导读 introduction
随着图灵3.0生态在业务中不断深入,数据量和分析需求飞速增长,传统ClickHouse架构面临成本高昂、即席探索链路冗长以及故障恢复缓慢等问题。
为解决上诉问题,百度MEG数据中台构建了存算分离的湖仓一体架构。通过打通Meta服务与图灵元数据,实现湖上数据"零入库"的透明访问;并利用冷热分层缓存、数据上卷及布局优化,攻克了共享存储下的IO效率难题。最后,为保障复杂查询场景下的系统稳定性,系统建设了统一查询网关,支持将复杂查询任务透明降级至Spark运行。
01 现状和问题
1.1 当前现状
针对百度MEG上一代大数据产品平台繁杂、质量参差不齐以及易用性不足等痛点,MEG数据中台构建了新一代大数据解决方案------"图灵3.0"。该方案旨在从数据计算引擎、数据开发与数据分析三个维度,为业务提供一站式的全链路解决方案。ClickHouse(下文简称CH)作为"图灵3.0"的核心数据计算引擎之一,在前期文章中ClickHouse在百度MEG数据中台的落地和优化,我们已有过详细介绍。其核心优化方案大致如下:
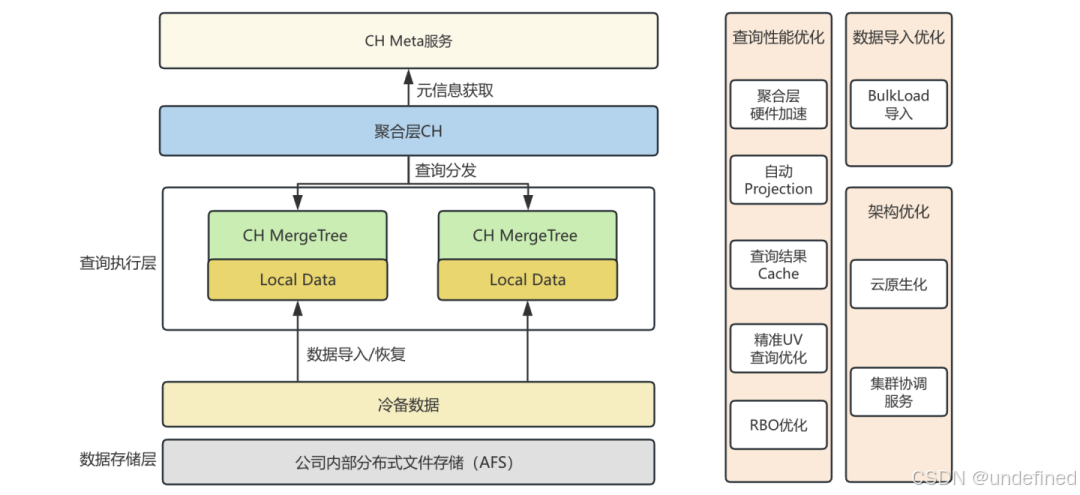
△ MEG数据中台CH优化方案
1.2 存在的问题
随着图灵3.0生态不断覆盖公司各个业务方向,CH作为底层引擎承接的数据规模和分析需求也日益增长。数据量激增带来的主要问题如下:
**1. 长周期存储的成本与扩展瓶颈:**部分数据集需要保存五年甚至更久。虽然本地磁盘存储具有低延迟访问的优势,但纵向扩容受限于本地磁盘Quota,横向扩容又会增加数据Rebalance和查询网络扇出的成本。此外,用于离线恢复的冷备数据进一步推高了资源消耗。因此,亟需在控制成本的前提下,提供长周期的数据存储与分析能力。
**2. 数据探索链路冗长:**传统基于CH MergeTree引擎的分析流程包含建表、入库及查询分析三个环节。这种模式对于即席探索需求而言过于繁琐,且维护离线导入任务涉及较高的人力成本。因此,亟待构建一套更敏捷、低门槛的数据探索机制。
3. 节点故障恢复缓慢:CH副本节点的故障恢复时间较长。由于服务在迁移或重启时需重新加载本地HDD盘数据,导致重启恢复通常达到小时级,迁移恢复甚至需要天级,严重影响了整体服务的可用性。因此,必须提供更稳定的数据分析引擎能力。
湖仓一体作为融合数据湖灵活性与数据仓库高性能的现代架构,通过开放数据格式实现计算与存储的解耦。为彻底解决上述挑战,MEG数据中台构建了存算分离的CH湖仓一体架构,通过以下核心逻辑实现问题收敛:
1. 存算解耦破解存储瓶颈:通过将本地磁盘存储演进为基于AFS(百度内部自研的高可靠分布式文件系统)的共享存储层,实现了容量的弹性扩展。长周期数据无需受限于物理节点的磁盘Quota,将数据沉淀至低成本存储池,并配合定制化的查询优化手段,有效平衡了成本与性能的矛盾。
