引言
写 Java 代码的时候,我们天天都在创建对象。但你有没有想过,其中有些对象压根就不该创建?
《Effective Java》第 6 条就叫"避免创建不必要的对象"。听起来简单,但真正理解了,能帮你省下不少性能开销。
通过 6 个实际的代码例子,讲清楚对象重用这件事。从字符串的小陷阱,到正则表达式的优化技巧;从依赖注入的设计,到适配器模式的巧用;最后还有一个容易踩坑的地方------自动装箱。每个例子都有真实的性能测试数据。
核心概念
为什么要避免创建不必要的对象?
创建对象不是免费的。
每次 new 操作,JVM 都要做三件事:分配内存、初始化对象、等对象用完了还得垃圾回收。单个对象的开销可能不大,但在循环或者高频调用的方法里,这些小开销会累积起来,变成性能瓶颈。
特别是循环里创建对象,最容易出问题。
不可变对象的重用价值
不可变对象(Immutable Objects)最适合重用。
什么叫不可变?就是一旦创建,状态就不会变。比如 String、Integer、LocalDate 这些都是。
因为状态不会变,所以可以放心地在多个地方重用同一个实例,不用担心线程安全问题,也不用担心数据被污染。记住这句话就行:不可变对象总是可以安全重用。
字符串重用:从 new String() 说起
字符串是 Java 中最常用的对象之一。正确使用字符串,可以避免大量不必要的对象创建。
错误示范:new String("bikini")
看看下面这行代码:
String s = new String("bikini"); // DON'T DO THIS!
这行代码的问题在于:每次执行都会创建一个新的 String 对象。如果这行代码在循环中,或者在频繁调用的方法中,就会毫无必要地创建数百万个 String 实例。
更糟糕的是,构造方法的参数 "bikini" 本身就是一个 String 实例,它与构造方法创建的对象功能完全相同,创建新的实例完全是多此一举。
正确示范:字符串字面量
改进后的版本:
String s = "bikini";
这个版本使用单个 String 实例,而不是每次执行时创建一个新实例。而且,它可以保证在同一个虚拟机上的任何其他代码,如果恰好包含相同的字符串字面量,都会重用这个实例。
JVM 字符串常量池原理
JVM 为了优化字符串的使用,维护了一个字符串常量池(String Constant Pool)。当代码中出现字符串字面量时,JVM 会先检查常量池中是否已存在相同内容的字符串:
如果存在,直接返回常量池中的引用
如果不存在,创建新实例并放入常量池
这就是为什么下面的代码中,s1 和 s2 指向同一个对象:
String s1 = "bikini";
String s2 = "bikini";
// s1 和 s2 指向同一个对象
assert s1 == s2; // true
深入理解:字符串常量池是 JVM 运行时数据区的一部分,存储在方法区(Method Area)中。这个池子在 JVM 启动时创建,包含了所有编译期常量字符串。通过 String.intern() 方法,我们还可以动态地将字符串添加到常量池中,但需要谨慎使用,因为常量池的大小是有限的,过度使用可能导致内存问题。
Pattern 缓存:正则表达式优化
正则表达式是处理文本的强大工具,但如果使用不当,会造成严重的性能问题。
错误示范:String.matches()
考虑一个验证罗马数字的方法:
java
static boolean isRomanNumeral(String s) {
return s.matches("^(?=.)M*(C[MD]|D?C{0,3})"
+ "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
}这个实现的问题是:String.matches() 方法在内部会为正则表达式创建一个 Pattern 实例,使用一次后就被丢弃,等待垃圾回收。
创建 Pattern 实例是昂贵的,因为它需要将正则表达式编译成有限状态机(Finite State Machine)。如果这个方法被频繁调用,性能损失会非常严重。
正确示范:静态 Pattern 缓存
改进版本:
java
public class RomanNumerals {
private static final Pattern ROMAN = Pattern.compile(
"^(?=.)M*(C[MD]|D?C{0,3})"
+ "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
static boolean isRomanNumeral(String s) {
return ROMAN.matcher(s).matches();
}}
这个版本将 Pattern 实例提升为静态常量,在类加载时编译一次,后续所有调用都可以重用这个实例。
性能对比:6.5 倍提升
根据实测数据:
原始版本:1.1 微秒/次
改进版本:0.17 微秒/次
性能提升:6.5 倍
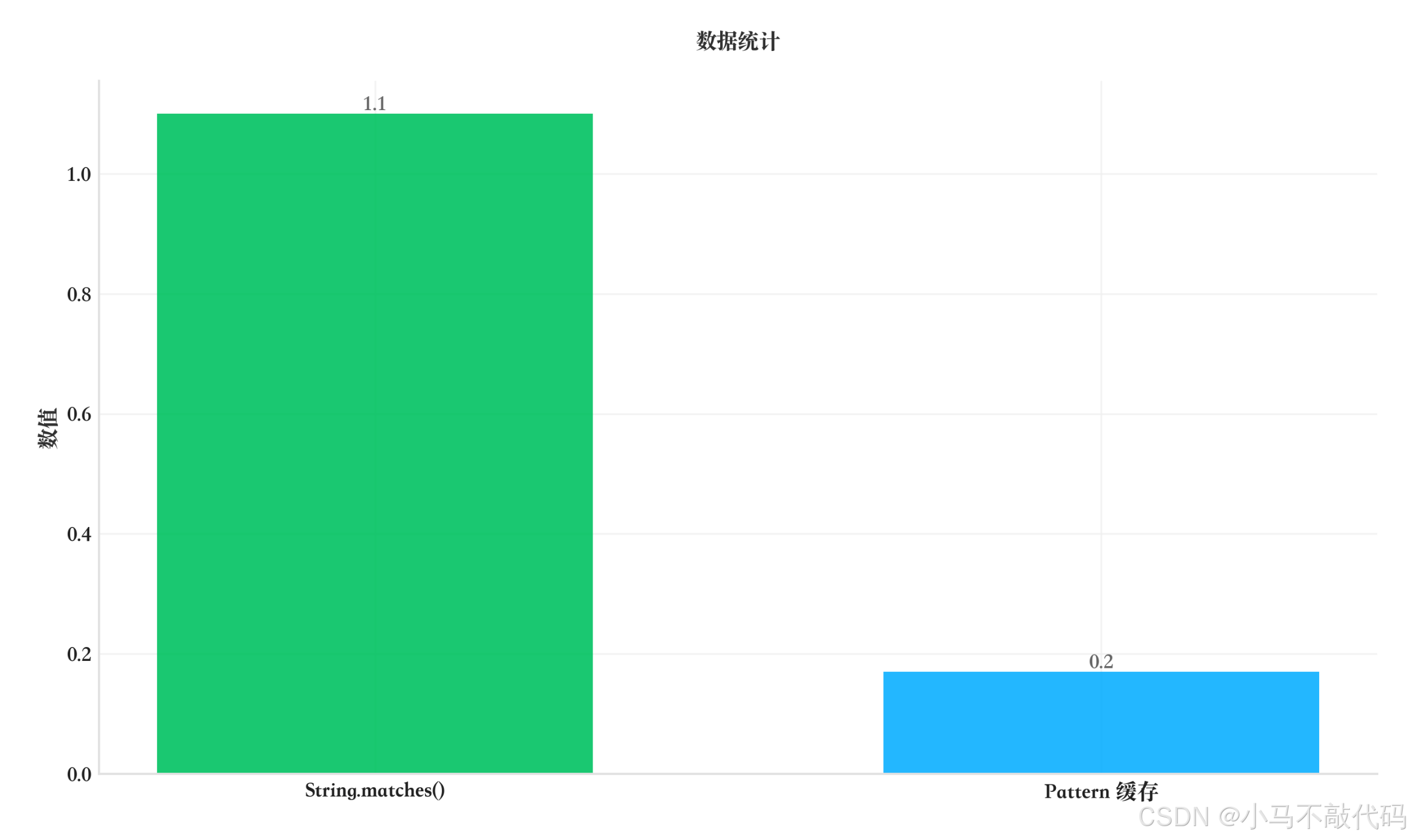
除了性能提升,改进版本还更清晰:为不可见的 Pattern 实例创建了一个静态 final 属性,并给它一个有意义的名字 ROMAN,这比正则表达式本身更具可读性。
