播今天和一个程序员学的哈哈,如果程序死循环了,可以在代码的循环结束部分随便打印一个数据,比如说cout << "1" << endl;如果在该位置打印不出结果,则说明上面的代码没有问题,反之

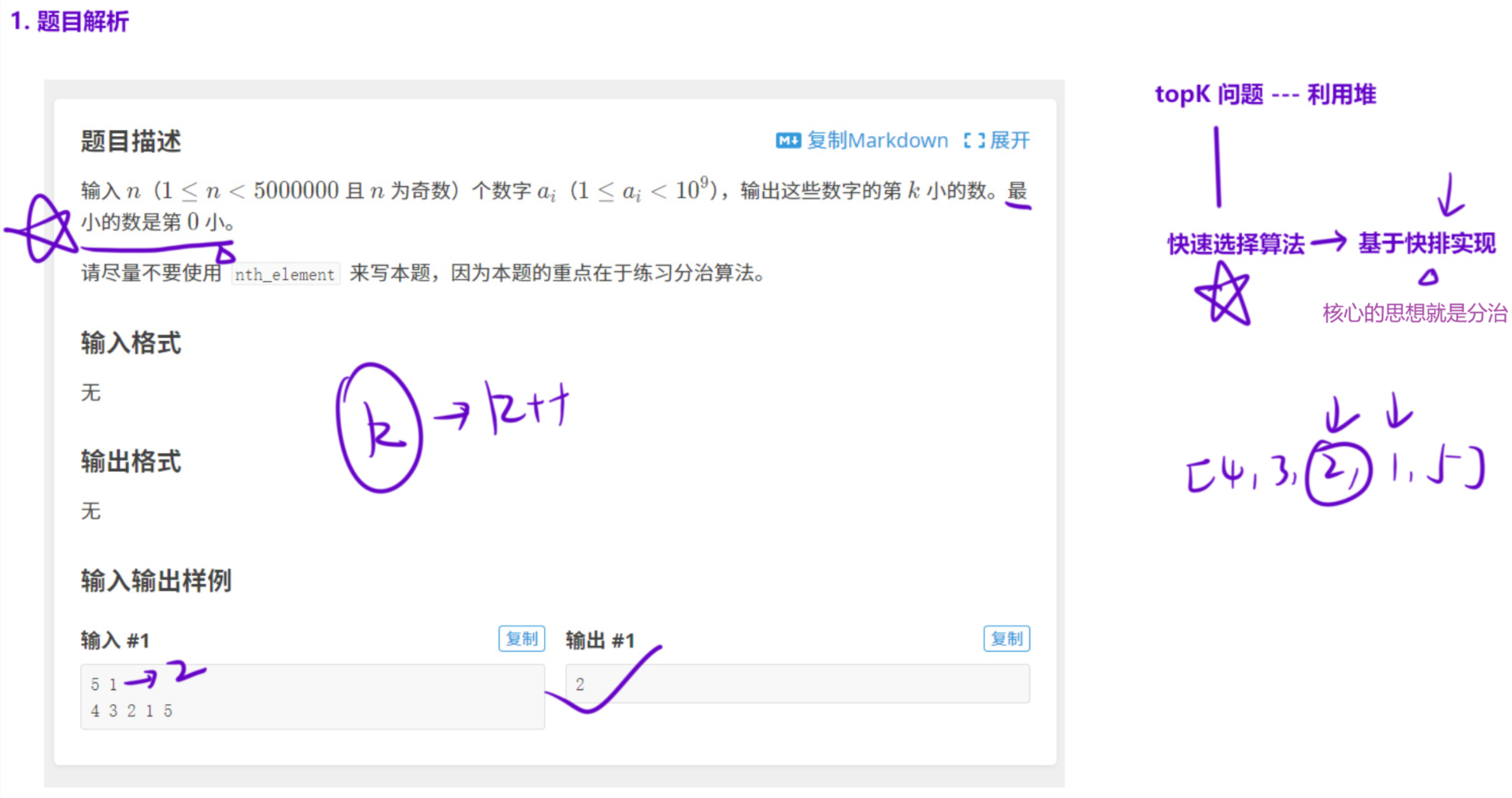
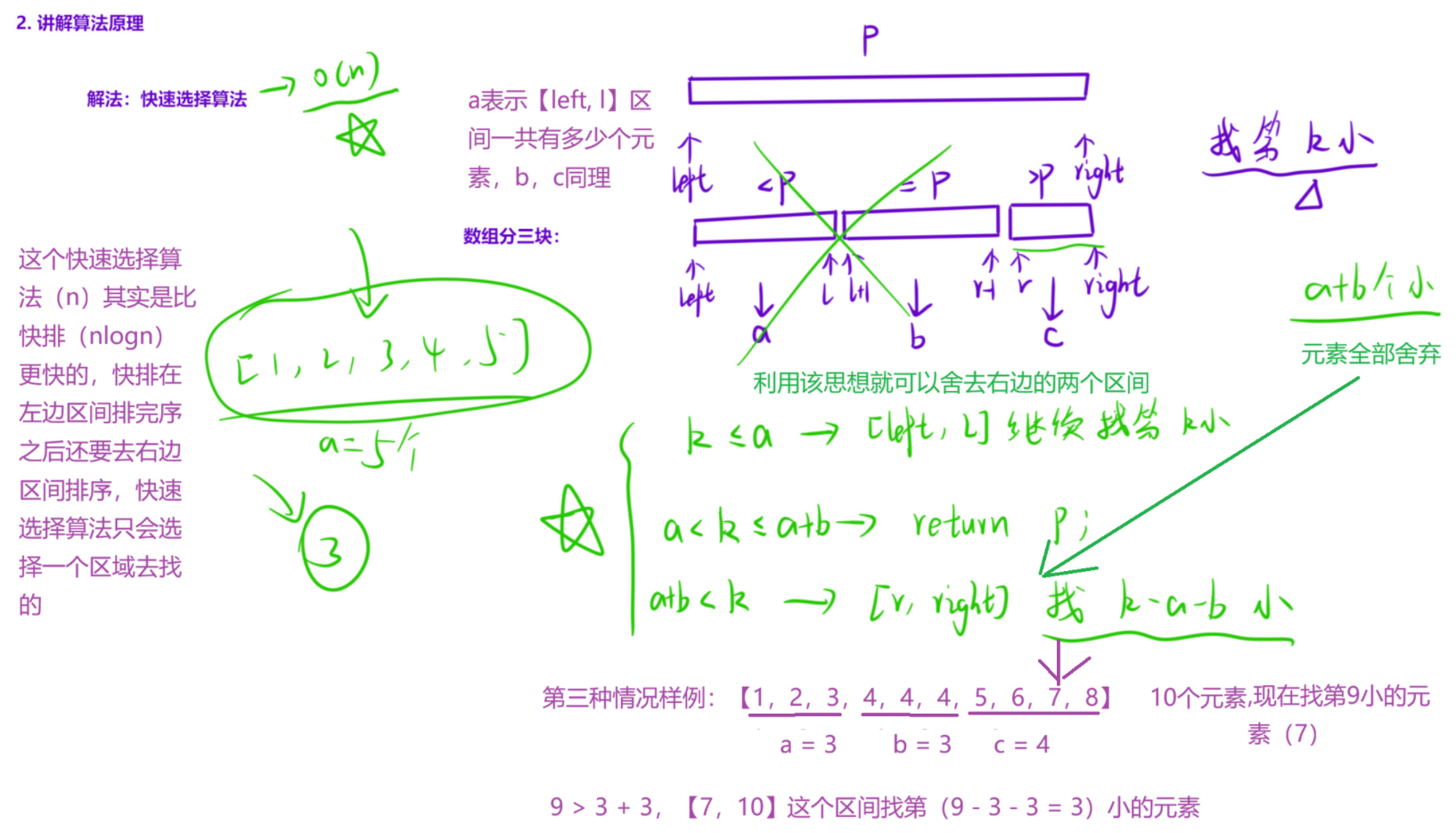
1.2 求第 k 小的数
cpp
#include<iostream>
#include<ctime>
using namespace std;
const int N = 5e6 + 10;
typedef long long LL;
LL a[N];
LL n, k;
//区间内选择基准元素
LL get_random(LL left, LL right)
{
return a[rand() % (right - left + 1) + left];
}
LL quick_select(LL left, LL right, LL k)
{
//如果当前区间只有一个元素,第k小必定是当前元素
if(left >= right) return a[left];
//只有当数组分完三块之后,最后部分才是快速选择算法
//前面还是快排的思路
//选择基准元素
LL p = get_random(left, right);
//数组分三块,三路快排
LL l = left - 1, i = left, r = right + 1;
while(i < r)
{
if(a[i] < p) swap(a[++l], a[i++]);
else if(a[i] == p) i++;
else swap(a[--r], a[i]);
}
//选择存在最终结果的区间
//[left, l] [l + 1, r - 1] [r, right]
LL a = l - left + 1, b = r - 1 - (l + 1) + 1, c = right - r + 1;
if(k <= a) return quick_select(left, l, k);
//不用写k > a了,上面if条件不成立k > a天然成立
else if(k <= a + b) return p;
else return quick_select(r, right, k - a - b);
}
int main()
{
//随机选择基准元素,种随机数种子
srand(time(0));
//cin >> n >> k;
scanf("%lld%lld", &n, &k);
//和常识对标,题目最小的数是最0小
k++;
for(int i = 1; i <= n; i++) //cin >> a[i];
{
scanf("%lld", &a[i]);
}
//cout << quick_select(1, n, k) << endl;
printf("%lld\n", quick_select(1, n, k));
return 0;
}接下来详细解析一下代码,这道题目我个人感觉还是有些难度的,其中还用到了三路快排的这种算法,不了解这个算法的详细见我这篇文章从三路快排到内省排序:探索工业级排序算法的演进
一、main函数:输入处理与参数转换
cpp
srand(time(0)); // 初始化随机数种子,用于后续随机选基准
scanf("%d%d", &n, &k); // 读入n(元素个数)和k(题目定义:第0小是最小值)
k++; // 关键转换:题目k是0-based → 算法里用1-based
for(int i = 1; i <= n; i++) // 读入n个元素到数组a(下标从1开始,1-based)
{
scanf("%d", &a[i]);
}
printf("%d\n", quick_select(1, n, k)); // 调用快速选择,输出结果为什么 k++?
题目规定「最小的数是第 0 小」(0-based),而quick_select函数是按1-based设计的(第 1 小 = 最小值,第 2 小 = 次小值...),所以需要把输入的 k 加 1,转换成算法能识别的 1-based 索引。