2. 开放格式简化探索链路:湖仓一体架构支持对Parquet等开放格式的直接查询。通过构建"零入库"的数据探索模式,用户无需经历繁琐的建表与离线导入,即可利用CH的向量化引擎对湖上数据进行即时查询,极大缩短了从原始数据到业务洞察的链路。
3. 无状态化加速故障恢复:在存算分离架构下,CH计算节点转化为"无状态"模式,节点重启或迁移无需经历冗长的数据重加载过程。这使得恢复时长从小时级/天级骤减至分钟级,显著提升了系统在高压力环境下的可用性与运维灵活性。
02 基于湖仓一体架构的解决方案
2.1 原生ClickHouse在湖仓场景下的使用局限
早期版本的开源CH对外部湖仓数据源的支持能力相对较弱,主要依赖表函数和表引擎,对特定格式的外部数据进行单机查询。随着版本的迭代,CH在24.11版本中新增了icebergCluster、deltaLakeCluster等表函数,从而有效增强了对外部湖仓数据源的分布式查询能力。而CH Cloud商业云服务从25.8版本开始,则已经能够基于DataLakeCatalog提供较为完备的分布式湖仓查询能力。

△ 社区CH湖仓能力演进
从社区迭代趋势来看,湖仓一体是CH未来的重要发展方向。MEG 数据中台依托开源CH构建了分析引擎,向湖仓一体架构演进符合长期的技术趋势。然而,当前开源CH在湖仓集成方面仍存在以下不足:
-
生态兼容不足:MEG数据中台的存储层主要依赖AFS。目前CH尚未打通对AFS数据的访问,也缺乏对图灵生态各类组件的深度兼容。
-
易用性欠佳:CH表函数主要用于数据探索,往往要求业务侧感知底层的物理分布;而Iceberg等外表引擎在模式演进和分布式查询性能上仍有欠缺,难以满足大规模生产需求。这些局限性共同导致了CH现有湖仓能力对业务的使用门槛较高。
-
查询性能受限:当前CH对外部数据源的读取优化主要集中于文件Reader层面。与MergeTree等本地表相比,缺乏数据上卷、Compaction等成体系的性能优化方案。
针对上述痛点,我们结合图灵生态,在开源CH的基础上构建了全新的湖仓一体引擎架构。该架构旨在全面提升系统的易用性与查询性能,从而更好地支撑上层业务的湖仓融合查询需求。
2.2 结合图灵生态对ClickHouse湖仓功能的改进
MEG数据中台主要以AFS作为存储层,以Parquet作为开放文件格式,通过图灵表(MEG数据中台自建的一种开放表格式)提供查询服务。考虑到前期在优化CH分布式架构时,我们已经构建了独立的元数据服务(Meta-Service),因此决定直接基于现有CH引擎能力进行扩展,通过兼容图灵生态组件来实现湖仓一体架构。主要工作如下:
-
打通CH Meta服务与图灵元数据:为CH引擎提供统一的湖仓元数据管理和访问入口,并支持实时订阅元数据变更。
-
