请注意本文部分内容经过AI辅助生成,虽然经过笔者检查但是并不保证内容的正确性,请自行判断准确性,本文对相关后果不承担责任
本文基于 EMR 7.12.0 集群实际反编译分析。集群配置如下
EMR 通过 AWS Glue Data Catalog 替代传统 Hive Metastore(MySQL/Derby)后端。其核心机制是利用 Hive 的 HiveMetaStoreClientFactory SPI 扩展点,用 AWS SDK v2 的 Glue API 调用替换 Thrift RPC + MySQL 后端,同时通过双向 Converter 在 Hive/Glue 数据模型之间无缝转换。
整体架构如下
┌─────────────────────────────────────────────────────────────────┐
│ Hive / Spark SQL 查询 │
│ (CREATE TABLE, SELECT, SHOW DATABASES ...) │
└──────────────────────────┬──────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────────┐
│ IMetaStoreClient 接口 (Hive 标准接口) │
│ getDatabase(), getTable(), getPartition(), createTable() ... │
└──────────────────────────┬──────────────────────────────────────┘
│ 实现替换
▼
┌──────────────────────────────────────────────────────────────────┐
│ AWSCatalogMetastoreClient (implements IMetaStoreClient) │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ GlueMetastoreClientDelegate ← 核心委托,所有操作在这里实现 │ │
│ │ ├── GlueClient (AWS SDK v2) ← 实际调用 Glue API │ │
│ │ ├── CatalogToHiveConverter ← Glue模型 → Hive模型 │ │
│ │ ├── HiveToCatalogConverter ← Hive模型 → Glue模型 │ │
│ │ └── Warehouse ← HDFS/S3 路径管理 │ │
│ └─────────────────────────────────────────────────────────────┘ │
└──────────────────────────┬──────────────────────────────────────┘
│ AWS SDK v2 (software.amazon.awssdk.services.glue)
▼
┌──────────────────────────────────────────────────────────────────┐
│ AWS Glue Data Catalog Service │
│ (Databases, Tables, Partitions, Functions) │
└──────────────────────────────────────────────────────────────────┘JAR 文件(3 层架构)位于 /usr/share/aws/hmclient/lib/:
| JAR | 大小 | 用途 |
|---|---|---|
aws-glue-datacatalog-client-common-4.9.0.jar |
155KB | 公共层:GlueMetastoreClientDelegate、Converter、GlueClientFactory、凭证工厂 |
aws-glue-datacatalog-hive3-client-4.9.0.jar |
199KB | Hive 专用:AWSCatalogMetastoreClient(Hive3 版本)、Factory 入口 |
aws-glue-datacatalog-spark-client-4.9.0.jar |
244KB | Spark 专用:AWSCatalogMetastoreClient(Spark 版本)+ LakeFormation FGAC 支持 |
加载路径如下
-
Hive Metastore 进程 :通过
/usr/lib/hive/auxlib/软链接加载hive3-client.jar/usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar → /usr/share/aws/hmclient/lib/aws-glue-datacatalog-hive3-client.jar → aws-glue-datacatalog-hive3-client-4.9.0.jar -
Spark Driver/Executor :通过
spark.driver.extraClassPath/spark.executor.extraClassPath加载spark-client.jar/usr/share/aws/hmclient/lib/aws-glue-datacatalog-spark-client.jar
Common JAR:
com/amazonaws/glue/catalog/converters/ # 双向模型转换器
com/amazonaws/glue/catalog/exceptions/ # 异常定义
com/amazonaws/glue/catalog/metastore/ # 核心委托、客户端工厂、凭证工厂
com/amazonaws/glue/catalog/util/ # 工具类(批量操作、分区、审计)Hive3 Client JAR(在 Common 基础上增加):
com/amazonaws/glue/shims/ # Hive 版本适配层Spark Client JAR(在 Common 基础上增加):