二、核心函数:quick_select(分治找第 k 小)
cpp
int quick_select(int left, int right, int k)
{
if(left >= right) return a[left]; // 递归终止:区间只剩一个元素,直接返回
// 1. 随机选择基准元素p
int p = get_random(left, right);
// 2. 三向切分:把数组分成 <p、=p、>p 三块
int l = left - 1, i = left, r = right + 1;
while(i < r)
{
if(a[i] < p) swap(a[++l], a[i++]); // 小于p → 移到左边
else if(a[i] == p) i++; // 等于p → 留在中间
else swap(a[--r], a[i]); // 大于p → 移到右边
}
// 3. 计算三块的大小
int a_size = l - left + 1; // 小于p的元素个数
int b_size = r - 1 - l; // 等于p的元素个数
int c_size = right - r + 1; // 大于p的元素个数
// 4. 根据k的位置,选择递归区间或直接返回
if(k <= a_size) return quick_select(left, l, k); // k在「小于p」区
else if(k <= a_size + b_size) return p; // k在「等于p」区
else return quick_select(r, right, k - a_size - b_size); // k在「大于p」区
}1. 随机选择基准:get_random
cpp
int get_random(int left, int right)
{
return a[rand() % (right - left + 1) + left];
}作用:在left, right区间内随机选一个元素作为基准p,避免了「数组已有序」时的最坏情况(O (n²)),保证期望时间复杂度 O (n)。
原理:rand() % (right-left+1)生成0, right-left的随机数,加上left后得到left, right的随机下标。
3. 三向切分(荷兰国旗问题)
这一步是把数组分成小于 p、等于 p、大于 p三个连续区域:
- l:指向「小于 p」区域的最右边界(初始在区间左边界外left-1)
- i:遍历指针,从left开始扫描
- r:指向「大于 p」区域的最左边界(初始在区间右边界外right+1)
循环逻辑:
- ai < p:把这个元素交换到「小于 p」区(l右移后交换),i继续右移
- ai == p:元素属于中间区,直接i右移
- ai > p:把这个元素交换到「大于 p」区(r左移后交换),i不动(因为交换来的新元素还没处理)
循环结束后,数组被划分为:
- 小于 p:left, l
- 等于 p:l+1, r-1
- 大于 p:r, right
4. 分治选择区间
根据 k 落在哪个区域,决定下一步递归方向:
- k ≤ 小于 p 的元素个数:第 k 小在「小于 p」区,递归处理left, l,k 不变
- k ≤ 小于 p + 等于 p 的元素个数:第 k 小在「等于 p」区,直接返回基准p(这部分所有元素都等于 p)
- 否则:第 k 小在「大于 p」区,递归处理r, right,k 需要减去前两部分的数量(k - a_size - b_size)
三、样例走一遍
假设现在找第2小的数
第二步:进入 quick_select (1, 5, 2)
cpp
int quick_select(int left=1, int right=5, int k=2)
{
// 1. 递归终止条件:left >= right?1 >=5?不成立,继续
if(left >= right) return a[left];
// 2. 随机选基准值 p
// 区间[1,5]随机选一个元素,我们假设选中 a[3]=2
int p = 2;
// 3. 初始化三向切分指针(核心!)
