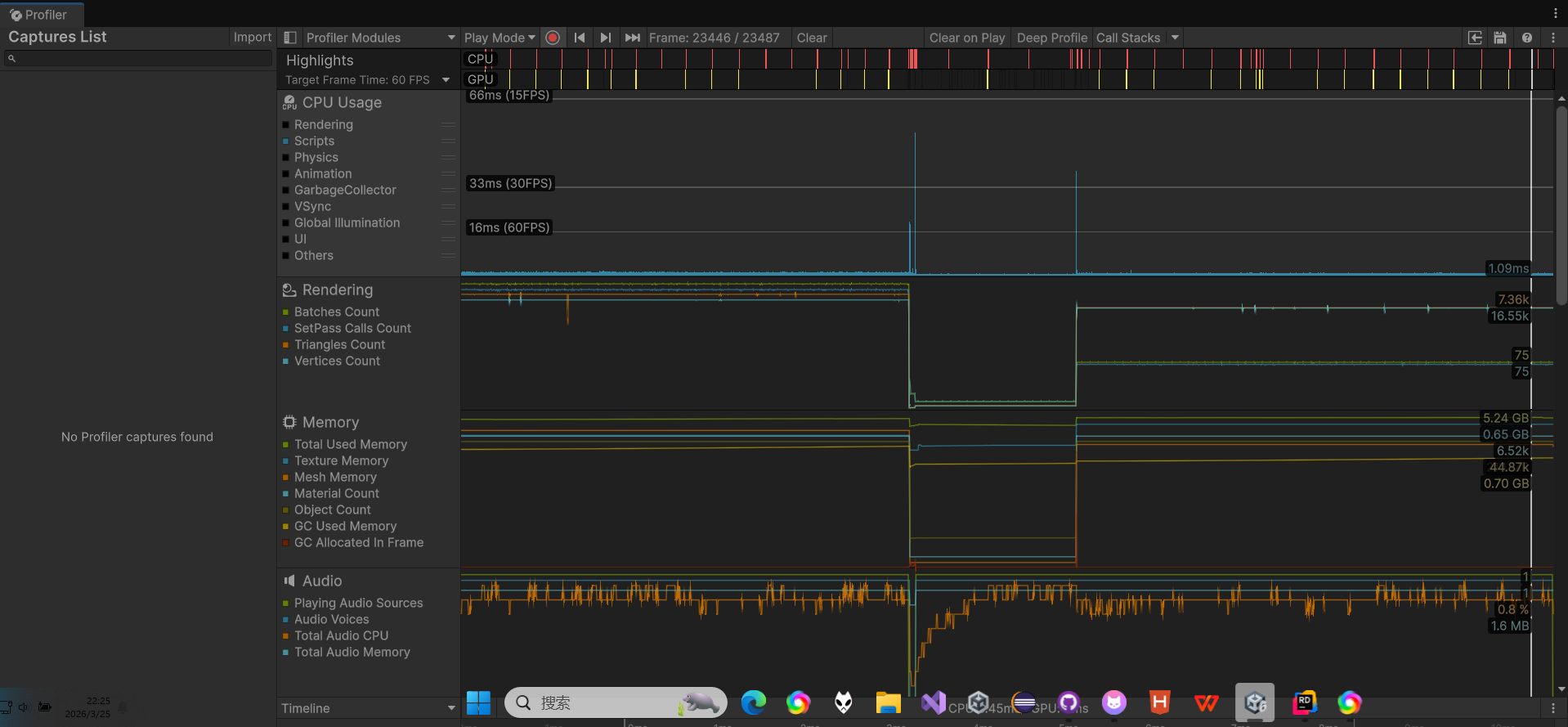
Unity自带的视锥体剔除
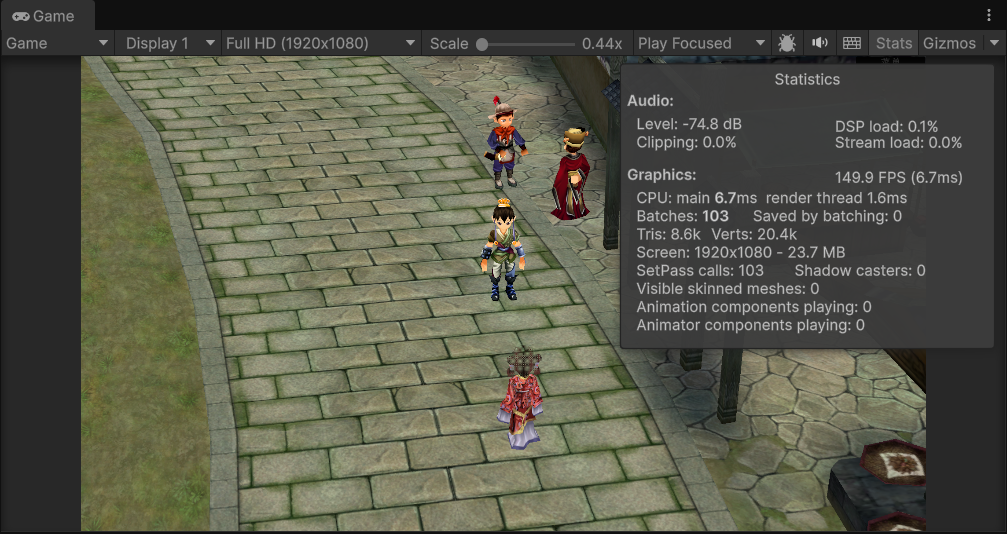
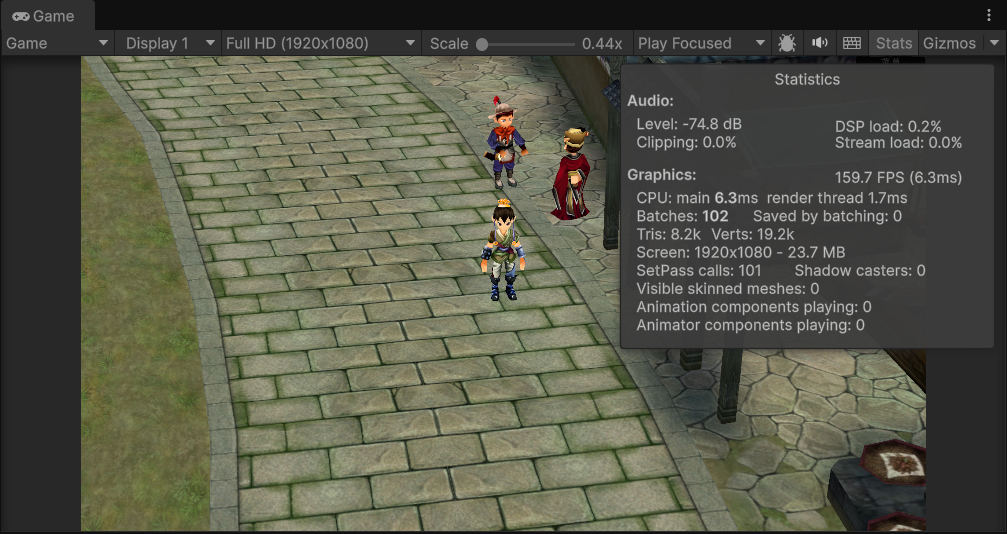
这里可以看到,在NPC走出我们视野范围的时候,渲染的顶点Verts和DrawCall提交次数Batches都减少了,这是Unity中自动为我们做的视锥体剔除。(在场景预览中仍然能看见整个场景,这是因为场景摄像机和游戏摄像机进行互相独立的剔除)
Batches:
这里Batches指的是CPU每次下达渲染命令的一个DrawCall,也就是一个批次,如果Batches过高会导致出现CPU瓶颈,即使GPU性能再高也只能等待CPU下达渲染指令。
而SaveBatches是Unity的合批技术,可以将多个DrawCall指令优化成一个:
静态合批 :如果场景中的物体是Static的,那么Unity就会在加载之前将多个物体的Mesh整合成一个Mesh。
GPU Instancing :如果开启,那么所有重复物体会使用同一套顶点数据来进行渲染。
材质球合并:同一个材质球的物体会进行合批,但是因为老游戏每一个物体都有一个独立的材质球,所以无法进行合批,要解决的话必须将同一个文件夹下的模型贴图打包成一张大纹理集 (Texture Atlas),并强制它们使用同一个 Shader 材质实例
Unity中的视锥体剔除依赖于物体的AABB包围盒,每一个物体的Renderer(MeshRenderer)都会持有一个Bounds,这个Bounds是通过Mesh.Bounds来进行计算的,如果物体上的MeshRenderer是通过代码来挂载的,那么必须调用meshComponent.Mesh.RecalculateBounds();Unity才会进行包围盒的重新计算,即使重新设置了顶点。所以我们在初始化模型的时候我们要重新计算包围盒。但是在初始化的时候有这样一段代码:
cs
if (triangles != null)
{
// 这里只是单材质网格
mesh.SetTriangles(triangles, 0);
}
if (triangles == null)
{
mesh.RecalculateBounds();
}这是因为SetTriangles会触发Unity重新计算包围盒,所以只有在IndexBuffer为空的时候才需要进行包围盒的重新计算。
这里又要提到Renderer.Bounds和Mesh.Bounds的区别,Mesh.Bounds是静态的,基于角色模型本身的包围盒,而Renderer.Bounds是在运行时计算的,在世界空间下的包围盒,每当GameObject的位置发生了变化,那么Unity就会通知底层的Renderer组件对Renderer.Bounds进行重新计算,自动的视锥体剔除就是基于这个来实现的。
值得一提的是,源代码在每次执行动画时都重新计算了包围盒,开销是很大的,这实际上是不需要的,我们只需要将每一帧顶点动作包围盒的并集作为包围盒的静态数值即可,不必每次更新
视锥体剔除的底层逻辑
在执行渲染逻辑的时候,每次都会将摄像机的6个视锥体平面与GameObject的AABB包围盒的8个顶点进行点乘测试,来判断物体是否处于视锥体中。只要AABB完全处于任意一个平面外,那么就放弃渲染。
当你把一个带有 MeshRenderer 的 GameObject 放到场景里,Unity 在底层的 C++ 核心(Native 层)到底做了什么?