新增CH AFS表引擎:支持直接访问AFS文件,并提供谓词下推、并行读和小IO合并读等文件级别的IO优化。
-
实现CH与Meta服务联动:提供AFS文件粒度的查询负载编排能力,支持对湖仓数据的分布式查询以及多源数据的联邦查询。
随后,为了进一步提升湖仓场景下的查询性能,我们从冷热数据分层和数据上卷聚合两个维度入手,分别对高频数据和高频查询模式进行IO提效。同时,我们还对底层数据布局进行了优化,构建更适合分析场景的数据分布,让上层业务获得接近本地表的查询体验。
最后,针对扫描量大或复杂度高、容易占用过多资源并影响系统稳定性的查询,我们建设了统一查询网关。该网关支持将CH查询透明降级为Spark,通过多引擎协同来保障整体服务的质量。
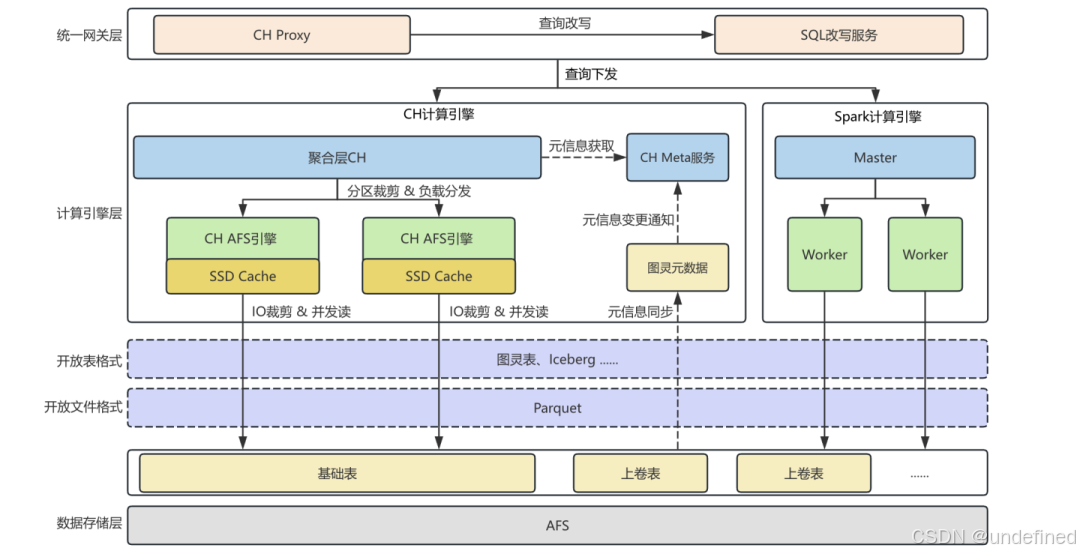
△ MEG数据中台湖仓一体解决方案
接下来的部分,我们将从元数据打通、查询性能优化和统一查询网关三个维度展开,分享我们在湖仓一体架构上的实践经验。
03 元数据打通:实现ClickHouse对共享存储的透明化查询
数据目录作为连接CH与外部数据源的桥梁,在湖仓一体架构中主要负责元数据发现。为了让CH具备对图灵表格式的查询能力,首先需要在数据目录层面完成兼容。相比于开源引擎通常在内核直接扩展数据目录,MEG数据中台选择在Meta服务层实现数据目录功能,主要考量如下:
(1)高扩展性:Meta服务采用插件化设计支持各类外部数据源接入。CH引擎只需按照统一规范与Meta服务交互,最大程度降低了对引擎本身的侵入。
(2)兼顾性能与一致性:Meta服务通过统一存储保存元数据,并利用缓存加速访问。同时,它支持实时变更订阅,平衡了元数据获取的性能需求与数据一致性。
(3)可维护性:Meta服务作为各类元数据的代理,符合内部对其的功能定位。这不仅减轻了CH的本地状态负担,也让后续的迭代和维护成本更加可控。
首先,为了建立统一的元数据访问规范,CH Meta服务需要对外部元数据进行抽象分类,具体可划分为以下三类信息:

其次,考虑到外部数据源与CH侧元信息的一致性直接影响查询结果,Meta服务引入了实时订阅机制。一旦图灵表的元信息发生变更,系统会自动同步AFS引擎、缓存与图灵表三者间的元数据,确保信息一致。
最后,分析场景通常涉及跨分区扫描,单次查询往往需要请求大量元数据。为此,CH Meta服务通过以下方式优化了访问性能:
(1)热点缓存与并发加速:将热点元数据保存在分布式缓存中,并利用多线程提升元数据的查询效率。
(2)数据压缩与合并:利用同类元数据通常存在公共前缀的特点,对元数据进行压缩合并,从而减少CH引擎与Meta服务之间的网络传输开销。
经过上述优化,Meta服务元数据查询的平均响应时间从之前的600ms以上大幅缩短至50ms以内。
通过上述三个层面的建设,Meta服务作为湖仓一体架构的逻辑底座,让AFS引擎能够"理解"存储在AFS上的数据文件,实现了湖上数据的透明化访问。