int l = left - 1 = 0; // 小于p区域的右边界(初始在区间外)
int i = left = 1; // 遍历指针(从左到右扫)
int r = right + 1 = 6; // 大于p区域的左边界(初始在区间外)
// 4. 核心循环:三向切分,把数组分成 <2、=2、>2
while(i < r)
{第三步:三向切分 逐次循环(关键)
当前数组: 4, 3, 2, 1, 5 指针:l=0,i=1,r=6 基准:p=2
第 1 次循环:i=1,a i=4
cpp
if(a[i] < p) → 4 < 2?不成立
else if(a[i]==p) →4==2?不成立
else → 执行 swap(a[--r], a[i])第 2 次循环:i=1,a i=5
cpp
a[i]=5 > 2 → 执行 swap(a[--r], a[i])r=4
交换 a4 和 a1
数组变为:1, 3, 2, 5, 4
指针:l=0,i=1,r=4
第 3 次循环:i=1,a i=1
cpp
a[i]=1 < 2 → 执行 swap(a[++l], a[i++])l=1,交换 a1 和 a1(无变化)
i 加 1 → i=2
数组:1, 3, 2, 5, 4
指针:l=1,i=2,r=4
第 4 次循环:i=2,a i=3
cpp
a[i]=3 > 2 → 执行 swap(a[--r], a[i])r=3
交换 a3 和 a2
数组变为:1, 2, 3, 5, 4
指针:l=1,i=2,r=3
第 5 次循环:i=2,a i=2
cpp
a[i]==p → 直接 i++i=3
指针:l=1,i=3,r=3
循环结束!
因为 i=3 不小于 r=3,退出循环 ✔️
第四步:划分最终区间(循环结束后的结果)
数组最终:1, 2, 3, 5, 4
三个区域严格划分:
- 小于 p (2):left, l = 1, 1 → 元素:1
- 等于 p (2):l+1, r-1 = 2, 2 → 元素:2
- 大于 p (2):r, right = 3,5 → 元素:3,5,4
第五步:计算区间大小,判断 k 的位置
cpp
// 计算三个区域的元素个数
int a_size = l - left + 1 = 1 - 1 +1 = 1 (小于2的有1个)
