二叉树的层序遍历
1. 题目回顾
问题描述:
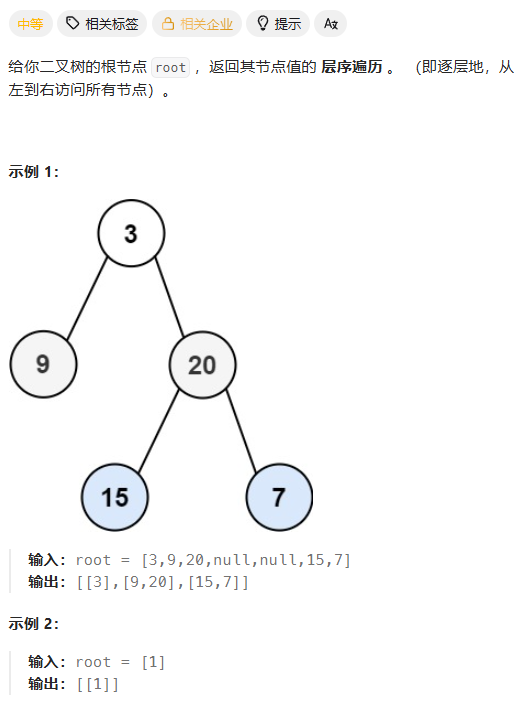
给定一个二叉树的根节点 root,返回其节点值的 层序遍历(即逐层地,从左到右访问所有节点)。
示例:
输入:root = [3,9,20,null,null,15,7]
输出:[[3], [9,20], [15,7]]
核心难点:
与普通的先序或中序遍历不同,层序遍历要求我们将同一层的节点放在同一个列表中。我们需要一种机制来精确感知 "这一层什么时候结束" 以及 "下一层从哪里开始"。
2. 核心思路:分治与模块化(队列版)
层序遍历的本质是 广度优先搜索(BFS) 。我们使用 队列(Queue) 作为核心数据结构,利用其"先进先出"的特性来模拟层级推进的过程。
- 分解过程(入队): 将当前层的节点从队列头部取出,同时将其左右子节点(即下一层的节点)放入队列尾部。
- 解决过程(计数分层): 这是代码中最关键的技巧------在每一层处理开始前,记录当前队列的大小
curSize。这个大小正好等于 当前层的节点数量。 - 合并过程(分组存储): 利用内层循环处理完这
curSize个节点后,我们就完整地收集了一层的数据,将其加入结果集并清空临时列表,准备进入下一层。
3. 算法详细步骤
3.1 递归终止条件(边界处理)
在迭代法中,外层 while 循环的条件充当了终止判断。
- 如果初始
root == null,直接返回空结果集。 - 只要队列
linkedList不为空,说明还有节点未被处理,循环继续;一旦队列为空,说明整棵树遍历完毕。
3.2 分解过程:寻找与断链(内层循环)
为了区分层级,我们在外层循环内部定义了一个变量 int curSize = linkedList.size()。
- 锁定当前层:
curSize锁定了当前这一层有多少个节点需要处理。 - 逐个击破: 内层
while (curSize != 0)循环确保我们只处理当前层的节点,不会混入下一层刚加入的节点。 - 断开连接: 使用
poll()方法移除队头元素,意味着该节点已被"消费"。
3.3 解决过程:调用通用遍历逻辑
在内层循环中,对每一个取出的节点 tempNode 执行以下操作:
- 记录值: 将
tempNode.val加入临时列表temp。 - 扩展下一层: 检查
tempNode.left和tempNode.right。如果不为空,使用offer()将它们加入队列尾部。注意:此时加入的节点属于下一层,不会影响当前层的curSize计数。
3.4 合并过程:重连与复位
当内层循环结束(即 curSize 减为 0)时:
- 保存结果: 将装满当前层数据的
temp列表加入最终结果res。 - 复位状态: 调用
temp.clear()清空临时列表,以便复用对象内存,为下一层的数据收集做准备。
4. 代码实现(Java 版本 - 你的代码分析)
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
// 结果容器
List<List<Integer>> res = new ArrayList<>();
if(root == null) return res;
// 临时列表用于存储每一层的节点值
List<Integer> temp = new ArrayList<>();
// 核心数据结构:队列(LinkedList实现了Deque接口,常用作队列)
LinkedList<TreeNode> linkedList = new LinkedList<>();
linkedList.offer(root); // 根节点入队
// 外层循环:控制层数,只要队列不空就还有下一层
while(!linkedList.isEmpty()){
// 【关键步骤】记录当前层的节点数量
int curSize = linkedList.size();
// 内层循环:只处理当前层的 curSize 个节点
while(curSize != 0){
TreeNode tempNode = linkedList.poll(); // 出队
temp.add(tempNode.val); // 记录值
curSize--; // 计数器减一
// 将下一层的子节点入队
if(tempNode.left != null) linkedList.offer(tempNode.left);
