一、ES简介
什么是 Elasticsearch(ES)?
Elasticsearch 是一个分布式、RESTful 风格的搜索和分析引擎 ,基于 Apache Lucene 构建,开源、免费、高可用、易扩展。它被设计用于处理海量数据的全文检索、数据分析、日志存储与分析,是 ELK 技术栈(Elasticsearch + Logstash + Kibana)的核心组件,广泛应用于电商搜索、日志监控、数据分析、站内检索等场景。
核心定位
- 不是关系型数据库(MySQL/Oracle),但具备近实时数据存储、检索能力;
- 核心优势:分布式架构 (自动分片、副本、集群扩容)、全文检索 (分词、模糊查询、聚合分析)、高可用(故障自动转移);
- 设计初衷:解决海量结构化 / 非结构化数据的快速检索 与复杂分析问题。
ES 核心概念
1. 近实时(NRT)
ES 是近实时的搜索平台,从数据写入到可被检索,有轻微延迟(默认 1 秒),区别于实时数据库,满足海量数据检索的性能需求。
2. 集群(Cluster)
- 定义:由一个或多个 ES 节点组成的集合,共享数据和负载;
- 唯一标识:每个集群有唯一名称(默认
elasticsearch),节点通过集群名加入对应集群; - 作用:实现高可用 (节点故障不影响集群)、水平扩展(新增节点扩容性能)。
3. 节点(Node)
- 定义:集群中的单个 ES 实例(一个服务器 / 进程),是存储数据、处理请求的基本单位;
- 常见类型:
- 主节点(Master Node):负责集群元数据管理(如创建索引、分片分配),控制集群状态;
- 数据节点(Data Node):存储数据,处理数据的读写、检索、聚合操作;
- 协调节点(Coordinating Node):接收客户端请求,分发任务到数据节点,汇总结果返回。
4. 索引(Index)
- 定义:同类数据的集合 ,类比 MySQL 中的数据库(Database);
- 特点:每个索引有唯一名称(小写),用于区分不同业务数据(如
user_index用户索引、log_index日志索引); - 核心:索引是 ES 数据组织的最高层级,所有数据都存储在索引中。
5. 文档(Document)
- 定义:ES 中最小的数据存储单位 ,类比 MySQL 中的行(Row);
- 格式:采用JSON 格式存储数据,结构化、易解析;
- 唯一标识:每个文档在索引中有唯一
_id,用于定位数据; - 示例:一个用户信息、一条日志记录都是一个文档。
6. 字段(Field)
- 定义:文档中的属性项 ,类比 MySQL 中的列(Column);
- 类型:ES 支持丰富的数据类型(文本
text、关键字keyword、整数integer、日期date等); - 关键:
text类型会被分词 (用于全文检索),keyword类型不会分词(用于精确匹配、排序、聚合)。
7. 分片(Shard)与副本(Replica)
这是 ES 分布式架构的核心,解决海量数据存储和高可用问题:
(1)主分片(Primary Shard)
- 作用:存储核心数据,处理数据的读写请求;
- 限制:索引创建后,主分片数量不可修改(默认 5 个);
- 原理:将一个索引的数据拆分为多个主分片,分布在不同节点上,实现数据水平拆分。
(2)副本分片(Replica Shard)
- 作用:主分片的备份,实现高可用(主分片故障时,副本自动升级为主分片);同时分担读请求,提升检索性能;
- 特点:副本数量可动态调整(默认 1 个);每个副本分片与主分片分布在不同节点,避免单点故障。
8. 映射(Mapping)
- 定义:定义索引中字段的结构、类型、分词规则 的元数据,类比 MySQL 中的表结构(
CREATE TABLE); - 作用:指定字段是否分词、数据类型、是否索引、是否存储等;
- 分类:
- 动态映射:ES 自动识别文档字段类型(新手友好);
- 静态映射:手动定义字段类型和规则(生产环境推荐,更可控)。
ES 核心特性
1. 分布式架构
- 自动分片:数据自动拆分到多个主分片,负载均衡;
- 自动发现:节点自动加入集群,无需手动配置;
- 故障转移:主节点 / 数据节点故障时,集群自动重新分配分片,保证服务可用;