int b_size = r-1 - l = 2-1-1 =1 (等于2的有1个)
int c_size = right - r +1=5-3+1=3 (大于2的有3个)
// 判断k=2
if(k <= a_size) → 2<=1?不成立
else if(k <= a_size + b_size) → 2 <= 1+1=2 → 成立!
return p;第六步:返回结果,程序结束
直接返回基准值 2
四、代码优化与注意点
- 输入输出效率:用scanf/printf而非cin/cout,因为 n 最大到 5×10⁶,C++ 标准输入输出流如果不关闭同步会很慢,这道题使用cin,cout就会超时。
- 随机化种子:srand(time(0))必须在main里调用一次,否则rand()会生成相同序列。
三路划分后,右边区间内部是乱的,为什么敢直接递归进去找第 k 小?不会找错吗?
我们找第 k 小,只需要知道:第 k 小的数,属于「最小的一批」「中间的一批」还是「最大的一批」 ,不需要知道它在区间里的具体位置
举个例子:假设我们要找 第 4 小(k=4)
左区间有 1 个元素(最小的 1 个数)
中区间有 1 个元素(次小的 1 个数)
前两个区间加起来一共 2 个数
k=4 > 2 → 说明第 4 小的数,一定在右区间里(最大的那一批数)。
👉 右区间里全是比前两个区间大的数,所以 ** 只需要在右区间里找「第 4-2=2 小」** 就行,哪怕右区间是乱的,递归进去后,会再次做三路划分,继续缩小范围,最终一定能找到正确值。
模拟:k=4(找第 4 小),递归右区间
原数组:1,2,3,5,4
右区间:3,5,4(下标 3~5)
k=4,前两个区间共 2 个元素 → 新 k=4-2=2
- 进入递归:quick_select(3,5,2)
- 随机选基准,比如p=4
三路划分右区间3,5,4:
左区间3(<4)
中区间4(=4)
右区间5(>4) - 新 k=2:落在中区间,直接返回4
✅ 正确!数组排序后1,2,3,4,5,第 4 小就是 4。
1.3 最大子段和
最大子段和
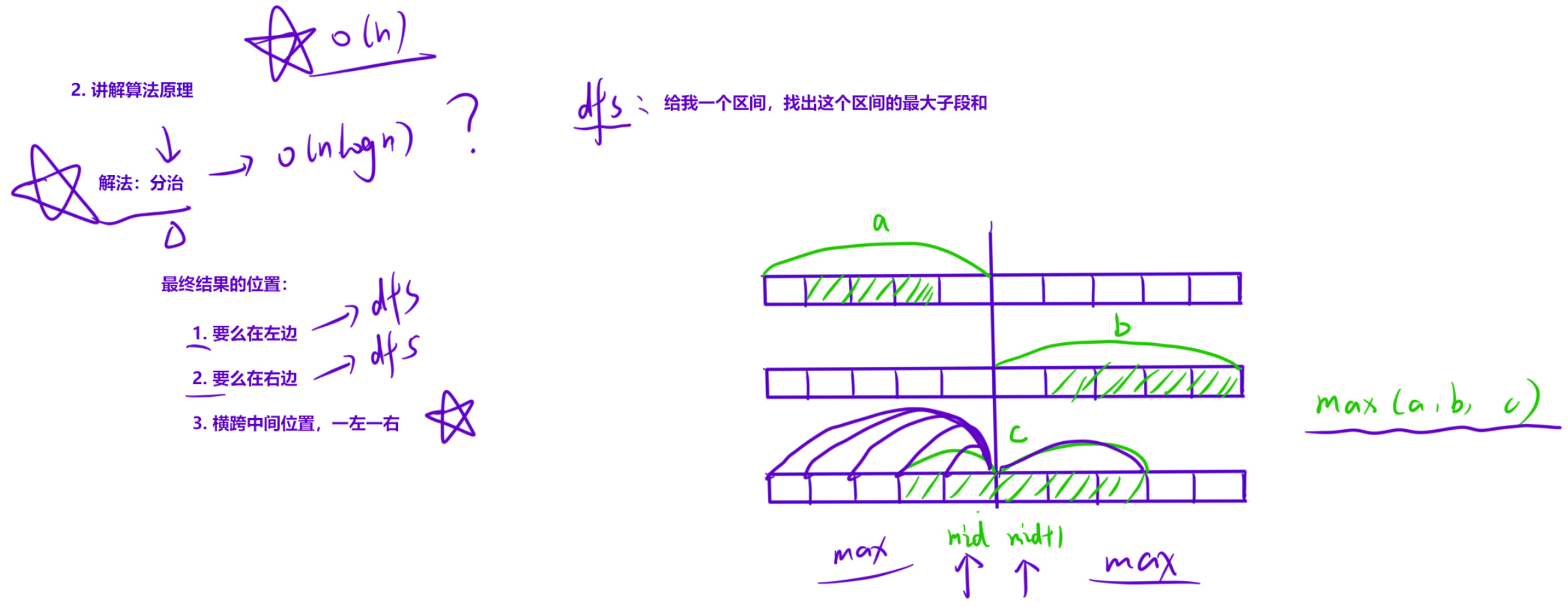
【解法】
第三次遇见它了~