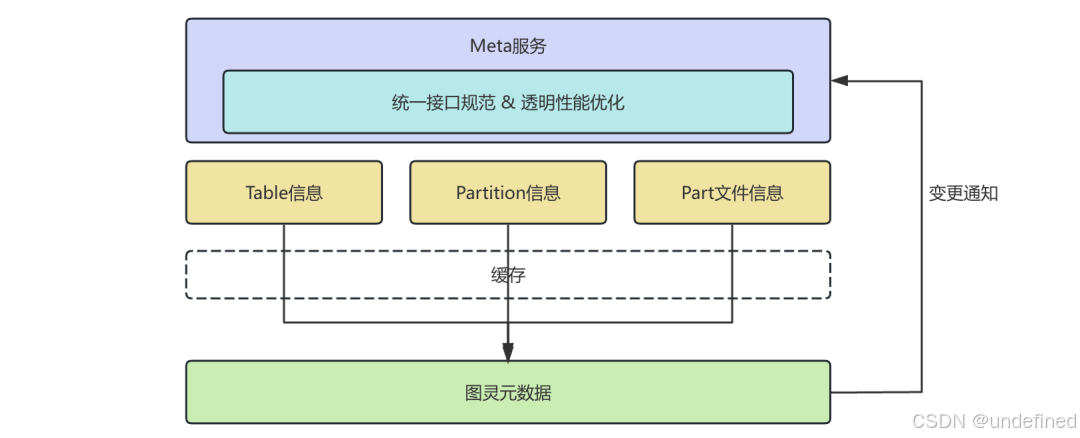
△ CH Meta服务
04 查询性能优化:攻克湖仓架构下AFS引擎的查询效率瓶颈
4.1 冷热数据分层
在实现湖上数据透明化访问的基础上,我们进一步将优化重心转向对外部数据的查询耗时。初期工作主要集中在IO优化和并行访问两个方面:
(1)IO优化:通过分区裁剪、谓词下推和小IO合并等手段,有效减少了数据扫描量以及对远端存储的访问频率。
(2)并行访问:充分利用多核资源并细化文件访问粒度,实现了RowGroup级别的并行读取,显著提升了查询性能。
结合AFS跨磁盘高IO吞吐的特性,AFS引擎在长周期数据扫描场景下的表现已接近本地HDD盘的MergeTree引擎。
在此基础上,我们进一步分析了Parquet数据的访问流程以及下游业务的查询模式,发现了一些深层次问题:
(1)Parquet访问流程方面:单次访问通常涉及多次数据请求,包括先获取Parquet元数据,再请求裁剪后的实际数据。这种多次往返的网络IO,对于只需分析少量数据的查询来说,访问成本被明显放大了。
(2)业务查询模式方面:通过对线上查询所涉及的分区范围进行统计汇总,我们发现近期数据以及同环比相关的数据通常会被高频访问。
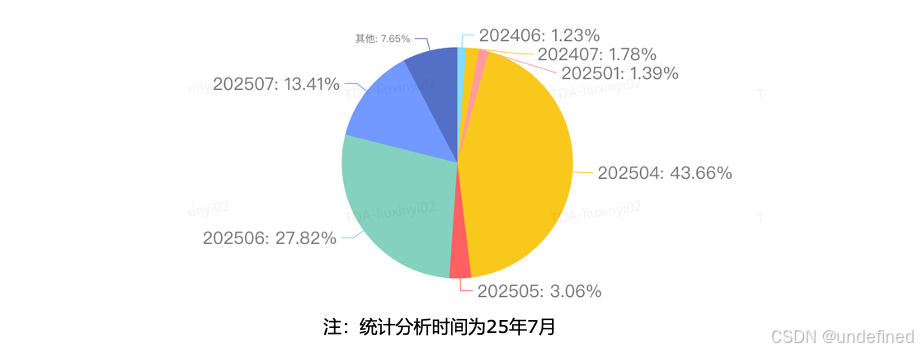
△ 线上查询对应的分区范围统计
4.1.1 热数据本地SSD缓存
结合上述统计分析,我们通过冷热数据分层机制,利用本地SSD缓存高频访问的热点数据段,从而提升查询IO吞吐并降低网络延迟。具体逻辑上,命中缓存的数据直接从本地读取;若未命中,则在从远端存储请求数据的同时,同步将对应数据段拉取并缓存至本地SSD。
此外,为了避免不同业务间的缓存抢占影响查询稳定性,我们按业务粒度划分了独立缓存池。在缓存池内部,我们通过设置淘汰策略清理过期数据,并利用准入规则(如限制仅近期或同环比数据入池)来进一步提升缓存的有效利用率。
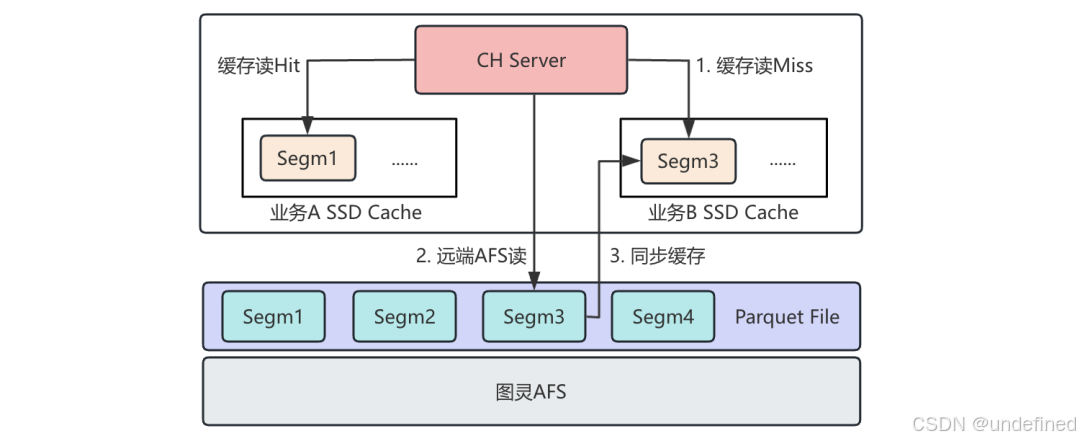
△ 冷热数据分层
4.1.2 一致性Hash提升缓存本地性
在利用本地SSD缓存热点数据的过程中,除了加速查询,如何提升缓存本地性也是我们需要重点考虑的问题。简单来说,我们既要保证查询请求在各分片间均衡分配,又要尽量确保相同的文件始终落在同一个分片上。
为此,我们引入了一致性Hash算法来优化缓存路由。具体实现上,通过cluster_parallelism设置虚拟节点数量,并利用table_parallelism限制负载分配的分片范围。这种方案实现了双重效果:整体文件能够均匀调度到各个分片,而同一个文件则能稳定路由到指定分片。此外,该设计在分片进行扩缩容时,也能最大限度地减少需要重新分布的缓存数据量。