- 水平扩展:新增节点即可扩容,无需停机,适合海量数据增长。
2. 强大的全文检索能力
- 支持精准匹配、模糊查询、短语匹配、范围查询、布尔查询等多种检索方式;
- 结合 IK 等分词器,实现中文智能分词,支持同义词、停用词、自定义词典;
- 支持高亮显示:检索结果中关键词自动高亮,提升用户体验。
3. 聚合分析(Aggregation)
- 区别于单纯的检索,ES 支持对数据进行统计、分组、求和、平均值、最大值、最小值等聚合操作;
- 应用场景:统计电商商品的销量排行、分析日志的错误率、统计用户的行为分布等;
- 轻量高效:聚合操作在分布式节点并行执行,性能远优于传统数据库。
4. 高可用与可扩展性
- 副本机制保证数据不丢失,节点故障自动恢复;
- 支持在线扩容、缩容,集群无需停机;
- 支持跨机房、跨地域部署,满足企业级高可用需求。
5. RESTful API 接口
- 所有操作(创建索引、增删改查数据、检索、聚合)都通过HTTP RESTful API 完成;
- 支持 JSON 格式请求 / 响应,兼容所有编程语言(Java/Python/Go/PHP 等),开发门槛低。
6. 生态丰富
- 集成 Kibana:可视化数据看板、日志分析、检索调试;
- 集成 Logstash/Beats:日志采集、数据清洗、传输;
- 支持插件扩展:IK 分词器、SQL 插件、监控插件等;
- 兼容大数据生态:与 Hadoop、Spark、Flink 集成,处理海量离线 / 实时数据。
四、ES 与传统数据库的对比
为了方便理解,我们将 ES 与 MySQL(关系型数据库)做对比:
表格
| Elasticsearch | MySQL | 说明 |
|---|---|---|
| 索引(Index) | 数据库(Database) | 数据组织的最高层级 |
| 文档(Document) | 行(Row) | 最小数据存储单位 |
| 字段(Field) | 列(Column) | 数据属性项 |
| 映射(Mapping) | 表结构(Schema) | 定义字段类型和规则 |
| 分片(Shard) | 分库分表 | 数据水平拆分 |
| 全文检索 | 全文索引(MyISAM) | ES 核心能力,性能更强 |
核心区别:
- ES 专注检索与分析 ,MySQL 专注事务处理;
- ES 无事务、外键约束,不适合存储核心交易数据;
- ES 适合海量非结构化 / 半结构化数据,MySQL 适合结构化数据的事务操作。
五、ES 工作原理(核心流程)
1. 数据写入流程
- 客户端发送写入请求到协调节点;
- 协调节点根据文档
_id计算对应的主分片; - 将数据写入主分片,同步复制到副本分片;
- 所有副本写入成功后,返回客户端写入成功;
- 数据近实时可检索(默认 1 秒延迟)。
2. 数据检索流程
- 客户端发送检索请求到协调节点;
- 协调节点将请求分发到所有分片(主 / 副本)并行执行;
- 各分片返回结果到协调节点;
- 协调节点汇总、排序、分页,最终返回给客户端。
3. 分词原理
ES 检索的核心是分词:将文本拆分为多个词汇(Token),建立倒排索引。
- 倒排索引 :ES 核心数据结构,格式为
词汇 -> 包含该词汇的文档列表,类比字典的 "拼音索引",实现快速检索; - 示例:文本 "我是中国人",通过 IK 分词器拆分为
我、是、中国人,建立倒排索引,检索 "中国" 时可匹配到该文档。
六、ES 应用场景
1. 全文检索
- 电商平台:商品名称、详情搜索(如淘宝、京东);
- 内容平台:文章、帖子、文档检索(如知乎、博客);
- 企业知识库:内部文档、资料快速检索。
2. 日志分析与监控
- 采集服务器、应用、容器的日志(ELK 栈);
- 实时监控系统状态、错误日志、性能指标;
- 日志可视化分析、故障快速定位。
3. 数据分析与报表
- 统计用户行为、商品销量、访问流量;
- 生成实时报表、数据看板(Kibana 可视化);
- 企业级商业智能(BI)分析。
4. 地理位置检索
- 支持经纬度数据存储,实现附近的人、附近的店等 LBS 功能;
- 应用:外卖平台、地图导航、线下门店检索。