如果把整个序列 l,r 从中间 mid 位置分成两部分,那么整个序列中「所有的子数组」就分成三部分:
- 子数组在区间 l,mid 内;
- 子数组在区间 mid+1,r 内;
- 子数组的左端点在 l,mid 内,右端点在 mid+1,r 内。
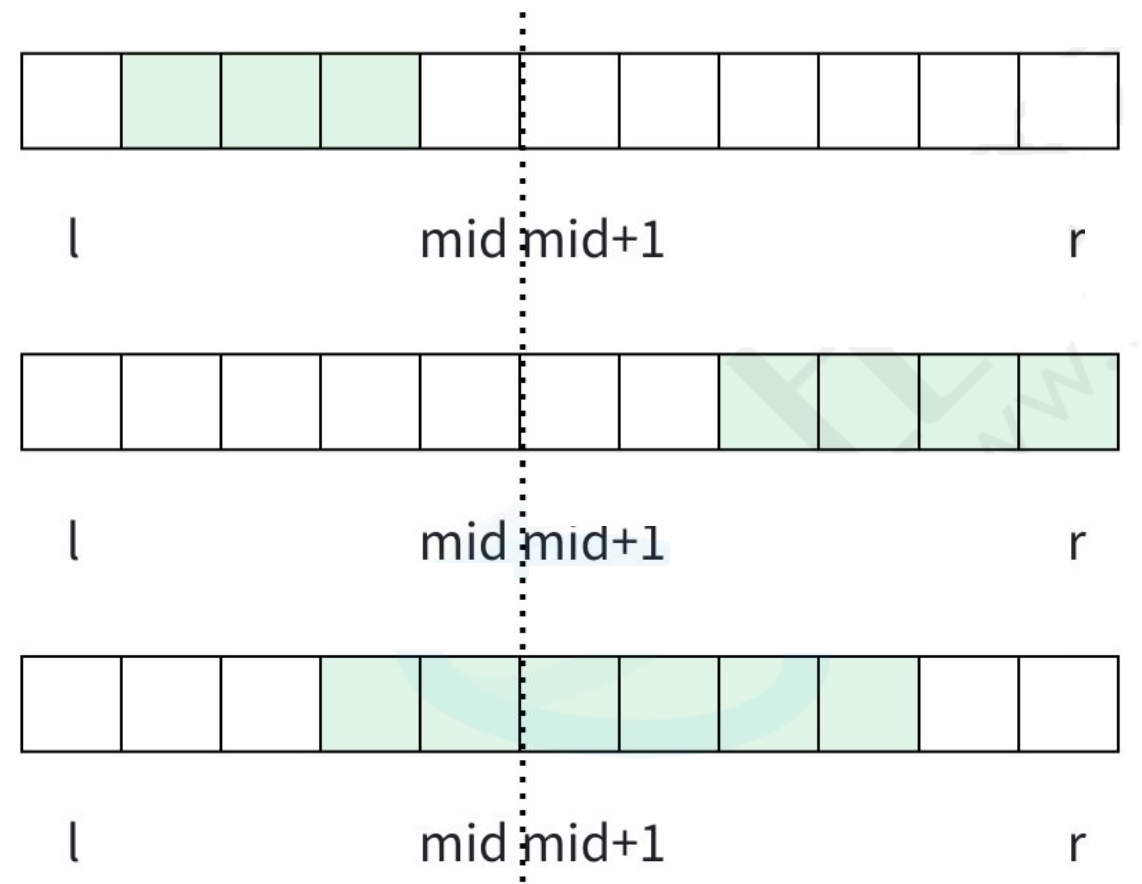
那么我们的「最终结果」也会在这三部分取到,要么在左边区间,要么在右边区间,要么在跨越中轴线的区间。因此,我们可以先求出左边区间的最大子段和,再求出右边区间的最大子段和,最后求出中间区间的最大子段和。最终结果就是三段中的max一段。其中求「左右区间」时,可以交给「递归」去解决。
那我们重点处理如何求出「中间区间」的最大子段和。可以把中间区间分成两部分:
- 左边部分是从 mid 为起点,「向左延伸」的最大子段和;
- 右边部分是从 mid+1 为起点,「向右延伸」的最大子段和。
分别求出这两个值,然后相加即可。求法也很简单,直接「固定起点」,一直把「以它为起点的所有子数组」的和都计算出来(找一左一右的时候相当于一个枚举过程,从mid为尾,向左枚举,以mid + 1为头,向右枚举),取最大值即可。
cpp
#include<iostream>
using namespace std;
const int N = 2e5 + 10;
typedef long long LL;
LL n;
LL a[N];
LL dfs(LL left, LL right)
{
//只有一个元素的时候最大子段和必定是这个元素
if(left >= right) return a[left];
LL mid = (left + right) / 2;
//分别去左右区间找最大子段和
LL ret = max(dfs(left, mid), dfs(mid + 1, right));
//求一左一右的最大子段和
//sum记录从mid向左的区间和
//lmax记录向左求区间和时候的最大值
LL sum = a[mid], lmax = a[mid];
for(int i = mid - 1; i >= left; i--)
{
sum += a[i];
lmax = max(lmax, sum);
}
//求右边的最大子段和
sum = a[mid + 1]; LL rmax = a[mid + 1];
