一、先算核心账:显存到底被谁吃了?
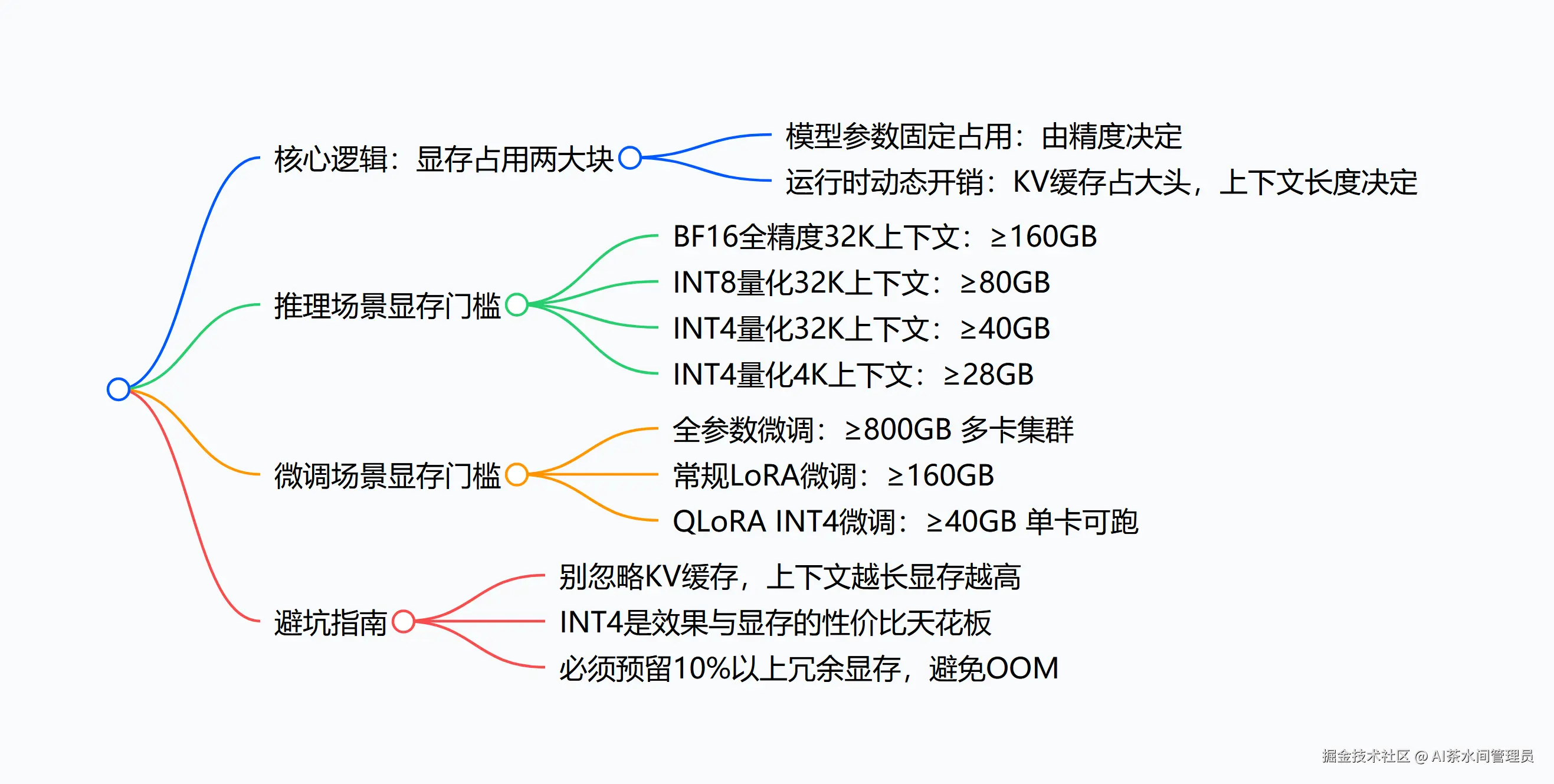
很多人算显存,只看模型文件大小,这是90%的人踩坑的根源。70B模型的显存占用,永远是两大块:模型参数本身的固定占用 + 运行时的动态开销,少算任何一块,都会直接OOM。
先上核心拆解图,一眼看懂显存去向:
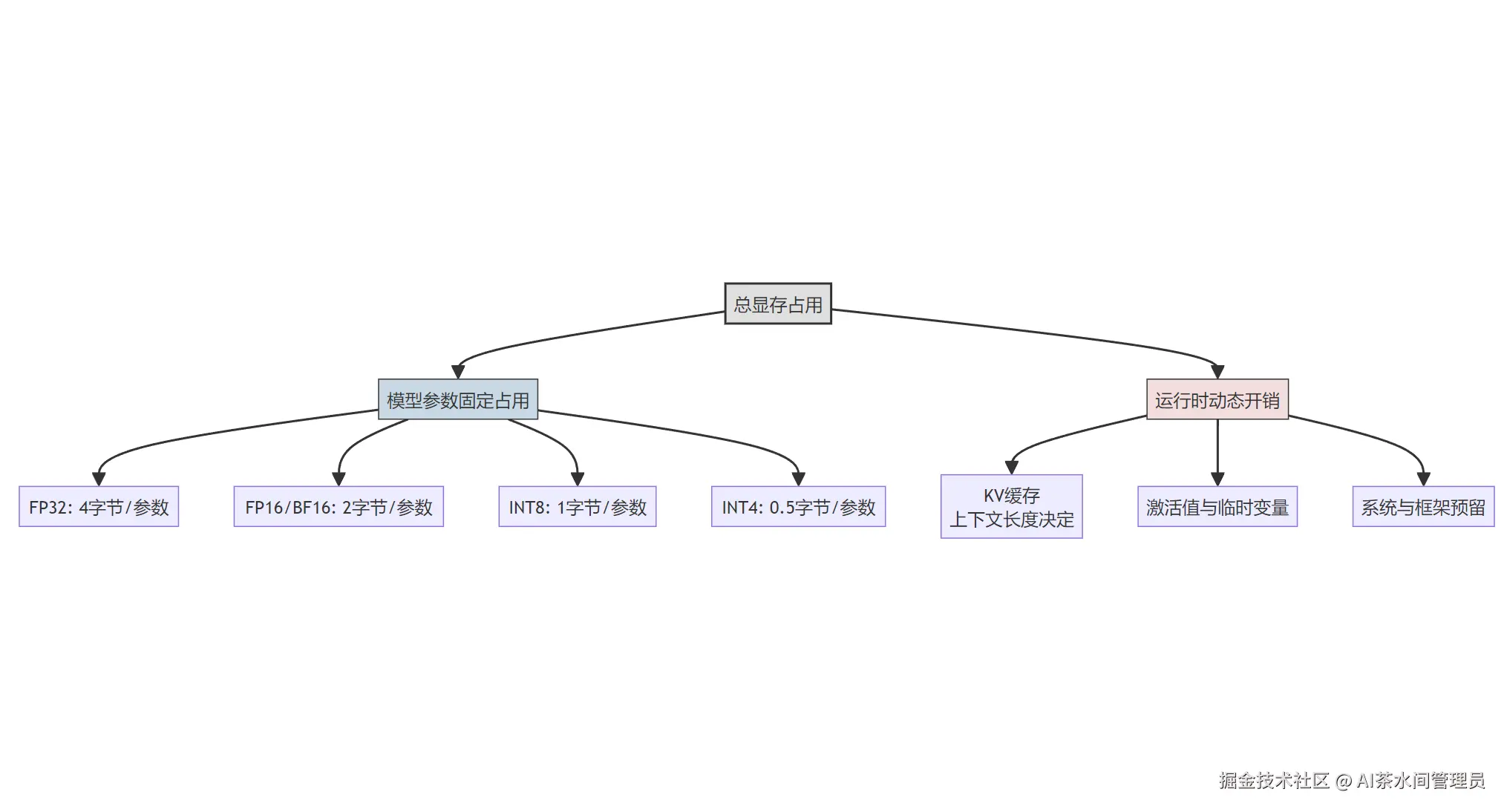
先算最基础的参数占用:70B就是700亿个参数,每个参数的显存占用,完全由精度决定,公式极其简单:
单参数字节数 × 700亿 ÷ 1024³ = 模型参数显存占用(GB)
给你算好现成的结果:
- FP32全精度:70B × 4B = 280GB
- FP16/BF16半精度:70B × 2B = 140GB
- INT8量化:70B × 1B = 70GB
- INT4量化:70B × 0.5B = 35GB
这还只是模型本身的大小,真正的"显存刺客",是运行时的KV缓存------它的大小完全由上下文长度决定,4K上下文和32K上下文,KV缓存能差出8倍,这也是为什么有人24G能跑,有人40G都炸了的核心原因。
二、最关心的推理场景:不同配置到底要多大显存?