延迟初始化的考虑:如果包含 isRomanNumeral 方法的类被初始化,但该方法从未被调用,则 ROMAN 属性则没必要初始化。可以通过延迟初始化(Lazy Initialization)来避免,但一般不建议这样做。延迟初始化常常会导致实现复杂化,而性能没有可衡量的改善。
最佳实践:优先使用急切初始化(Eager Initialization),除非性能分析明确显示初始化开销是瓶颈。
依赖注入:资源共享的艺术
依赖注入(Dependency Injection)不仅是实现解耦的手段,也是实现对象重用的重要模式。
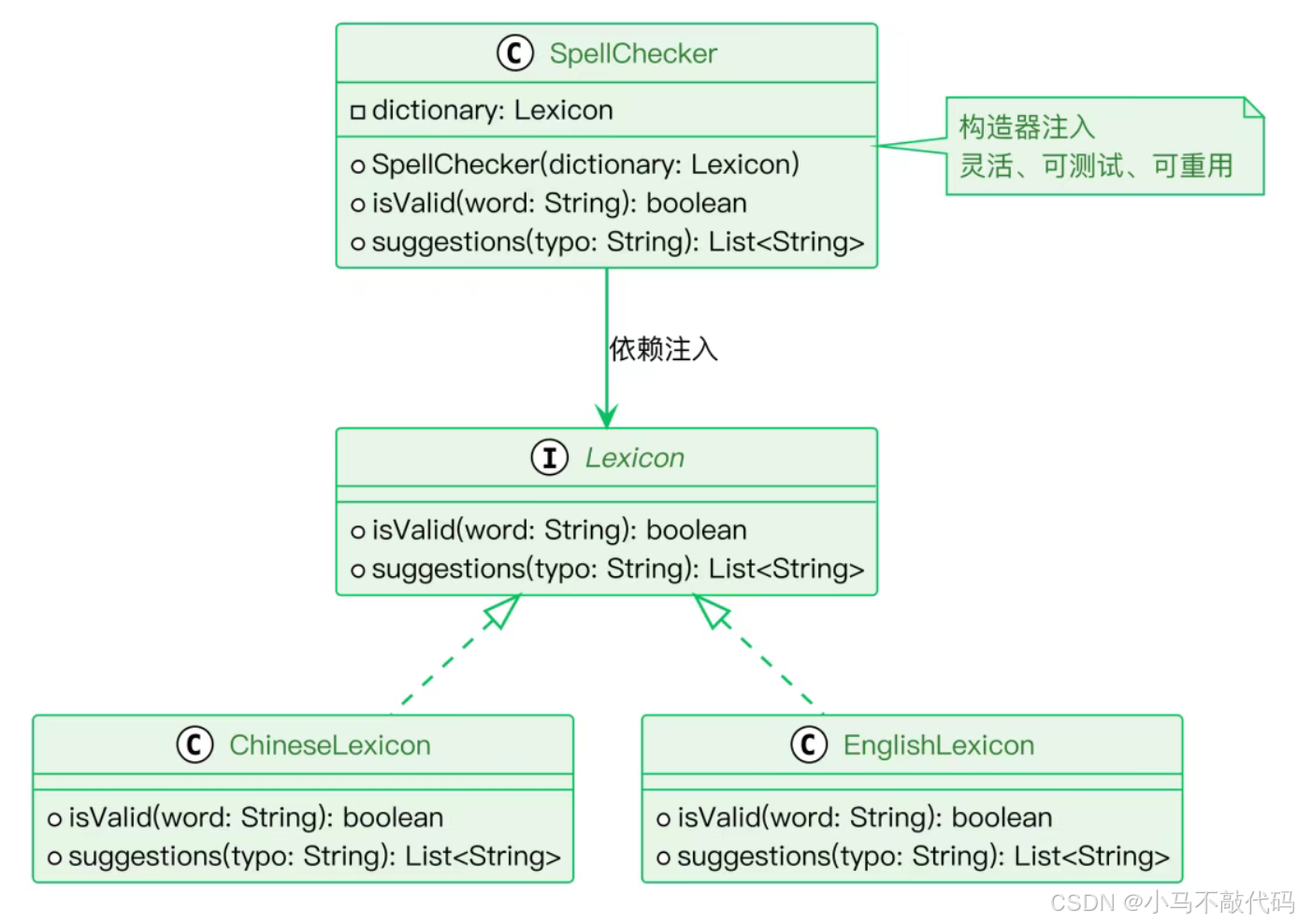
问题场景:SpellChecker
假设我们要实现一个拼写检查器,需要一个词典来验证单词。
错误示范:内部创建依赖
java
public class SpellChecker {
private final Lexicon dictionary = new ChineseLexicon();
public boolean isValid(String word) {
return dictionary.isValid(word);
}
}这种实现有以下问题:
不灵活:词典类型硬编码,无法切换到其他语言
难以测试:无法注入 Mock 词典进行单元测试
资源浪费:每个 SpellChecker 实例都创建一个新的词典实例
正确示范:构造器注入
java
public class SpellChecker {
private final Lexicon dictionary;
public SpellChecker(Lexicon dictionary) {
this.dictionary = Objects.requireNonNull(dictionary);
}
public boolean isValid(String word) {
return dictionary.isValid(word);
}
}这个实现通过构造器注入词典依赖,带来了三大优势:
灵活性:可以注入不同的词典实现(中英文、专业词典等)
可测试性:可以注入 Mock 对象进行单元测试
资源重用:多个 SpellChecker 可以共享同一个词典实例
适配器模式:视图对象的智慧
适配器(Adapter)模式,也称为视图(View)模式,是一种特殊的对象:它委托给一个支持对象(Backing Object),提供一个可替代的接口。由于适配器没有超出其支持对象的状态,因此不需要为给定对象创建多个适配器实例。
Map.keySet() 的设计哲学