5. 企业级搜索
- 内部系统搜索、文档管理系统、知识图谱;
- 结合分词器和自定义规则,实现精准的企业级检索。
二、环境准备
1.1 关闭防火墙与 SELinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
setenforce 01.2 创建专用用户(ES 禁止 root 运行)
useradd esuser
echo "123456" | passwd --stdin esuser1.3 配置系统内核参数(ES 必配)
bash
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
cat >> /etc/security/limits.conf <<EOF
esuser soft nofile 65535
esuser hard nofile 65535
esuser soft nproc 4096
esuser hard nproc 4096
EOF1.4 安装依赖
bash
yum install -y wget unzip lsof二、安装 Elasticsearch 7.17.10
2.1 下载并解压
bash
cd /usr/local
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.10-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.17.10-linux-x86_64.tar.gz
mv elasticsearch-7.17.10 elasticsearch2.2 修改权限
bash
chown -R esuser:esuser /usr/local/elasticsearch2.3 修改 elasticsearch.yml 配置
bash
cat > /usr/local/elasticsearch/config/elasticsearch.yml <<EOF
cluster.name: my-es
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
discovery.type: single-node
bootstrap.memory_lock: false
xpack.security.enabled: false
EOF2.4 调整 JVM 内存(虚拟机必备)
cat > /usr/local/elasticsearch/config/jvm.options <<EOF
-Xms512m
-Xmx512m
-XX:+UseG1GC
-XX:+HeapDumpOnOutOfMemoryError
EOF2.5 注册 systemd 服务
bash
cat > /etc/systemd/system/elasticsearch.service <<EOF
[Unit]
Description=Elasticsearch
After=network.target
[Service]
User=esuser
Group=esuser
ExecStart=/usr/local/elasticsearch/bin/elasticsearch
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF2.6 启动并设置开机自启
bash
systemctl daemon-reload
systemctl start elasticsearch
systemctl enable elasticsearch2.7 验证 ES
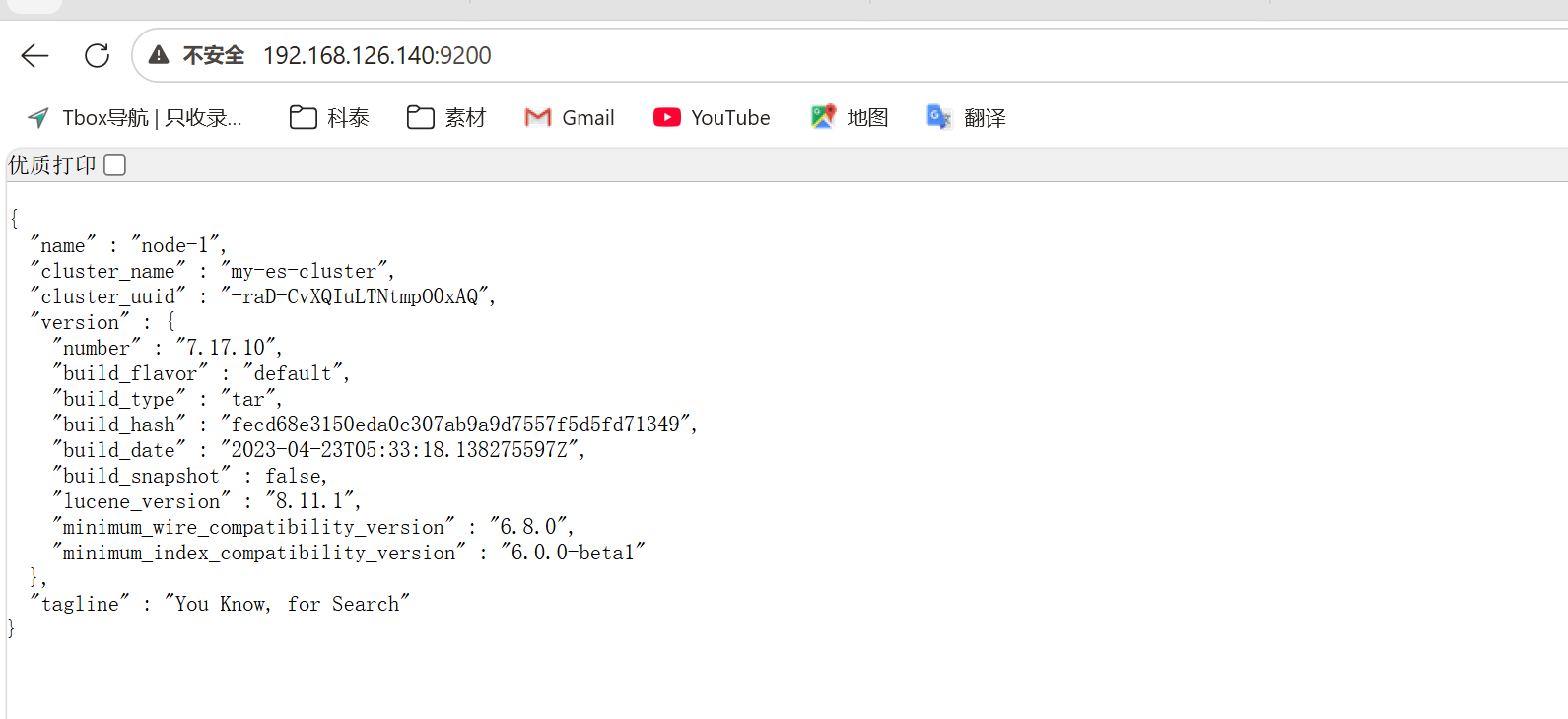
bash
curl http://localhost:9200出现版本信息即安装成功。
三、安装 Kibana 7.17.10
3.1 下载解压
bash
cd /usr/local
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.10-linux-x86_64.tar.gz
tar -zxvf kibana-7.17.10-linux-x86_64.tar.gz