- 动态包围体层次树 (DBVH)
在 C++ 层,Unity 维护了一棵极其高效的动态包围体层次树(Dynamic Bounding Volume Hierarchy, DBVH)。
- 每当你的物体 Transform 发生位移,C++ 层会重新计算它的世界空间 AABB(Axis-Aligned Bounding Box,轴对齐包围盒),并更新这棵树。(这也就是为什么在 Update 里疯狂移动大量物体会导致 CPU 开销飙升,因为底层的 DBVH 树在疯狂重构)。
- 提取视锥体平面
在渲染每一帧(Render Loop)开始时,引擎会拿到当前摄像机的 VP 矩阵(View-Projection Matrix) 。
通过极其廉价的矩阵运算,引擎直接提取出视锥体的 6 个平面方程(上下左右前后,方程式为 Ax + By + Cz + D = 0)。
- 暴力的 SIMD 矩阵相交测试
这是现代引擎碾压手写 C# 代码的核心。
Unity 的底层 C++ 核心将这些 AABB 数据在内存中连续紧凑排列(Data-Oriented Design) 。
然后,C++ 工作线程(Worker Threads)利用 CPU 的 SIMD 指令集(如 AVX/SSE)。
- C++ 并行思维 :它不是一个一个去算,而是利用一条 CPU 指令(如 _mm256_cmp_ps),**同时将 8 个物体的 AABB 与视锥体平面进行相交测试,**如果判定在视锥体外,这个物体就会被直接标记为 Culled。此外还有多线程并行。
- 提交渲染队列
只有通过了剔除测试的物体,它们底层的 C++ 指针才会被收集起来,按照材质(Material)排序后,作为 Draw Call 提交给图形 API(如 DirectX 11 / Vulkan / OpenGL)。
既然Unity已经帮我们做好了视锥体剔除,那么我们为什么还需要额外写代码?
因为Unity只是剔除了渲染,而没有剔除GameObject的运行逻辑,这就是我们接下来要做的优化:视锥体逻辑休眠
而且Unity在进行计算的时候是遍历整个场景的所有物体进行计算,而基于八叉树的视锥体剔除实际上就是将整个场景划分为若干小空间,每个空间中有若干物体,在计算时只计算空间的8个顶点,只要空间不在视锥体内,那么就放弃整个空间内物体的渲染。八叉树实际上就是将空间递归划分为8个子节点,每个节点需要维护顶点及GameObject信息,这在NPC频繁移动时就需要频繁修改树状结构,所以八叉树现在多用于空间零散的大型开放世界中。
但实际上遍历计算可能性能比八叉树更好,这是因为树状结构的访问特性导致的,树状结构的节点在内存中是碎片化的,每次使用指针跳转都会导致Cache Miss。
Cache Miss
CPU缓存是位于CPU和主内存(RAM)之间的一种高速、小容量的存储器。它的作用是缓存CPU近期可能访问的数据和指令,以弥补CPU和主内存之间巨大的速度差异。
- 缓存命中(Cache Hit):CPU需要的数据正好在缓存中,可以极速获取。
- 缓存未命中(Cache Miss):CPU需要的数据不在缓存中,必须从慢得多的主内存中加载,这个过程会造成CPU流水线停顿,性能急剧下降。一次Cache Miss的延迟可能是几百个时钟周期,而Cache Hit只需要几个。
当用指针查找树节点时,Cache Miss的发生过程如下:
- 访问父节点 :假设CPU正在访问节点A。它会先检查节点A的数据是否在L1缓存中。
- 如果不在(Cold/Compulsory Miss) :CPU会从主内存中加载节点A所在的整个缓存行(Cache Line) (通常是64字节)到L1缓存。这个缓存行不仅包含节点A的数据(
data,left,right指针),还包含了节点A内存地址附近的其他数据。
- 如果不在(Cold/Compulsory Miss) :CPU会从主内存中加载节点A所在的整个缓存行(Cache Line) (通常是64字节)到L1缓存。这个缓存行不仅包含节点A的数据(
- 跟随指针 :为了找到子节点B,CPU需要读取节点A中的
left或right指针,获取子节点B的内存地址。 - 访问子节点 :CPU拿着子节点B的地址去缓存里找。由于节点B和节点A在内存中是不连续的、零散的 ,节点B极大概率不在刚刚加载的那个缓存行中,甚至不在L1、L2、L3任何一级缓存里。