com/amazonaws/emr/spark/ # Spark 自定义函数插件
com/amazonaws/glue/accesscontrol/ # LakeFormation 访问控制
com/amazonaws/glue/accesscontrol/s3a/ # S3 访问控制集成
com/amazonaws/glue/fgac/ # 细粒度访问控制
com/amazonaws/glue/catalog/metastore/converters/ # Spark 专用转换器
com/amazonaws/glue/catalog/metastore/util/ # 视图 SQL 验证启动调用链(Factory 模式)
AWSGlueDataCatalogHiveClientFactory 实现了 Hive 的 HiveMetaStoreClientFactory 接口,这是 Hive 的 SPI 扩展点,让 Glue 客户端无缝替换原生 Thrift 客户端。从反编译字节码还原的调用链如下
1. Hive/Spark 读取配置:
hive.metastore.client.factory.class =
com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory
2. AWSGlueDataCatalogHiveClientFactory.createMetaStoreClient(HiveConf, HookLoader, ...):
→ new AWSCatalogMetastoreClient(HiveConf, HiveMetaHookLoader)
3. AWSCatalogMetastoreClient 构造函数 (Builder 模式):
→ AWSGlueClientFactory.newClient() // 创建 AWS SDK v2 GlueClient
→ new Warehouse(conf) // 初始化 HDFS/S3 路径管理
→ new GlueMetastoreClientDelegate(conf, glueClient, warehouse, catalogId, converter)
→ doesDefaultDBExist() ? : createDefaultDatabase() // 确保 default 库存在反编译的 Factory 字节码:
java
public class AWSGlueDataCatalogHiveClientFactory implements HiveMetaStoreClientFactory {
public IMetaStoreClient createMetaStoreClient(HiveConf conf, HiveMetaHookLoader hookLoader,
boolean allowEmbedded, ConcurrentHashMap<String, Long> cache) throws MetaException {
return new AWSCatalogMetastoreClient(conf, hookLoader);
}
}核心委托模式(GlueMetastoreClientDelegate)
所有 metastore 操作都委托给此类:
关键成员变量
java
private final GlueClient glueClient; // AWS SDK v2 Glue 客户端
private final Configuration conf; // Hadoop 配置
private final Warehouse wh; // 路径管理
private final CatalogToHiveConverter catalogToHiveConverter; // Glue→Hive 转换
protected final String catalogId; // Glue Catalog ID(默认账号ID)
protected final int numPartitionSegments; // 分区并行获取段数
protected static final ExecutorService GLUE_METASTORE_DELEGATE_THREAD_POOL; // 并行线程池操作映射关系
| Hive Metastore 操作 | Glue API 调用 |
|---|---|
getDatabase("mydb") |
glueClient.getDatabase(GetDatabaseRequest) → CatalogToHiveConverter.convertDatabase() |
createTable(table) |
HiveToCatalogConverter.convertTable(table) → glueClient.createTable(CreateTableRequest) |
getTable(db, tbl) |
glueClient.getTable(GetTableRequest) → CatalogToHiveConverter.convertTable() |
getPartitions(db, tbl, expr) |
glueClient.getPartitions() → CatalogToHiveConverter.convertPartitions() |
addPartitions(partList) |
HiveToCatalogConverter.convertPartition() → glueClient.batchCreatePartition() |
dropTable(db, tbl) |
glueClient.deleteTable(DeleteTableRequest) |
alterTable(db, tbl, newTbl) |
HiveToCatalogConverter.convertTable() → glueClient.updateTable(UpdateTableRequest) |
AWSCatalogMetastoreClient 关键成员
java
public class AWSCatalogMetastoreClient implements IMetaStoreClient {