mv kibana-7.17.10-linux-x86_64 kibana
chown -R esuser:esuser /usr/local/kibana3.2 修改 kibana.yml
bash
cat > /usr/local/kibana/config/kibana.yml <<EOF
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
i18n.locale: "zh-CN"
EOF3.3 注册服务并启动
bash
cat > /etc/systemd/system/kibana.service <<EOF
[Unit]
Description=Kibana
After=elasticsearch.service
[Service]
User=esuser
Group=esuser
ExecStart=/usr/local/kibana/bin/kibana
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start kibana
systemctl enable kibana3.4 访问 Kibana
浏览器打开:http://虚拟机IP:5601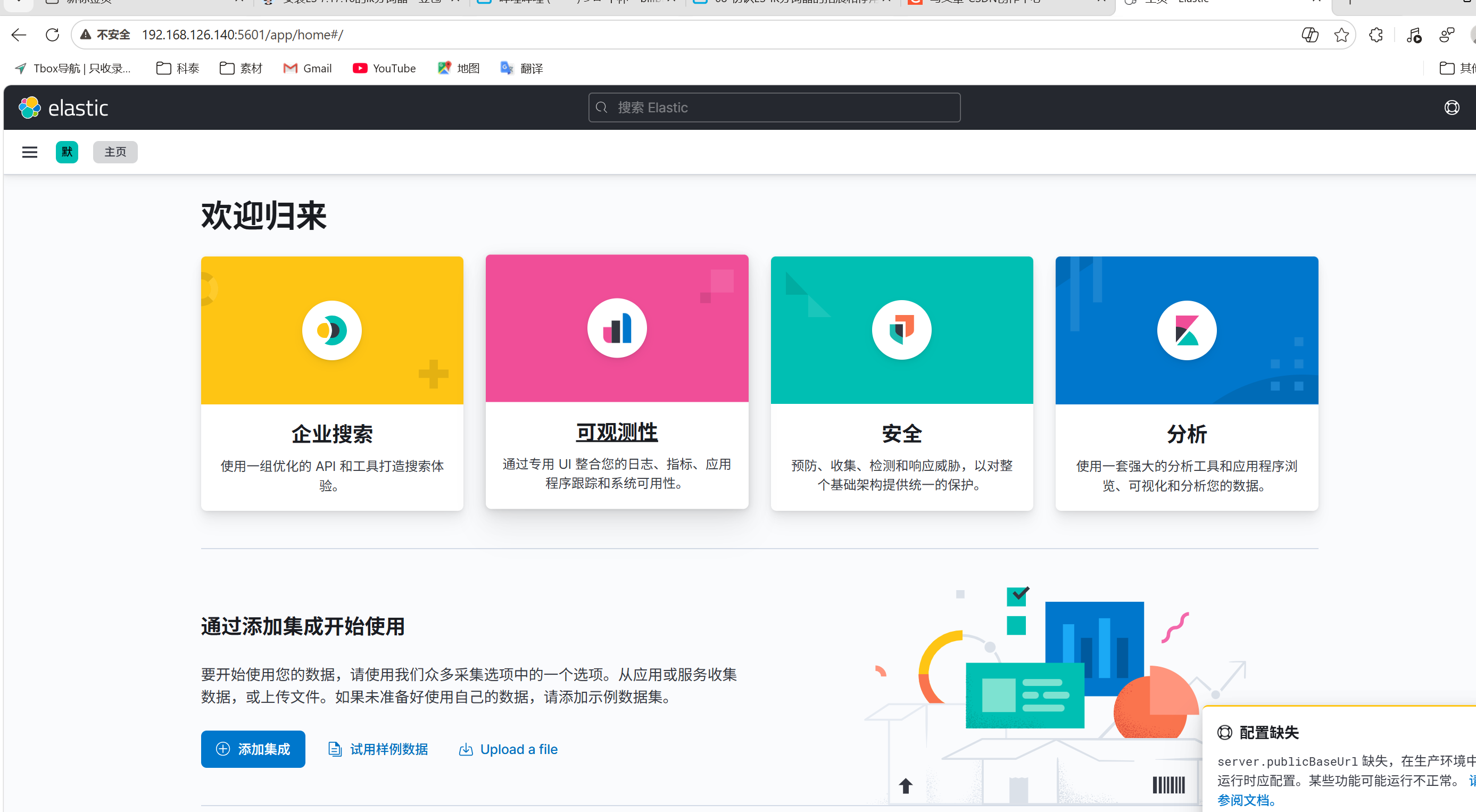
四、安装 IK 中文分词器(版本必须一致)
4.1 下载对应版本 IK
bash
cd /usr/local/elasticsearch/plugins
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.10/elasticsearch-analysis-ik-7.17.10.zip
unzip elasticsearch-analysis-ik-7.17.10.zip -d ik
rm -rf *.zip
chown -R esuser:esuser ik4.2 重启 ES 生效
bash
systemctl restart elasticsearch4.3 验证 IK 分词
bash
curl -X POST "http://localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d '{
"analyzer": "ik_smart",
"text": "我是中国人"
}'返回分词结果即成功。
五、安装拼英分词器
1.拼音分词器 在线安装命令
bash
/usr/local/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.17.10/elasticsearch-analysis-pinyin-7.17.10.zip2.安装完 重启 ES 生效
bash
systemctl restart elasticsearch3.检查是否安装成功
bash
/usr/local/elasticsearch/bin/elasticsearch-plugin listElasticsearch索引操作
1.先搞懂 3 个核心概念,这是 ES 索引的基础:
- 索引(Index) 类比关系型数据库的数据库 ,是存储同类文档的集合,比如
goods(商品索引)、user(用户索引)。 - 映射(Mapping) 类比关系型数据库的表结构 ,定义文档中字段的类型、分词规则、是否索引、是否存储等,比如
title是文本类型、用 IK 分词,price是数字类型。 - 文档(Document) 索引中的一条数据,类比数据库的行记录,每个文档有唯一 ID,以 JSON 格式存储。
2. 关键特性
- 无模式与动态映射:默认情况下,ES 会自动识别文档字段的类型(如字符串、数字、日期),无需提前定义表结构;也可手动定义固定映射。
- 分片与副本 :
- 主分片(Primary Shard):数据的物理存储单元,主分片数量在索引创建后不可修改。
- 副本分片(Replica Shard):主分片的备份,用于容错和提升查询性能,副本数量可动态调整。
- 近实时 :数据写入后,默认 1 秒内可被检索(由