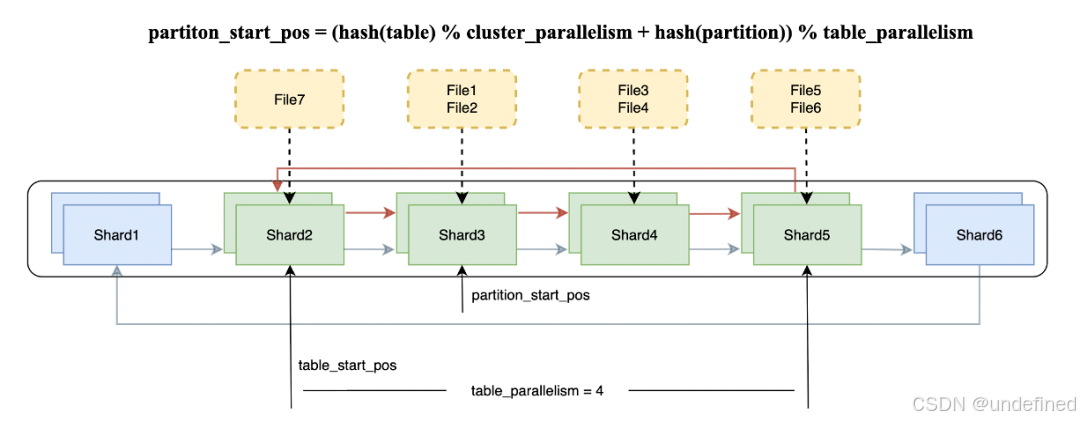
△ 一致性Hash下发查询文件
针对某线上数据集的查询分析场景,我们对比了冷热分层架构与原线上环境的耗时表现。数据表明,在中长周期的数据查询场景中(未命中MergeTree上卷),AFS引擎的查询耗时相比本地HDD MergeTree引擎缩短了至少30%。
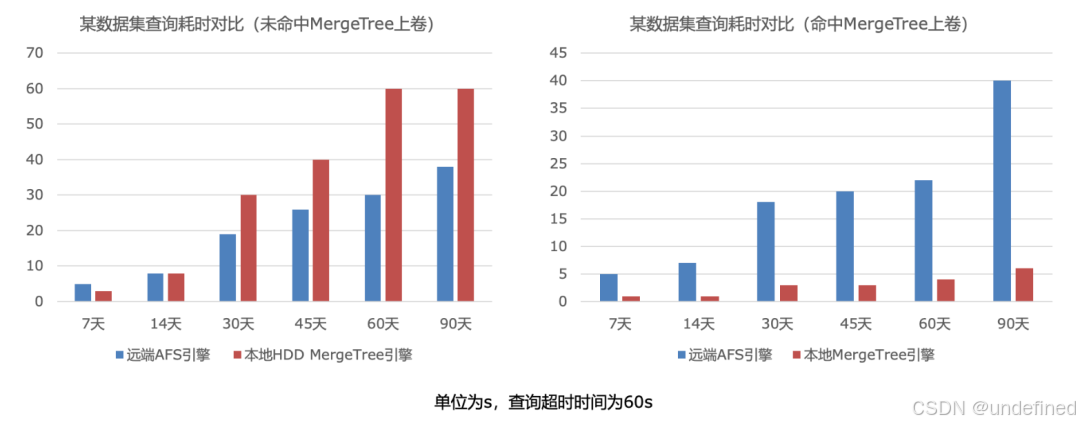
△ AFS引擎和本地MergeTree引擎查询耗时对比
4.2 数据上卷聚合
在短周期数据查询场景下,受限于Parquet的数据组织格式以及潜在的网络延迟,AFS引擎的查询耗时仍然高于本地MergeTree引擎。而在命中MergeTree上卷的场景中,即使有本地SSD缓存热数据,AFS引擎的查询性能也远低于MergeTree。因此,我们重点通过补齐AFS引擎的上卷能力,来提升这类场景的性能表现。
为了保持湖仓一体架构的存算分离特性,我们选择基于远端存储构建上卷表。同时,为简化数据处理流程,我们将上卷表的表引擎与基础表保持对齐。上卷能力的建设主要包括:上卷生命周期管理、基础表与上卷表的数据同步、以及命中上卷时的查询改写这三部分。
4.2.1 上卷生命周期管理
虽然有效的上卷能大幅提升查询性能,但通常需要投入额外的存储和计算成本,质量不佳的上卷反而会适得其反。因此,在上卷建设初期,我们主要通过人工方式进行管理;同时,我们将上卷管理功能与图灵开发平台打通,通过平台化、流程化的手段来降低管理成本。
数据RD作为业务需求侧与引擎侧的桥梁,既了解业务模式又熟悉数据建模。目前,主要由数据RD发起上卷的创建与删除,并结合外部表引擎的过期数据清理等机制,完成对数据全生命周期的管理。
在上卷建设后期,我们计划引入自动化或半自动化的能力,主动挖掘业务的高频查询模式。届时将参考上卷的ROI指标,在提升查询体验的同时,进一步压降管理成本。
4.2.2 上卷数据自动同步
在前期文章对CH的查询优化过程中,我们利用Projection机制实现了高频查询模式下的数据上卷聚合。由于Projection采用增量同步来保证上卷数据与基础表的数据一致性,为了兼容下游业务习惯并控制同步成本,我们同样按照分区粒度来实现上卷表的数据同步。
上卷表的数据同步按时效性可分为同步(Sync)和异步(Async)两种方式。Sync方式虽然能简化一致性保障,但会增加基础表导入任务的计算复杂度和耗时。考虑到基础表往往有多个下游消费任务,且部分入库任务有严格的时效SLA要求,我们最终选择以Async方式实现数据同步。
我们通过引入版本机制实现了上卷表与基础表的最终一致性,并以此保障查询结果的正确性。同时,我们通过引入外部计算队列来完成数据同步,实现了数据同步负载与查询负载的有效隔离,从而保障了下游业务查询的稳定性。
