怎么解决Lost in the Middle(中间迷失)现象

文章目录
- [怎么解决Lost in the Middle(中间迷失)现象](#怎么解决Lost in the Middle(中间迷失)现象)
-
- 前言:当大语言模型开始"健忘"
- [一、什么是"Lost in the Middle"现象?](#一、什么是"Lost in the Middle"现象?)
-
- [1.1 专业解释](#1.1 专业解释)
- [1.2 为什么会这样?](#1.2 为什么会这样?)
- [1.3 大白话解读](#1.3 大白话解读)
- [1.4 真实案例](#1.4 真实案例)
- 二、问题的影响有多严重?
-
- [2.1 对RAG系统的致命打击](#2.1 对RAG系统的致命打击)
- [2.2 典型失败场景](#2.2 典型失败场景)
- [2.3 数据说话](#2.3 数据说话)
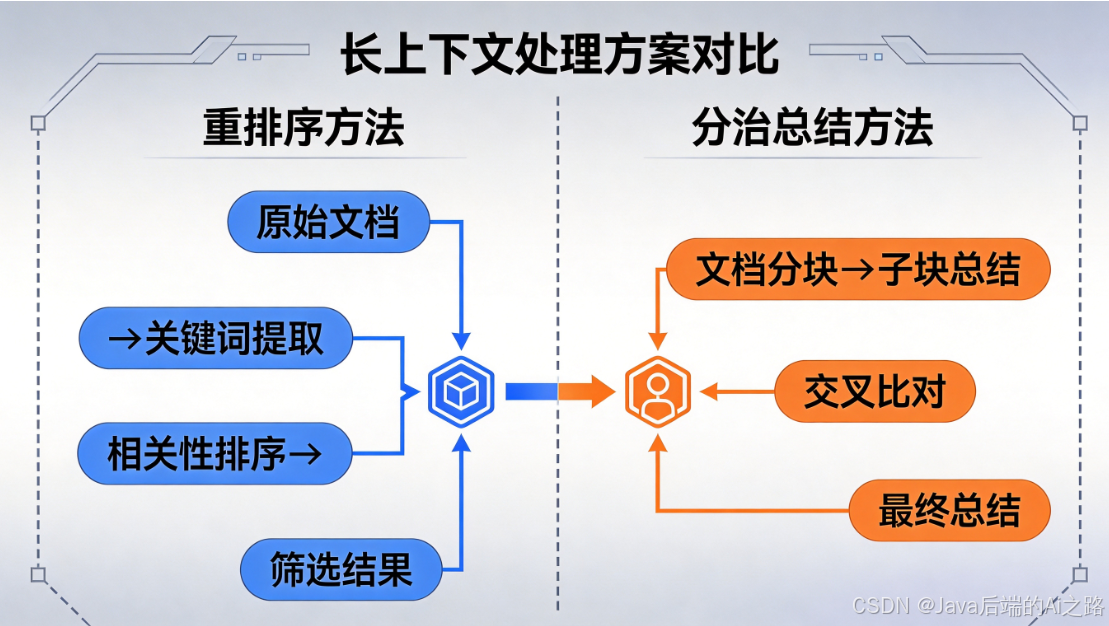
- 三、解决方案一:重排序(Rerank)
-
- [3.1 核心思想](#3.1 核心思想)
- [3.2 工作原理](#3.2 工作原理)
- [3.3 BGE-Reranker模型详解](#3.3 BGE-Reranker模型详解)
- [3.4 代码示例](#3.4 代码示例)
- [3.5 性能提升](#3.5 性能提升)
- 四、解决方案二:分治总结(Map-Reduce)
- 五、两种方案的对比与选择
-
- [5.1 适用场景对比](#5.1 适用场景对比)
- [5.2 组合使用策略](#5.2 组合使用策略)
- [5.3 性能对比数据](#5.3 性能对比数据)
- 六、最佳实践建议
-
- [6.1 RAG系统设计原则](#6.1 RAG系统设计原则)
- [6.2 工程实现要点](#6.2 工程实现要点)
- [6.3 常见陷阱](#6.3 常见陷阱)
- 七、总结与展望
-
- [7.1 核心要点回顾在这里插入图片描述](#7.1 核心要点回顾在这里插入图片描述)
- [7.2 未来发展方向](#7.2 未来发展方向)
- [7.3 行动建议](#7.3 行动建议)
- 八、互动时间
- 转载声明
- 参考链接
前言:当大语言模型开始"健忘"
你有没有遇到过这样的场景:精心准备了一大段超长Prompt,把所有背景信息、约束条件、参考资料都塞给大模型,满怀期待地等待它的回答,结果发现------它完全忽略了中间那段最重要的内容?
这不是你的错觉,也不是模型在故意和你作对。这是一个被学术界称为"Lost in the Middle(中间迷失)"的现象,而且它几乎存在于所有主流大语言模型中。
今天我们就来深入探讨这个现象,更重要的是------如何解决它!
一、什么是"Lost in the Middle"现象?