refresh_interval控制)。 - 多租户:一个 ES 集群可以创建多个独立的索引,隔离不同业务的数据。
3. 核心元数据
每个索引都有核心配置项,分为设置(Settings) 和映射(Mapping) 两部分:
- Settings:索引的物理配置(分片数、副本数、刷新间隔、路由规则等)。
- Mapping:索引的字段定义(字段类型、分词器、是否索引、是否存储等)。
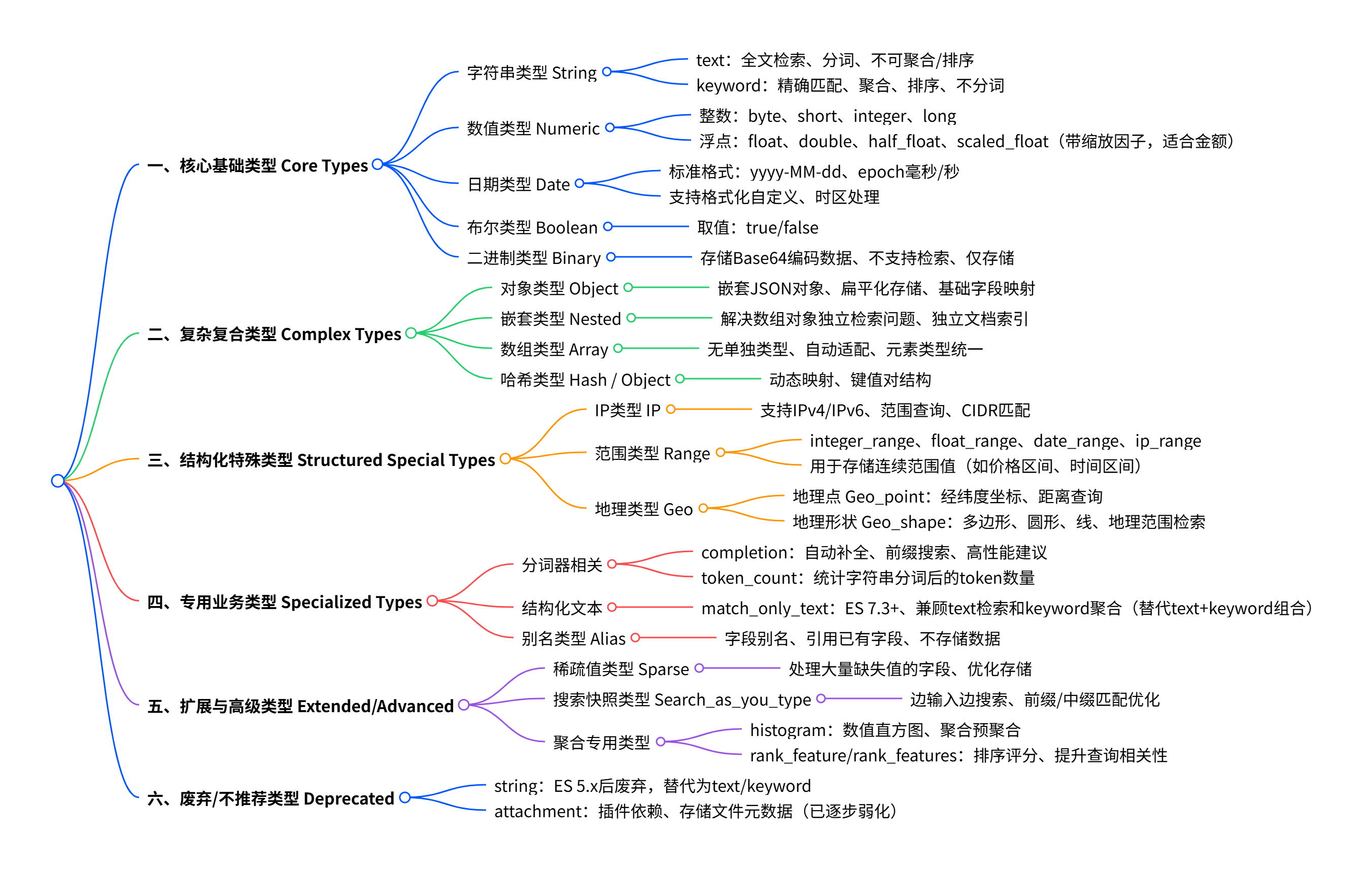
字段的数据类型:
ES中字段的类型主要有:核心类型,复杂类型,地理类型以及特殊类型等
实战练习创建索引
我们有一个这样的数据表需要用到如何创建索引
表格
| MySQL 字段名 | ES 字段名 | MySQL 数据类型 | ES 数据类型 | 字段说明 | 关键备注 |
|---|---|---|---|---|---|
| id | id | BIGINT(20) | keyword | 酒店唯一 ID | 主键,精确匹配 |
| name | name | VARCHAR(255) | text | 酒店名称 | 支持 IK 分词 + 拼音搜索,聚合到 searchInfo |
| brand | brand | VARCHAR(32) | text | 酒店品牌 | 支持 IK 分词,聚合到 searchInfo |
| address | address | VARCHAR(255) | text | 酒店地址 | 仅存储,不建立索引 |
| price | price | INT | integer | 酒店价格 | 数值类型,支持排序 / 区间查询 |
| score | score | DECIMAL(3,2) | scaled_float | 酒店评分 | 高精度浮点,缩放因子 100 |
| city | city | VARCHAR(32) | keyword | 所在城市 | 精确匹配、聚合分组 |
| star | star | TINYINT | byte | 酒店星级 | 1-5 星,小数值类型 |
| lat | location | DECIMAL(10,6) | geo_point | 纬度 | 与 lon 组合为 ES 地理坐标 |
| lon | location | DECIMAL(10,6) | geo_point | 经度 | 与 lat 组合为 ES 地理坐标 |
| pic | pic | VARCHAR(255) | keyword | 酒店图片 | 仅存储,不索引 |
最终创建的索引参考如下:
java
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"ik_pinyin_analyzer": {
"tokenizer": "ik_max_word",
"filter": ["pinyin_filter"]
}
},
"filter": {
"pinyin_filter": {
"type": "pinyin",
"keep_first_letter": true,
"keep_full_pinyin": false,
"keep_none_chinese": true
}
}
}
},
"mappings": {
"properties": {
"id": { "type": "keyword" },
"name": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "ik_pinyin_analyzer"
}
},
"copy_to": "searchInfo"
},
"brand": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "searchInfo"
},
"address": {
"type": "text",
"index": false
},
"price": { "type": "integer" },
"score": {
"type": "scaled_float",
"scaling_factor": 100
},
"city": {