- 发生Cache Miss:此时,就会发生一次Cache Miss。CPU被迫暂停当前操作,向主内存发出请求,去加载节点B所在的缓存行。这个等待过程非常漫长。
- 恶性循环:当你从节点B再访问它的子节点C时,同样的事情再次发生。每一次指针跳转,都极有可能引发一次新的Cache Miss。
核心原因总结:
- 缺乏空间局部性(Spatial Locality):这是最关键的原因。空间局部性原理指的是:如果一个数据被访问,那么它附近的数据也很可能被访问。数组是空间局部性的典范,一次加载一个缓存行可以服务于多次后续访问。而链式树结构通过指针跳转,访问的内存地址是随机的、不连续的,完全破坏了空间局部性。CPU预取(Prefetcher)机制也无法有效工作,因为它无法预测下一次跳转的地址。
- 指针本身的开销:访问一个节点不仅要加载节点数据,还要加载指针本身。如果指针指向的内存区域已经被缓存替换出去,就会引发未命中。
- 容量和冲突未命中 :当树非常大时,整个树的节点不可能全部放入缓存,这会导致容量未命中(Capacity Miss) 。同时,由于内存地址的映射机制,多个不相关的节点可能被映射到同一个缓存组(Cache Set),导致冲突未命中(Conflict Miss),即使缓存还有空余空间。
这里可以进行优化,如使用数组来模拟树状结构(二叉堆,B+树,B-树),通过内存池分配一段连续的空间。
视锥体逻辑剔除
值得一提的是,在对脚本生命周期的控制中,如果是挂载在GameObject上的MonoBehavior脚本,我们采用OnEnable和OnDisable来管理生命周期,而对于那些单例Manager,我们使用构造函数和Dispose来管理生命周期。在我们的逻辑休眠中,OnEnable充当暂停和恢复的角色,而Dispose则负责在程序完全关闭时进行垃圾回收。
在Unity中如果对一个GameObject调用SetActive(false),Unity会对这个物体挂载的所有脚本调用OnDisable并且禁用所有组件,并将物体移除渲染队列(包括子物体)。在Unity中这个物体相当于被标记为不存在,需要重新构建整个场景的场景树,而且重新SetActive(true)也会调用所有脚本的OnEnable,这就是为什么不建议对GameObject进行频繁的SetActive,有极大的性能开销。
而我们这里模型的具体渲染逻辑是在主逻辑脚本中进行AddComponent加入具体类型的模型Renderer来实现的,所以我们更不应该将所有的脚本OnDisable,而应该只将主逻辑脚本enbale设置为false。(实际上在我们当前的项目中也不能简单的将一个脚本设置为false,因为在OnEnbale的时候会将所有状态清理掉,应该将isActivate和isVisible的逻辑进行解耦)
这里因为GameActor只负责存储Actor的信息,Scene负责管理整个场景的物体(包括Actor),而ActorController不执行任何具体的逻辑,只控制角色的Active与否,并且保存有Actor移动和渲染逻辑的组件,所以应该将其作为ILogicCullable接口的实现者。
讲讲整个项目的场景加载逻辑,SceneManager负责将Scene挂载在场景物体上,Load具体的场景文件来创建场景,再TryAddSceneScript挂载对应的场景SceFile脚本。Scene中会分开创建场景物件和场景角色。这里所有的场景创建只复用Material纹理(还未实现),在加载新场景时都是简单的销毁整个场景,再重新加载新的场景。所以这里所有加载脚本都是在OnDisable的时候就销毁所有的状态(在OnDisable时就当作物体被销毁),这就是为什么要将isActivate和isVisible的逻辑进行解耦。
*
后续可以实现LeastResentlyUsed队列缓存场景,将OnDisable中的销毁逻辑转移到OnDestroy中,然后使用SetActive来实现对场景的复用。但是原游戏中场景的跳转是使用SceneLoad指令来实现的(现在实现的SceneLoad指令会销毁当前场景),而且场景的重新生成逻辑不由OnEnable来控制,由于这两点的存在,我们想要实现场景的复用就变得非常困难了,有机会再来尝试实现吧。
突然意识到一个有意思的事情,我们在创建物体的时候,一般都是父物体持有子物体的实例(非继承关系),这样父物体可以随意调用子物体的函数,而如果子物体需要调用父物体的函数怎么办呢?这时候就需要用到委托???使用静态工具类就无法实现这种效果???