1.1 专业解释
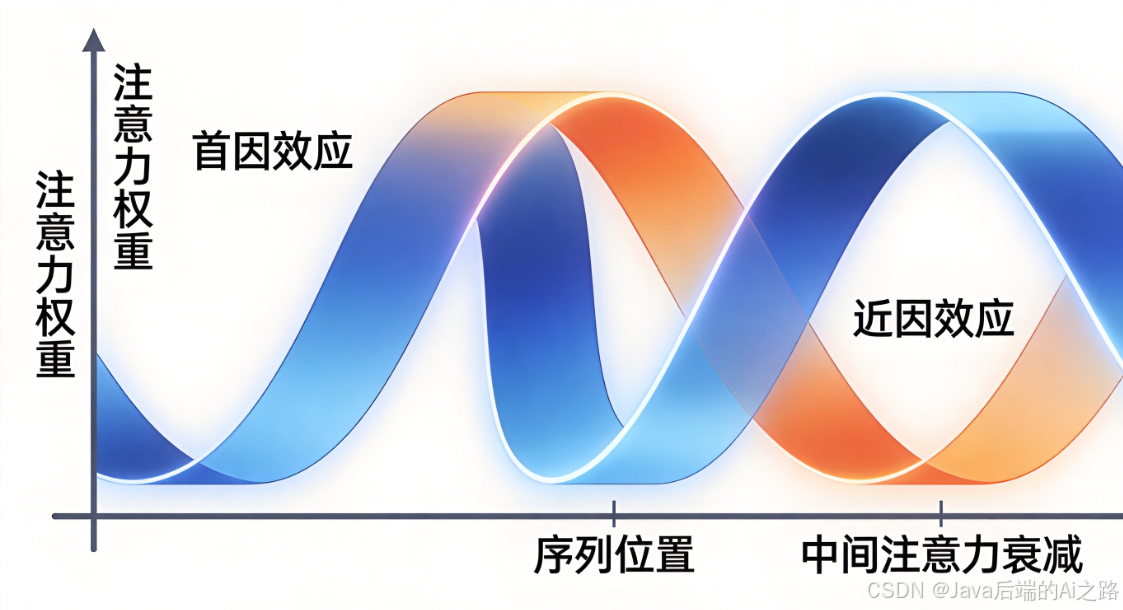
Lost in the Middle 现象指的是:当大语言模型(LLM)处理极长的上下文(如100k tokens甚至更多)时,模型往往只记得开头和结尾 的信息,而会忽略中间部分的内容。
这种现象呈现出明显的U型曲线特征:
- 开头位置(首因效应):模型注意力权重高,信息提取效果好
- 结尾位置(近因效应):模型注意力权重也高,信息提取效果较好
- 中间位置(中间迷失):模型注意力权重显著下降,信息提取效果最差
1.2 为什么会这样?
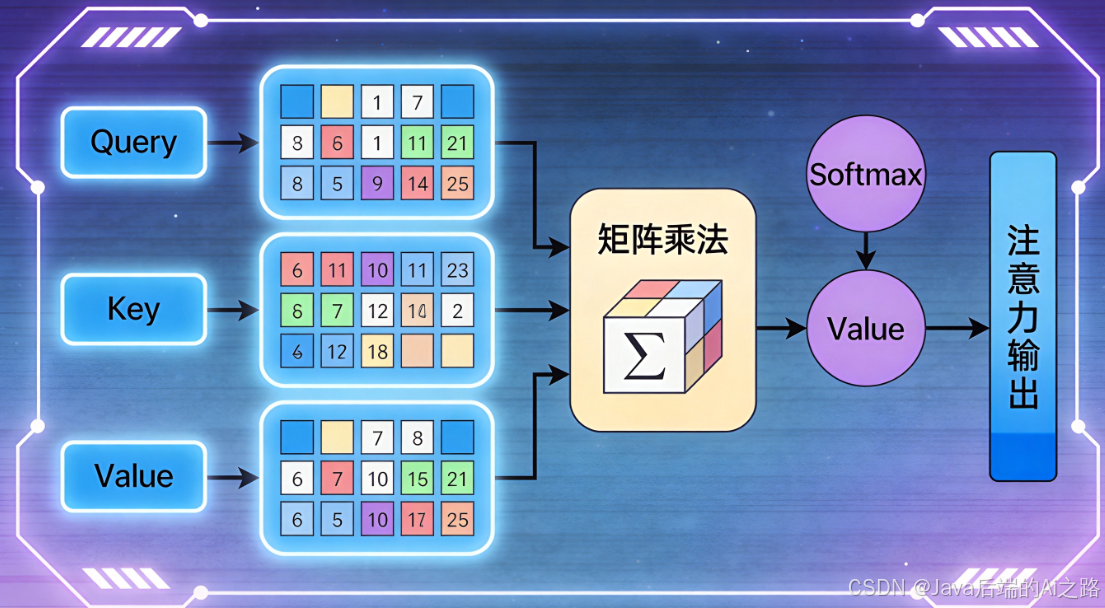
根本原因在于Transformer架构的注意力机制。当上下文长度增加时,注意力权重的计算遵循以下规律:
python
# 注意力权重计算(简化版)
Attention(Q, K, V) = softmax(QK^T / √d_k) V当序列长度n增加时,Softmax的指数特性使得:
- 靠近当前token的key获得高权重(局部性)
- 远离的key被"淹没"在指数求和的分母中
即使使用RoPE(旋转位置编码)、ALiBi等先进的位置编码技术,也只能缓解,无法完全根除这个问题。
1.3 大白话解读
想象一下你正在看一部超级长的电视剧(比如100集):
- 开头几集:你记得很清楚,因为这是你刚看完的,印象还新鲜
- 结尾几集:你也记得,因为这是最新的剧情,还热乎着
- 中间那几十集 :完全记不清了!只记得大概发生了什么,但具体细节?想不起来了
大语言模型的"记忆"也是这样------它不是真的"健忘",而是注意力有限,在处理超长内容时,只能把有限的注意力资源分配给开头和结尾。
1.4 真实案例
微软研究院的实验数据显示:
- GPT-3.5-Turbo在关键文档位于中间时的准确率(~54%)甚至低于其闭卷准确率(56.1%)
- GPT-4虽然整体准确率更高,但依然遵循"两头高、中间低"的规律
- 多轮对话场景:模型的可靠性从单轮的95%暴跌至45%
这意味着:提供错误的上下文位置不仅无益,反而有害!
