1Backbone骨干网络 Darknet-53
1.1 为什么YOLOv3要求输入尺寸是32的倍数
YOLO v3使用Darknet-53 作为backbone,其特征提取过程包含5次stride=2的下采样:
输入图像 → 卷积+下采样 → 特征图尺寸变化
416 × 416
↓ ÷2 (第1次)
208 × 208
↓ ÷2 (第2次)
104 × 104
↓ ÷2 (第3次)
52 × 52
↓ ÷2 (第4次)
26 × 26
↓ ÷2 (第5次)
13 × 13 ← 最深特征图
5次下采样 = 缩小 2⁵ = 32 倍
特征图尺寸必须是整数:
-
若输入 415×415 :415 ÷ 32 = 12.968 ❌ 不是整数
-
若输入 416×416 :416 ÷ 32 = 13 ✅ 整数
5次下采样导致总stride=32,为保证特征图尺寸为整数且多尺度特征能正确融合,输入必须是32的倍数。
1.2关键点回顾
- 卷积:小窗口(卷积核)在图像上滑动,提取局部特征(边缘,纹理)
- stride(步长):控制移动距离,每次移动一格/两格
- 下采样:缩小特征图,把高分辨率特征图变成低分辨率的过程-->增大感受野,减小计算量,提取高级特征。
- 卷积(Conv) ──┬── 提取特征(边缘→纹理→部件→物体)
│
└── 参数stride控制 ──┬── stride=1: 保持尺寸
│
└── stride=2: 下采样(尺寸÷2)
↓
多次下采样后
↓
特征图变小,通道变多
↓
总下采样倍数 = 2^n
↓
输入尺寸必须是其倍数(YOLO中是32) - 卷积是"看"图像的方式,stride是"看"的步长,stride=2的卷积就是"跳着看"同时"记要点"(下采样),YOLO v3跳了5次(2⁵=32),所以输入必须是32的倍数才能整除。

1.3 为啥要更换这个网络?
1.3.1原因1:解决梯度消失,能训练更深网络
生活化类比理解什么是残差连接
普通网络(无残差):
发件人 → 中转站1 → 中转站2 → ... → 中转站N → 收件人
每个中转站必须"重新打包"记住全部信息
中转站越多,包裹越容易丢/错(梯度消失)
残差网络(有残差连接):
发件人 ─→ 中转站1 ─→ 中转站2 ─→ ... ─→ 收件人
↓ ↑
└────────────────────────┘
开设"直达专线"
每个中转站只需要记住"和原包裹的差异"
即使中转站出错,还有原包裹保底
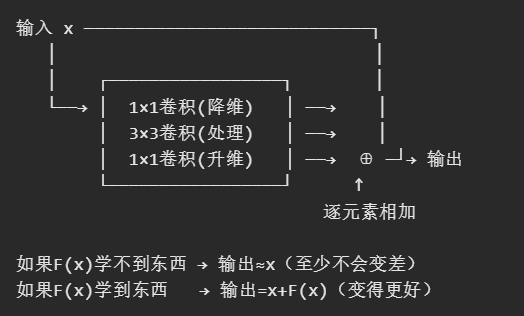
数学表达:
普通层要学的: H(x) = 复杂的映射(很难学)
残差层要学的: F(x) = H(x) - x (残差,即"变化量")
实际输出: y = F(x) + x = H(x)学"变化量"比学"完整映射"容易得多!