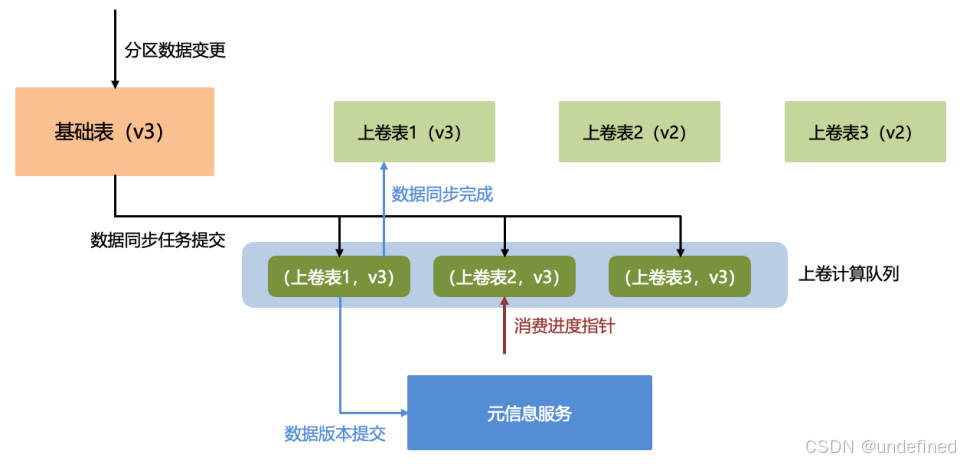
△ 上卷数据同步
4.2.3 上卷查询透明修改
对于命中上卷的基础表查询,具体的执行流程可以细分为上卷命中检查、最优上卷选择和查询透明改写三个步骤:
(1)上卷命中检查:根据查询SQL中的维度列和聚合指标,与已有的上卷模式进行匹配,从而判断查询是否可以命中上卷,以及具体命中了哪些上卷。
(2)最优上卷选择:首先通过版本号判断上卷表与基础表的分区数据是否一致;在此基础上,利用CBO选择聚合效果最好的上卷表,在保证数据准确性的同时,最大限度减少查询IO开销。
(3)查询透明改写:将原基础表对应分区的查询负载,透明替换为上卷表对应分区的查询负载,并完成后续的查询计算流程。
通过补齐AFS引擎的上卷能力,某业务针对高频查询模式建设了相关上卷,其线上数据集查询耗时平均响应时间缩短了约55%。
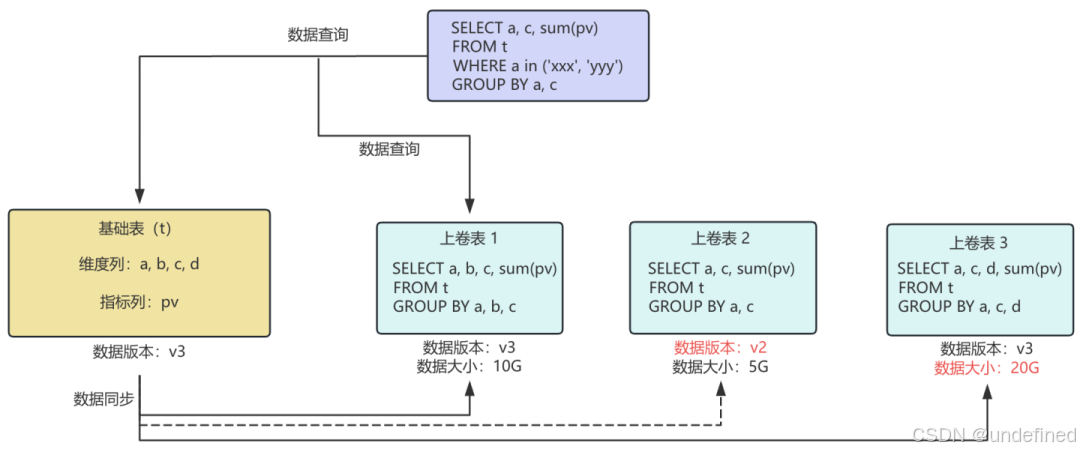
△ 查询透明改写
4.3 数据布局优化
作为封闭式的数据仓库服务,CH的极致性能不仅依靠缓存和数据上卷来优化IO,更离不开MergeTree引擎对数据组织格式及管理任务的深度定制。由于存算分离的湖仓一体架构基于开放格式构建,天然缺乏对数据布局的干预机制,因此我们通过优化图灵表的数据布局,构建计算友好型的数据分布,从而进一步提升查询性能。
目前,业界主流方案通常由外部任务通过覆盖写的方式,定期对数据进行排序和合并;也有如Databricks的Liquid Clustering等新技术,支持增量、自动地完成布局优化。考虑到图灵表的数据生产模式主要是通过离线ETL加工后,一次性产出分区的全量数据,为了避免额外的计算开销和维护成本,我们选择直接干预离线ETL流程,并引入插件式的优化规则,从而在生产阶段直接完成对数据布局的优化。
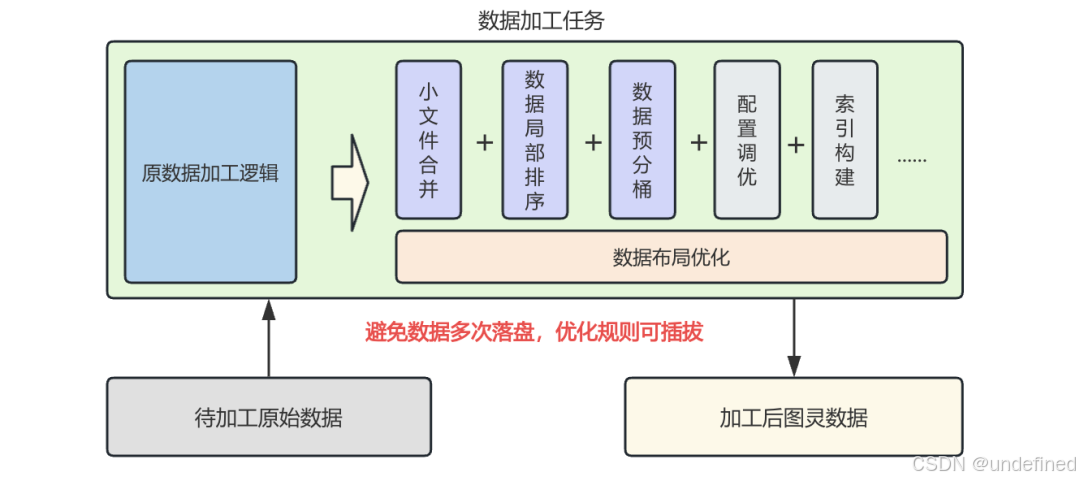
△ 数据布局优化
目前支持的优化规则主要包括以下三项:
(1)小文件合并:将大量碎片化的小文件合并为少量大文件,从而避免磁盘IO的碎片化,同时结合AFS引擎的读缓存和预读能力,有效提升了网络吞吐。
(2)数据局部排序:按照指定规则对乱序数据进行重排序。这不仅提升了数据的压缩效率,还能配合Parquet的Min-Max索引增强IO裁剪效果。
(3)数据预分桶:参考Colocation Group的思路,将数据按固定Key预先划分。在进行高基数去重查询时,利用NoMerge机制(详见前期文章)将相同Key的数据下发给同一CH计算节点。这样可以避免中间大状态在节点间传输,大幅缩短查询耗时。
从实际效果看,某线上数据集通过数据预分桶优化布局后,4个月跨度的高基数去重查询耗时缩短了60%以上。同时,小文件合并在部分业务场景中也取得了显著收益,查询耗时最高降低了80%。