二、问题的影响有多严重?
2.1 对RAG系统的致命打击
对于检索增强生成(RAG)系统来说,这个问题尤其致命。因为RAG系统的核心流程是:
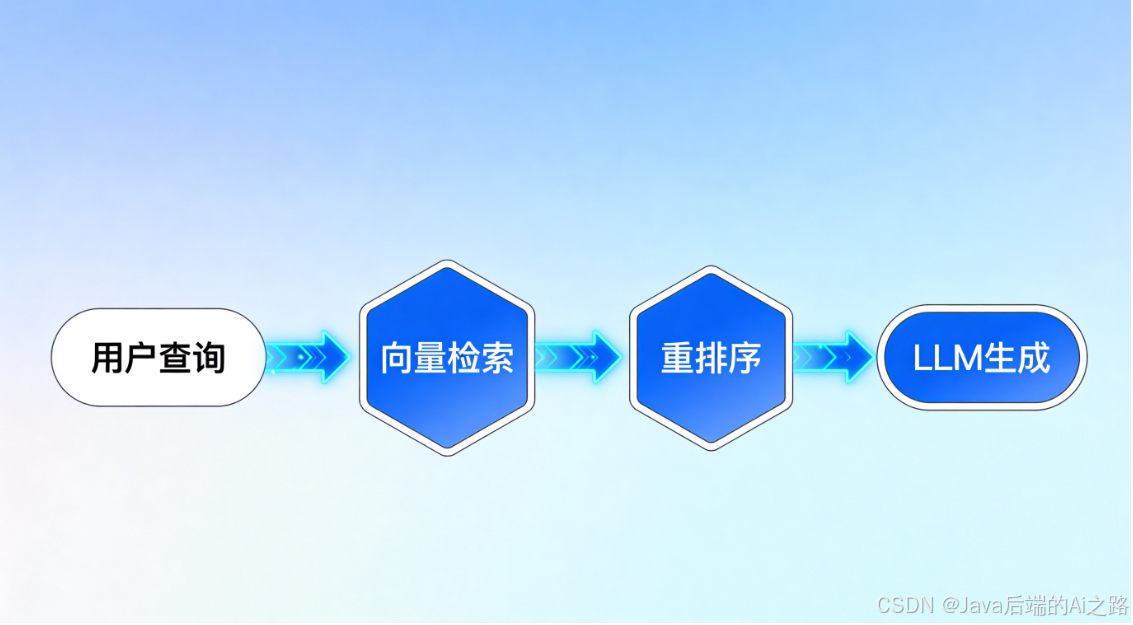
- 检索出Top-K个相关文档(比如Top-50)
- 将这些文档拼接成上下文
- 喂给大语言模型生成答案
如果模型只能有效利用开头和结尾的文档,那么中间那些可能包含关键答案的文档就被浪费了!
2.2 典型失败场景
- 法律文书分析:把100页合同塞给模型,模型只记得开头和结尾,中间的关键条款全忽略了
- 代码库理解:项目有1000个文件,模型只看了前50个和后50个,中间的核心逻辑代码完全没看
- 多轮对话:聊着聊着,模型就"忘了"你最早提出的重要约束条件
2.3 数据说话
实验表明,在20个文档的多文档问答任务中:
- 关键文档在开头:准确率约85%
- 关键文档在结尾:准确率约78%
- 关键文档在中间:准确率仅约54%
超过文档数Top-20后,模型准确率迅速饱和,不再提升!
三、解决方案一:重排序(Rerank)
3.1 核心思想
既然模型对中间的内容"记不住",那我们就主动调整内容的位置 ------把最相关的内容放到开头或结尾,把不相关的内容放到中间!