private final Configuration conf;
private final GlueClient glueClient;
private final Warehouse wh;
private final GlueMetastoreClientDelegate glueMetastoreClientDelegate; // 核心委托
private final String catalogId;
private final CatalogToHiveConverter catalogToHiveConverter;
private final AwsGlueHiveShims hiveShims; // Hive 版本适配
private final HiveMetaHookLoader hookLoader; // Hook 加载器
private Map<String, String> currentMetaVars;
// 批量删除分区的线程池
private static final int BATCH_DELETE_PARTITIONS_PAGE_SIZE;
private static final int BATCH_DELETE_PARTITIONS_THREADS_COUNT;
private static final ExecutorService BATCH_DELETE_PARTITIONS_THREAD_POOL;
}双向模型转换器
HiveToCatalogConverter(Hive → Glue)
java
public class HiveToCatalogConverter {
public static glue.model.Database convertDatabase(hive.api.Database);
public static glue.model.Table convertTable(hive.api.Table);
public static glue.model.Partition convertPartition(hive.api.Partition);
public static glue.model.StorageDescriptor convertStorageDescriptor(hive.api.StorageDescriptor);
public static glue.model.Column convertFieldSchema(hive.api.FieldSchema);
public static glue.model.SerDeInfo convertSerDeInfo(hive.api.SerDeInfo);
public static glue.model.SkewedInfo convertSkewedInfo(hive.api.SkewedInfo);
public static glue.model.Order convertOrder(hive.api.Order);
public static glue.model.UserDefinedFunction convertFunction(hive.api.Function);
public static List<glue.model.ColumnStatistics> convertColumnStatisticsObjList(hive.api.ColumnStatistics);
}CatalogToHiveConverter(Glue → Hive,接口)
java
public interface CatalogToHiveConverter {
TException wrapInHiveException(Throwable);
TException errorDetailToHiveException(glue.model.ErrorDetail);
hive.api.Database convertDatabase(glue.model.Database);
hive.api.Table convertTable(glue.model.Table, String dbName);
hive.api.TableMeta convertTableMeta(glue.model.Table, String dbName);
hive.api.Partition convertPartition(glue.model.Partition);
List<hive.api.Partition> convertPartitions(List<glue.model.Partition>);
hive.api.Function convertFunction(String dbName, glue.model.UserDefinedFunction);
List<hive.api.ColumnStatisticsObj> convertColumnStatisticsList(List<glue.model.ColumnStatistics>);
}实现类:
Hive3CatalogToHiveConverter--- Hive3 专用实现SparkCatalogToHiveConverter--- Spark 专用实现(在 spark-client JAR 中)- 通过
CatalogToHiveConverterFactory按版本选择
分区操作的并行优化
java
// 关键常量
BATCH_CREATE_PARTITIONS_MAX_REQUEST_SIZE // 批量创建分区的最大请求大小
BATCH_GET_PARTITIONS_MAX_REQUEST_SIZE // 批量获取分区的最大请求大小
GET_PARTITIONS_MAX_SIZE // 单次获取分区上限
GET_COLUMNS_STAT_MAX_SIZE // 列统计信息批量获取上限
UPDATE_COLUMNS_STAT_MAX_SIZE // 列统计信息批量更新上限
DEFAULT_NUM_PARTITION_SEGMENTS // 默认并行段数
MAX_NUM_PARTITION_SEGMENTS // 最大并行段数并行获取机制:
getPartitions(db, table, expression, max)
→ getPartitionsParallel(db, table, expression, max, convertToHive)
→ 将请求分成多个 Segment
→ 通过 GLUE_METASTORE_DELEGATE_THREAD_POOL 并行执行 getPartitionsFutures()
→ 合并结果并转换为 Hive Partition 对象可通过配置调整:
aws.glue.partition.num.segments--- 并行段数
Hive和Spark 客户端比较
Spark 客户端比 Hive 客户端多出以下能力:
LakeFormation 细粒度访问控制(FGAC)
| 类 | 功能 |
|---|---|
GlueMetastoreClientLakeFormationDelegate |
LakeFormation 权限委托 |
AWSLakeFormationAccessControlInternal |
内部访问控制逻辑 |
AWSLakeFormationAccessControlUtils |
访问控制工具 |
AWSLakeFormationCredentialVendor |
临时凭证分发 |
AWSLakeFormationCredentialResolver |
凭证解析 |
LakeFormationCredentialsProviderV1 |
凭证提供者 |
accesscontrol.s3a.AWSLakeFormationCredentialResolver |
通过 LakeFormation 获取 S3 临时凭证 |
Spark 特有功能
| 类 | 功能 |
|---|---|
SparkCatalogToHiveConverter |
Spark 专用模型转换器 |
GlueMetastoreViewSqlValidatorUtil |
视图 SQL 验证 |
AwsFunctionsPluginImpl |
AWS 自定义函数插件 |
多方言视图支持
通过 GlueMetastoreClientDelegate 中的常量可以看到:
VIEW_HAS_NON_SPARK_DIALECTS--- 标记视图是否包含非 Spark 方言VIEW_SUB_OBJECTS--- 视图子对象VIEW_UPDATE_ACTION--- 视图更新动作IS_MDV--- 是否为多方言视图FORCE_ALTER_VIEW--- 强制修改视图
凭证链
AWSCredentialsProviderFactory (接口)
├── DefaultAWSCredentialsProviderFactory ← 默认,使用 EC2 Instance Profile
├── SessionCredentialsProviderFactory ← STS 临时凭证
├── ProfileCredentialsProviderFactory ← AWS Profile 配置文件
├── AutoRefreshingProfileCredentialsProvider ← 自动刷新的 Profile 凭证
└── LakeFormationCredentialsProviderFactory ← LakeFormation 凭证
GlueClientFactory (接口)
└── AWSGlueClientFactory.newClient()
→ 使用上述凭证工厂创建 software.amazon.awssdk.services.glue.GlueClient
StsClientFactory (接口)
└── AWSStsClientFactory ← 用于跨账号访问时的 STS AssumeRole
LakeFormationClientFactory (接口)
└── AWSLakeFormationClientFactory ← 创建 LakeFormation 客户端多 Catalog 支持
AWSGlueMultipleCatalogDecorator 继承 AWSGlueDecoratorBase,装饰 GlueClient:
java
public class AWSGlueMultipleCatalogDecorator extends AWSGlueDecoratorBase {
private final Map<String, AwsCredentialsProvider> catalogsCredentialsProviders;
private final String catalogSeparator;
private final AWSCredentialsProviderFactory credentialsProviderFactory;
// 每个 Glue API 调用都会经过 configureRequest() 处理
// 根据 database 名称中的 catalog 分隔符,路由到不同的 Catalog
// 并使用对应 Catalog 的凭证
}因此该库支持通过数据库名称中的分隔符访问不同 AWS 账号的 Glue Catalog。
实际集群配置
Spark hive-site.xml (/etc/spark/conf/hive-site.xml):
xml
<property>
<name>hive.metastore.client.factory.class</name>
<value>com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://ip-192-168-23-52.cn-north-1.compute.internal:9083</value>
</property>Spark spark-defaults.conf:
spark.driver.extraClassPath ...:/usr/share/aws/hmclient/lib/aws-glue-datacatalog-spark-client.jar:...
spark.executor.extraClassPath ...:/usr/share/aws/hmclient/lib/aws-glue-datacatalog-spark-client.jar:...