"type": "keyword"
},
"star": { "type": "byte" },
"location": { "type": "geo_point" },
"pic": { "type": "keyword", "index": false },
"searchInfo": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}一、核心配置:settings(分词 / 分析器)
这部分是中文 + 拼音搜索的核心,自定义了专门的分词规则,解决中文和拼音首字母搜索的问题。
"analysis": {
"analyzer": {
"ik_pinyin_analyzer": { // 自定义拼音分析器
"tokenizer": "ik_max_word", // 分词器:IK最大粒度分词
"filter": ["pinyin_filter"] // 过滤器:拼音转换
}
},
"filter": {
"pinyin_filter": { // 拼音过滤器
"type": "pinyin",
"keep_first_letter": true, // ✅ 保留拼音首字母(如:如家 → rj)
"keep_full_pinyin": false, // ❌ 不保留全拼(节省空间)
"keep_none_chinese": true // ✅ 保留数字/英文
}
}
}关键作用:
ik_max_word:IK 分词器的最大细粒度分词(最常用的中文分词模式),比如 "北京希尔顿酒店" 会拆分为:北京、希尔顿、酒店、希尔、尔顿等,保证中文搜索全覆盖。ik_pinyin_analyzer:组合分词 + 拼音,把中文转换成拼音首字母 ,实现拼音首字母快捷搜索 (比如搜rj能找到「如家酒店」)。
二、字段映射:mappings(所有酒店字段定义)
这部分定义了酒店数据的字段类型、是否分词、是否索引、存储规则,是业务搜索的基础:
表格
| 字段名 | 类型 / 配置 | 业务作用 |
|---|---|---|
id |
keyword |
酒店唯一 ID,不分词、精确匹配,用于精准查询 / 更新 |
name |
text + ik_max_word 子字段:pinyin copy_to: searchInfo |
酒店名称(核心搜索字段) 1. 主字段:中文分词搜索2. pinyin子字段:拼音首字母搜索3. 内容复制到聚合搜索字段 |
brand |
text + ik_max_word copy_to: searchInfo |
酒店品牌(如:希尔顿、如家),中文分词搜索,内容复制到聚合字段 |
address |
text + index: false |
酒店地址,只存储、不建立索引(不用于搜索,节省存储空间) |
price |
integer |
酒店价格,整数类型,用于价格区间筛选(如:100-300 元) |
score |
scaled_float scaling_factor: 100 |
酒店评分(如 4.95 分),精准存储小数(避免浮点型误差) |
city |
keyword |
城市名称,不分词、精确匹配,用于筛选城市(如:北京、上海) |
star |
byte |
酒店星级(1-5 星),极小整数类型,节省存储空间 |
location |
geo_point |
经纬度坐标,地理定位专用,支持「附近酒店」「距离排序」 |
pic |
keyword + index: false |
酒店图片地址,只存储、不索引 |
searchInfo |
text + ik_max_word |
聚合搜索字段 :接收name+brand的内容,实现「名称 + 品牌」一次性搜索 |
三、这个索引的核心设计亮点
-
双模式搜索(中文 + 拼音首字母) 酒店名称
name通过 ** 多字段(fields)** 实现:- 搜中文:匹配主字段(ik 分词)
- 搜拼音首字母:匹配
pinyin子字段极大提升用户搜索体验。
-
聚合搜索(copy_to) 用
searchInfo整合酒店名称 + 品牌 ,搜索时不用分别查两个字段,简化搜索语句、提升搜索效率。 -
字段类型极致优化