这就是**重排序(Rerank)**策略的核心思想。
3.2 工作原理
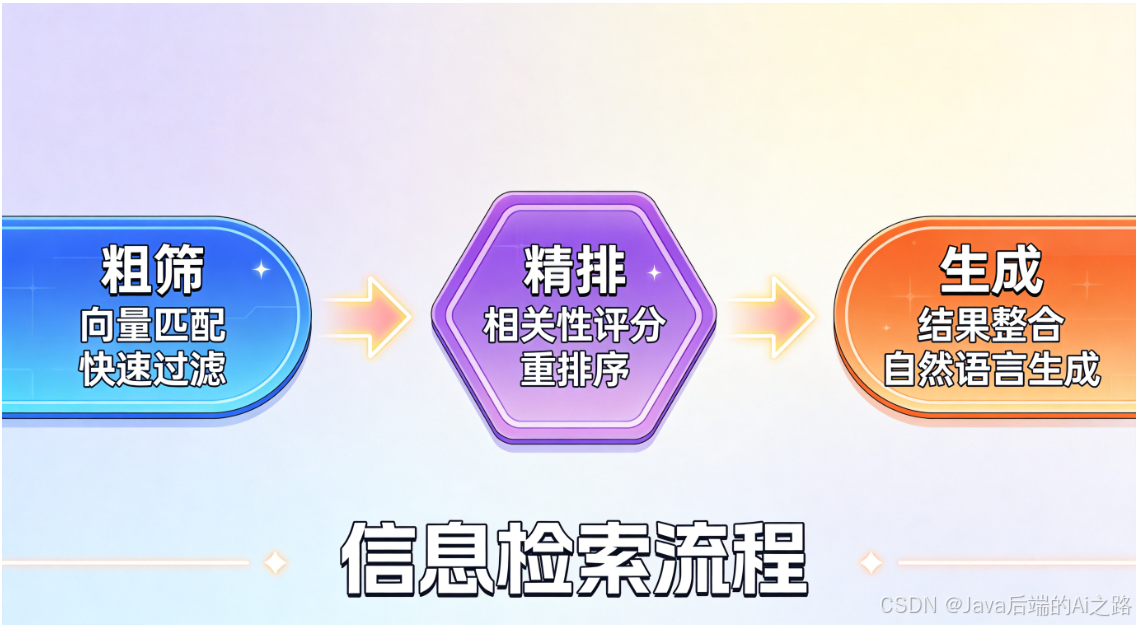
Rerank策略通常分为三个阶段:
- 粗筛阶段:使用向量检索模型快速检索出Top-K个候选文档(如Top-50)
- 精排阶段:使用重排序模型(如BGE-Reranker)对这50个文档重新打分排序
- 生成阶段:将排序后的Top-N个文档(如Top-5)喂给大语言模型
3.3 BGE-Reranker模型详解
BGE-Reranker 是由智源研究院(BAAI)开发的高性能重排序模型,它采用Cross-Encoder架构,能够深度分析查询与文档的逻辑匹配度。
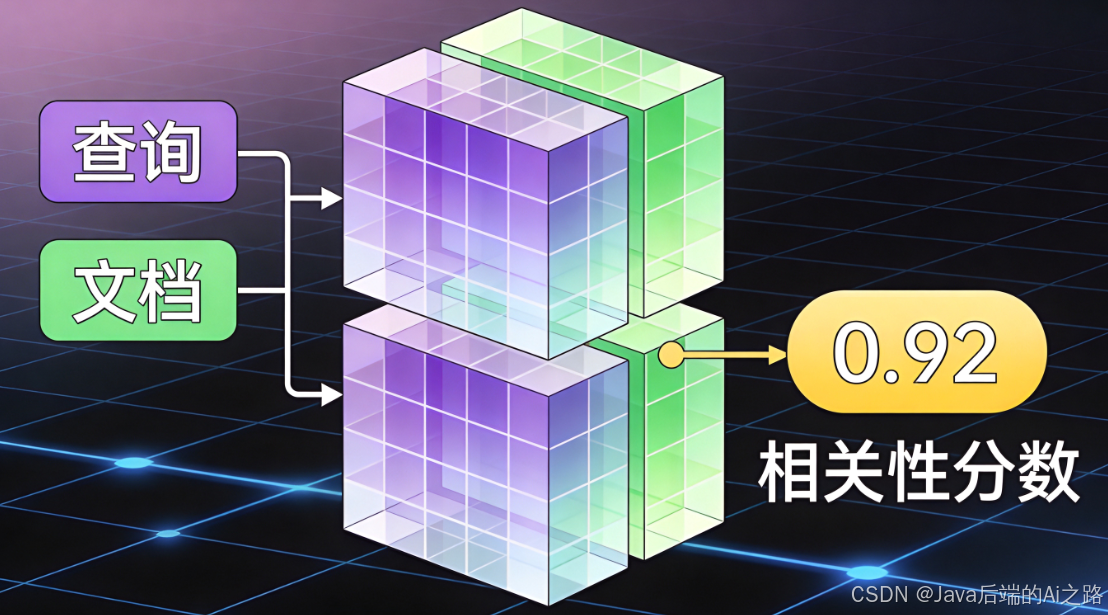
为什么Cross-Encoder更准?