绝大多数人玩70B模型,都是用来推理部署,我直接给你实测好的、可落地的显存门槛,同时给你一个可直接复用的显存计算脚本,自己就能精准算。
先上不同场景的显存需求一览:
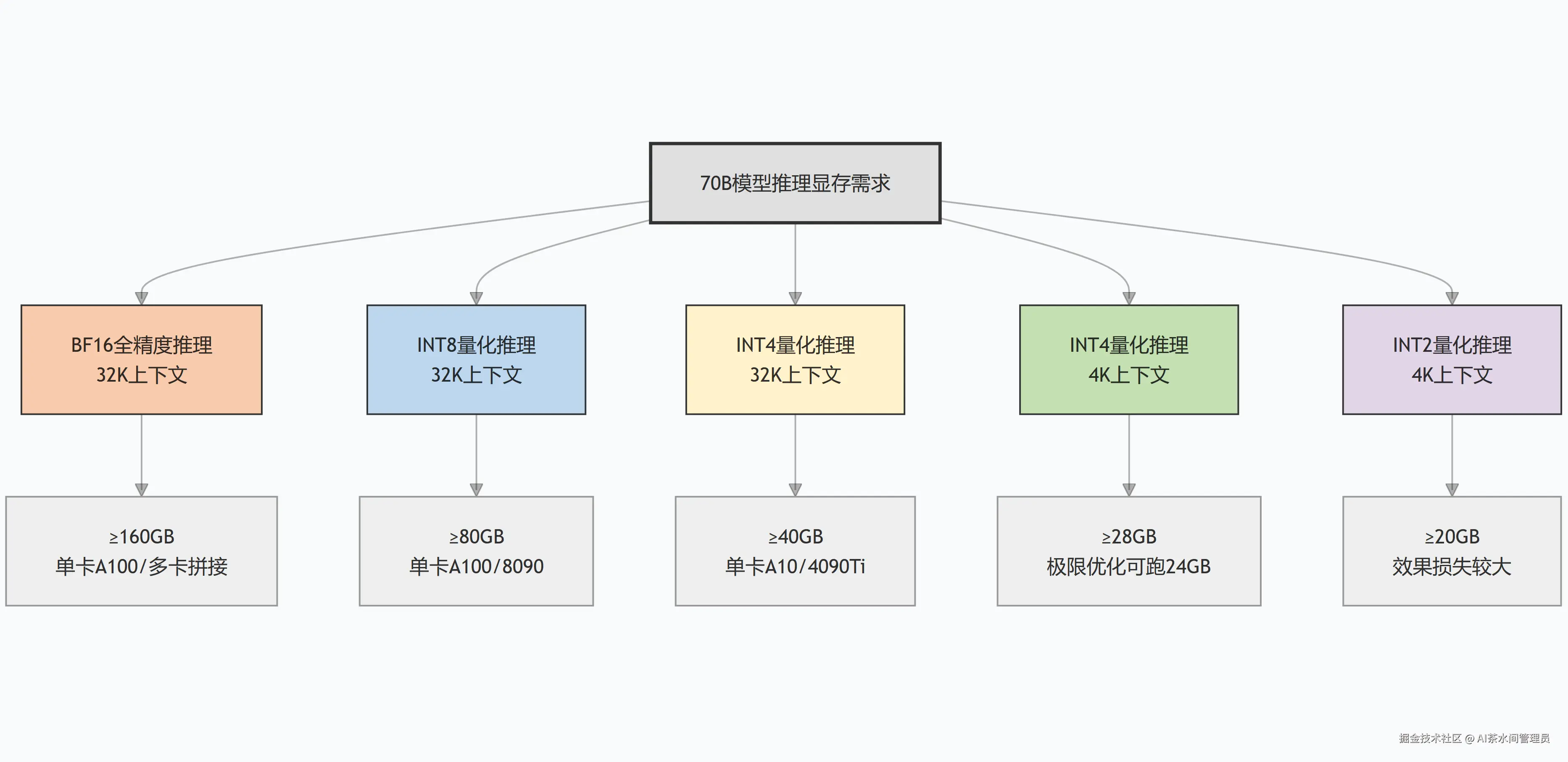
给你划重点:
- 日常玩,INT4量化+4K上下文是性价比天花板,效果损失极小,30GB左右显存就能跑,极限优化下24GB的4090也能跑,但只能单轮对话,没法开长上下文;
- 要做服务部署、长文本处理,INT4量化+32K上下文,至少要40GB显存,别想着用24GB的卡硬扛,一定会炸;
PS:本人部署过70B Deepseek,量化int4,4090显卡,显存共48G。是完全可以用的,就是有点慢捂脸,大家可以参考。
这里给你一个核心的Python计算脚本,输入参数就能精准算出显存需求,再也不用瞎猜:
Python
def calc_70b_vram(precision_bit: int, context_len: int, batch_size: int = 1):
# 70B模型固定参数(以Llama3为例)
param_count, n_layers, n_heads, head_dim = 70e9, 80, 64, 128
# 1. 模型参数显存(GB)
param_vram = (param_count * (precision_bit / 8)) / 1024**3
# 2. KV缓存显存(GB)
kv_vram = (2 * n_layers * n_heads * head_dim * context_len * batch_size * 2) / 1024**3