if(tempNode.right != null) linkedList.offer(tempNode.right);
}
// 当前层处理完毕,存入结果
//res.add(temp); 核心问题:temp.clear() 导致上述的引用
结果集被清空
res.add(new ArrayList<>(temp)); //这种方式就行
// 清空临时列表,复用内存
temp.clear();
}
return res;
}
}5. 复杂度分析
-
时间复杂度: O(N)O(N)
其中 NN 是二叉树的节点总数。每个节点进队一次、出队一次,且被访问一次,因此总操作次数与节点数成正比。
-
空间复杂度: O(N)O(N)
主要消耗在于队列
linkedList。在最坏情况下(完全二叉树的最后一层),队列中需要存储约 N/2N/2 个节点,因此空间复杂度为 O(N)O(N) 。此外,结果集res也需要存储所有节点的值。
前序遍历
1. 题目回顾
问题描述: 给定一个二叉树的根节点 root,返回它节点值的前序遍历结果。
示例: 输入 root = [1,null,2,3],输出 [1,2,3]。
核心定义: 前序遍历遵循"根节点 →→ 左子树 →→ 右子树"的访问顺序。这种遍历方式天然适合用于复制一棵树、序列化树结构或生成拓扑排序。
2. 核心思路:分治与模块化
递归版思路
将整棵树的遍历拆解为无数个相同逻辑的子任务。对于任意节点,先处理自己(记录值),再委托给左孩子处理左子树,最后委托给右孩子处理右子树。这是一种自顶向下的自然延伸。
迭代版思路
由于计算机底层没有自动的函数调用栈,我们需要手动使用显式栈(Stack)来模拟递归行为。因为前序遍历要求"根优先",所以我们在遇到节点时立刻将其值加入结果集,然后为了维持"先左后右"的顺序,利用栈的后进先出特性,先将右孩子压栈,再将左孩子压栈。
3. 算法详细步骤
3.1 递归终止条件(边界处理)
当传入的当前节点为 null 时,说明已经走到了叶子节点的尽头,直接返回,不再继续深入。
3.2 分解过程:寻找与断链
- 递归视角: 依次对
node.left和node.right发起递归调用。 - 迭代视角: 每次从栈中弹出一个节点,检查其是否有左右孩子。如果有,按照"先右后左"的顺序将它们推入栈中,等待下一轮处理。
3.3 解决过程:调用通用反转/遍历逻辑
在递归代码中,"解决"动作发生在进入左右子树之前(即 list.add(node.val))。在迭代代码中,则是弹出栈顶元素后立即收集其值。
3.4 合并过程:重连与复位
递归的回溯机制天然完成了状态的恢复;而在迭代法中,循环的下一次执行会自动从栈中取出下一个待处理的节点,实现了流程的无缝衔接。
4. 代码实现(Java 版本)
递归实现
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
dfs(root, res);
return res;
}
private void dfs(TreeNode node, List<Integer> list) {
if (node == null) return; // 3.1 边界处理
list.add(node.val); // 3.3 解决:先访问根节点
dfs(node.left, list); // 3.2 分解:遍历左子树
dfs(node.right, list); // 3.2 分解:遍历右子树
}
}迭代实现
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop(); // 3.4 合并:取出下一个节点
res.add(node.val); // 3.3 解决:访问根节点
// 3.2 分解:注意必须先压右孩子,再压左孩子,保证出栈时左边优先
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
}
return res;
}
}5. 复杂度分析
- 时间复杂度: O(n)。无论是递归还是迭代,每个节点都会被精确访问且仅被访问一次。
- 空间复杂度: O(h) 。其中 hh 为树的高度。递归消耗系统调用栈,迭代消耗显式栈。最坏情况(退化为链表)为 O(n),平衡树时为 O(logn) 。
后序遍历
1. 题目回顾
问题描述: 给定一个二叉树的根节点 root,返回它的后序遍历结果。
示例: 输入 root = [1,null,2,3],输出 [3,2,1]。