与传统的双编码器(Bi-Encoder)不同,Cross-Encoder不是分别给查询和文档打分,而是将二者拼接成一个输入序列,送入Transformer进行联合编码。
python
# Bi-Encoder:分别编码
query_embedding = encoder_model.encode(query)
doc_embedding = encoder_model.encode(document)
score = cosine_similarity(query_embedding, doc_embedding)
# Cross-Encoder:联合编码
input_text = f"[CLS] {query} [SEP] {document} [SEP]"
score = cross_encoder_model.predict(input_text)技术类比:
- Bi-Encoder像"根据标题找书"
- Cross-Encoder像"通读摘要后判断是否真正相关"
3.4 代码示例
python
from FlagEmbedding import FlagReranker
# 初始化BGE-Reranker模型
reranker = FlagReranker(
'BAAI/bge-reranker-base',
query_max_length=256,
use_fp16=True,
devices=['cuda:0']
)
# 示例:对检索到的文档进行重排序
query = "如何解决LLM的中间迷失现象?"
# 假设这是第一阶段检索到的Top-10文档
candidates = [
"LLM长上下文处理的挑战与解决方案...",
"Transformer注意力机制原理解析...",
"检索增强生成系统最佳实践...", # 这个最相关
"自然语言处理发展历史...",
"机器学习基础概念...",
"深度学习优化算法...",
"神经网络架构演进...",
"计算机视觉应用案例...",
"强化学习入门指南...",
"数据科学工具使用..."
]
# 计算每个候选文档的相关性分数
scores = []
for doc in candidates:
score = reranker.compute_score([[query, doc]])
scores.append(score[0])
# 按分数排序
ranked_results = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
# 输出排序结果
print("重排序后的结果:")
for i, (doc, score) in enumerate(ranked_results[:5]):
print(f"{i+1}. 相关度: {score:.4f} | {doc[:50]}...")输出示例:
重排序后的结果:
1. 相关度: 0.9523 | 检索增强生成系统最佳实践...
2. 相关度: 0.8765 | LLM长上下文处理的挑战与解决方案...
3. 相关度: 0.6543 | Transformer注意力机制原理解析...
4. 相关度: 0.4321 | 自然语言处理发展历史...
5. 相关度: 0.3210 | 机器学习基础概念...3.5 性能提升
使用BGE-Reranker后:
- 检索精度提升:在中文任务上的NDCG@10平均提升达28.6%
- 长尾查询优化:对"北京朝阳区办理居住证需要哪些材料"这类长尾问题,匹配准确率提升41%
- 幻觉率降低:因接收不相关上下文而产生的幻觉风险显著下降
四、解决方案二:分治总结(Map-Reduce)
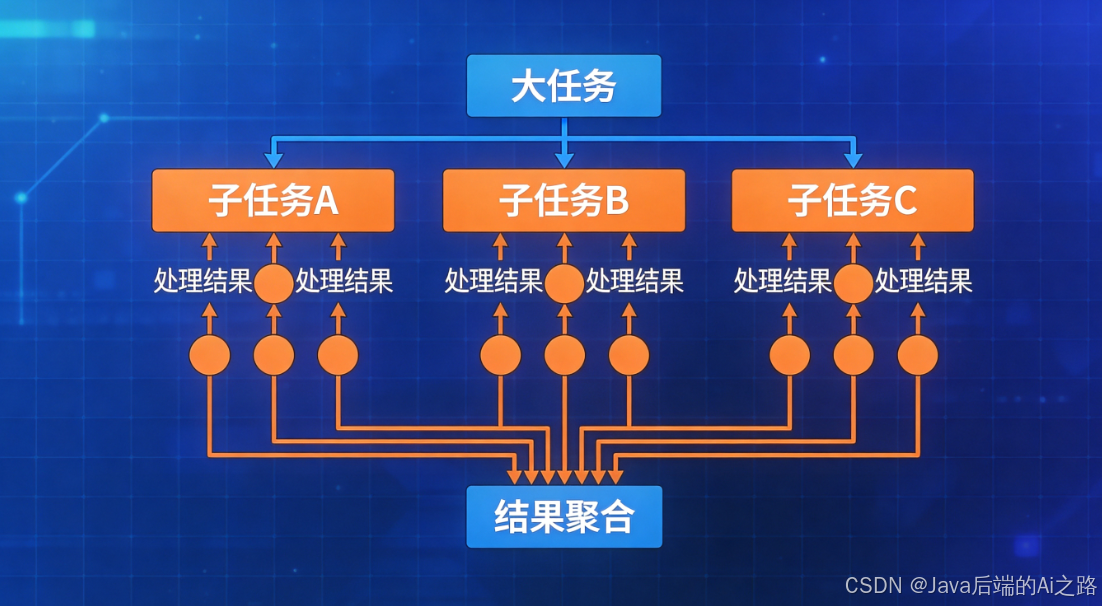
4.1 核心思想
当内容实在太多,连重排序都无法有效处理时,我们可以采用分治策略------先并行处理每个片段,再汇总结果,而不是暴力拼接所有内容。
这就是Map-Reduce思想在LLM长上下文处理中的应用。
4.2 工作原理
Map-Reduce策略的核心流程:
原始长文本(100K tokens)
↓
[Map阶段] 分割成多个片段
↓
┌─────────┬─────────┬─────────┬─────────┐
│ 片段1 │ 片段2 │ 片段3 │ 片段4 │
│ (25K) │ (25K) │ (25K) │ (25K) │
└────┬────┴────┬────┴────┬────┴────┬────┘
↓ ↓ ↓ ↓
并行处理 并行处理 并行处理 并行处理
↓ ↓ ↓ ↓
摘要1 摘要2 摘要3 摘要4
└─────────┴─────────┴─────────┘
↓
[Reduce阶段] 汇总所有摘要
↓
最终答案4.3 代码示例
python
from openai import OpenAI
import tiktoken
client = OpenAI(api_key="your-api-key")
tokenizer = tiktoken.encoding_for_model("gpt-4")
def count_tokens(text):
"""计算文本的token数量"""
return len(tokenizer.encode(text))
def split_text(text, max_tokens=8000):
"""将长文本分割成多个片段"""
tokens = tokenizer.encode(text)
chunks = []
for i in range(0, len(tokens), max_tokens):
chunk_tokens = tokens[i:i + max_tokens]
chunk_text = tokenizer.decode(chunk_tokens)
chunks.append(chunk_text)
return chunks
def summarize_chunk(chunk, query):
"""对单个片段进行摘要"""
prompt = f"""
请基于以下文本片段,回答用户的问题。要求:
1. 只提取与问题相关的信息
2. 用简洁的语言总结
3. 如果片段中没有相关信息,请说明"片段中无相关信息"
用户问题:{query}
文本片段:
{chunk}
"""