spark.sql.hive.metastore.sharedPrefixes software.amazon.awssdk.services.dynamodb,com.amazon.ws.emr.hadoop.fs数据流路径
Spark SQL 查询
→ Spark 内置 HiveExternalCatalog
→ 加载 spark-client.jar 中的 AWSGlueDataCatalogHiveClientFactory
→ 创建 AWSCatalogMetastoreClient (Spark 版本)
→ GlueMetastoreClientDelegate
→ AWS SDK v2 GlueClient → Glue Data Catalog API
Hive CLI / HiveServer2 查询
→ HiveMetaStore 进程 (thrift://...:9083)
→ 加载 hive3-client.jar(通过 auxlib 软链接)
→ 创建 AWSCatalogMetastoreClient (Hive3 版本)
→ GlueMetastoreClientDelegate
→ AWS SDK v2 GlueClient → Glue Data Catalog API注意:Metastore Thrift 服务是否运行取决于配置方式,详见下方"两种配置模式"。
两种配置模式对比
基于集群 仅配 spark-hive-site和 同时配 hive-site + spark-hive-site的实际验证:
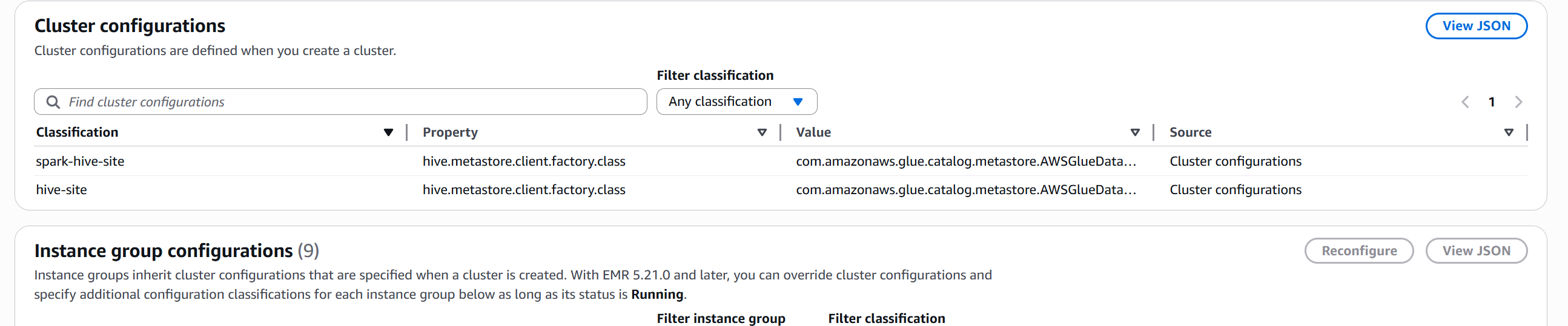
仅配置 spark-hive-site
json
{
"Classification": "spark-hive-site",
"Properties": {
"hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
}| 项目 | 状态 |
|---|---|
| Hive Metastore Thrift 服务 | 运行中,监听 9083 |
| Metastore 后端 | MySQL (jdbc:mysql://...:3306/hive) |
| Hive CLI / HiveServer2 | 通过 Thrift → Metastore → MySQL |
| Spark SQL | 直连 Glue API(通过 spark-client.jar) |
数据流:
Hive CLI → Thrift(:9083) → Metastore → MySQL(:3306)
Spark SQL → AWSGlueDataCatalogHiveClientFactory → Glue API同时配置 hive-site + spark-hive-site
json
[
{
"Classification": "hive-site",
"Properties": {
"hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
},
{
"Classification": "spark-hive-site",
"Properties": {
"hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
}
]| 项目 | 状态 |
|---|---|
| Hive Metastore Thrift 服务 | 不运行,9083 未监听 |
| MySQL 连接 | 无 |
| Hive CLI / HiveServer2 | 直连 Glue API(通过 hive3-client.jar) |
| Spark SQL | 直连 Glue API(通过 spark-client.jar) |
数据流:
Hive CLI → AWSGlueDataCatalogHiveClientFactory → Glue API
Spark SQL → AWSGlueDataCatalogHiveClientFactory → Glue APIEMR 在检测到 hive-site 中配置了 Glue factory 后,不再启动 Metastore Thrift 服务,所有组件直连 Glue,减少一跳延迟。
CloudTrail 审计分析
基于集群上执行 DROP TABLE + CREATE TABLE + INSERT + SELECT 的 CloudTrail 记录。
Hive SQL 到 Glue API 的映射
| Hive SQL 操作 | 触发的 Glue API 调用 |
|---|---|
| Hive CLI 启动 | GetDatabase(default) + GetUserDefinedFunctions(pattern=.*) |
ALTER DATABASE <databasename> SET LOCATION 's3://...' |
GetDatabase(<databasename>) → UpdateDatabase(<databasename>, locationUri=s3://...) |
DROP TABLE IF EXISTS <databasename>.glue_test_table |
GetTable → GetPartitions(segment N/5) → DeleteTable |
CREATE TABLE <databasename>.glue_test_table (...) |
GetDatabase(<databasename>) → GetTable(检查不存在) → CreateTable |
INSERT INTO <databasename>.glue_test_table VALUES (...) |
GetTable ×多次(编译+执行阶段) |
SELECT * FROM <databasename>.glue_test_table |