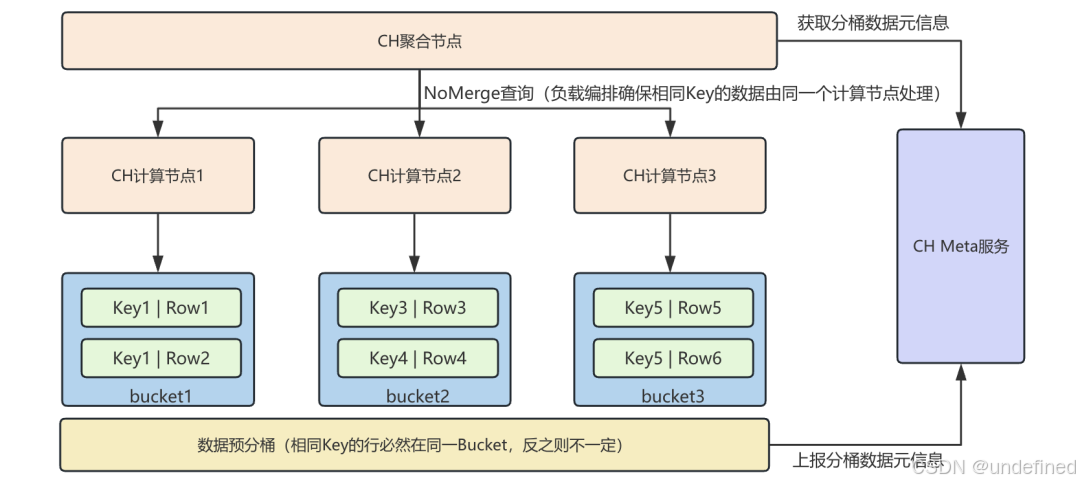
△ 基于数据预分桶的NoMerge查询
05 统一查询网关:建立ClickHouse复杂查询的透明降级机制
经过对元数据查询以及对远端文件读取的持续优化,目前CH AFS引擎在大部分分析场景下的性能已追平、甚至超越了基于本地HDD磁盘的MergeTree引擎。
随着MEG数据中台CH被更多业务深度使用,查询负载的类型和场景也随之增加。受限于CH分布式架构的一些固有局限------如Shuffle能力较弱、缺乏完善的资源隔离机制等,部分复杂查询往往会占用过多计算资源,进而影响整体服务的稳定性。这些问题在传统的存算一体架构中解决成本极高,而存算分离的湖仓一体架构为我们提供了新的解决思路。
存算分离的湖仓一体架构完全解耦了存储与计算的依赖关系,不仅为存储和计算的独立弹性扩展奠定了基础,还通过开放表格式与开放文件格式解决了厂商锁定问题。这意味着上层业务可以根据不同的工作负载,灵活选择最合适的计算引擎来查询同一套存储层。考虑到Spark凭借其DAG执行模型和资源管理机制,在数据Shuffle与资源隔离方面表现优异,我们建设了统一查询网关,支持将CH复杂查询透明降级至Spark运行。通过为不同负载匹配最合适的引擎,有效提升了整体查询服务的质量。
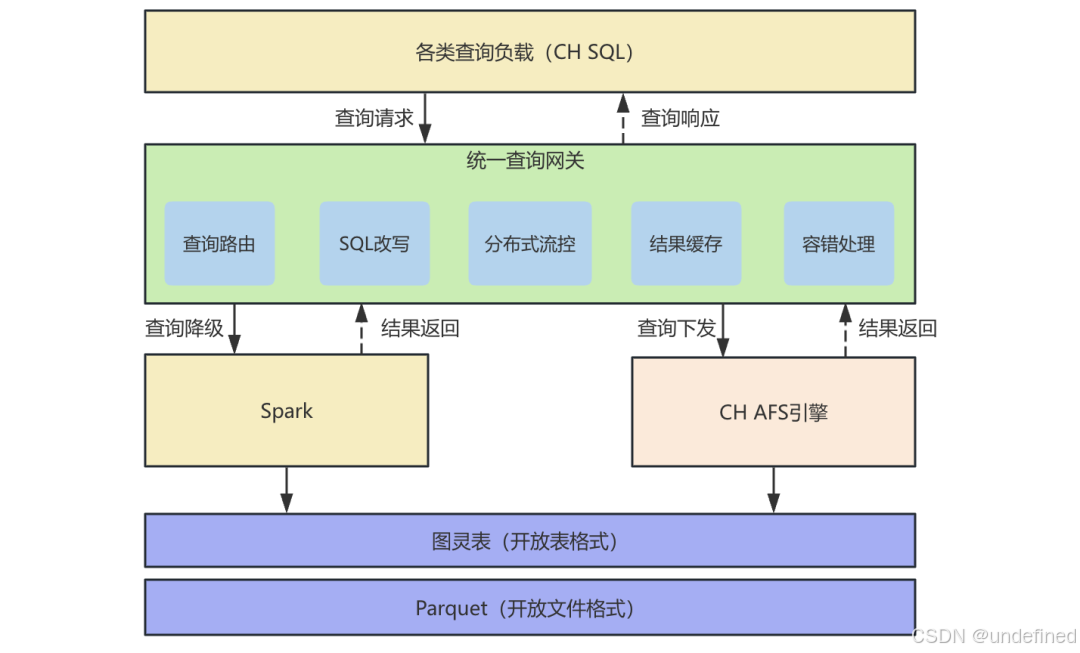
△ 统一查询网关
为了实现不同类型工作负载的按需调度,首先需要构建查询路由模块。初期我们主要通过模式匹配的方式进行路由决策:
(1)SQL规则匹配:若查询SQL命中预设的降级模式规则,则直接将其转为Spark查询。
(2)异常状态匹配:若CH查询出现超时或OOM等异常状态,系统将自动触发Spark引擎重试。
后续我们计划结合查询的历史运行记录,以及分区数、IO量等统计信息,进一步优化查询路由的决策能力。
其次,由于我们统一使用CH SQL作为对外方言,在将任务降级至Spark时,必须进行SQL语法改写。在对比了Calcite、SQLGlot等开源框架并权衡了内部兼容性后,我们选择基于SQLGlot构建改写服务。
为确保改写的准确性,我们抽取了线上高频的CH SQL,利用SQLGlot转译为Spark SQL后进行了"双跑"校验。结果显示,两者的语法差异主要集中在两点:
(1)函数命名差异:部分实现相同功能的函数名不同,且SQLGlot尚未涵盖所有转换规则。
(2)底层实现逻辑差异:例如数组索引的起始位置,Spark从0开始,而CH从1开始。
针对上述挑战,我们通过一套半自动化的闭环流程持续优化SQLGlot的转译能力。目前,我们已在开源版本基础上新增了30多个函数的改写支持,CH SQL的改写成功率已超过80%。同时,线上服务对于改写失败的SQL会放弃降级,以此保障查询结果的绝对正确。