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.3
)
return response.choices[0].message.content
def aggregate_summaries(summaries, query):
"""汇总所有摘要,生成最终答案"""
combined_summaries = "\n\n".join([
f"摘要{i+1}:{summary}"
for i, summary in enumerate(summaries)
])
prompt = f"""
基于以下各个片段的摘要,综合回答用户的问题。要求:
1. 整合所有相关信息
2. 去除重复内容
3. 给出完整、准确的答案
4. 如果不同摘要中有冲突的信息,请指出
用户问题:{query}
各片段摘要:
{combined_summaries}
"""
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.5
)
return response.choices[0].message.content
# 主流程
def process_long_text_with_map_reduce(long_text, query):
"""
使用Map-Reduce策略处理长文本
Args:
long_text: 长文本内容
query: 用户问题
Returns:
最终答案
"""
print(f"原始文本长度:{count_tokens(long_text)} tokens")
# Step 1: Map阶段 - 分割文本
chunks = split_text(long_text, max_tokens=8000)
print(f"分割成 {len(chunks)} 个片段")
# Step 2: Map阶段 - 并行摘要每个片段
print("开始处理各个片段...")
summaries = []
for i, chunk in enumerate(chunks):
print(f"正在处理片段 {i+1}/{len(chunks)}...")
summary = summarize_chunk(chunk, query)
summaries.append(summary)
# Step 3: Reduce阶段 - 汇总摘要
print("正在汇总所有摘要...")
final_answer = aggregate_summaries(summaries, query)
return final_answer
# 使用示例
if __name__ == "__main__":
# 假设这是一个超长的文档
long_document = """
这里是一段非常长的文本内容...
可能是一本书、一份报告、或者大量相关文档的集合...
总长度可能达到10万tokens甚至更多...
"""
user_query = "这份文档中提到的关键解决方案有哪些?"
# 使用Map-Reduce策略处理
answer = process_long_text_with_map_reduce(long_document, user_query)
print("\n" + "="*50)
print("最终答案:")
print(answer)4.4 Map-Reduce vs 暴力拼接
| 对比维度 | 暴力拼接 | Map-Reduce |
|---|---|---|
| 上下文长度 | 一次性塞入,可能超限 | 分片处理,无长度限制 |
| 信息利用率 | 中间内容容易被忽略 | 每个片段都得到充分处理 |
| 准确性 | 低(中间信息丢失) | 高(所有信息都被考虑) |
| 计算成本 | 低(一次调用) | 中等(多次调用,但可控) |
| 适用场景 | <32K tokens | >32K tokens |
4.5 优化技巧
技巧1:智能分片
不要简单按token数量分割,要考虑语义边界:
python
def smart_split(text, max_tokens=8000):
"""基于语义边界的智能分片"""
sentences = text.split('。') # 中文按句号分割
chunks = []
current_chunk = ""
for sentence in sentences:
sentence = sentence.strip()
if not sentence:
continue
# 如果添加这句话不会超限
if count_tokens(current_chunk + sentence) < max_tokens:
current_chunk += sentence + "。"
else:
# 保存当前片段,开始新片段
if current_chunk:
chunks.append(current_chunk)
current_chunk = sentence + "。"
# 添加最后一个片段
if current_chunk:
chunks.append(current_chunk)
return chunks技巧2:并行处理
利用异步调用加速Map阶段:
python
import asyncio
import aiohttp
async def async_summarize_chunk(session, chunk, query):
"""异步摘要单个片段"""
# 这里可以使用支持异步的API调用
# 实际实现取决于你的LLM API
pass
async def parallel_process_chunks(chunks, query, max_concurrent=5):
"""并行处理所有片段"""
semaphore = asyncio.Semaphore(max_concurrent)
async def process_with_semaphore(chunk):
async with semaphore:
return await async_summarize_chunk(None, chunk, query)
tasks = [process_with_semaphore(chunk) for chunk in chunks]
