26.1 流形学习(manifold learning)
++"流形"是指局部具有欧氏空间的性质,能用欧氏距离进行距离计算++ 。这给降维方法带来了很大的启发:++若将低维流形嵌入到高维空间,数据样本在高维空间的分布虽然非常复杂,但在局部仍具有欧氏空间的性质++ ,因此,++可以比较容易在局部建立降维映射关系,再设法将局部映射关系推广到全局。++
介绍两种著名的流形学习方法:
26.1.1 等度量映射
等度量映射 (Isometric Mapping,简称Isomap) Tenenbaum et al.,2000的基本出发点,是认为低维流形嵌入到高维空间之后,++低维流形上两点之间的距离是S曲面上的"测地线" (geodesic)距离++ :想象一只虫子从一点爬到另一点,++即测地线距离是两点之间的本真距离++。显然,直接在高维空间中计算直线距离是不恰当的。
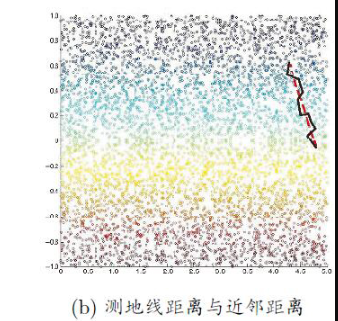
如何计算测地线距离?可利用流形在局部上具有欧氏空间的性质,对每个点基于欧氏距离找出其近邻点,建立一个近邻连接图。于是,++计算两点之间测地线距离的问题,就转变为计算近邻连接图上两点之间最短路径问题++。如下图可看出,基于近邻距离能很好地逼近低维流形上测地线距离。
lsomap算法描述:
for i = 1, 2, ..., m do
确定 xi 的k近邻
将 xi 与k近邻点之间的距离设置为欧氏距离 (与其他点的距离设置为无穷大)
end for
在近邻连接图上可采用著名**++Dijkstra算法 (详见附录)++** 或Floyd算法,计算任意两样本点之间的距离 dist(xi, xj)
++将 dist(xi, xj) 作为MDS算法的输入++
<MDS算法:
(具体可详见我的博客 《机器学习(二十四) 降维 : MDS降维方法与 ...》)
- 根据 dist(xi, xj) 代入公式计算 disti.^2, dist.j^2, dist..^2
- 根据 bij = -(1/2)(distij^2 -disti·^2 -dist·j^2 +dist··^2) 计算矩阵B
- 对矩阵B做特征值分解:
(特征值分解具体算法实例可详见我的博客 《机器学习(二十五) 降维:... 及特征值分解》)
4. 取d'个最大特征值构成对角矩阵Λ',V'为对应的特征向量矩阵
5. 输出:(V')√(Λ') ∈ Rm×d' (每行是一个样本xi在低维空间的投影向量zi)
>
- ++return MDS算法的输出++
输出: 样本集在d'低维空间的投影矩阵 Z={z1, z2, ..., zm}
对近邻连接图的构建通常有两种做法:一种是指定近邻点个数,例如欧氏距离最近的k个点为近邻点;另一种是指定距离阈值,距离小于阈值的点被认为是近邻点。两种方式均有不足,例如若近邻范围指定得较大,则距离很远的点可能被误认为近邻,这样就会出现"短路"问题;近邻范围指定得较小,则图中有些区域可能与其他区域不存在连接,这样就出现"孤点"问题。"短路"与"孤点"都会给后续的最短路径计算造成误导。
需注意的是,Isomap仅是得到了训练样本在低维空间的坐标,对于新样本,如何将其映射到低维空间呢?这个问题的常用解决方案目前仅有一个权宜之计,是将训练样本的高维空间坐标作为输入、低维空间坐标作为输出,训练一个回归学习器来对新样本的低维空间坐标进行预测。
附录 Dijkstra算法描述:
在带权有向图/无向图中,给定起点s,求s到图中任意点x的最短路径。其核心逻辑基于"局部最优解逐步扩展至全局最优解"的思想,算法步骤如下:
- 初始化:
. 设起点s的距离dists=0,与其他所有点的距离初始化为无穷大(∞)
. 将起点s加入优先队列Q,Q按点距离从小到大排序。
- 从Q中++++弹出distu最小的点u 并加入集合S++++ ,++遍历u的所有近邻节点v:++
. ++若u到达v的路径长度 (即distu+w(u,v),其中w(u,v)为u与v之间的欧氏距离++ <边(u,v)的权重>) ++小于当前distv,则将v加入Q,更新distv=distu+w(u,v)++
. 若v已在队列中,则更新其距离并调整队列顺序。
- 重复上述过程:
直到Q为空 (即所有相关的节点均被访问),此时集合S即为起点s到各点的最短路径。
26.1.2 局部线性嵌入
Isomap算法是基于近邻样本之间的距离,与此不同,局部线性嵌入 (Locally Linear Embedding,简称LLE) Roweis and Saul,2000 ++基于邻域内样本之间的线性关系++。
假定样本点 xi 的坐标能通过它的邻域样本 xj, xk, xl 的坐标通过线性组合而重构出来,即
xi = wij·xj + wik·xk + wil·xl
<LLE希望此等式的关系在低维空间中得以保持,即 wi 在低维空间保持不变>。
LLE先为每个样本 xi 找到其近邻集合 Qi,然后计算出基于 Qi 中的样本点对 xi 进行线性重构的系数 wi:
min(w1, w2, ..., wm) Σ(i=1,m)||xi - Σ(j∈Qi)wijxj||^2
s.t. Σ(j∈Qi)wij=1
其中xi和Qi均为已知,令Cjk=(xi-xj)ᵀ(xi-xk),wij有闭式解
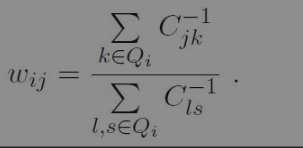
LLE在低维空间中保持wi不变,于是xi对应的低维空间坐标zi可通过下式求解:
min(z1, z2, ..., zm) Σ(i=1,m)||zi - Σ(j∈Qi)wijzj||^2
s.t. Σ(j∈Qi)wij=1
令Z=(z1, z2, ..., zm)∈Rd′×m,(W)ij=wij,M=(I-W)ᵀ(I-W),则对zi的求解可重写为:
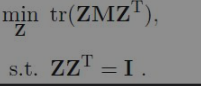
++此目标可通过特征值分解求解:M最小的d'个特征值对应的特征向量组成的矩阵即为Zᵀ++。
LLE算法描述:
输入:样本集D={x1, x2, ..., xm},近邻个数k,低维空间维数d'
for i=1, 2, ..., m do
确定xi的近邻集合Qi (近邻k)
基于 wij 闭式解,求得wij,j∈Qi
对于j∉Qi,令wij=0
end for
基于M=(I-W)ᵀ(I-W) 求得M
通过对M进行特征值分解:
(特征值分解具体算法实例可详见我的博客 《机器学习(二十五) 降维:... 及特征值分解》)
- return M最小的d'个特征值对应的特征向量组成的矩阵即为Zᵀ
输出:样本集D在低维空间的投影Z={z1, z2, ..., zm}