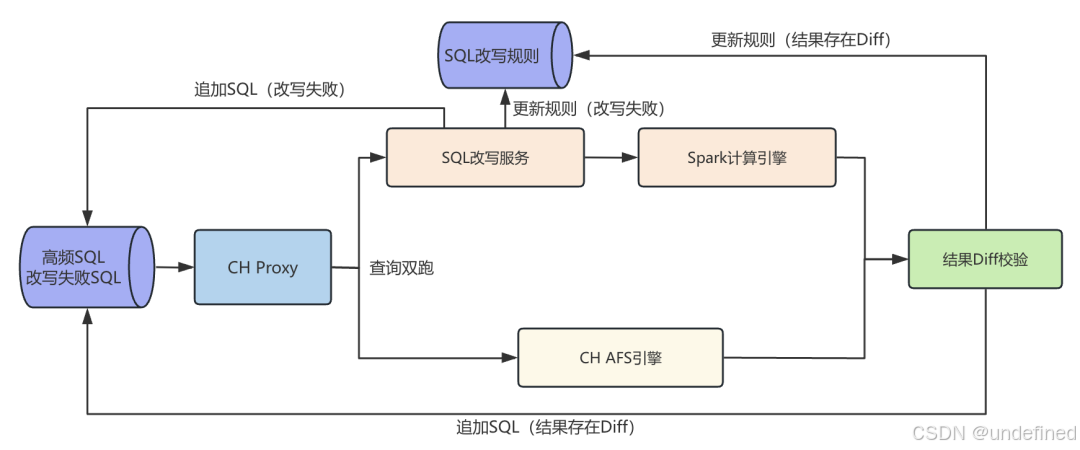
△ SQL改写规则迭代流程
最后,为了提供一致的查询体验,我们需要打通降级后的Spark查询与原有的CH查询流程,实现统一的查询入口与一致的结果返回。
在查询入口方面,我们将CH与Spark查询收敛至同一套服务与接口,统一由CH Proxy服务承接上游的CH SQL请求,确保业务侧无感知。
在结果返回方面,我们利用clickhouse-local工具(一种无需安装完整服务、可直接使用SQL访问本地或远端文件的开箱即用工具),按照预定的Format格式读取Spark产出的Parquet结果文件,并封装为标准的CH响应返回给上游。
此外,我们还引入了分布式流控与幂等重试机制,以保障查询降级服务的可用性;同时利用基于版本的查询结果缓存,进一步提升了高频查询的响应性能。
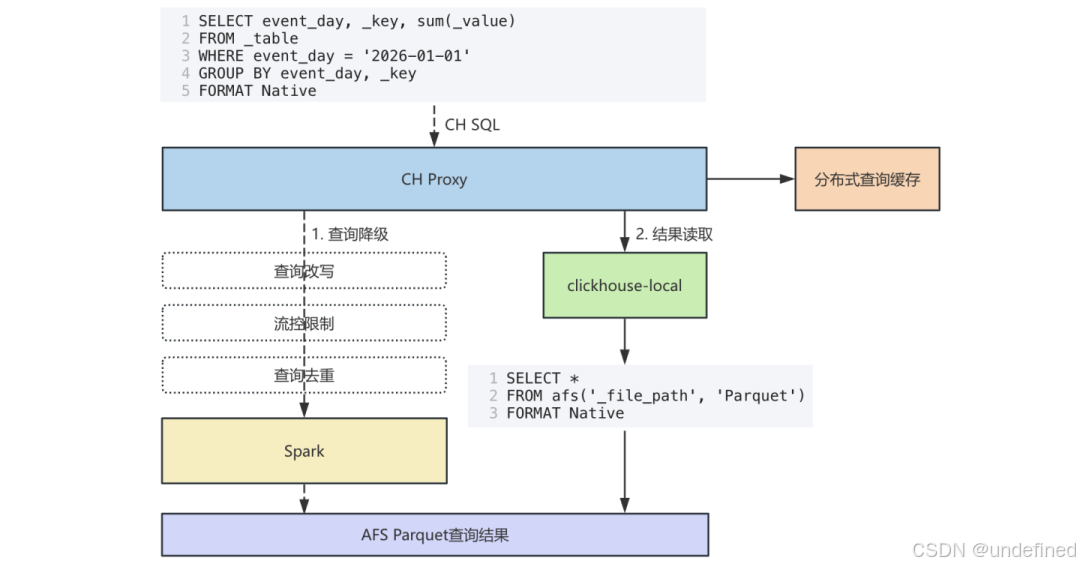
△ CH & Spark查询流程打通
06 总结与展望
湖仓一体作为近年兴起的现代架构理念,完美融合了数据湖的低成本、高扩展性与数据仓库的高性能查询能力。为满足实际业务中对CH引擎在成本、弹性和稳定性等方面的诉求,百度MEG数据中台持续探索并实践了CH在湖仓一体架构下的深度应用。
元数据服务作为连接CH与图灵生态的桥梁,在提供高效元数据发现能力的同时,也为低侵入式接入各类开放表格式提供了可能。此外,针对限制湖仓架构大规模应用的"查询性能"痛点,我们通过冷热数据分层优化热点IO吞吐,利用数据上卷聚合减少扫描量,并借助数据布局优化构建出计算友好型的数据分布。最后,基于存算解耦的特性,我们建设了统一查询网关,通过将CH复杂查询透明降级至Spark,有效提升了整体服务的稳定性。
目前,已有30余条业务线、300多个数据集接入了CH湖仓一体能力。在单日查询PV超过2万的背景下,剔除缓存影响后,湖仓场景下的平均响应时间小于6秒,P90耗时在13秒以内。
展望未来,我们仍将在以下三个维度持续深耕:
(1)架构层面:数据湖虽解决了存储弹性,但CH计算层的弹性仍有优化空间。后续我们将构建资源管理服务,结合K8S Operator能力打造计算组,通过解耦控制面与计算面,实现计算节点的动态编排。
(2)性能层面:构建针对开放表/文件格式的统计信息服务,为查询优化决策提供完备的数据支撑。同时,针对各类优化手段门槛较高的问题,我们将致力于构建自动化、智能化的流程,真正实现技术赋能业务。
(3)生态层面:Lance等新兴格式在点查性能上弥补了Parquet的短板。得益于存算解耦架构对新格式的良好兼容性,后续我们将进一步完善对Lance等格式的支持,持续拓宽应用场景。
业务需求的不断更迭、大数据理论的演进以及存储网络等硬件的革新,三者相辅相成,共同驱动着数据架构的演进。我们也将始终关注前沿趋势,持续迭代,为业务提供更极致的数据分析体验。