- 精确查询用
keyword(城市、ID、图片) - 分词搜索用
text(名称、品牌) - 地理用
geo_point、小数用scaled_float、小数字用byte兼顾查询性能 + 存储成本。
- 精确查询用
-
非搜索字段关闭索引 地址、图片只做存储,不建立索引,减少 ES 写入压力、节省磁盘空间。
查看索引
带表头、清晰查看所有索引
GET _cat/indices?v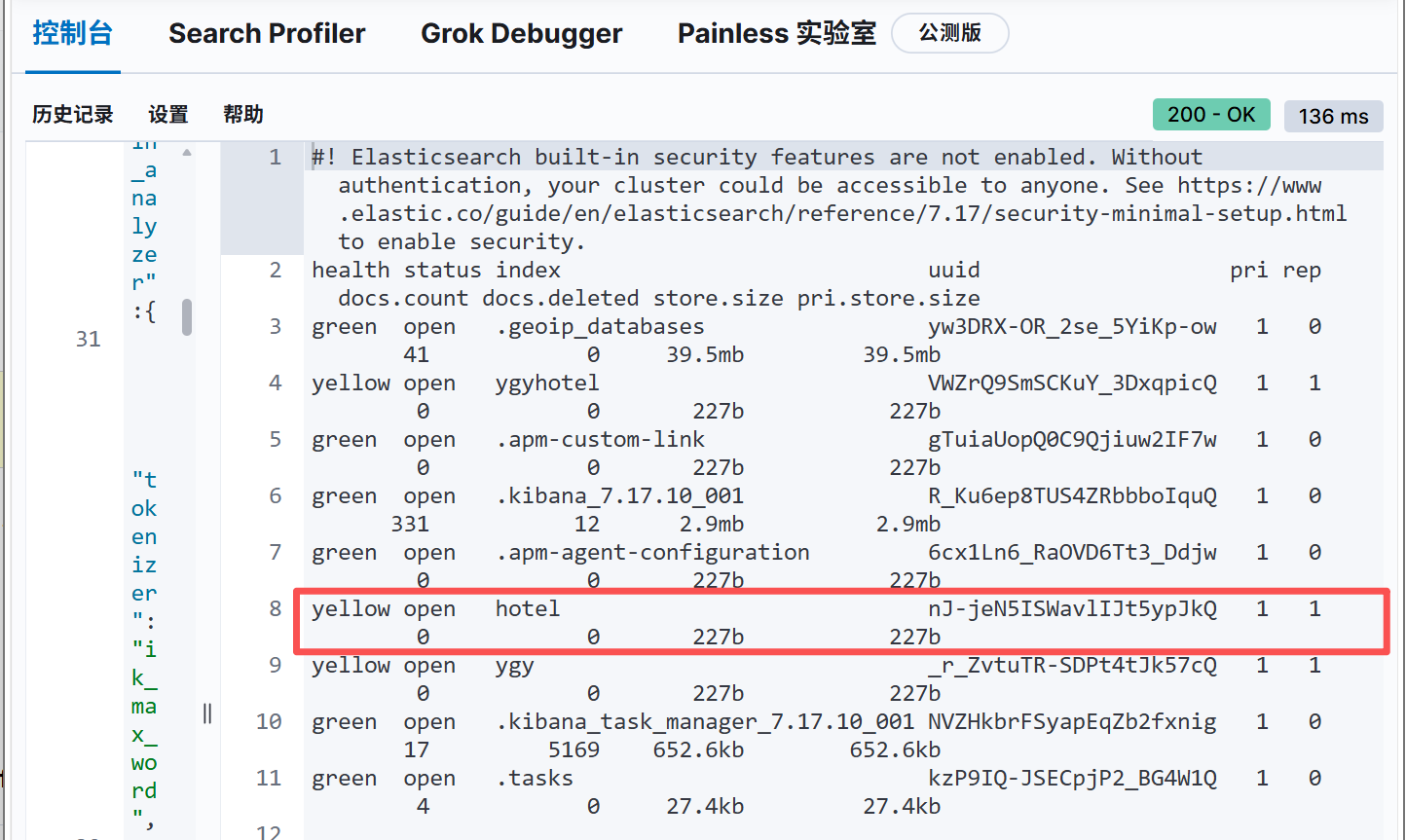
通过这个命令可以看到我们之前创建的索引
输出字段解释(看懂结果)
| 字段名 | 含义 |
|---|---|
| health | 索引健康状态(green/yellow/red) |
| status | 索引状态(open/close) |
| index | 索引名称(你能看到 hotel) |
| docs.count | 索引中文档总数 |
| store.size | 索引占用存储空间 |
查看单个索引
bash
GET /hotel通过这个语句可以查看我们单个索引的情况
修改索引
索引和Mapping一旦创建无法修改,但是可以添加新字段。简单来说不能修改以有字段,可以通过/PUT请求添加新字段
bash
PUT /hotel/_mapping
{
"properties":{
"business":{
"type":"keyword"
}
}
}删除索引
bash
DELETE /hotel如果我们删除后没有备份怎么办,我们可以在Kibana中会记录你的DSL语句的执行的,我们可以找到对应的历史记录进行恢复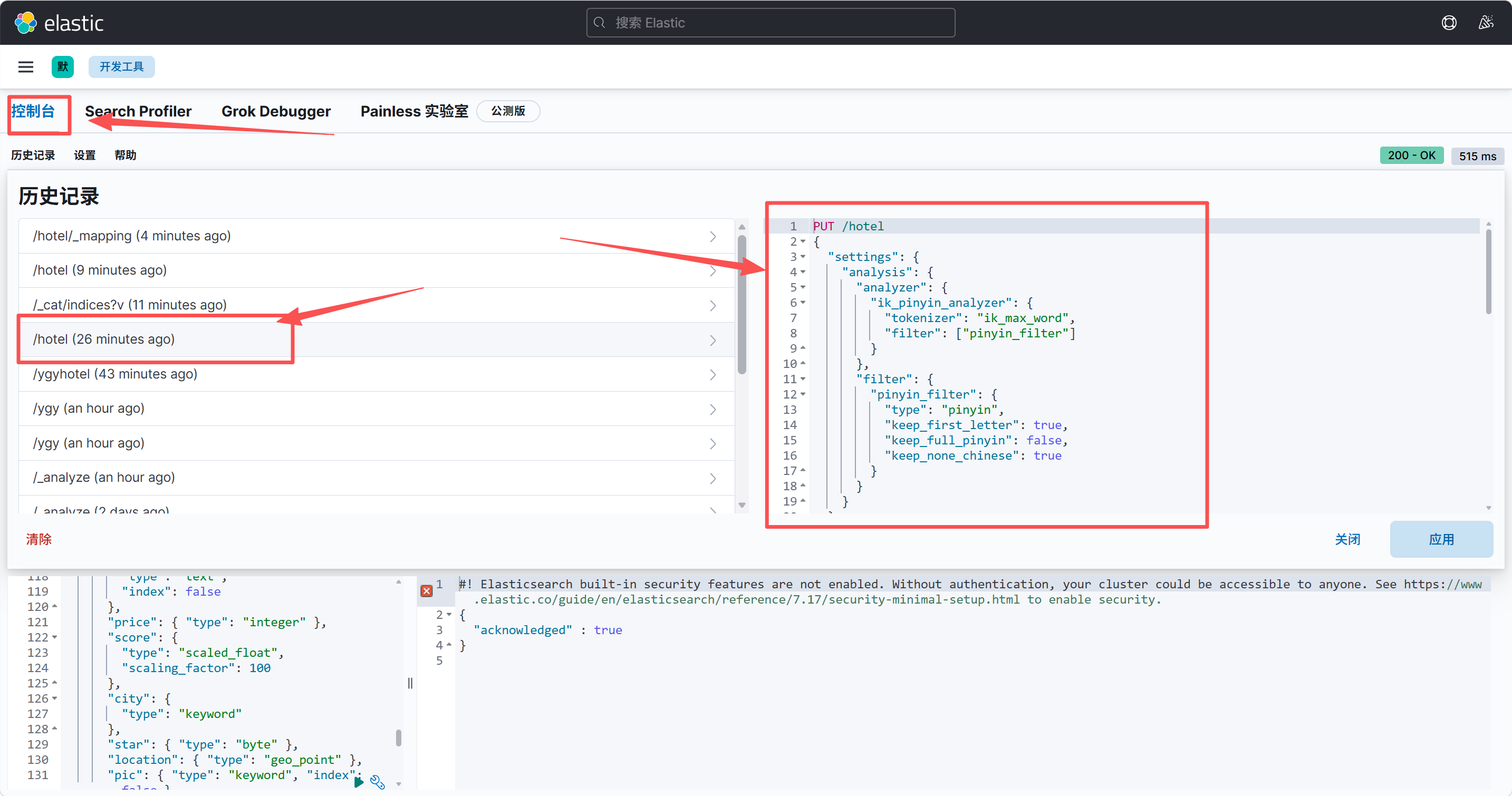
ES文档操作
建立好索引我们就可以开始添加数据了,ES中数据以文档的形式存在
添加文档
要创建一个新文档在es7之前通常需要指定类型即/indexName/type/_doc/id,在es7之后type部分被移除直接使用/indexName/_doc/id
例如,按照数据库中第一条酒店信息,创建一个ID为1的文档到hotel索引中:
bash
PUT /hotel/_doc/1
{
"id": "1",
"name": "北京希尔顿酒店",
"brand": "希尔顿",
"address": "北京市朝阳区建国门外大街1号",
"price": 1280,
"score": 4.98,
"city": "北京",
"star": 5,
"location": "39.9042,116.4074",
"pic": "https://xxx.com/hotel/1.jpg"
}运行效果如图:
如果我们不指定ID则ES会自动生成一个ID与新增文档对应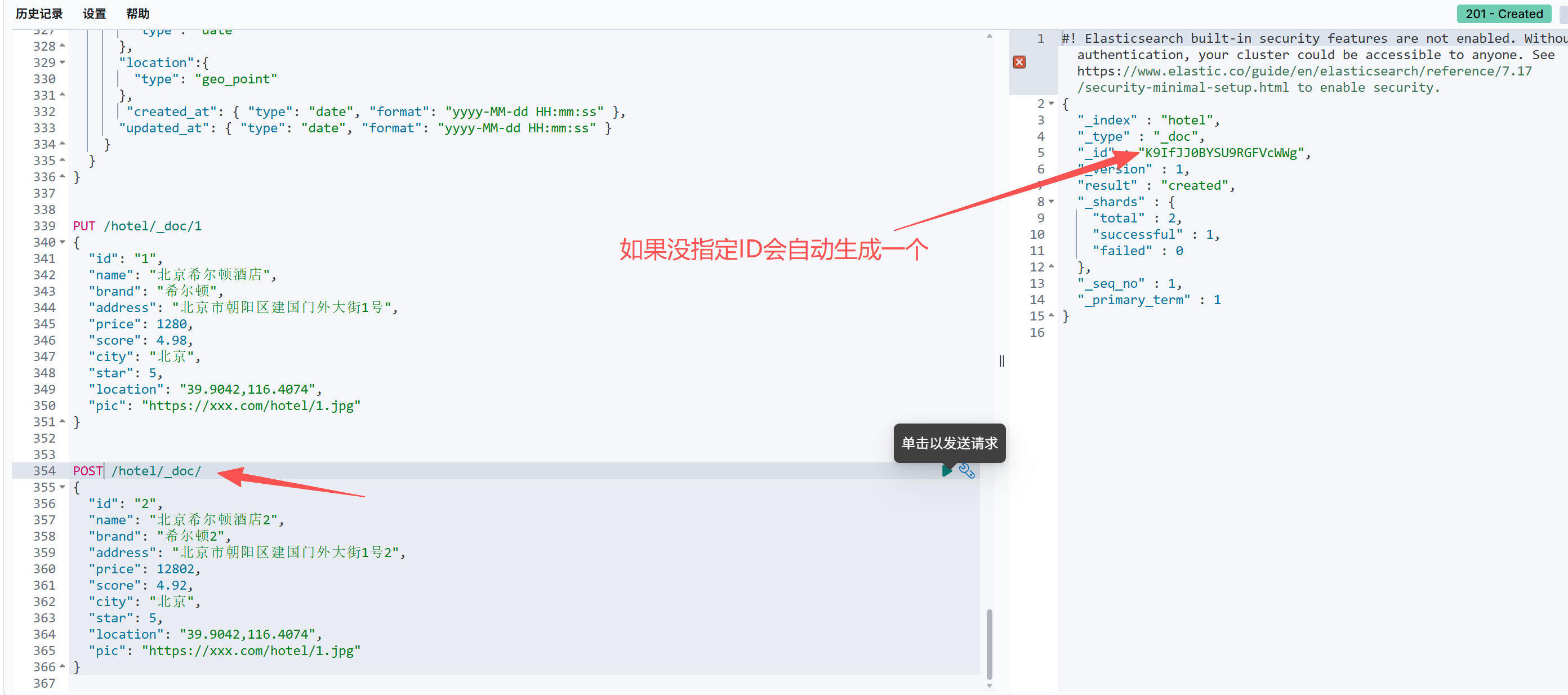
查看文档
根据ID搜索文档
在已知文档ID的情况下,我们可以通过ID去查找,DSL如下:
bash
GET /hotel/_doc/1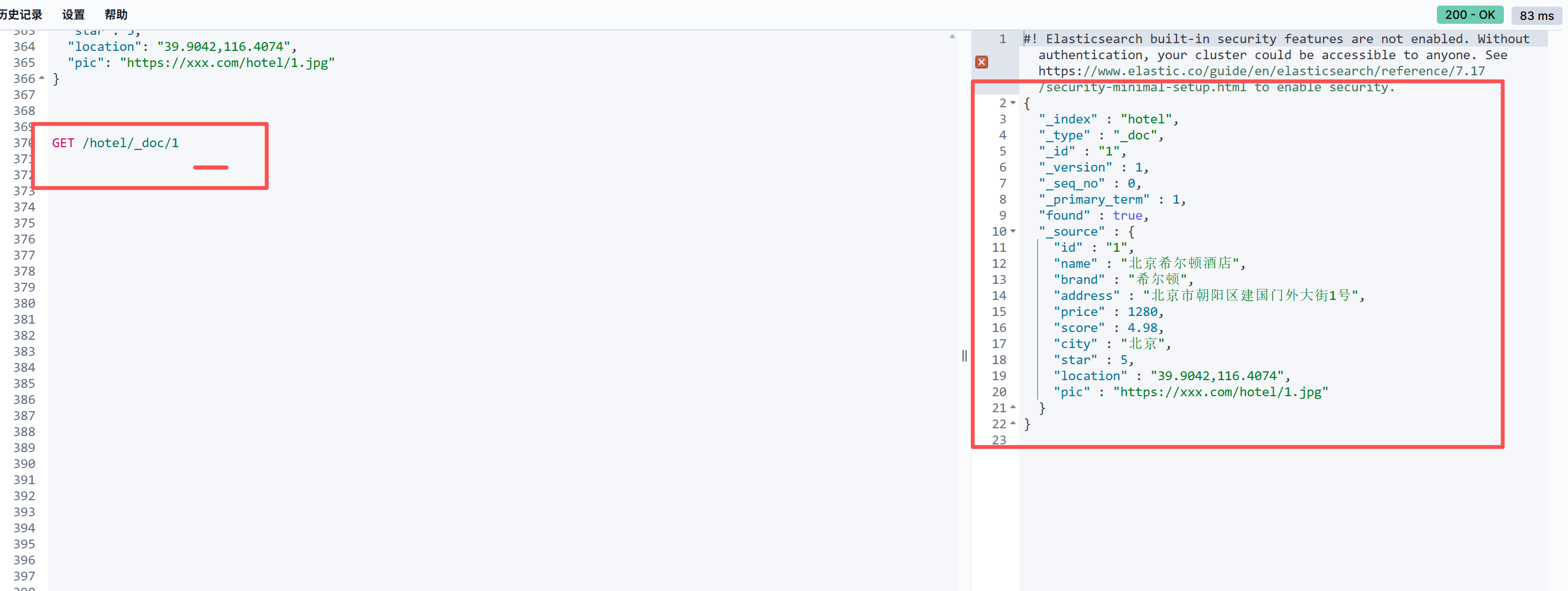
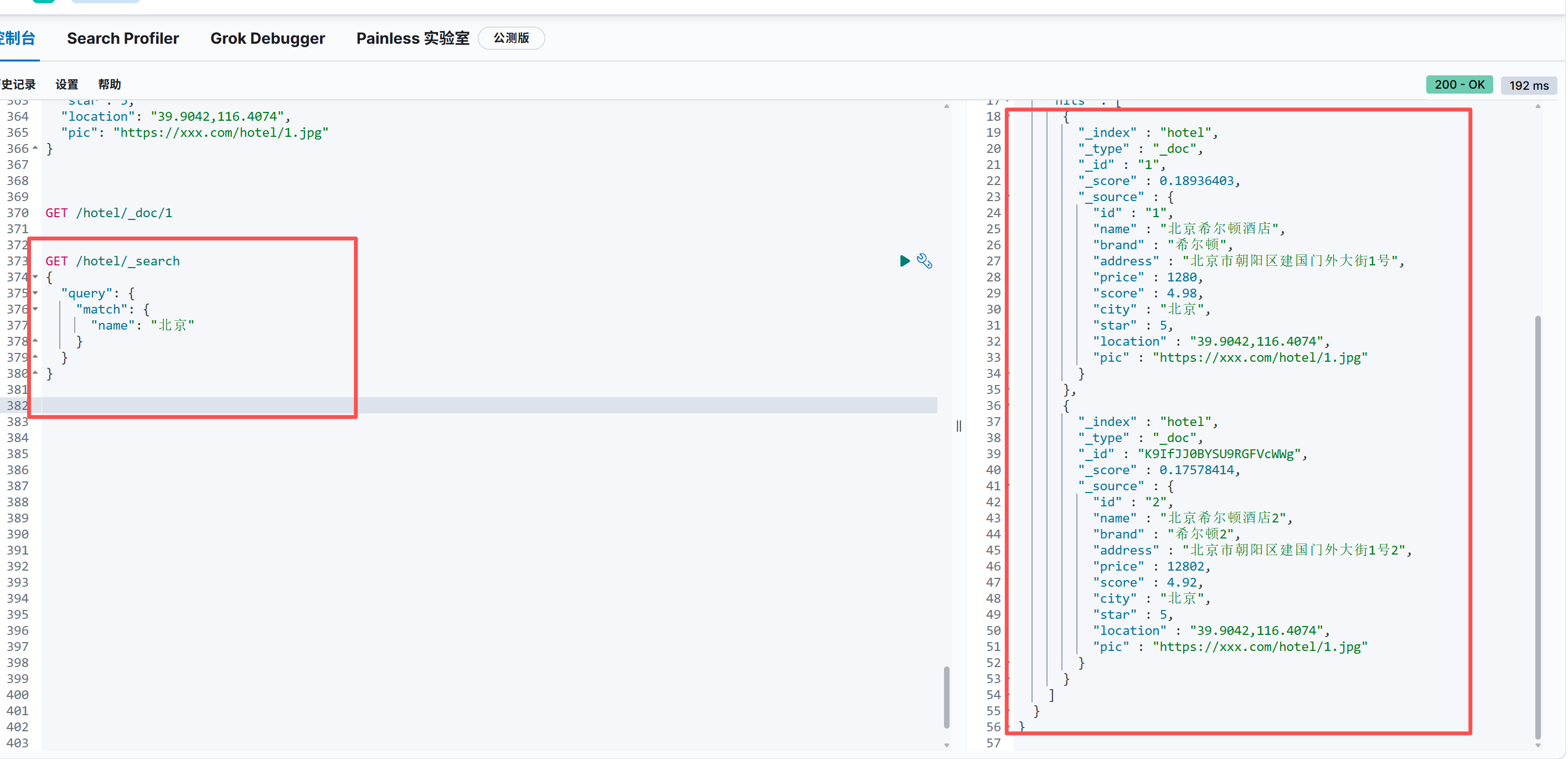
条件搜索
使用 Elasticsearch 搜索接口 _search:
bash
GET /hotel/_search
{
"query": {
"match": {
"name": "北京"
}
}
}
修改文档
在 Elasticsearch 中修改文档有**两种常用方式,**分两种:全量替换(PUT)和部分更新(POST _update)
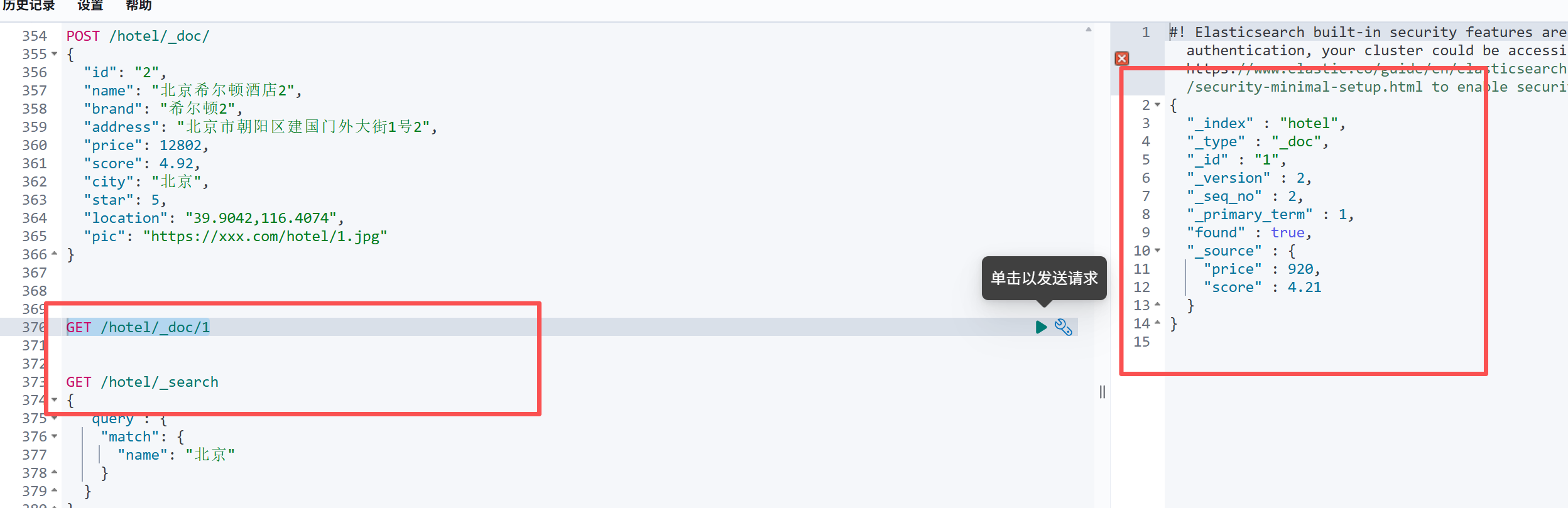
1. 全量替换(覆盖整个文档)
用新数据完全覆盖 旧文档,字段少写会丢失数据,谨慎使用:
bash
PUT /hotel/_doc/1
{
"price":920,
"score":4.21
}
执行完成之后我们来查询一下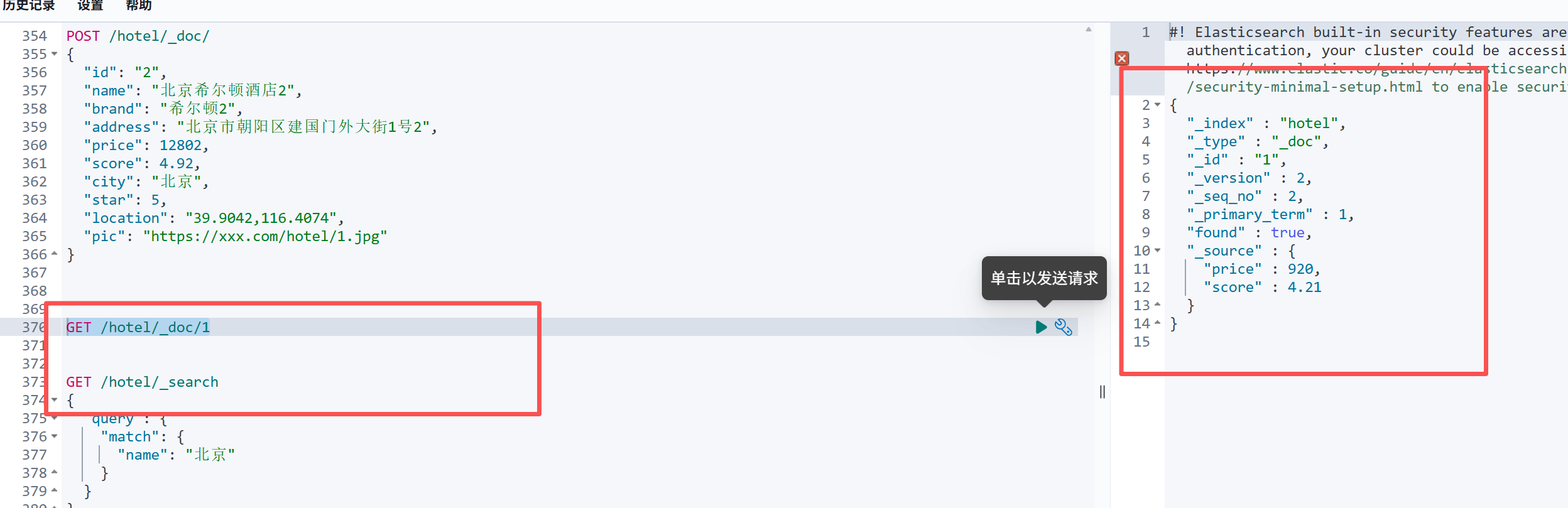
可以发现现在只要两个字段了其他字段都被置空了
2.推荐:部分更新(只改指定字段,最安全)
只修改你想改的字段,其他字段保留不变,日常开发首选!