for(int i = mid + 2; i <= right; i++)
{
sum += a[i];
rmax = max(rmax, sum);
}
ret = max(ret, lmax + rmax);
return ret;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
cout << dfs(1, n) << endl;
return 0;
}时间复杂度分析 :
整个过程依旧类似归并排序,处理一左一右的时候,情况是遍历整个数组一遍,因此分治解这道题的时间复杂度也是nlogn,和归并排序的时间复杂度一样
1.4 地毯填补问题
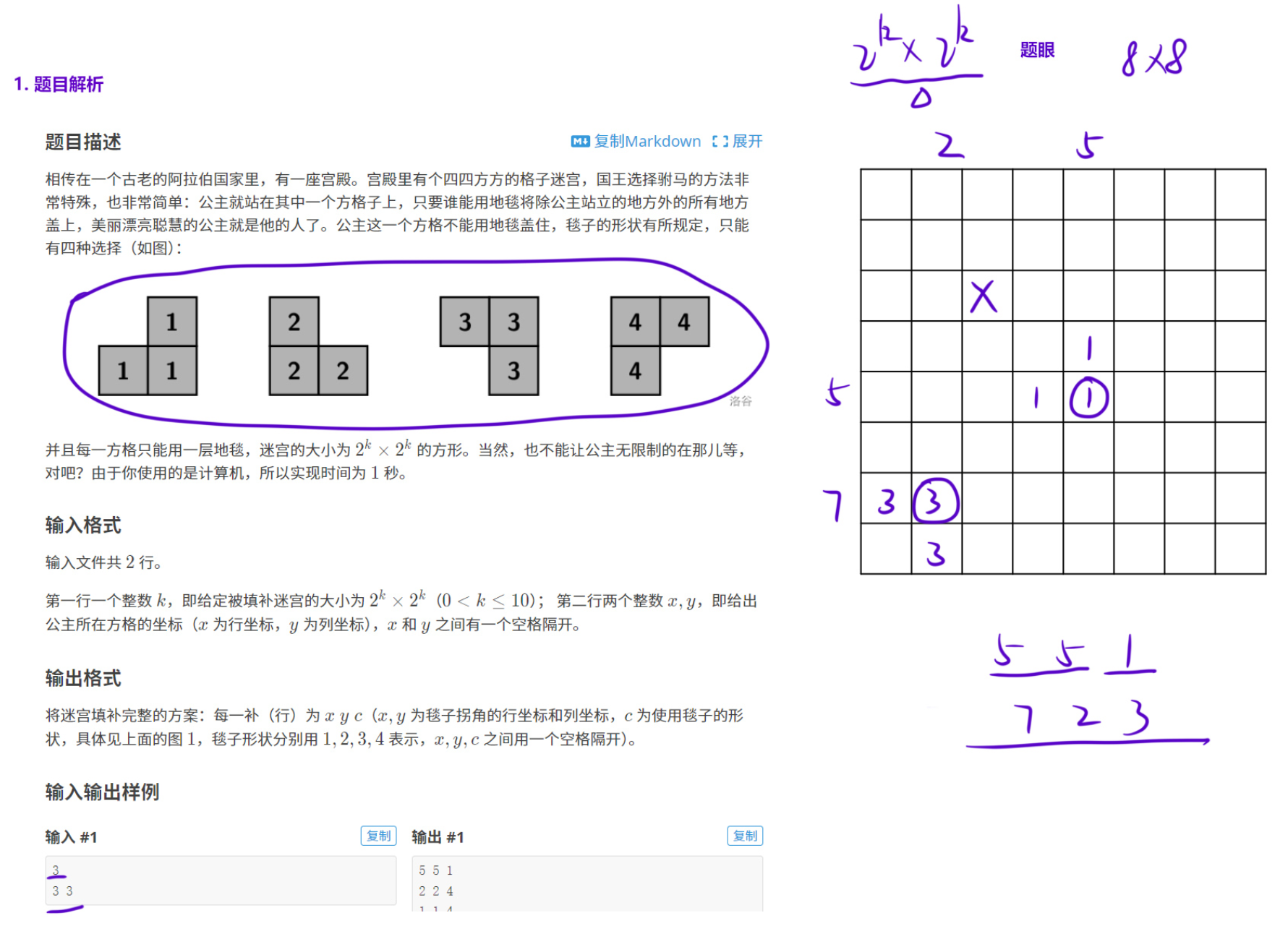
【解法】
非常经典的一道分治题目,也可以说是一道递归题目。
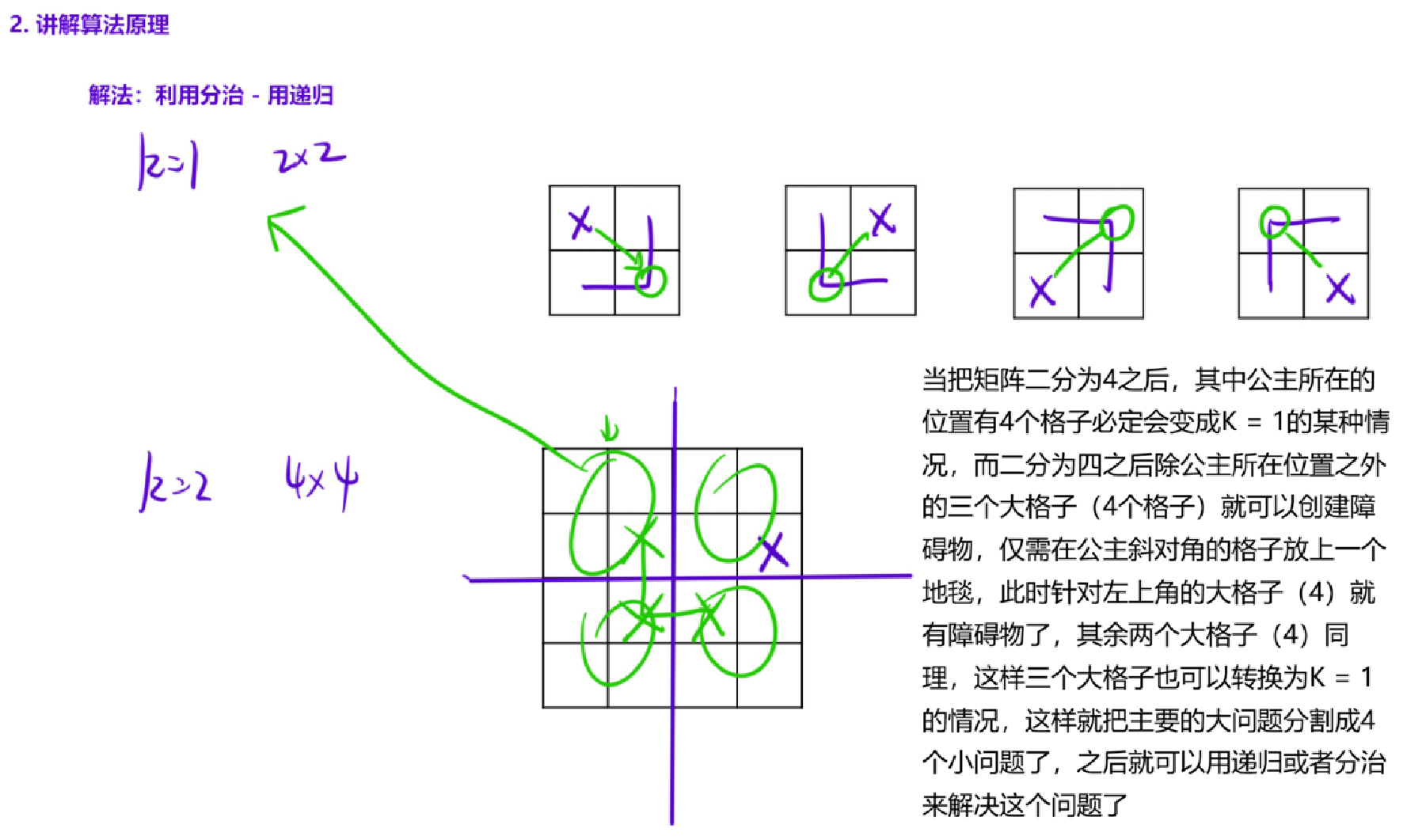
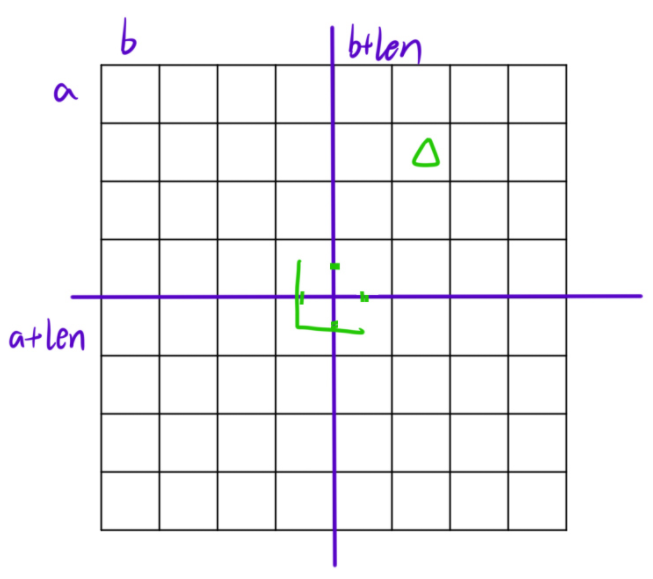
一维分治的时候,我们是从中间把整个区间切开,分成左右两部分(其实有时候我们可以三等分,就看具体问题是什么)。二维的时候,我们可以横着一刀竖着一刀,分成左上、右上、左下、右下四份。而这道题的矩阵长度正好是 2k,能够被不断平分下去。像是在暗示我们,要用分治,要用分治,要用分治......
当我们把整个区间按照中心点一分为四后,四个区间里面必然有一个区间有缺口(就是公主的位置),那这四个区间不一样,那就没有相同子问题了。别担心,只要我们在中心位置放上一块地毯,四个区间就都有一个缺口了。如下图所示:
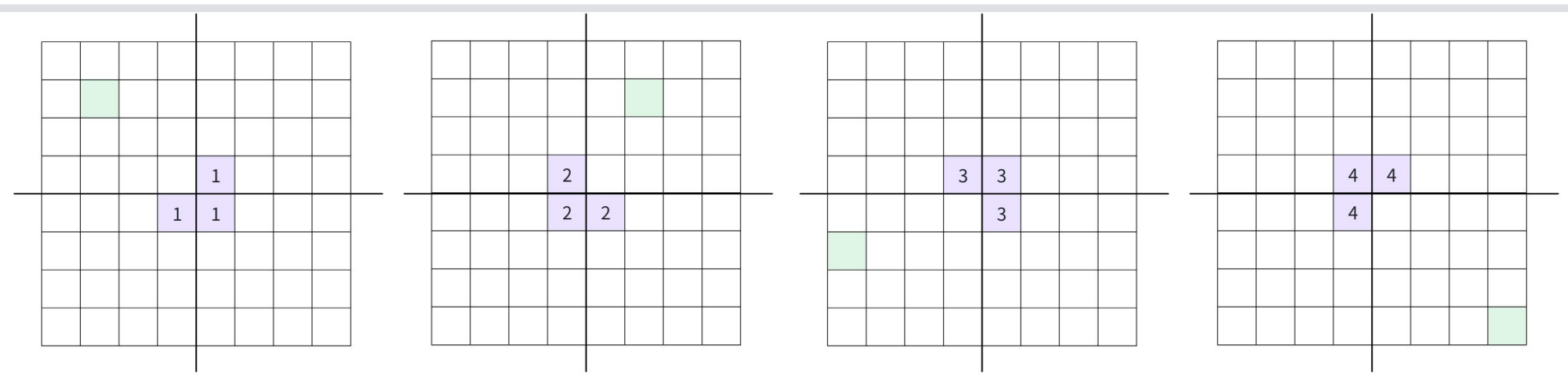
无论缺口在哪里,我们都可以在缺口对应的区间的角落,放上一个地毯。接下来四个区间都变成只有一个缺口的形式,就可以用递归处理子问题。
因此,我们拿到一个矩阵后的策略就是:
- 先四等分;
- 找出缺口对面的区间,放上一块地毯;
- 递归处理四个子问题
cpp
#include<iostream>
using namespace std;
int k, x, y;
void dfs(int a, int b, int len, int x, int y)