Gemini:你的直觉非常敏锐! 你意识到的这个问题,在软件工程中有一个非常经典的总结:"自顶向下是方法调用,自底向上是事件派发(委托)。"
cs
public class Child
{
public Action OnConditionMet;
void Update() {
if (条件满足) OnConditionMet?.Invoke();
}
}父类(非继承关系)只需child.OnConditionMet += ParentMethod进行注册,那么子类就可以调用父类的函数了(子类不应该持有父类的实例,会造成依赖循环)
而对于静态类的问题,静态类有且仅有两个特点:全局共享 和 无状态(无实例上下文) ,最多只能够实现广播**,** 要实现父子之间的精准通信,必须依赖具体的实例(Instance) ,而委托(Delegate)本质上就是绑定了特定对象实例的函数指针。 所以原作者在这里几乎没有使用静态类,全部都是使用实例来进行显式依赖注入,这是对的**。
总结:**
-
向下通信(父管子): 直接调用方法(或修改属性)。因为上层应该掌控下层。
-
向上通信(子报父): 使用委托(Delegate / Action / C# Event)。因为下层不该知道上层的存在,保持自己的清白之身(高内聚低耦合)。
-
横向/跨模块通信: 两个毫无层级关系的系统通信(比如 UI 系统和 成就系统),才应该使用全局事件总线(EventBus / 消息中心 / 静态中介者)。
*(还没懂)
值得一提的是,在PolyMeshRenderer和StaticMeshRenderer等具体渲染类中,使用了OnDisable() { Dispose(); } 模式,这种模式,通常只出现在:
-
包含异步持续循环逻辑(Task/Coroutine/CancellationToken)的类。
-
持有大块非托管内存(Texture, Material, Mesh, ComputeBuffer)的类。
-
为了适配"对象池"反复重用,需要在"隐藏"时立刻卸载包袱的类。
本来想尝试使用Renderer.OnBecameVisible来实现逻辑剔除,但是因为Renderer并没有提供任何委托或事件,这让子类的Renderer组件向上传递,以及事件广播变的难以实现(有点复杂,需要额外添加一个类),在现代游戏中,使用DOTS实现数据与逻辑的解耦,而不是面向对象的层层传递,这时候就不需要面对层层的向上传递了。而且Renderer.OnBecameVisible过于依赖Renderer,暂时放弃。
使用CullingGroup进行LOD分级逻辑剔除
结果剔除完帧率没什么变化,因为角色的动画只是做简单的线性插值而已,CullingGroup的计算开销可能比节省下来的还要更多emmm,可能在NPC更多的场景下才会比较明显。
在剔除前后CPU的Script运行时间确实有显著提升,从2.7ms降到了1.7ms,但是因为瓶颈在Renderder,所以帧数变化不够明显。
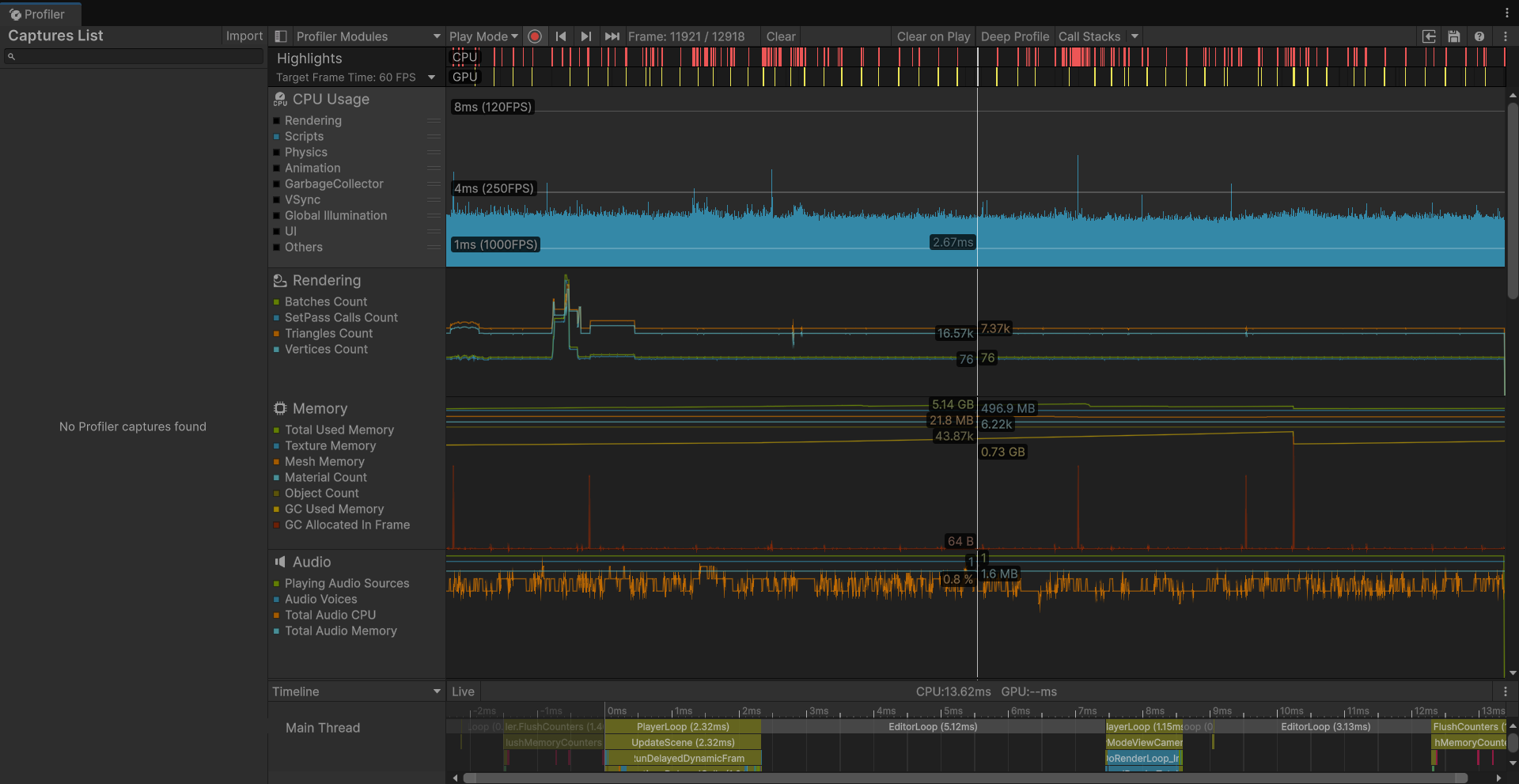
CullingGroup
CullingGroup维护一个BoundingSphere(包含位置与包围球半径)数组的指针(引用),这是一个共享的内存桥梁,没有任何的封送开销,这个数组中存储了所有可剔除的物体的包围球。为什么要用包围球?这是因为相对于传统的AABB包围盒8个顶点都需要做计算,球体包围盒的计算非常简单,计算球心到视锥体 6 个平面的距离,只要 距离 > -半径,球体就在平面内。
其中计算的时候使用了多线程异步的Job系统:
-
并行计算 :Unity 内部会将这 256 个(或更多)球体的判定逻辑包装成一个 C++ Job。
-
分发执行:这个 Job 会被分发到 CPU 的**工作线程(Worker Threads)**上运行,而不是卡在主线程。
-
运行频率:它与渲染帧同步。在相机渲染之前,Job 系统会批量算出所有球的状态。
-
结果回传:计算结果被写回另一个共享的位掩码(Bitmask)中
CullingGroup为每一个包围球存储了一个简单的整数,记录了isVisible (1 bit)和currentDistanceBand (几 bits),只有发生变化的时候才会通知委托。
LOD计算:
当你设置了 SetBoundingDistances:
-
参考点更新:如果你设置了 SetDistanceReferencePoint(Transform),底层每帧会通过该 Transform 拿到一个最新的坐标 P。
-