bash
POST /hotel/_update/1
{
"doc":{
"city":"南昌"
}
}运行查看结果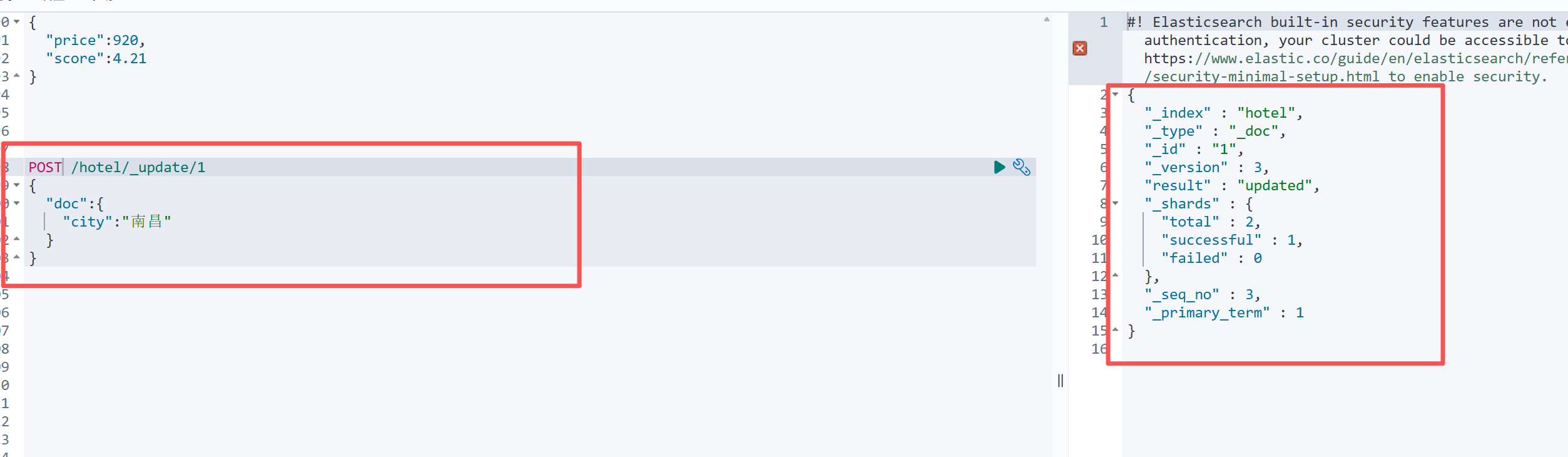
我们再次查询id为1的文档
可以发现文档数据新增了一个字段而不是覆盖了
删除文档
bash
DELETE /hotel/_doc/1删除操作也会使版本号自增
Logstash数据同步
Logstash 是 Elastic Stack(ELK Stack) 中的核心组件之一,由 Elastic 公司开发,是一款开源的数据收集、处理、转发工具 。它的核心定位是数据管道(Data Pipeline) ,可以从任意来源 读取数据,经过清洗、转换、 enrichment 等处理后,发送到任意目标存储 / 分析系统中。
我们常说的 ELK 栈,指的就是 Elasticsearch(存储 / 检索)+ Logstash(数据处理)+ Kibana(可视化),后续还加入了 Beats(轻量数据采集器),演变为 EFK/ELastic Stack。
一、核心工作流程:三个核心阶段
Logstash 的数据流转遵循固定的三步模型,也是它的核心设计逻辑:
- 输入(Input):从数据源读取数据(文件、数据库、日志、消息队列、API 等)
- 过滤(Filter):对数据进行清洗、转换、格式化(分词、脱敏、格式转换、 enrich enrich 等)
- 输出(Output):将处理后的数据发送到目标系统(Elasticsearch、MySQL、Kafka、文件、API 等)
同时还支持 编解码(Codecs) 插件,用于处理 JSON、CSV、日志行等不同格式的数据。
二、Logstash 有什么用?核心应用场景
结合你的酒店数据、Elasticsearch 场景,以及通用业务场景,Logstash 的核心作用分为以下几类:
场景 1:数据库 → Elasticsearch 数据同步(你的核心需求)
这是最常用的场景之一,尤其适合关系型数据库(MySQL/Oracle) 与 Elasticsearch 之间的全量 / 增量同步。
- 你的酒店数据存在 MySQL 中,需要同步到 ES 的
hotel索引供搜索使用; - Logstash 可以通过
jdbc插件读取 MySQL 数据,经过简单处理后,直接写入 ES; - 支持定时同步(增量 / 全量),实现数据库与 ES 的数据一致性。
三、安装Logstash
1.准备安装包需要Logstash以及mysql的安装包
可以直接通过wget方式下载:
bash
# 下载RPM包
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.10-x86_64.rpm
# 安装
rpm -ivh logstash-7.17.10-x86_64.rpm我已经有对应安装包直接导入到文件夹中
2. 安装后默认路径(牢记!)
- 主目录:
/usr/share/logstash/ - 配置目录:
/etc/logstash/ - 服务配置:系统自带
systemctl管理
3.放置 MySQL 驱动包
1. 创建驱动目录
bash
mkdir -p /usr/share/logstash/drivers2. 上传 / 移动 MySQL 驱动
把你的 mysql-connector-java-8.0.30.jar 放到该目录
bash
# 如果你驱动在/usr/local,直接移动(你之前的操作)
mv /usr/local/mysql-connector-java-8.0.30.jar /usr/share/logstash/drivers/
# 验证驱动是否存在
ls /usr/share/logstash/drivers/4.编写 MySQL 同步 ES 配置文件(最终可用版)
Logstash 服务默认读取配置路径 :/etc/logstash/conf.d/
1. 创建配置文件
bash
vi /etc/logstash/conf.d/mysql_to_es.conf2. 粘贴完整配置
bash
# 输入:MySQL数据源
input {
jdbc {
# MySQL连接地址(同服务器用127.0.0.1)
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/你的数据库名?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
# MySQL账号密码
jdbc_user => "root"
jdbc_password => "你的MySQL密码"
# 驱动路径(固定!)
jdbc_driver_library => "/usr/share/logstash/drivers/mysql-connector-java-8.0.30.jar"
# 新版驱动类(消除警告)
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# 要同步的表(替换成你的真实表名)
statement => "SELECT * FROM 你的表名"
# 同步频率:每分钟同步一次
schedule => "*/1 * * * *"
}
}
# 输出:Elasticsearch
output {
elasticsearch {
# ES地址
hosts => ["http://127.0.0.1:9200"]
# ES索引名(自定义,自动创建)
index => "hotel"
# 用MySQL主键id作为ES文档ID(避免重复)
document_id => "%{id}"
}
# 控制台打印日志(调试用)
stdout {
codec => rubydebug
}
}3. 必须修改 3 个地方
你的数据库名→ MySQL 真实库名你的MySQL密码→ MySQL root 密码你的表名→ MySQL 真实表名
4. 保存退出
ESC → :wq 回车
5.配置权限
bash
# 给Logstash目录赋权(esuser专用)
chown -R esuser:esuser /usr/share/logstash/
chown -R esuser:esuser /etc/logstash/
chmod -R 755 /usr/share/logstash/6、测试配置文件(检查语法,必做)
bash
# 切换esuser
su - esuser
# 测试配置语法
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/mysql_to_es.conf -t✅ 出现 Configuration OK = 配置完全正确
七、系统服务化部署(你要的 systemctl 管理)
1. 启动 Logstash 服务
bash
systemctl start logstash2. 设置开机自启(重启服务器自动运行)
bash
systemctl enable logstash3. 查看运行状态(最终验证)
bash
systemctl status logstash✅ 显示 active (running) = 服务启动成功!
8、验证数据同步(最终测试)
1. 查看 ES 索引数据
bash
curl http://127.0.0.1:9200/hotel/_search?pretty✅ 能看到 MySQL 里的数据 = 同步成功!
2. 实时查看 Logstash 日志(排错用)
journalctl -u logstash -f