{
//长度为1,放不下毯子
if(len == 1) return;
len /= 2;
if(x < a + len && y < b + len) //障碍物在左上角
{
//摆上1号地毯
cout << a + len << " " << b + len << " " << 1 << endl;
dfs(a, b, len, x, y);//左上角
dfs(a, b + len, len, a + len - 1, b + len);//右上角
dfs(a + len, b, len, a + len, b + len - 1);//左下角
dfs(a + len, b + len, len, a + len, b + len);//右下角
}
else if(x >= a + len && y >= b + len)
{
//摆上4号地毯
cout << a + len - 1 << " " << b + len - 1 << " " << 4 << endl;
dfs(a, b, len, a + len - 1, b + len - 1);//左上角
dfs(a, b + len, len, a + len - 1, b + len);//右上角
dfs(a + len, b, len, a + len, b + len - 1);//左下角
dfs(a + len, b + len, len, x, y);//右下角
}
//若前面两个条件不成立,只有左下角和右上角了
//此时只需限定一个横/纵坐标即可
else if(x >= a + len)//障碍物在左下角
{
cout << a + len - 1 << " " << b + len << " " << 3 << endl;
dfs(a, b, len, a + len - 1, b + len - 1);//左上角
dfs(a, b + len, len, a + len - 1, b + len);//右上角
dfs(a + len, b, len, x, y);//左下角
dfs(a + len, b + len, len, a + len, b + len);//右下角
}else{