残差连接直观理解:
1.3.2 原因2:更强的特征提取能力
检测任务需要两种特征:
├── 深层特征(13×13):大感受野,知道"这是猫"(语义信息)
└── 浅层特征(52×52):小感受野,知道"猫耳朵在这里"(位置信息)
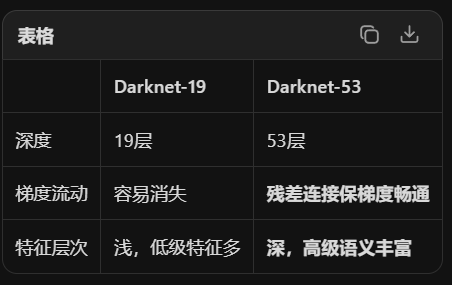
Darknet-53:
├── 53层深度 → 深层语义极强(比19层理解更抽象的"物体概念")
└── 残差结构 → 保留更多细节信息(跳跃连接像"记忆通道")
实际效果 :在ImageNet分类上,Darknet-53和ResNet-152精度相当,但速度快2倍。
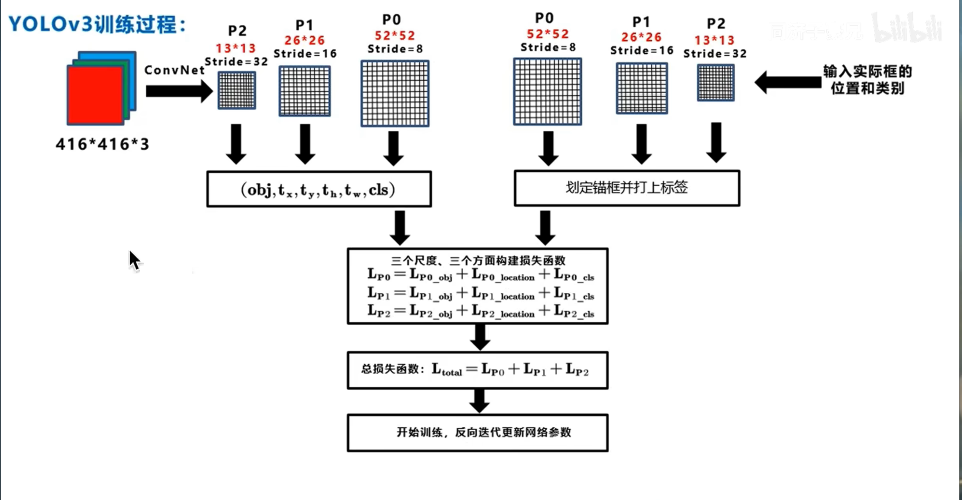
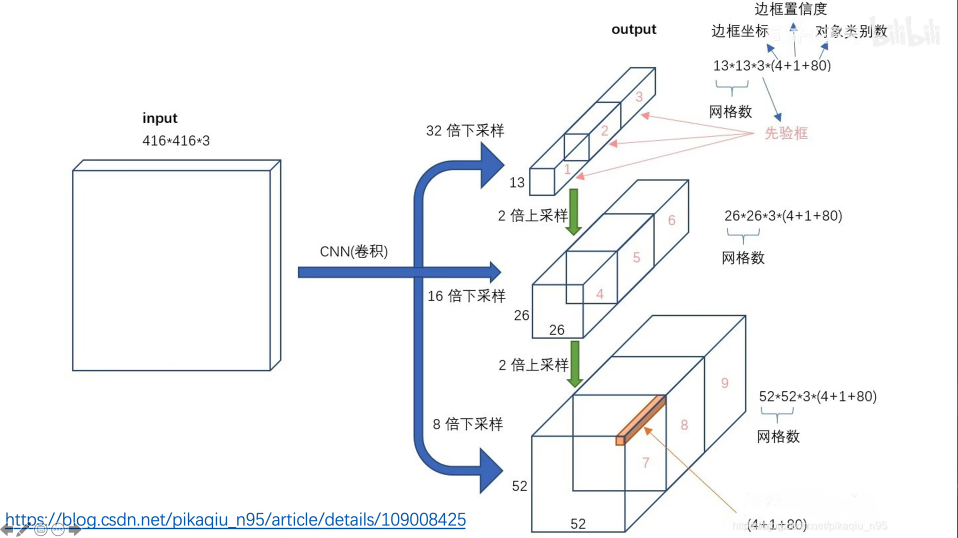
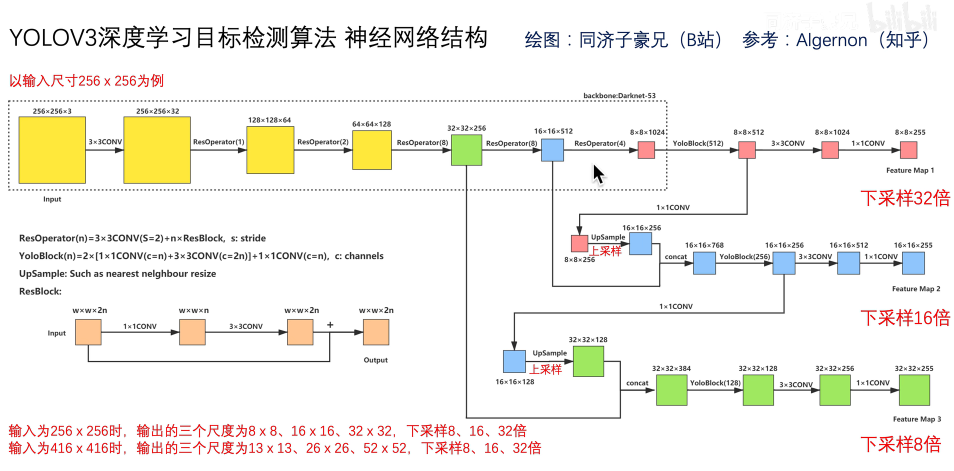
2 YOLO v3网络结构
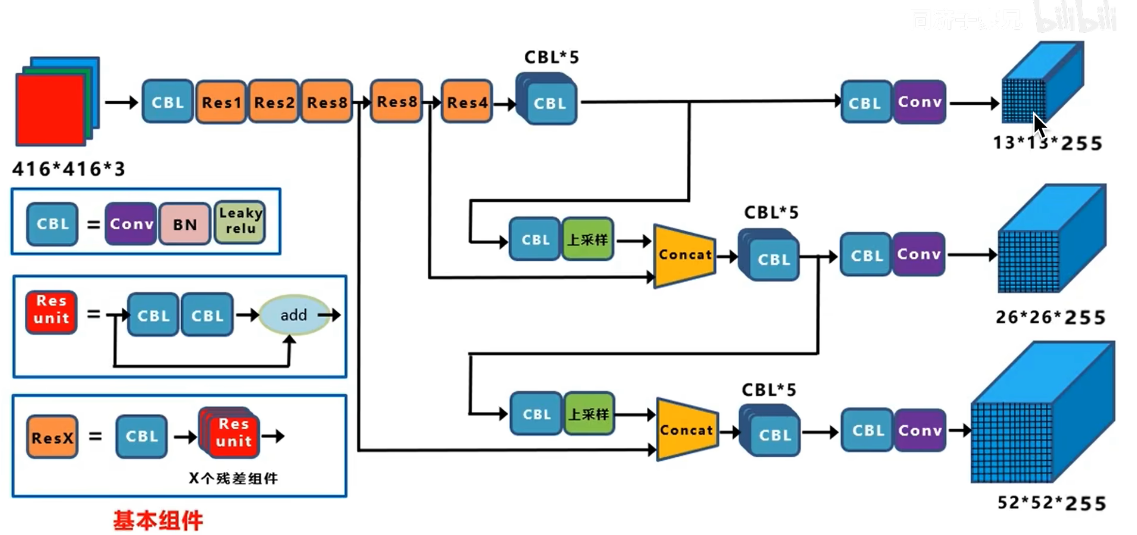
52*52*255 这一路 既发挥了深层网络的语义特化抽象的特征,也发挥了浅层网络细粒度像素级别的,边缘转角和结构信息的底层特征,通过这个结构就可以实现多尺度的特征融合和不同尺度物体的预测
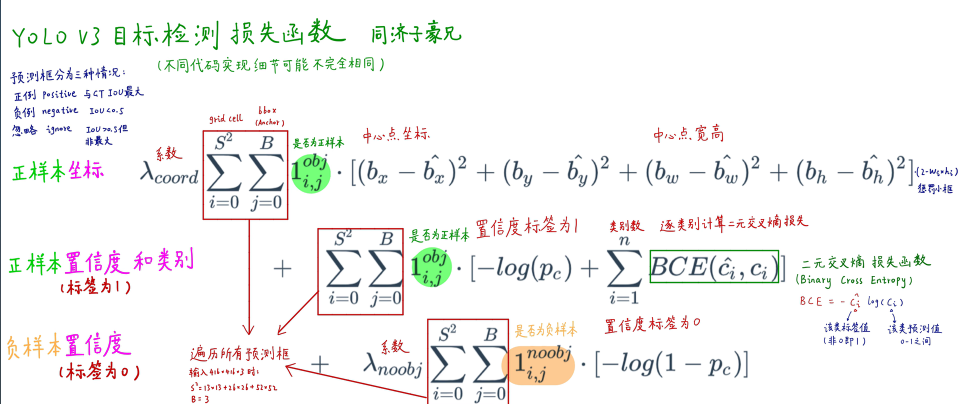
YOLOv3损失函数