GetTable + GetPartitions |
CloudTrail 事件时间线
15:03:43 GetUserDefinedFunctions pattern=.* # Hive CLI 启动
15:03:44 GetDatabase default # 初始化
15:03:44 UpdateDatabase <databasename> → s3://user-tmp/<databasename>/ # ALTER DB
15:04:07 GetTable <databasename>.glue_test_table # DROP 前检查
15:04:08 GetPartitions segment 4/5 # 并行获取分区(5段)
15:04:08 DeleteTable <databasename>.glue_test_table # 删除表
15:04:09 GetTable → EntityNotFoundException # 确认已删除
15:04:09 GetDatabase <databasename> # CREATE 前获取DB
15:04:10 GetTable ×多次 <databasename>.glue_test_table # INSERT 编译+执行
15:04:12 GetTable <databasename>.glue_test_table # SELECT
15:04:25 GetDatabases catalogId # 结束关键观察
- API 调用量 :一个简单的
DROP + CREATE + INSERT + SELECT产生约 40+ 次 Glue API 调用 - GetTable 最频繁:Hive 在每个 DDL/DML 阶段都会反复获取表元数据
- 并行分区获取 :
GetPartitions使用segment/totalSegments参数并行获取(默认 5 段),验证了GlueMetastoreClientDelegate中的并行机制 - CreateTable 请求参数:包含完整表定义 --- 列信息、StorageDescriptor、SerDe、InputFormat/OutputFormat、统计信息
- LakeFormation 集成 :每个事件都包含
lakeFormationPrincipal和insufficientLakeFormationPermissions字段 - 传输安全 :所有调用通过 TLSv1.3 加密,endpoint 为
glue.cn-north-1.amazonaws.com.cn - 身份 :使用 EC2 Instance Profile(
EMR_EC2_DefaultRole)通过 STS AssumeRole 获取临时凭证
CloudTrail 事件结构示例(CreateTable)如下
json
{
"eventName": "CreateTable",
"eventSource": "glue.amazonaws.com",
"sourceIPAddress": "xx.xx.xx.118",
"userAgent": "ugi=hadoop aws-sdk-java/2.35.5 ... api/Glue#2.35.x",
"requestParameters": {
"catalogId": "<accountID>",
"databaseName": "<databasename>",
"tableInput": {
"name": "glue_test_table",
"owner": "hadoop",
"storageDescriptor": {
"columns": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "created_at", "type": "timestamp"}
],
"location": "s3://user-tmp/<databasename>/glue_test_table",
"inputFormat": "org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat",
"outputFormat": "org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat",
"serdeInfo": {
"serializationLibrary": "org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe"
}
},
"tableType": "MANAGED_TABLE"
}
},
"resources": [
{"type": "AWS::Glue::Catalog", "ARN": "arn:aws-cn:glue:cn-north-1:<accountID>:catalog"},
{"type": "AWS::Glue::Database", "ARN": "arn:aws-cn:glue:cn-north-1:<accountID>:database/<databasename>"},
{"type": "AWS::Glue::Table", "ARN": "arn:aws-cn:glue:cn-north-1:<accountID>:table/<databasename>/glue_test_table"}
]
}注意事项
- Glue Data Catalog 中的数据库必须设置
locationUri,否则 CREATE TABLE 会报错:location is not defined for database - 使用
ALTER DATABASE db SET LOCATION 's3://bucket/path/'设置(注意不是SET DBPROPERTIES) - CloudTrail 默认记录 Glue 管理事件,无需额外开启