核心定义: 后序遍历遵循"左子树 →→ 右子树 →→ 根节点"的访问顺序。这种"自底向上"的特性常用于释放内存、计算目录大小或表达式树求值。
2. 核心思路:分治与模块化
递归版思路
与前序遍历相反,我们将"处理自己"的动作延后。先彻底清空左子树的任务,再彻底清空右子树的任务,最后才把当前节点的值记录下来。
迭代版思路(双栈法)
后序遍历的非递归实现是三种遍历中最复杂的,因为根节点必须最后处理。这里采用最直观的 "辅助栈暂存 + 收集栈逆序" 技巧:
- 栈1(辅助栈):严格按照前序遍历的逻辑(根 →→ 左 →→ 右)进行压栈和弹栈操作。
- 栈2(收集栈):将栈1弹出的每一个节点,直接推入栈2中。由于栈1的弹出顺序是"根 →→ 左 →→ 右",那么栈2从底到顶的顺序就变成了"根 →→ 右 →→ 左"。当最终将栈2的元素全部弹出时,得到的正好是完美的后序序列:"左 →→ 右 →→ 根"。
3. 算法详细步骤
3.1 递归终止条件(边界处理)
同样地,当节点为 null 时触发 Base Case,直接返回。在迭代法中,则体现为初始判断和循环条件的控制。
3.2 分解过程:寻找与断链
- 递归视角: 严格先调用
dfs(node.left),再调用dfs(node.right)。 - 迭代视角(双栈): 在栈1不为空时,不断弹出栈顶元素,并检查其左右孩子。为了保证下一次弹出的是左孩子,必须先压入右孩子,再压入左孩子。
3.3 解决过程:调用通用反转/遍历逻辑
- 递归版:
list.add(node.val)被放在两次递归调用的下方。 - 迭代版: 每次从栈1中弹出一个节点时,不急着收集它的值,而是将其作为一个整体对象推入栈2中进行暂存。
3.4 合并过程:重连与复位
- 递归版: 依靠隐式栈回溯完成状态恢复。
- 迭代版: 当栈1被完全掏空后,说明整棵树已经按"根 →→ 左 →→ 右"的顺序被转移到了栈2中。此时只需不断从栈2中弹出节点,将其值加入结果列表,即可完成最终的"合并"与输出。
4. 代码实现(Java 版本)
递归实现
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
dfs(root, res);
return res;
}
private void dfs(TreeNode node, List<Integer> list) {
if (node == null) return; // 3.1 边界处理
dfs(node.left, list); // 3.2 分解:先遍历左子树
dfs(node.right, list); // 3.2 分解:再遍历右子树
list.add(node.val); // 3.3 解决:最后访问根节点
}
}迭代实现(双栈法)
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Deque<TreeNode> stack1 = new ArrayDeque<>(); // 辅助栈:用于模拟前序遍历
Deque<TreeNode> stack2 = new ArrayDeque<>(); // 收集栈:用于暂存节点以达成逆序
stack1.push(root);
while (!stack1.isEmpty()) {
TreeNode node = stack1.pop();
// 3.3 解决:将弹出的节点存入收集栈
stack2.push(node);
// 3.2 分解:先压左孩子,再压右孩子
// 这样出栈的顺序就是:根 -> 右 -> 左
if (node.left != null) stack1.push(node.left);
if (node.right != null) stack1.push(node.right);
}
// 3.4 合并:将收集栈中的节点依次弹出,得到真正的后序序列(左 -> 右 -> 根)
while (!stack2.isEmpty()) {
res.add(stack2.pop().val);
}
return res;
}
}5. 复杂度分析
- 时间复杂度: O(n) 。每个节点都会被精确地压入和弹出两次(分别在两个栈中各一次),总操作次数依然是线性的。
- 空间复杂度: O(n) 。除了需要 O(h) 的空间维护栈1的深度外,栈2在最坏情况下也需要存储所有的节点,因此总的额外空间消耗为 O(n) 。