距离平方计算 :计算球心 C 到 P 的距离。为了优化性能,底层计算的是 距离的平方(Magnitude Squared),从而避开了开销巨大的**开放(Square Root)**运算。
-
区间二分查找:将计算出的平方距离与你设定的距离平方数组进行对比,确定它落在哪个序号(Index)里。
cs
public sealed class LogicalCullingManager : IDisposable
{
private CullingGroup _cullingGroup;
private BoundingSphere[] _boudingSpeheres;
private List<ILogicalCullable> _cullableObjects;
private UnityEngine.Camera _mainCamera;
private const int MAX_ACTOR_NUMBER = 256;
public LogicalCullingManager(UnityEngine.Camera mainCamera)
{
_mainCamera = mainCamera.IsNotNull(nameof(mainCamera));
// 预分配
_cullableObjects = new List<ILogicalCullable>(MAX_ACTOR_NUMBER);
_boudingSpeheres = new BoundingSphere[MAX_ACTOR_NUMBER];
_cullingGroup = new CullingGroup();
_cullingGroup.targetCamera = _mainCamera;
_cullingGroup.SetBoundingSpheres(_boudingSpeheres);
_cullingGroup.SetBoundingSphereCount(0); // 初始为 0
// 初始化参考点为摄相机,这里如果传入position,那么值永远不会被更新
_cullingGroup.SetDistanceReferencePoint(_mainCamera.transform);
// 自定义区间,因为使用相机为参考点,所以设置的大一点
_cullingGroup.SetBoundingDistances(new float[] { 80f,200f });
_cullingGroup.onStateChanged += OnCullingChanged;
}
public void Dispose()
{
_cullingGroup.onStateChanged -= OnCullingChanged;
_cullingGroup?.Dispose();
_cullingGroup = null;
}
}
cs
private void OnCullingChanged(CullingGroupEvent e)
{
ILogicalCullable cullableObject = _cullableObjects[e.index];
cullableObject.SetVisible(e.isVisible,e.currentDistance);
}每一个可剔除的物体都需要实现这个接口,使用SetVisible来控制物体是否可见,CullTransform用于更新包围球的位置。
cs
public interface ILogicalCullable
{
void SetVisible(bool isVisible,int lodLevel);
public Transform CullTransform { get; }
}这里只有Actor实现了这个接口。
cs
public void SetVisible(bool isVisible, int lodLevel)
{
// 无论什么时候,看不见就停止动画
bool shouldAnim = isVisible;
if (shouldAnim)
{
_actionController.RestartAnimation();
}else
{
_actionController.StopAnimation();
}
// TODO:动画质量:设置跳帧频率
// _actionController.SetLOD(lodLevel);
// 在0层级(0-80m)继续自动寻路
bool shouldMove = isVisible || lodLevel == 0;
_movementController.IsMovable = shouldMove;
}在OnEnable的时候需要使用Register进行注册
cs
//ActorActionController.cs
