1.环境变量
下面来说说环境变量,windows中存在环境变量(右键此电脑->属性->高级系统设置->环境变量):
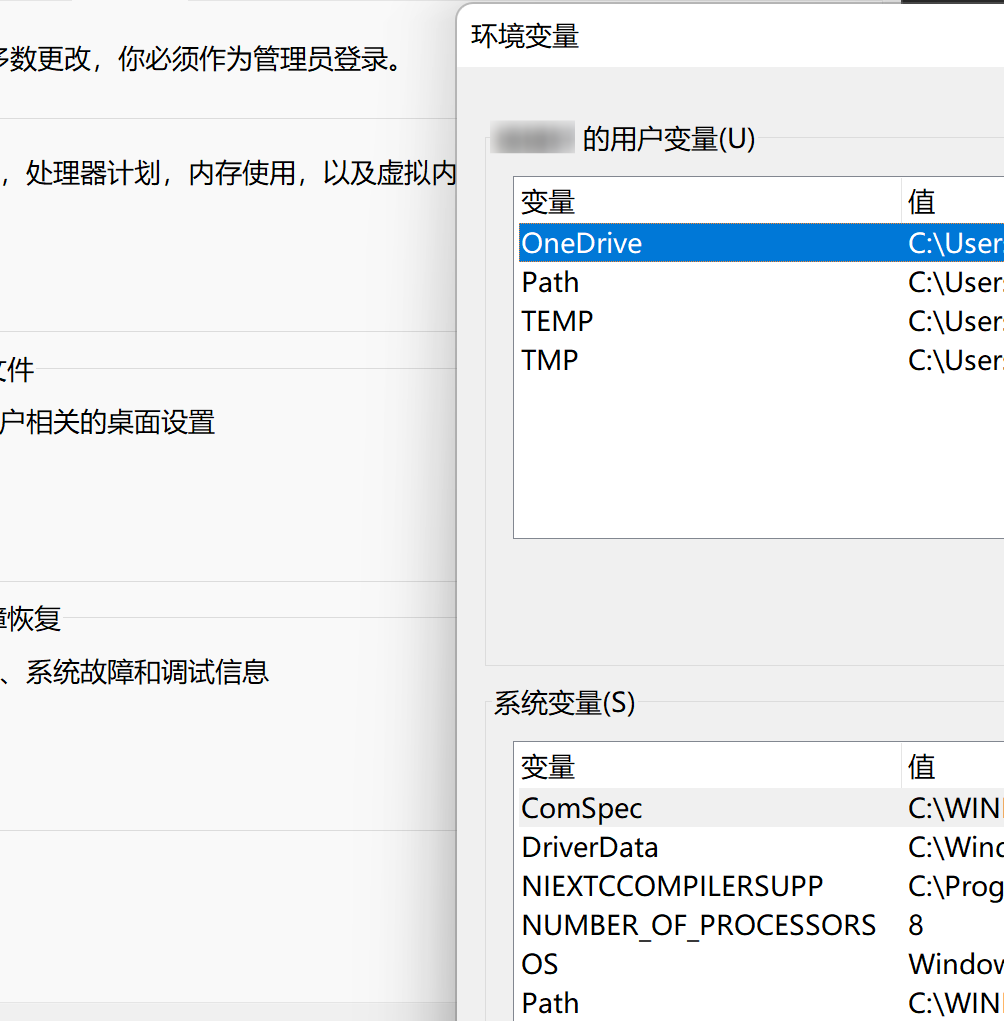
可以看到环境变量里有变量名和值,所以环境变量其实是由OS帮我们维护的一组KV值。那环境变量有什么用?这里先直接挑出3~4个环境变量来认识一下都是干什么的,做一些实验,然后再来看什么是环境变量。下面来看:
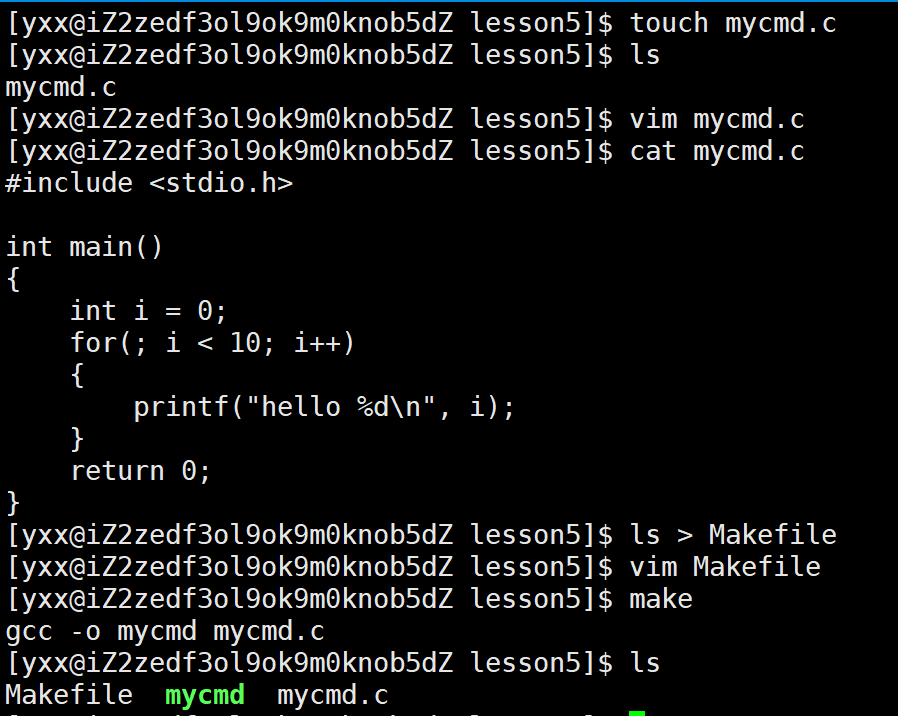
以前说过自己写的程序就是指令,为什么运行ls,pwd这样的指令不用带./,运行自己的指令必须带./呢,不带会报错说不认识,这是为什么?像which pwd看到pwd在/usr/bin这样的系统默认指令所搜路径,所以执行对应指令不用带路径;pwd看到当前处于用户工作目录下不在系统指令搜索路径下,所以直接执行不了我们写的程序,这又是为什么?包括which为啥可以快速搜索到路径呢?因为系统当中针对指令搜索,我们Linux系统会为我们提供一个环境变量,这个环境变量叫PATH。这个环境变量是在系统中已经在我们开机、登陆自己的xshell时天然存在的,若想查看PATH环境的内容,此时echo PATH不行,会把它当字符串来用,所以要echo $PATH来提取环境变量的内容:

此时看到里面包含了一堆路径,一串路径,冒号,再一串路径,用冒号作为分割符,在PATH中定义了非常多的路径,这上面的每一条路径,就是一般在执行指令的时候系统查找指令对应的路径。换言之系统怎么知道ls,pwd在哪里呢?因为OS在执行命令时我们的shell会首先在PATH下的一个一个路径中找,因为在/usr/bin下找到了,所以再不往后找了,直接执行该路径下的ls程序,所以执行时不用带路径了。