Java 的 Map 接口提供了一个 keySet() 方法,返回 Map 中所有键的 Set 视图。一个常见的误解是:每次调用 keySet() 都会创建一个新的 Set 实例。
实际上,对于给定的 Map 对象,keySet() 的多次调用返回的是功能相同的实例:
java
Map<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
Set<String> keys1 = map.keySet();
Set<String> keys2 = map.keySet();
// keys1 和 keys2 可能是同一个对象
// 或者是不同的对象,但功能完全相同视图同步机制
视图对象的核心特性是:对原始 Map 的修改会立即反映到所有视图上。
java
Set<String> view = map.keySet();
// 修改原始 Map
map.put("three", 3);
// 视图立即反映修改
assert view.contains("three"); // true
// 通过视图删除元素
view.remove("one");
// Map 也被修改
assert !map.containsKey("one"); // true这种设计避免了为每次查询创建新的 Set 实例,同时保证了数据的一致性。
自动装箱陷阱:基本类型 vs 包装类型
自动装箱(Auto-boxing)让 Java 开发者可以混用基本类型和包装类型,但在性能关键的场景下,无意识的自动装箱会造成严重的性能损失。
错误示范:Long sum = 0L
看看这个计算正整数总和的方法:
java
private static long sum() {
Long sum = 0L; // DON'T DO THIS!
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
return sum;
}这个程序的结果是正确的,但因为写错了一个字符,性能慢了很多。
问题在于:sum 被声明为 Long(包装类型),而不是 long(基本类型)。每次 += 操作都会:
Long 自动拆箱为 long
执行加法运算
long 自动装箱为 Long(创建新对象)
这个过程在大约 2^31 次迭代中,创建了大约 2^31 个不必要的 Long 实例!
正确示范:long sum = 0L
java
private static long sum() {
long sum = 0L; // 使用基本类型
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