# 3. 10%冗余预留,避免OOM
total_vram = (param_vram + kv_vram) * 1.1
return f"参数占用: {param_vram:.1f}GB, KV缓存: {kv_vram:.1f}GB, 总需求: {total_vram:.1f}GB"
# 示例:INT4量化,32K上下文
print(calc_70b_vram(precision_bit=4, context_len=32768))三、微调场景:想训70B模型,显存门槛有多高?
很多同学还想自己微调70B模型,这里直接给你划清门槛,别白费功夫:
- 全参数微调:FP16精度下,算上优化器状态、梯度、激活值,至少需要800GB显存,必须用多卡分布式集群,个人玩家直接不用想;
- 常规LoRA微调:冻结主干,只训小部分参数,也需要至少160GB显存,单卡基本跑不动;
- QLoRA量化微调:INT4量化+梯度检查点优化,4K上下文下,40GB显存就能单卡跑通,这是个人玩家微调70B的唯一可行方案。
四、需要注意
- 只算模型大小,忽略KV缓存:这是最常见的坑,INT4的70B模型本身35GB,但32K上下文的KV缓存要10GB+,总需求直接冲到45GB,24GB的卡根本扛不住;
- 盲目追求低量化:不是量化越低越好,INT4是效果和显存的平衡点,INT2及以下的量化,模型推理能力会断崖式下跌,基本没法用;
- 不留冗余显存:别卡着上限买显卡,一定要留10%以上的冗余,不然稍微长一点的对话,直接就OOM。
如果这篇文章对你有帮助,别忘了点赞、收藏、关注,我会持续分享更多软件开发、AI应用开发、Agent、LLM、面试干货。
我们下期再见!