比如执行mycmd,它在/home/yxx/lesson5这个路径下,在PATH下找都不在,找到时候发现并不在系统默认的指令搜索路径下,所以直接执行mycmd时报出command not found。因此第一个我们系统中所对应的环境变量是PATH,它是Linux系统的指令搜索路径。这就是为什么执行指令时不用带路径,因为把系统对应的输入当指令的话会自动去系统的PATH环境变量中进行查找。那如果我当前所处路径添加到PATH环境变量里,那我是不是就能直接执行指令不用再带./呢?PATH=路径,直接这样是用现在的路径把PATH环境变量里的值都覆盖了,因此要这样:
 此时echo $PATH发现环境变量对应的路径中多了一个,此时把我的路径添加到了系统的环境变量里。此时./mycmd和mycmd都可以直接跑:
此时echo $PATH发现环境变量对应的路径中多了一个,此时把我的路径添加到了系统的环境变量里。此时./mycmd和mycmd都可以直接跑:
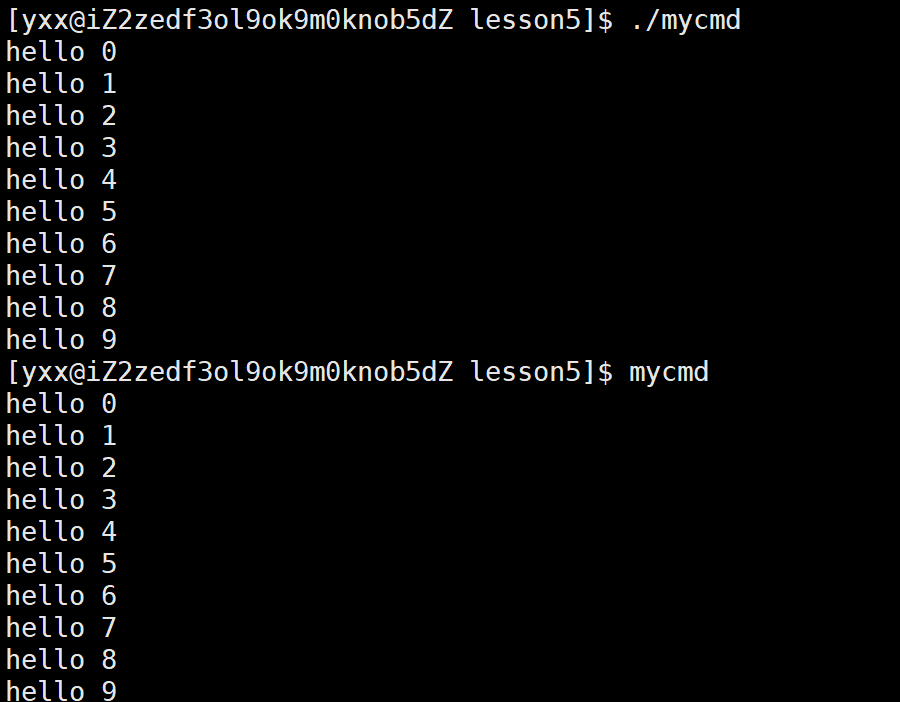
不用带路径了,因为当前系统当前在环境变量能够找到可执行程序了,甚至which也能找到mycmd所在的路径。因此得到了两个结论:1.系统中的shell内部会维护一个PATH环境变量,它指明系统指令的搜索路径。2.which是根据环境变量来搜索指令的,假如直接把环境变量覆盖式的改了:PATH=/home/yxx/lesson5,此时系统中的所有指令不带路径都跑不了了。这样改的PATH是内存级的环境变量,改错了把xshell关了重新登一下就恢复了。