return sum;
}这个版本使用基本类型 long,完全没有对象创建。
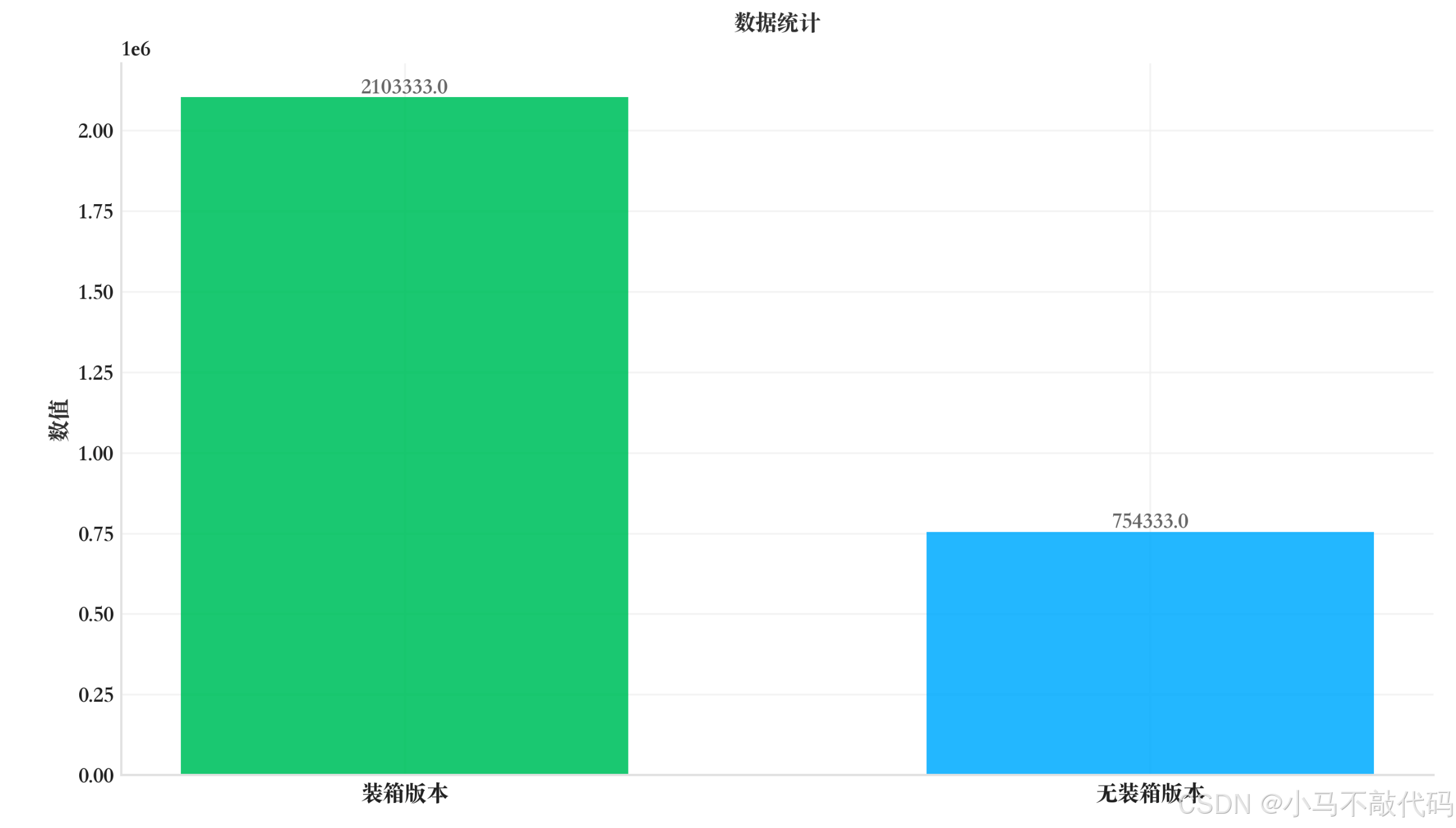
真实性能测试:2.79 倍差异
实际环境中运行。测试范围设定为 100,000 次迭代(避免测试时间过长),以下是真实的测试结果:
无装箱: 754,333 ns
装箱: 2,103,333 ns
比率: 2.79
数据显示,使用基本类型的版本比使用包装类型的版本快了 2.79 倍。如果将迭代次数增加到 Integer.MAX_VALUE,差异会更加显著。
Integer 缓存机制:Java 为 Integer 类型提供了缓存,范围是 -128 到 127。在这个范围内,Integer.valueOf() 会返回缓存的实例:
java
Integer a = 127;
Integer b = 127;
assert a == b; // true,使用缓存实例
Integer c = 128;
Integer d = 128;
assert c == d; // false,超出缓存范围,创建新对象
assert c.equals(d); // true,内容相等这个缓存机制在《Java 语言规范》中有明确定义,但开发者不应该依赖它来优化性能,而应该优先使用基本类型。
最佳实践:在性能关键的代码中,优先使用基本类型,避免不必要的自动装箱。
扩展思考
防御性复制的平衡
本文讲的是重用对象,但有时候必须创建新对象。《Effective Java》第 50 条讲的是防御性复制,就是这种场景。
什么时候该创建新对象?当你需要保护数据不被外部修改的时候。正确性比性能重要,别为了性能引入 Bug。
对象池的使用场景
虽然提倡对象重用,但不建议自己维护对象池,除非对象真的很重:
数据库连接池
线程池
大型缓冲区
对于轻量级对象,JVM 的垃圾收集器已经够快了,自己写对象池反而更慢。
现代 JVM 优化
现代 JVM 会自动优化很多场景:
逃逸分析:对象不会逃逸出方法,就在栈上分配
标量替换:把对象拆成几个变量
即时编译:热点代码编译成本地代码
所以小对象的创建成本很低。别过早优化,先测量,确认对象创建真的是瓶颈再优化。
结语
字符串重用:别用 new String(),直接用字面量就行。
Pattern 缓存:正则表达式编译一次就够,别每次都编译,性能能差 6.5 倍。
依赖注入:构造器注入依赖,既灵活又能重用资源。
适配器模式:Map.keySet() 返回的是视图,不用每次都创建新实例。
自动装箱:循环里用基本类型,别用包装类型。测试数据显示,基本类型快 2.79 倍。
核心就一句话:不可变对象可以安全重用。