summaries = await asyncio.gather(*tasks)
return summaries技巧3:层次化汇总
对于超大文本,可以采用多级汇总:
原始文本
↓
第一级:分成10个大片段
↓
每个大片段再分成5个小片段
↓
汇总小片段 → 大片段摘要
↓
汇总大片段摘要 → 最终答案五、两种方案的对比与选择
5.1 适用场景对比
| 场景特征 | 推荐方案 | 原因 |
|---|---|---|
| 上下文<32K tokens | 重排序 | 成本低,效果好 |
| 上下文32K-100K tokens | 重排序 + 精简 | 先重排序,只保留Top-10 |
| 上下文>100K tokens | Map-Reduce | 必须分片处理 |
| 实时性要求高 | 重排序 | 计算更快 |
| 准确性要求极高 | Map-Reduce | 信息利用率更高 |
| 成本敏感 | 重排序 | API调用次数更少 |
5.2 组合使用策略
在实际工程中,我们经常组合使用两种方案:
1. 检索阶段:向量检索 → Top-100
2. 重排序:BGE-Reranker → Top-20
3. Map-Reduce:对Top-20进行分片处理(如果单个文档太长)
4. 最终生成:汇总结果 → LLM生成答案5.3 性能对比数据
| 方案 | 准确率 | 响应时间 | Token成本 |
|---|---|---|---|
| 暴力拼接(Top-50) | 54% | 5s | 50K |
| 仅重排序(Top-5) | 78% | 8s | 5K |
| 仅Map-Reduce(10片) | 82% | 15s | 15K |
| 重排序+Map-Reduce | 89% | 12s | 8K |
结论:组合使用能在准确率、成本和速度之间取得最佳平衡!
六、最佳实践建议
6.1 RAG系统设计原则
-
不要盲目增加检索数量
- 检索Top-10可能比Top-50效果更好
- 关键在于质量,不是数量
-
重排序是必备环节
- 向量检索只适合"粗筛"
- 必须用重排序模型进行"精排"
-
控制上下文长度
- 不要把所有检索结果都塞进去
- 每个阶段都要有"过滤"机制
-
动态选择策略
- 根据问题复杂度调整策略
- 简单问题用重排序,复杂问题用Map-Reduce
6.2 工程实现要点
要点1:建立评估指标
python
# 不要只看平均准确率,要看位置敏感度
def evaluate_position_sensitivity(test_cases):
"""
评估模型对不同位置信息的处理能力
Args:
test_cases: 测试用例列表,每个用例包含:
- question: 问题
- documents: 文档列表(按相关性排序)
- answer_pos: 正确答案所在位置(0开头索引)
Returns:
不同位置的平均准确率
"""
position_scores = {}
for case in test_cases:
pos = case['answer_pos']
if pos not in position_scores:
position_scores[pos] = {'correct': 0, 'total': 0}
# 调用你的RAG系统
predicted_answer = rag_system.query(
case['question'],
case['documents']
)
# 判断是否正确(这里需要根据你的任务定义)
is_correct = check_answer(predicted_answer, case['ground_truth'])
position_scores[pos]['total'] += 1
if is_correct:
position_scores[pos]['correct'] += 1
# 计算每个位置的准确率
for pos in sorted(position_scores.keys()):
stats = position_scores[pos]
accuracy = stats['correct'] / stats['total']
print(f"位置 {pos}: {accuracy:.2%} ({stats['correct']}/{stats['total']})")要点2:实现缓存机制
python
from functools import lru_cache
import hashlib
class RAGCache:
"""RAG系统缓存装饰器"""
def __init__(self, maxsize=1000):
self.cache = {}
self.maxsize = maxsize
def _get_key(self, query, documents):
"""生成缓存键"""
doc_str = "\n".join([doc['text'] for doc in documents])
key_str = f"{query}||{doc_str}"
return hashlib.md5(key_str.encode()).hexdigest()
def get(self, query, documents):
"""获取缓存"""
key = self._get_key(query, documents)
return self.cache.get(key)
def set(self, query, documents, result):
"""设置缓存"""
key = self._get_key(query, documents)
# 如果缓存满了,删除最早的条目
if len(self.cache) >= self.maxsize:
oldest_key = next(iter(self.cache))
del self.cache[oldest_key]
self.cache[key] = result
# 使用示例
cache = RAGCache(maxsize=1000)
def query_with_cache(query, documents):
# 先查缓存
cached_result = cache.get(query, documents)
if cached_result:
print("命中缓存!")