下面再来看个环境变量,平时登陆后pwd看到是/home/xxx,用ssh的root方式登陆一下,再echo $HOME看到/root,pwd后也是/root:

那怎么知道登后默认在哪个路径下?因为当我们登陆时会直接识别到账户是谁,然后填充HOME这样的环境变量,然后就默认cd $HOME进了我们的所看到的路径。系统中怎么知道当前用的哪一个shell呢?:

可以看到当前shell所对应的可执行程序。除了以上其实还有非常多的环境变量,那我应该怎么查这么多的环境变量呢?可用env:
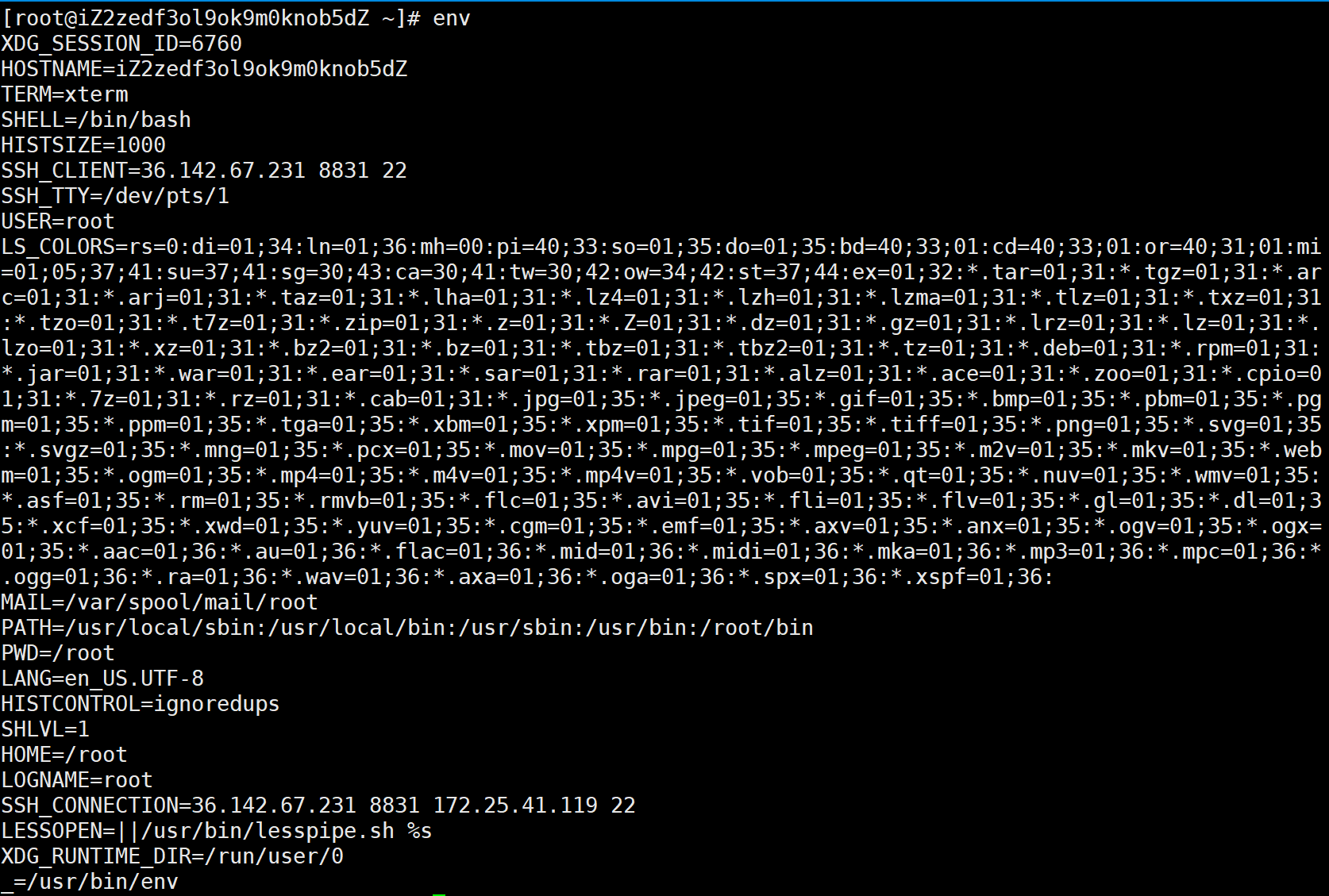
可查看到当前你自己的进程及以bash进程从系统里继承下的所有环境变量,如HOSTNAME代表当前机器主机名,通过HOSTNAME知道当前机器是谁;HISTSIZE保存历史命令被记录下的条数,环境变量约束xhell不要记录太多指令;SSH_TTY是当前终端设备文件,写个hello到这个终端可把消息打印到这个终端:
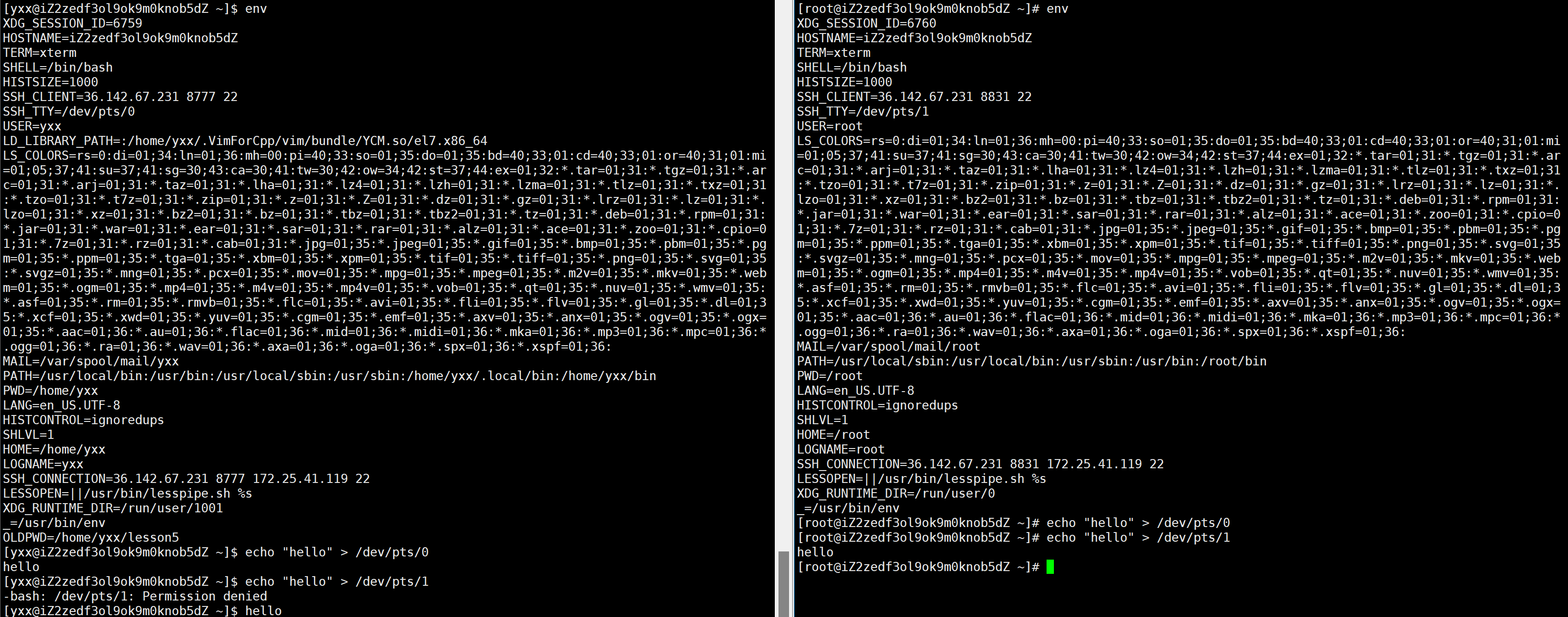
也就是说现在左右各是一个终端。PWD代表当前进程所对应的路径;USER代表当前用户;OLDPWD记录上一次所处的路径。
下面再来看,以前谈权限时会说是拥、所、O会分别怎么样,那么不管权限怎么弄首先要认识我是谁。下面做个小实验:
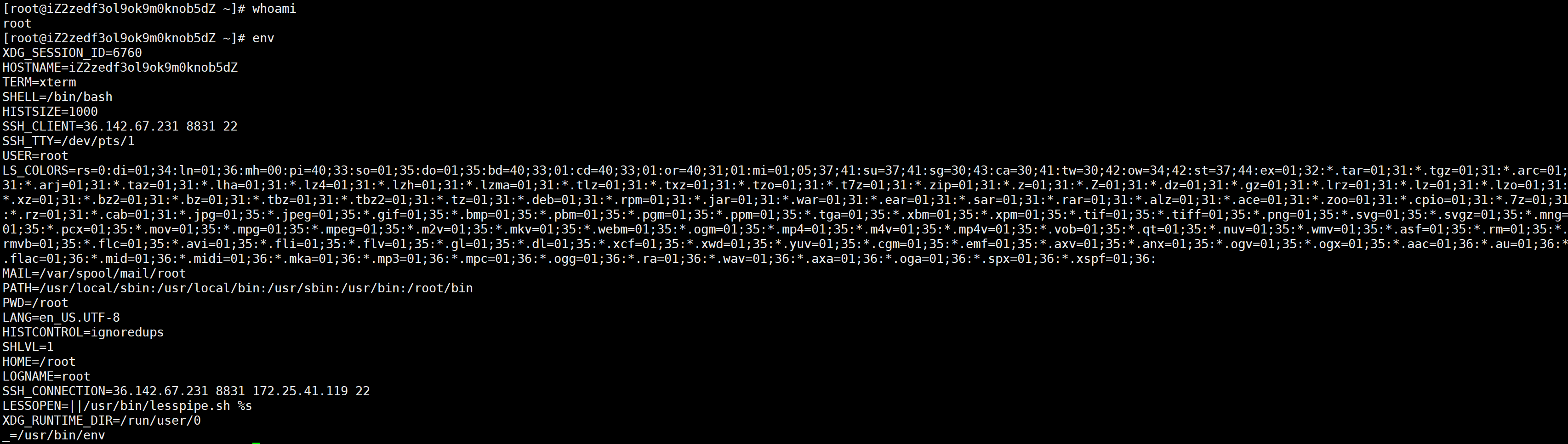
当前我是root,env后里面有USER和LOGNAME,两个都是root。现在su yxx把账号切一下变成普通用户,再env:
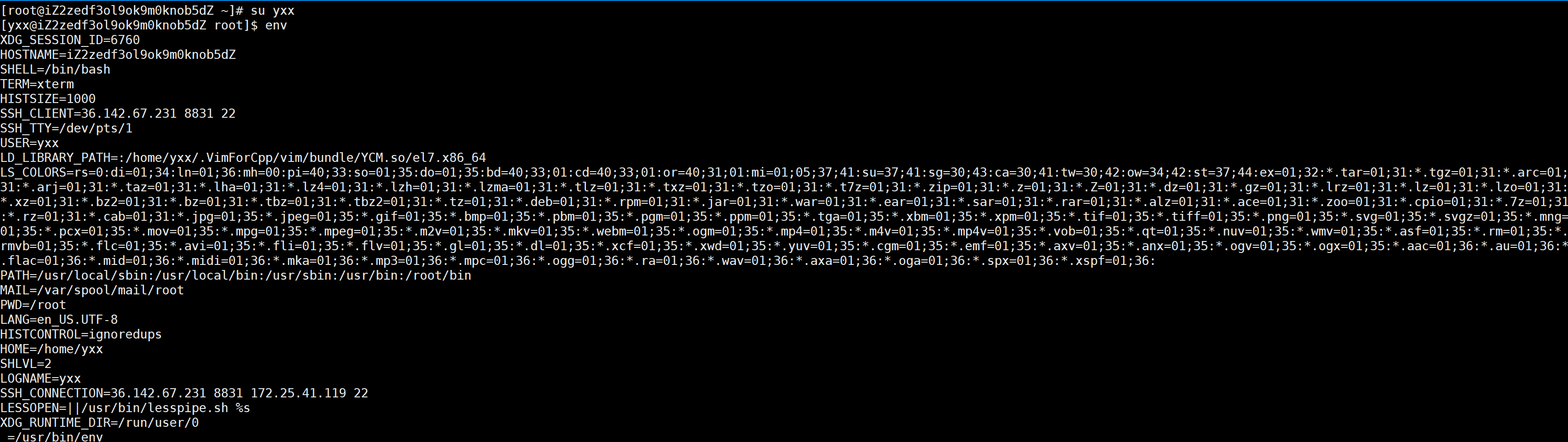