cout << a + len << " " << b + len - 1 << " " << 2 << endl;
dfs(a, b, len, a + len - 1, b + len - 1);//左上角
dfs(a, b + len, len, x, y);//右上角
dfs(a + len, b, len, a + len, b + len - 1);//左下角
dfs(a + len, b + len, len, a + len, b + len);//右下角
}
}
int main()
{
cin >> k >> x >> y;
//矩阵长度
k = (1 << k);
//矩阵起始位置,矩阵的长度,障碍物位置
dfs(1, 1, k, x, y);
return 0;
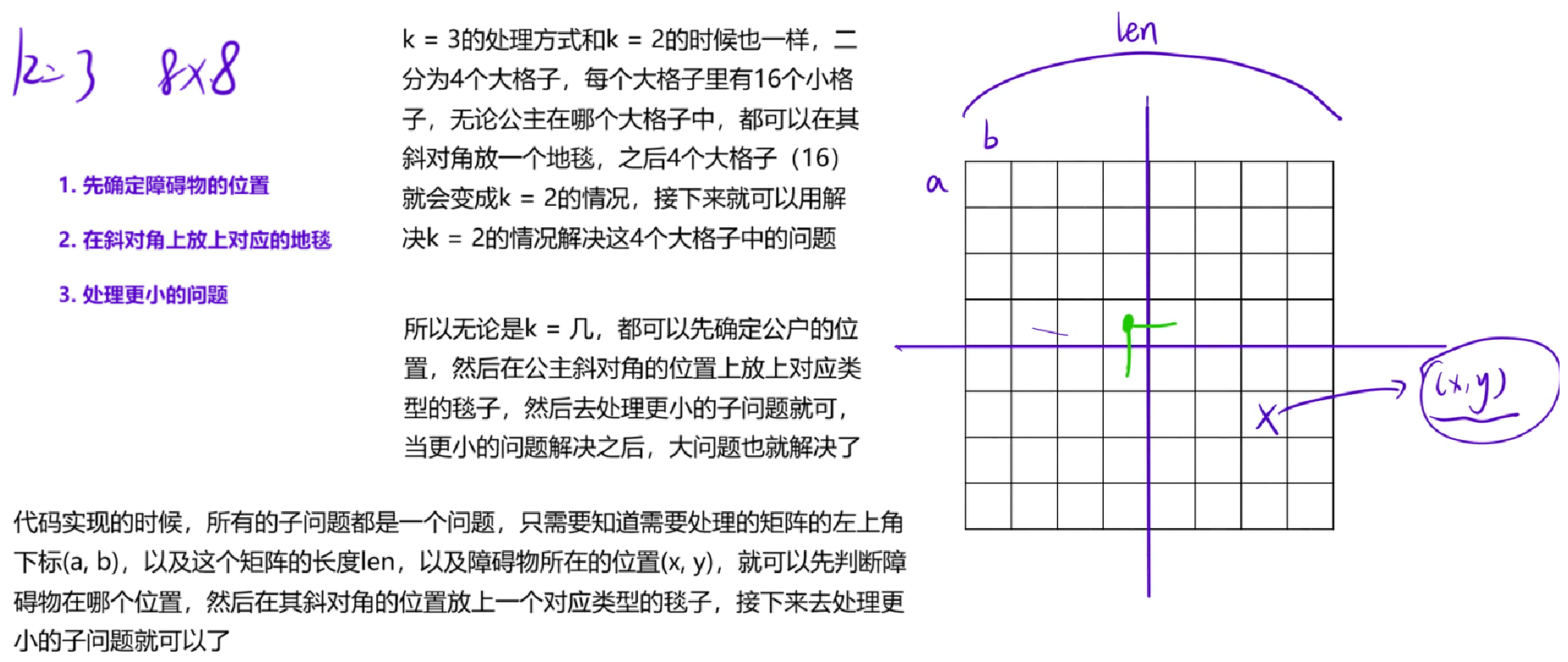
}len表示矩阵初始长度,研究的时候是研究1/2的位置,当k = 3的时候,len就是4个格子的长度,当障碍物在左上角的时候,障碍物坐标的取值范围如图,也就是横纵坐标小于画点的格子的坐标
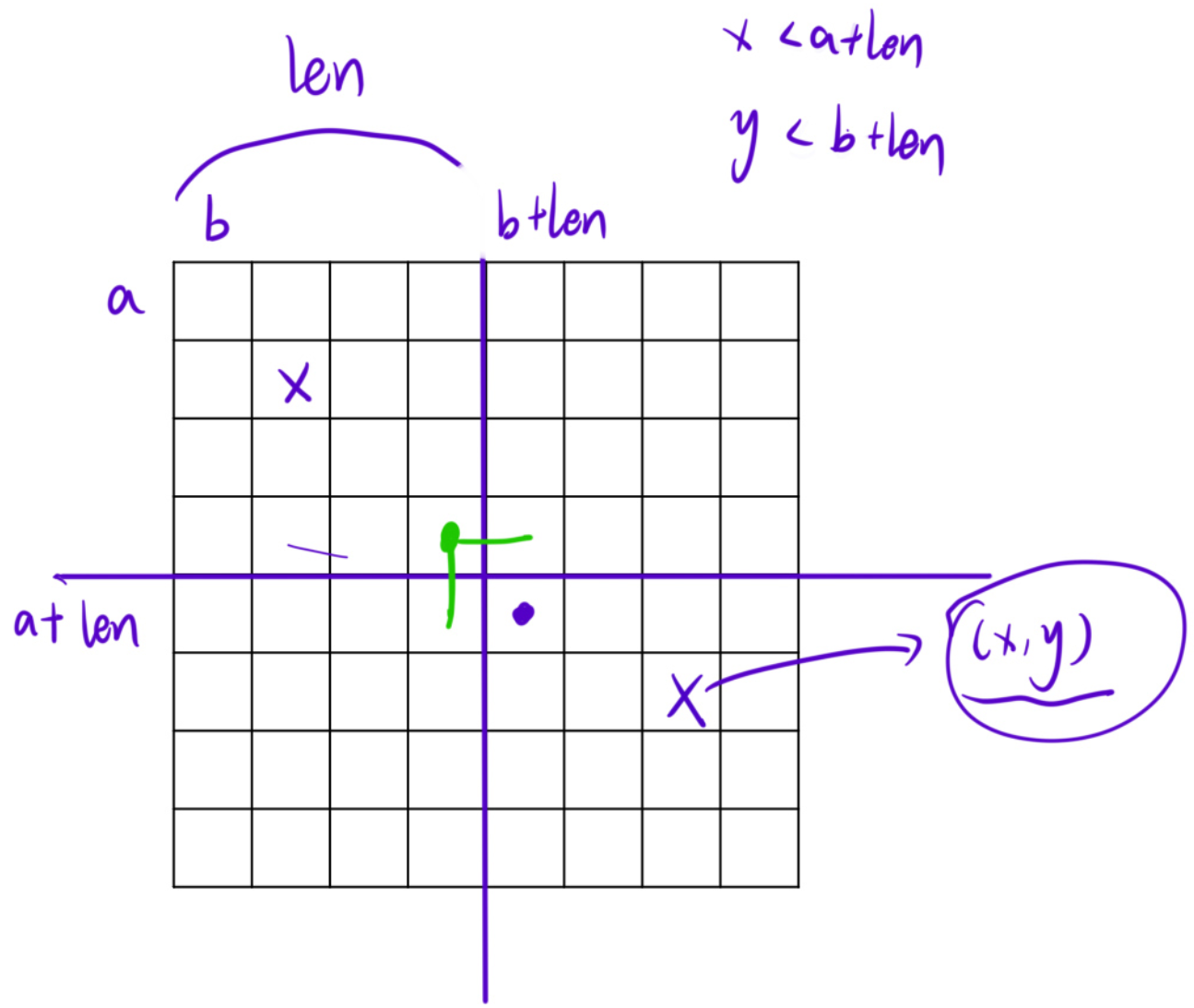
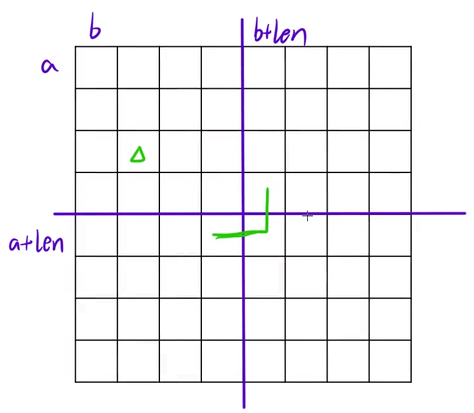
代码中障碍物在左上角对应图中情况,障碍物在左上角是在 (a + len, b + len) 放1号类型的地毯,摆上地毯之后要处理四个大格子(16)的子问题,之后就是4个dfs
第一个子问题即左上角的子问题,矩阵的起始位置是(a, b),长度是len(前面已经除2),障碍物依旧在 (x, y) 的位置上
第二个子问题即右上角的位置,其左上角的坐标 (a, b + len),长度为len,障碍物的坐标位置是(a + len - 1, b + len)
...
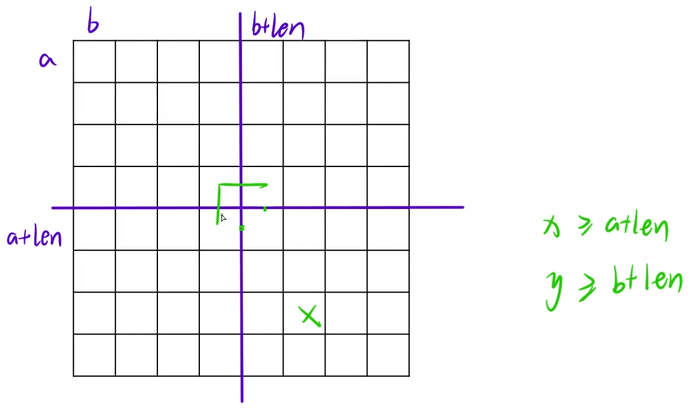
障碍物在右下角的时候,其横纵坐标的限制也比较好找(x >= a + len, y >= b + len)
障碍物在左下角的情况:
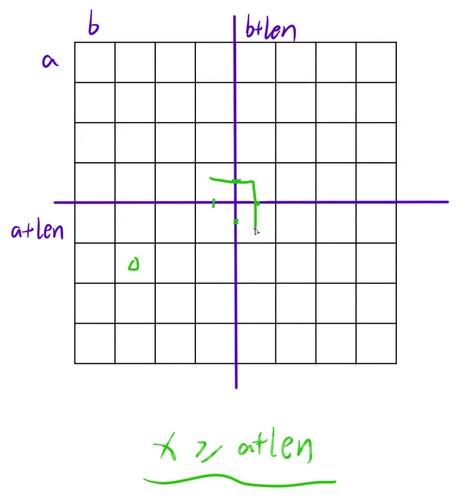
障碍物在右上角
补充一下这道题的测试方法是Special Judge,我们的代码的输出结果就算与样例不同,顺序是乱的也没有关系
结语