private void OnEnable()
{
_logicalCullingManager = ServiceLocator.Instance.Get<LogicalCullingManager>();
_logicalCullingManager.Register(this);
CommandExecutorRegistry<ICommand>.Instance.Register(this);
}
// ILogicalCullingManager.cs
public void Register(ILogicalCullable cullableObject)
{
int index = _cullableObjects.Count;
_cullableObjects.Add(cullableObject);
// 因为包围盒的获取依赖于Renderer,所以我们这里直接设置一个较大的默认值
_boudingSpeheres[index] = new BoundingSphere(cullableObject.CullTransform.position, 2.0f);
_cullingGroup.SetBoundingSphereCount(_cullableObjects.Count);
}因为我们维护的BoundsSphere是静态的,不会自动更新包围盒的位置,所以我们需要在LateUpdate中更新位置
cs
public void LateUpdate(float deltaTime)
{
for (int i = 0; i < _cullableObjects.Count; i++)
{
_boudingSpeheres[i].position = _cullableObjects[i].CullTransform.position;
}
}但是这样子写会有巨大的性能开销:
-
接口的虚函数调用(Virtual Dispatch):_cullableObjectsi 是一个接口(ILogicalCullable),通过接口调用属性 CullTransform 比直接调用类的方法要慢得多(因为需要查虚函数表)。
-
List<T> 的边界检查:每次通过 i 访问 List,C# 底层都会做一次安全检查(看索引有没有越界)。
-
C# 到 C++ 的跨界调用(P/Invoke) :访问 .position 会穿越 C# 托管堆,去 Unity 底层的 C++ 内存中读取数据。这是这行代码里最耗时的部分。
在极其频繁的循环(如每帧遍历几百次的 Update)中,绝对不要出现接口调用(Interface)、GetComponent、属性读取(Getter)和闭包(Lambda)。
优化后的代码:
cs
namespace Game.LogicalCulling
{
public sealed class LogicalCullingManager : IDisposable
{
private CullingGroup _cullingGroup;
private BoundingSphere[] _boudingSpeheres;
// 【优化1】将 List 换成原生数组,消除边界检查开销
private ILogicalCullable[] _cullableObjects;
// 【优化2】额外维护一个专门存 Transform 的数组,避开接口调用
private Transform[] _cachedTransforms;
// 记录当前实际的 Actor 数量
private int _activeCount = 0;
private UnityEngine.Camera _mainCamera;
private const int MAX_ACTOR_NUMBER = 256;
public void LateUpdate(float deltaTime)
{
// 【优化3】将全局变量提到局部变量,帮助 JIT 编译器进行循环展开和寄存器优化
int count = _activeCount;
// 【优化4】直接遍历原生数组,没有任何多余的函数调用
for (int i = 0; i < count; i++)
{
_boudingSpeheres[i].position = _cachedTransforms[i].position;
}
}
public LogicalCullingManager(UnityEngine.Camera mainCamera)
{
_mainCamera = mainCamera.IsNotNull(nameof(mainCamera));
// 预分配