发现USER和LOGNAME变成了yxx,用户在进行变换时USER和LOGNAME都会发生变换。环境变量可通过指令的方式来查看,可是我未来一个指令用环境变量不可能把env跑一下,所以有一个系统调用接口可以获得:
把环境变量名字交过来,通过函数在系统层面把系统环境变量所对应的内容返回。比如:
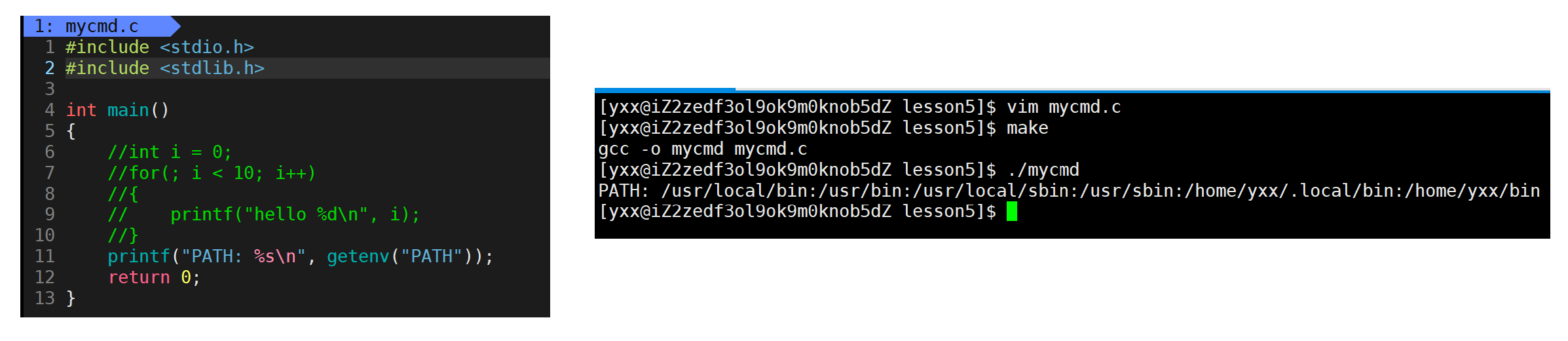
发现可用c/c++的方式通过getenv来获取环境变量。所以可这样:
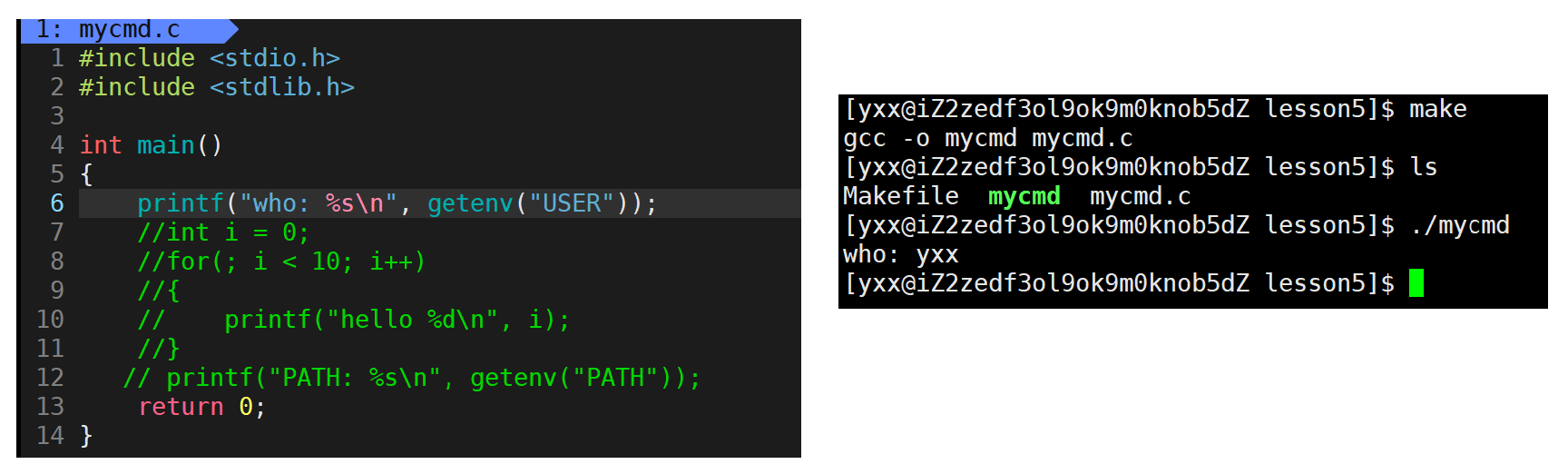
此时运行认识到我当前是whb,然后用root,cd/home/whb下同样的目录:
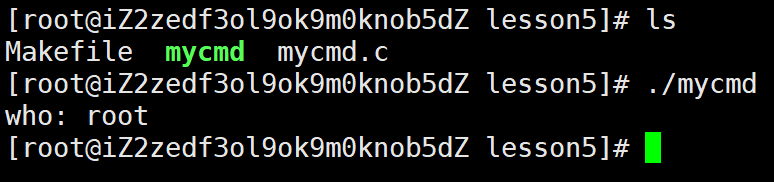
运行后看到是root,所以程序内部可通过获取环境变量来获知当前是哪个人在执行指令。那么权限理解可以更进一步:
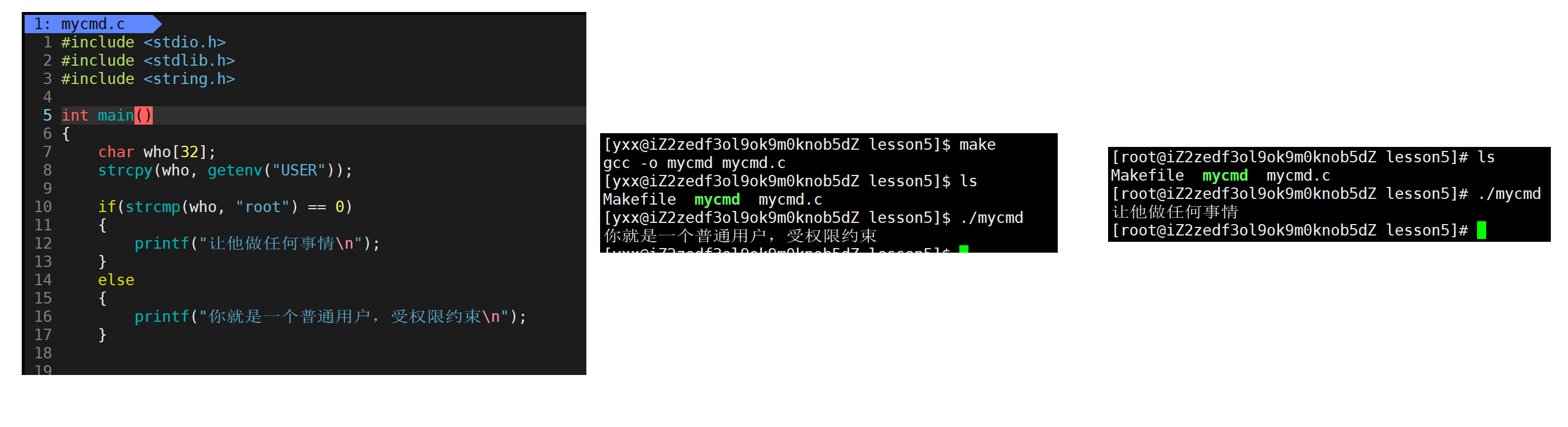
所以有环境变量存在,系统就具备了认识你这个人是谁的能力,这样可和文件中属性中的文件拥有者、所属组、权限做对比,进而判定是否可读写。
下面来看看什么是环境变量呢?环境变量是系统提供的一组name=value形式的变量,不同的环境变量有不同的用途,通常具有全局属性。那什么叫全局属性呢?前面自己编写好的可执行程序能通过函数获取环境变量,那获取环境变量有其它方式吗?接下来说个知识点叫命令行参数,我们是否见过main函数是可以带参数的?:

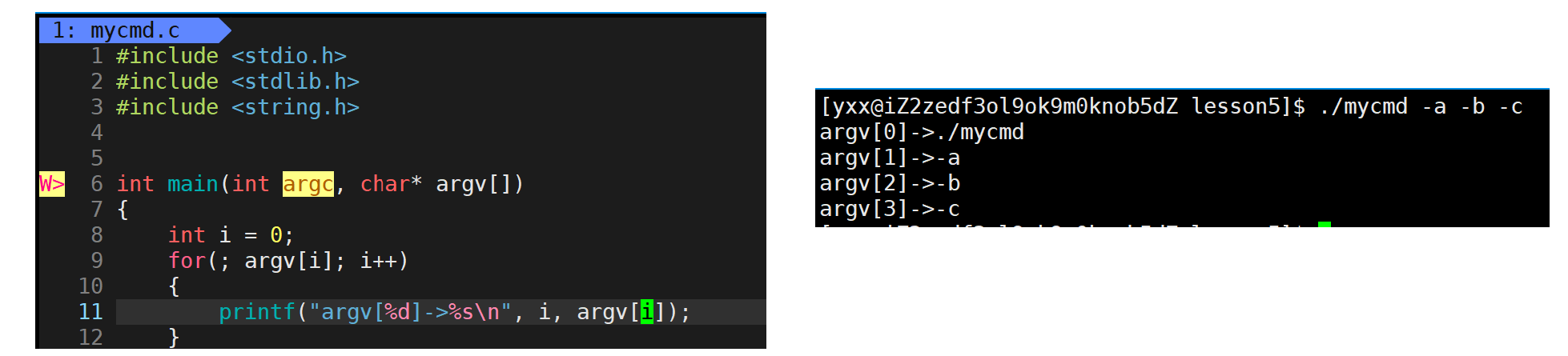
char* argv\[\]是个指针数组,数组中的元素保存字符中的地址,这个数组有多少个元素由argc决定。也不懂是什么,先打印出来看看:
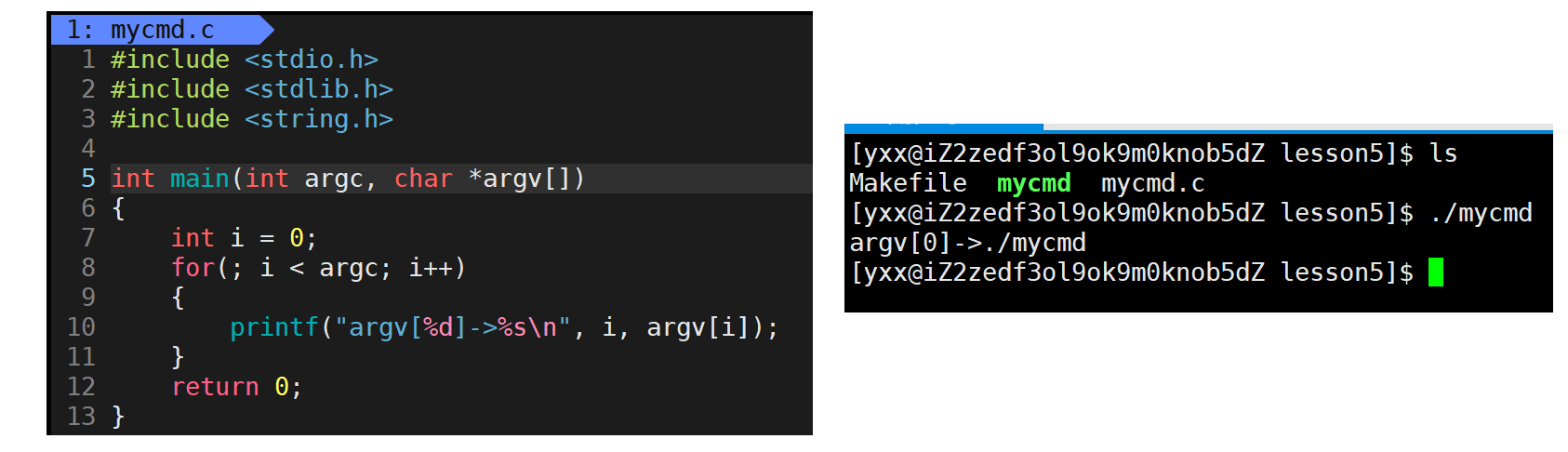
发现命令行参数只有一个,指向./mycmd。再看下图:
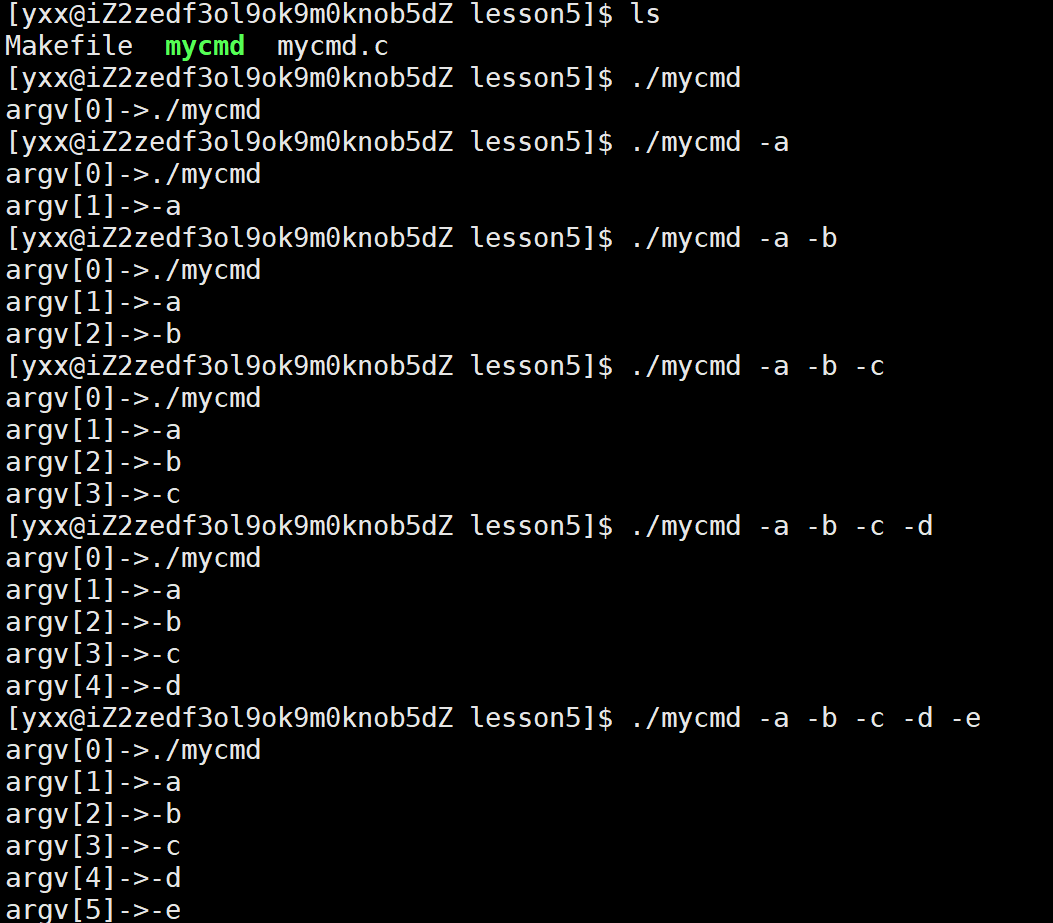
char*argv\[\]是个指针数组,一共有argc个元素,当我们的c语言程序被运行起来的时候,argc和argv这两个参数会被调用方传参,main函数是函数,所以main函数除了调别人也能被调用,因此main不是第一个被调用的,第一个被调用的是Startup(),所以main函数可以被别人传参。在命令行中我们认为输入的是./mycmd -a -b -c这样,其实输入的是"./mycmd -a -b -c",在bash看来输的是字符串。basn做命令行解释时把这个字符串打散成4个字符串:" ./mycmd","-a","-b","-c",然后依据这个初始化argc是4,每个子串的起始地址保存在argv中,然后传给main函数:
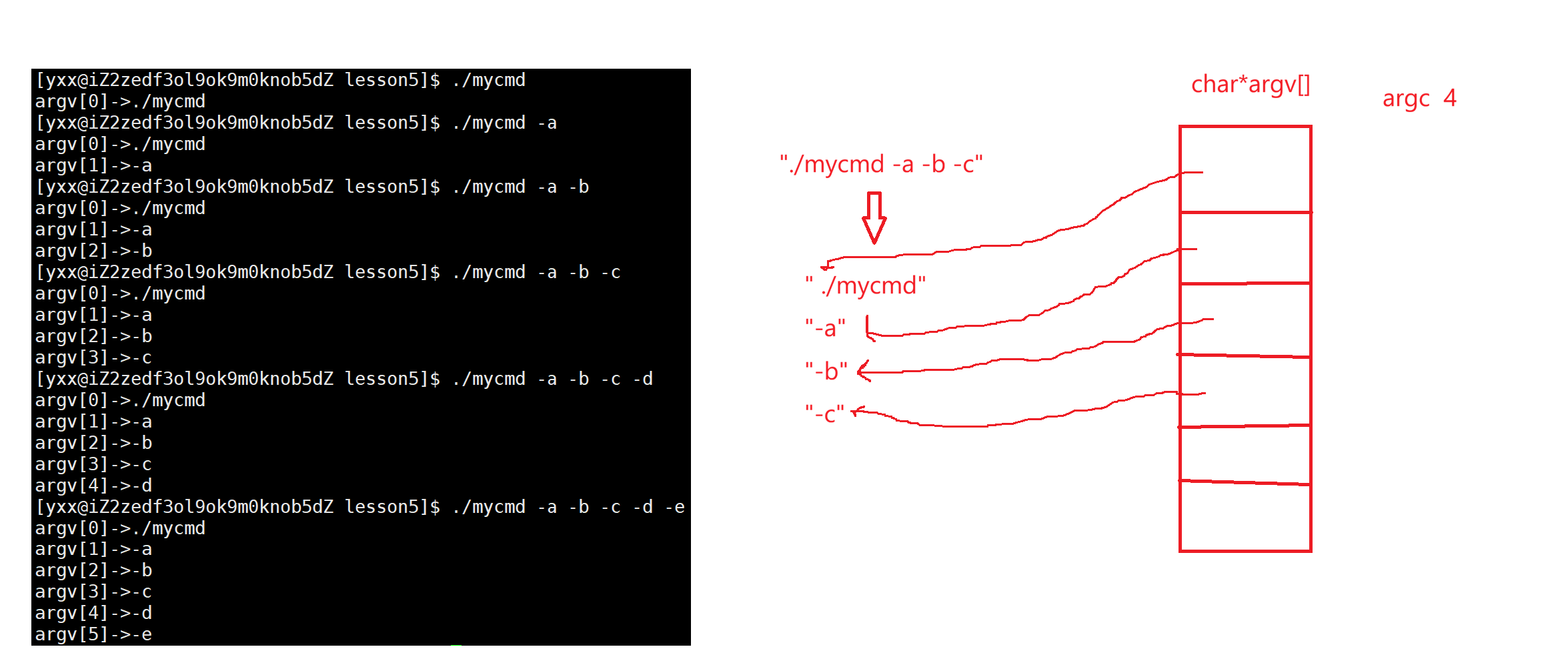
./mycmd -a -b -c叫命令行参数,命令行参数以空格作为分割符,打散成子串,然后传给main函数。那为什么这样做呢:
因此命令行参数有个重要的用途是为指令、工具、软件等提供命令行选项的支持。一般argv这个命令行参数,它把字符串依次指向了,除了argc是4,最后一个会被设置为空:
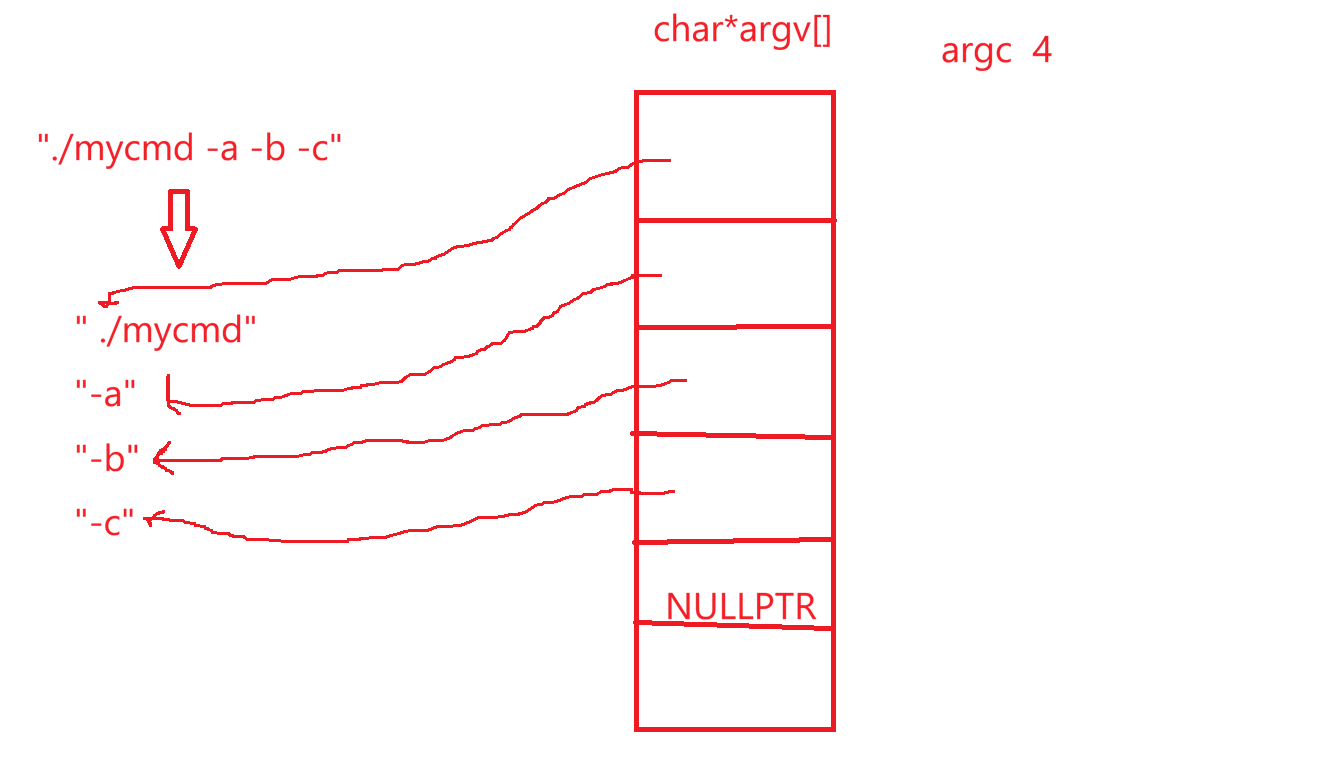
所以若想遍历系统命令行参数,可以:
再看下一部分,main函数只会有argc和argv吗,还有没有其它参数呢?有的,这个参数是cahr*env\[\],它也是一个指针数组:

它是一个环境变量,它的结构和argv结构是一模一样的。因此c/c++代码一共有两张核心向量表,一张叫命令行参数,另一张叫环境变量表。env的有效指针指向的都是一个个环境变量,下面证明一下:
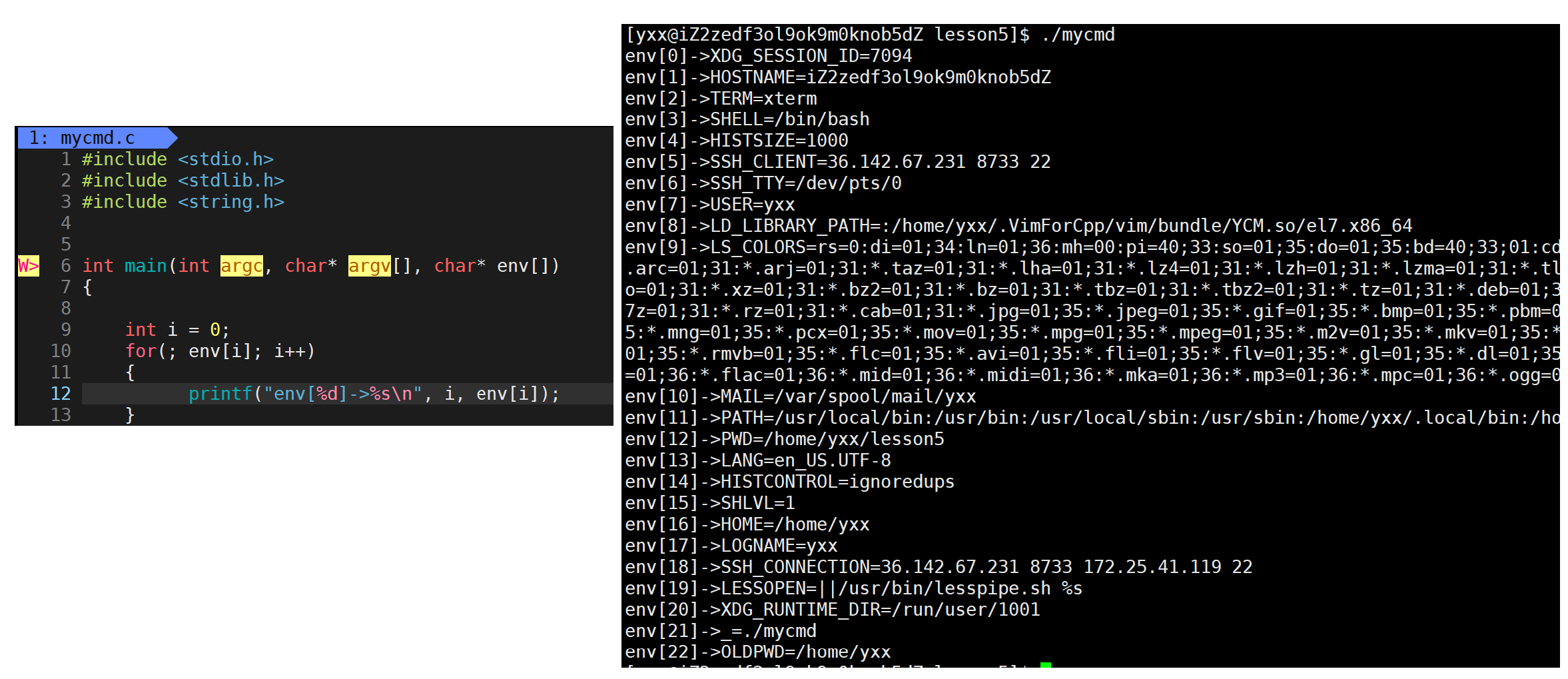
发现竟然打印出来了环境变量。因此一个进程在运行时,不要简单认为进程启动就是把程序加载到内存,而是一定有人调用main函数把两张向量表传进去了。我们所运行的进程都是子进程,没有子进程时系统中bash本身在启动的时候,会从OS的配置文件中读取环境变量信息,子进程会继承父进程交给我们的环境变量。若将来自己代码也创建子进程,从bash做为起始点开始它的子进程可再创建子进程,环境变量会被所有子进程继承下去。这句话告诉我们从当前bash开始,往后命令行上所运行的所有程序全部都会认识我曾经定义的环境变量,所以说环境变量是具有全局属性的。下面有些细节:1.环境变量也是数据,默认情况下是父子共享的,进程有独立性,若子进程想修改环境变量,不能影响父进程,会写时拷贝。2.前面写代码没传过env,因为环境变量被继承的方式有两种方式,一种是直接继承,一种是传参。下面有个问题,怎么验证环境变量被子进程继承了?直接MY_VALUE=12345678这样定义的是本地变量,不是环境变量。若想让MY_VALUE变成环境变量,可以这样:
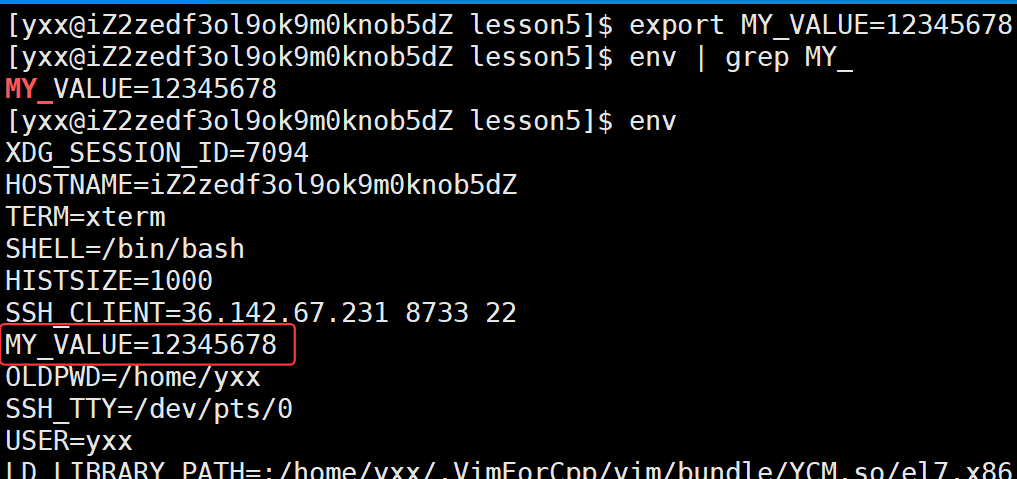
可以看到把这个环境变量写到了bash的上下文里,此时./mycmd:
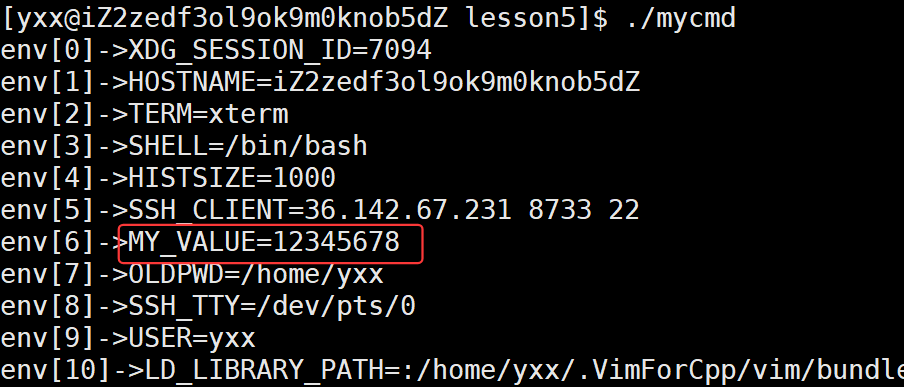