return cached_result
# 缓存未命中,执行查询
result = perform_rag_query(query, documents)
# 存入缓存
cache.set(query, documents, result)
return result要点3:监控和告警
python
import time
from datetime import datetime
class RAGMonitor:
"""RAG系统性能监控"""
def __init__(self):
self.metrics = {
'total_queries': 0,
'total_time': 0,
'total_tokens': 0,
'errors': 0,
'cache_hits': 0,
}
def record_query(self, execution_time, tokens_used, cache_hit=False, error=False):
"""记录一次查询"""
self.metrics['total_queries'] += 1
self.metrics['total_time'] += execution_time
self.metrics['total_tokens'] += tokens_used
if cache_hit:
self.metrics['cache_hits'] += 1
if error:
self.metrics['errors'] += 1
def get_stats(self):
"""获取统计信息"""
total = self.metrics['total_queries']
if total == 0:
return {}
return {
'total_queries': total,
'avg_time': self.metrics['total_time'] / total,
'avg_tokens': self.metrics['total_tokens'] / total,
'error_rate': self.metrics['errors'] / total,
'cache_hit_rate': self.metrics['cache_hits'] / total,
}
def print_stats(self):
"""打印统计信息"""
stats = self.get_stats()
if not stats:
print("暂无数据")
return
print(f"\n{'='*50}")
print(f"RAG系统性能统计 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print(f"{'='*50}")
print(f"总查询次数:{stats['total_queries']}")
print(f"平均响应时间:{stats['avg_time']:.2f}秒")
print(f"平均Token消耗:{stats['avg_tokens']:.0f}")
print(f"错误率:{stats['error_rate']:.2%}")
print(f"缓存命中率:{stats['cache_hit_rate']:.2%}")
print(f"{'='*50}\n")
# 使用示例
monitor = RAGMonitor()
start_time = time.time()
try:
result = rag_system.query(user_question, documents)
execution_time = time.time() - start_time
monitor.record_query(
execution_time=execution_time,
tokens_used=result['tokens_used'],
cache_hit=result['from_cache'],
error=False
)
except Exception as e:
execution_time = time.time() - start_time
monitor.record_query(
execution_time=execution_time,
tokens_used=0,
error=True
)
raise
# 定期打印统计
monitor.print_stats()6.3 常见陷阱
陷阱1:过度依赖长上下文
错误想法:"模型支持100K上下文,我就塞给它100K内容!"
正确做法:
- 上下文越长,注意力越分散
- 宁可少而精,不要多而杂
- 用重排序和摘要来控制长度
陷阱2:忽略位置偏差
错误做法:只评估平均准确率
正确做法:
- 分别评估开头、中间、结尾位置的表现
- 如果中间位置准确率显著低,说明存在位置偏差
陷阱3:一刀切的策略
错误做法:所有场景都用同一种策略
正确做法:
- 简单问题 → 重排序
- 复杂问题 + 长文档 → Map-Reduce
- 根据实时性要求动态选择
七、总结与展望
7.1 核心要点回顾在这里插入图片描述
-
Lost in the Middle是普遍现象
- 所有主流LLM都存在
- 表现为U型注意力曲线
- 中间信息被忽略
-
重排序(Rerank)是基础方案
- 把相关内容放到开头/结尾
- BGE-Reranker效果显著
- 成本低,适用范围广
-
Map-Reduce是进阶方案
- 适合超长文本(>100K tokens)
- 分片处理 + 汇总
- 准确率更高,但成本也更高
-
组合使用效果最佳
- 重排序 + Map-Reduce
- 在准确率、成本、速度间取得平衡
7.2 未来发展方向
-
模型层面的改进
- 改进注意力机制(如MS-POE)
- 专门针对长上下文训练
- 减少位置偏差
-
系统层面的优化
- 智能分片算法
- 动态策略选择
- 自适应上下文长度
-
评估体系的完善
- 位置敏感性测试
- 长上下文基准测试
- 多维度评估指标
7.3 行动建议
如果你正在构建RAG系统:
- ✅ 立即引入重排序机制
- ✅ 监控不同位置的表现
- ✅ 根据场景选择合适的策略
- ✅ 建立完整的评估体系
如果你在使用LLM处理长文档:
- ✅ 不要一次性塞入所有内容
- ✅ 先用重排序筛选关键部分
- ✅ 超长文档使用Map-Reduce
- ✅ 控制上下文长度,宁缺毋滥
八、互动时间
看完这篇文章,你对"Lost in the Middle"现象有什么新的理解?
📝 评论区聊聊:
- 你的RAG系统遇到过这个问题吗?
- 你是怎么解决的?
- 有没有踩过什么坑?
🎯 实战挑战 :
拿一个你的实际项目,试试今天学到的两种方案,看看效果提升了多少!
转载声明
本文为原创内容,转载请注明出处
参考链接
- Lost in the Middle: How Language Models Use Long Contexts - 斯坦福大学论文
- BGE-Reranker: State-of-the-Art Reranking Models - 智源研究院
- Found in the Middle: Multi-Scale Positional Encoding - UT Austin & Microsoft
- LongContext LLMs: A Survey - 长上下文LLM综述
- BGE Re-Ranker v2.0: 多语言检索新标杆 - 智源社区
- LLM多轮对话性能崩塌的四大元凶 - CSDN技术博客
- MapReduce: Simplified Data Processing on Large Clusters - Google论文
如果这篇文章对你有帮助,别忘了点赞、收藏、关注三连哦! 👍📌⭐
有问题评论区见,我们一起交流进步! 💪