_cullableObjects = new ILogicalCullable[MAX_ACTOR_NUMBER];
_cachedTransforms = new Transform[MAX_ACTOR_NUMBER];
_boudingSpeheres = new BoundingSphere[MAX_ACTOR_NUMBER];
_cullingGroup = new CullingGroup();
_cullingGroup.targetCamera = _mainCamera;
_cullingGroup.SetBoundingSpheres(_boudingSpeheres);
_cullingGroup.SetBoundingSphereCount(0); // 初始为 0
// 初始化参考点为摄相机,这里如果传入position,那么值永远不会被更新
_cullingGroup.SetDistanceReferencePoint(_mainCamera.transform);
// 自定义区间,因为使用相机为参考点,所以设置的大一点
_cullingGroup.SetBoundingDistances(new float[] { 80f,200f });
_cullingGroup.onStateChanged += OnCullingChanged;
}
public void Register(ILogicalCullable cullableObject)
{
if (_activeCount >= MAX_ACTOR_NUMBER)
{
Debug.LogError("超过最大值,请扩容MAX_ACTOR_NUMBER");
return;
}
_cullableObjects[_activeCount] = cullableObject;
// 在这里就把 Transform 存下来,避免调用接口虚函数查询开销
_cachedTransforms[_activeCount] = cullableObject.CullTransform;
// 因为包围盒的获取依赖于Renderer,所以我们这里直接设置一个较大的默认值
_boudingSpeheres[_activeCount] = new BoundingSphere(cullableObject.CullTransform.position, 2.0f);
_activeCount++;
_cullingGroup.SetBoundingSphereCount(_activeCount);
}
private void OnCullingChanged(CullingGroupEvent e)
{
ILogicalCullable cullableObject = _cullableObjects[e.index];
cullableObject.SetVisible(e.isVisible,e.currentDistance);
}
public void Dispose()
{
_cullingGroup.onStateChanged -= OnCullingChanged;
_cullingGroup?.Dispose();
_cullingGroup = null;
}
}
}优化后能到1.4ms
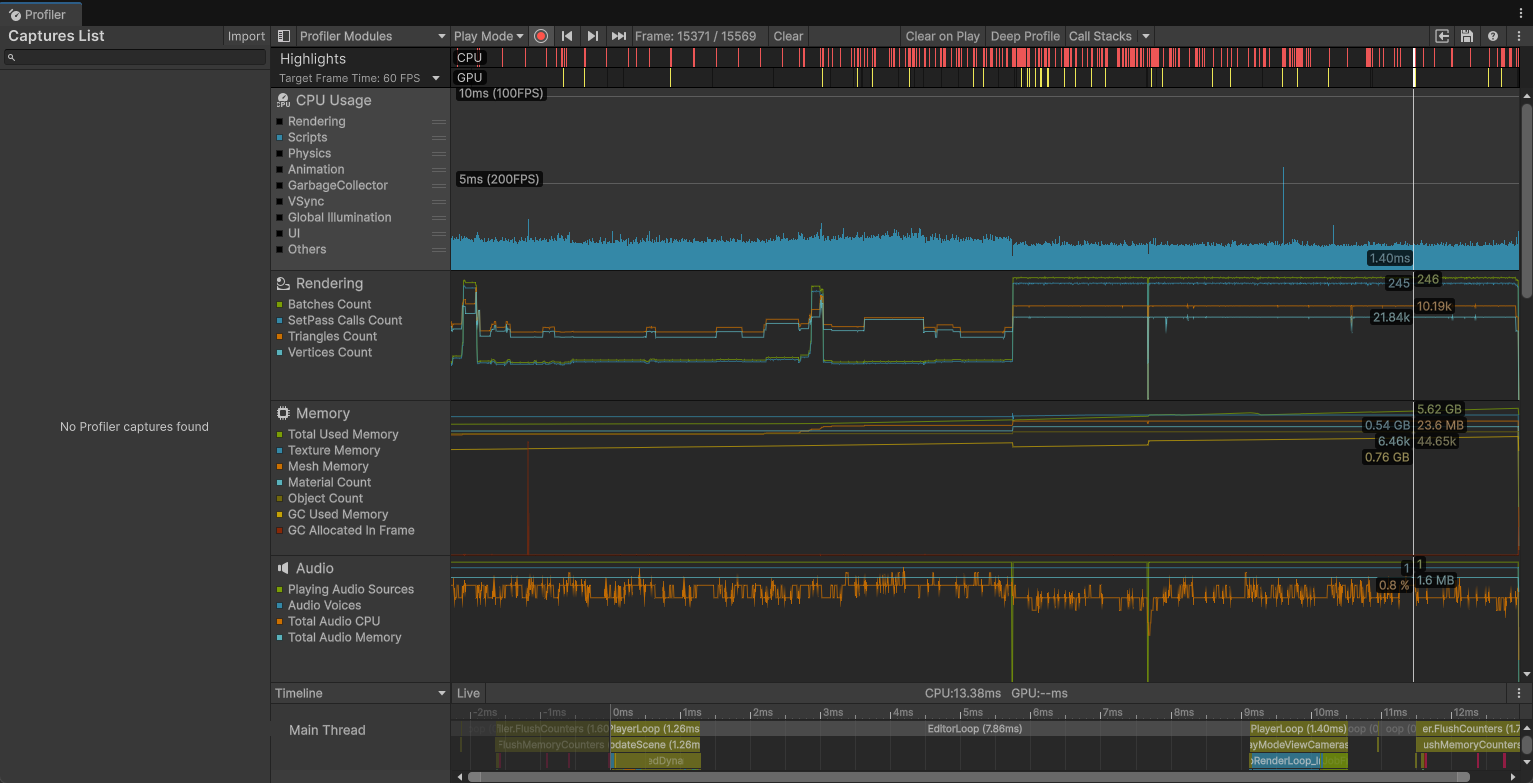
我们这里还可以做一个优化,只更新移动的物体。在接口中加入IsMovable
cs
public interface ILogicalCullable
{
void SetVisible(bool isVisible,int lodLevel);
public Transform CullTransform { get; }
public bool IsMovable { get;}
}
// ActorController.cs
public bool IsMovable => _movementController.IsMovable;
cs
public void LateUpdate(float deltaTime)
{
int count = _activeCount;
for (int i = 0; i < count; i++)
{
// 只有移动物体才更新
if (_cullableObjects[i].IsMovable)
{
_boudingSpeheres[i].position = _cachedTransforms[i].position;
}
}
}几乎到了1.0ms,说实话优化幅度有点夸张,所以获取position是一个开销很大的动作。