看到了MY_VALUE,所以环境变量可被子进程继承。那怎么取消环境变量呢:

此时就没有了。
2.本地变量与内建命令
下面看看本地变量与内建命令,本地变量指的是为我们可在命令中直接a=1,b=2,c=3这样定义,这就是本地变量:
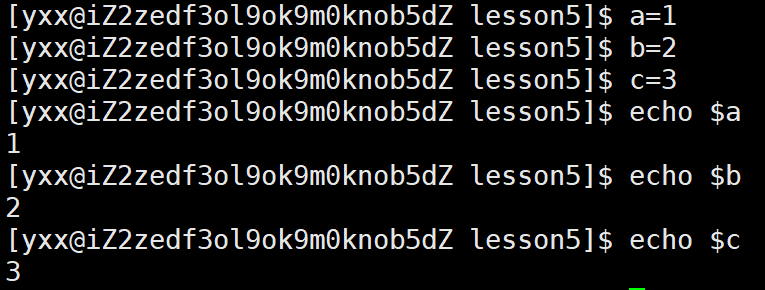
那怎么查找系统中的所有环境变量与本地变量呢:
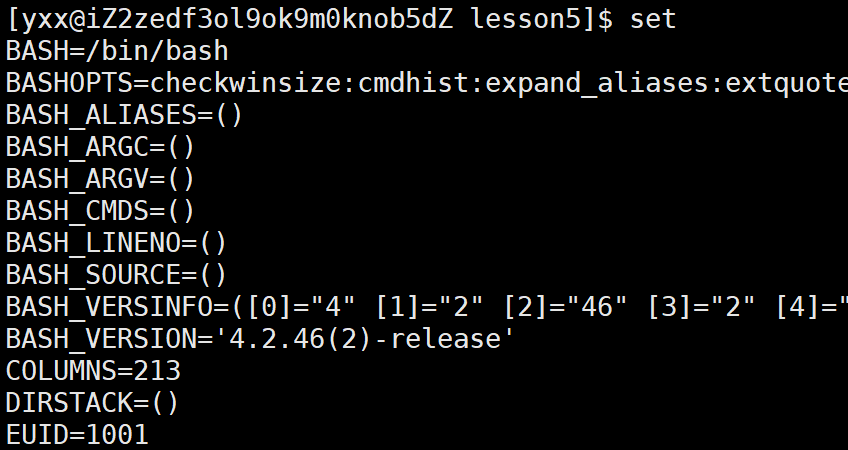
可以用set,本地变量不会被子进程继承,它只会在本bash内部有效。以前说过命令行中运行的指令都是bash的子进程,现在定义本地变量,那上面echo $a,echo是如何打印出本地变量的值的呢?现在纠正一下,命令行上所有启动的指令不一定全都要创建子进程,命令行分为两批指令:1.常规命令,通过创建子进程完成的。2.内建命令,是由bash不创建子进程,而是由自己亲自执行,类似于bash调用了自己写的或者系统提供的函数。这样相当于bash中有个函数叫echo,把本地变量获取打印。有个类似的还有cd指令,如果cd命令要创建子进程,每个进程都有自己当前工作目录,若cd创建子进程最后改的子进程路径,父进程路径不应受影响,但实则父进程路径更改了,因为cd也是个内建命令。那怎么去cd?系统中有个调用接口叫chdir:
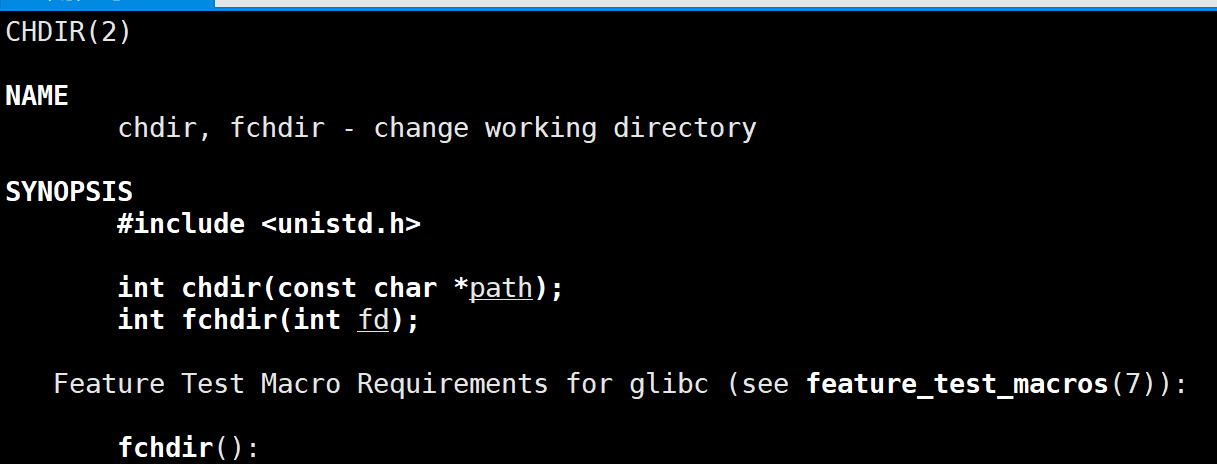
谁调用这个接口就把自己工作路径特定的。下面设计一个自己的cd来感受一下:
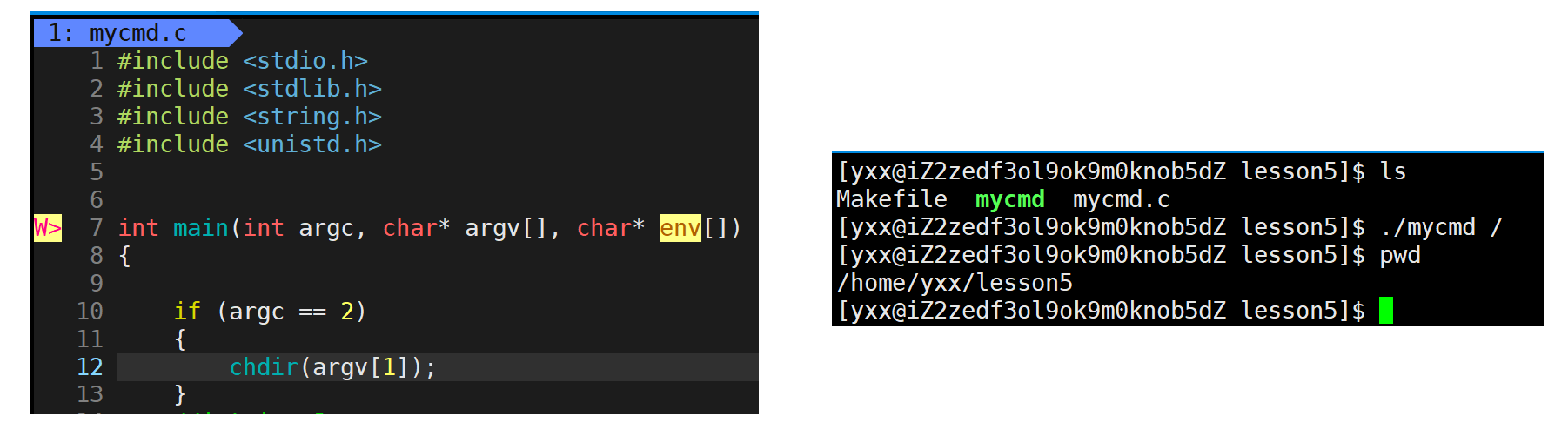
发现没有改变,因为./mycmd起来时bash要创建子进程。所以改一下,看子进程pwd变化:

因此当前进程自己把自己路径是可以改变的。假如这个程序是bash本身:
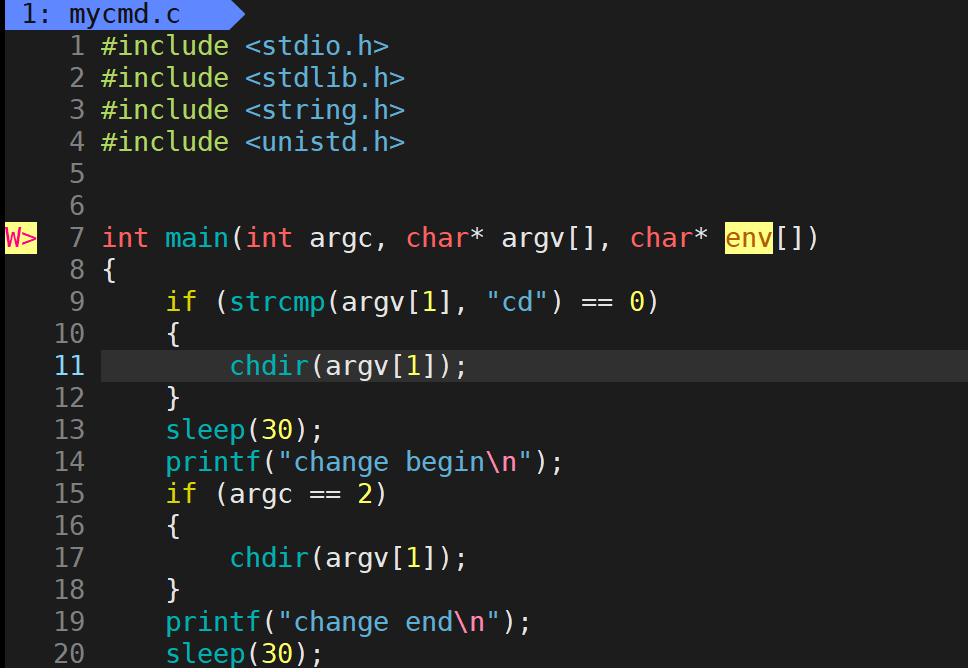
它里面判断需要执行cd时就不fork创建子进程了,直接改路径,这就是内建命令。还有个点,若没有命令行参数想获取系统的整个环境变量,c语言会提供一个环境变量,要使用先声明一下,该指针指向父进程环境变量表:
3.程序地址空间
下面来谈程序地址空间,首先回顾一个事情,之前谈fork时返回值有两个,两个分别是什么,为什么有两个返回值都解决过了,但id变量只有一个:

怎么可能一个变量既等于0又大于0呢?下面来说程序进程地址空间:以前学c/c++时听说过c/c++将地址空间化分为如下区域:从下到上是代码区,字符常量区,已初始化全局数据区,未初始化全局数据区,堆区,栈区:
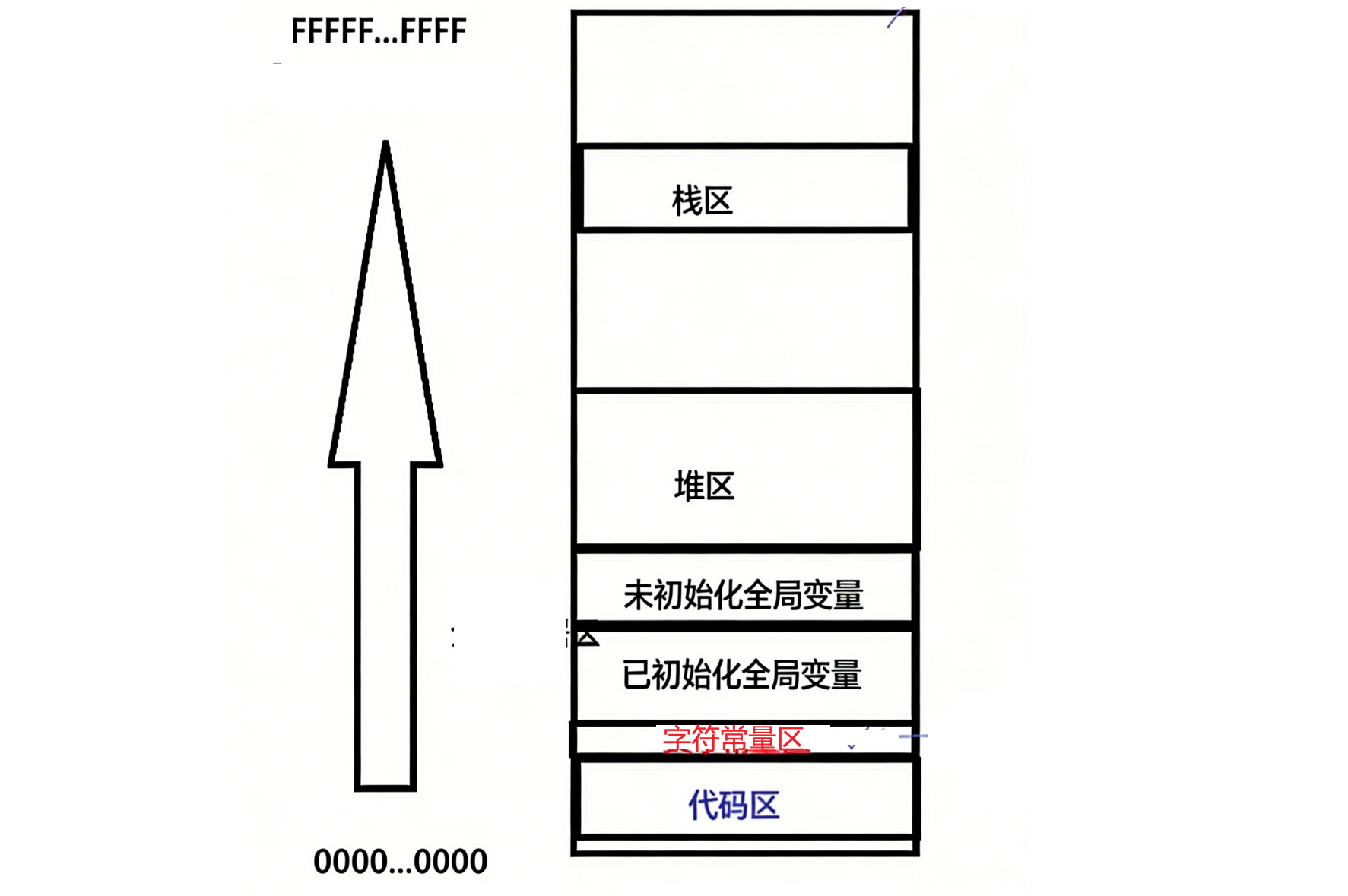
假设从全0到全F,大概是4GB,那上图所展示的是内存吗?这个东西叫地址空间。我们说c/c++程序,变量对象等都是在这上面分布的,那怎么区验证?这里自底向上打印(main函数充当代码区地址):
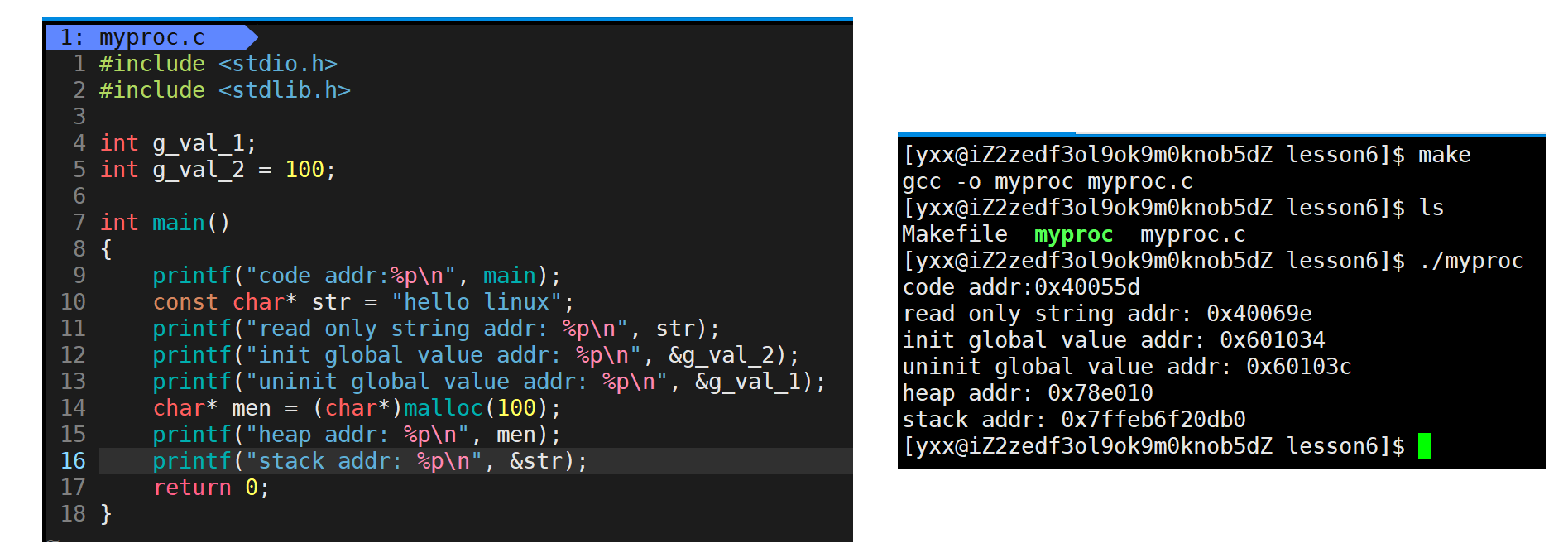
按大小划分一下:
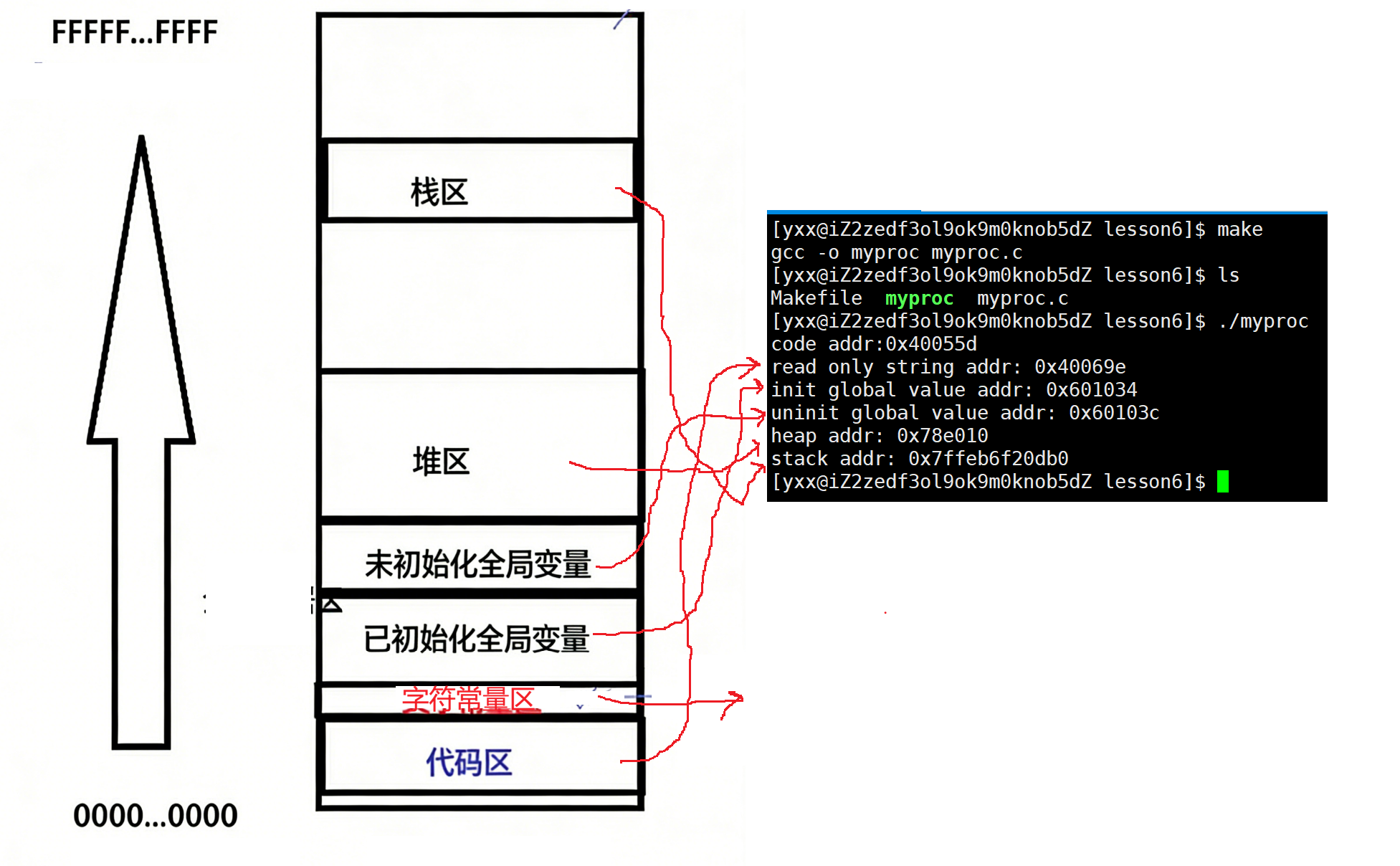
发现代码中定义的局部变量、常量、代码等是遵循我们所化的图的,其中栈区是向地址减小方向(向下)增长,堆区是向地址增大方向(向上)增长。下面验证:
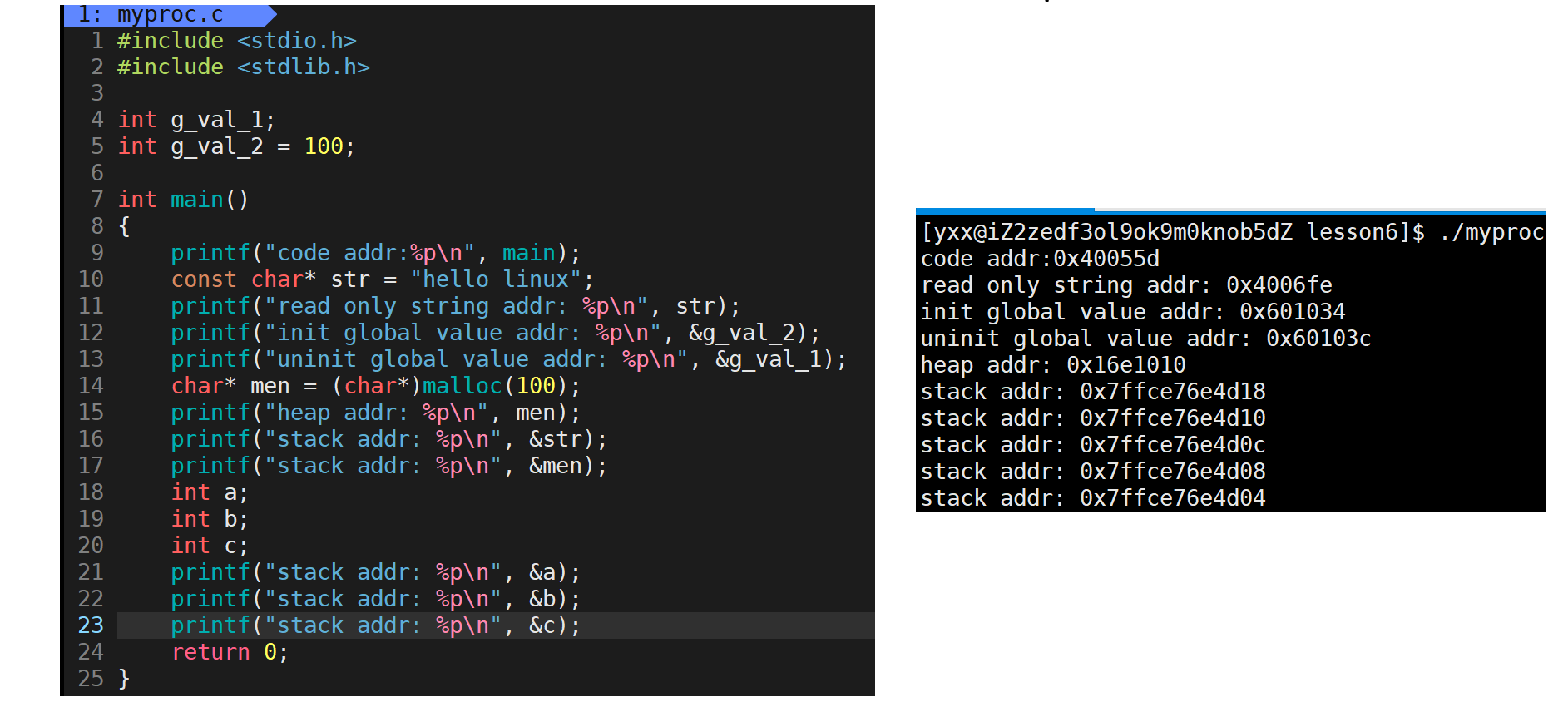
所以c语言中定义的很多函数内变量要入栈,先定义的变量先入栈,后定义的变量后入栈,所以栈是向下增长的。继续看:
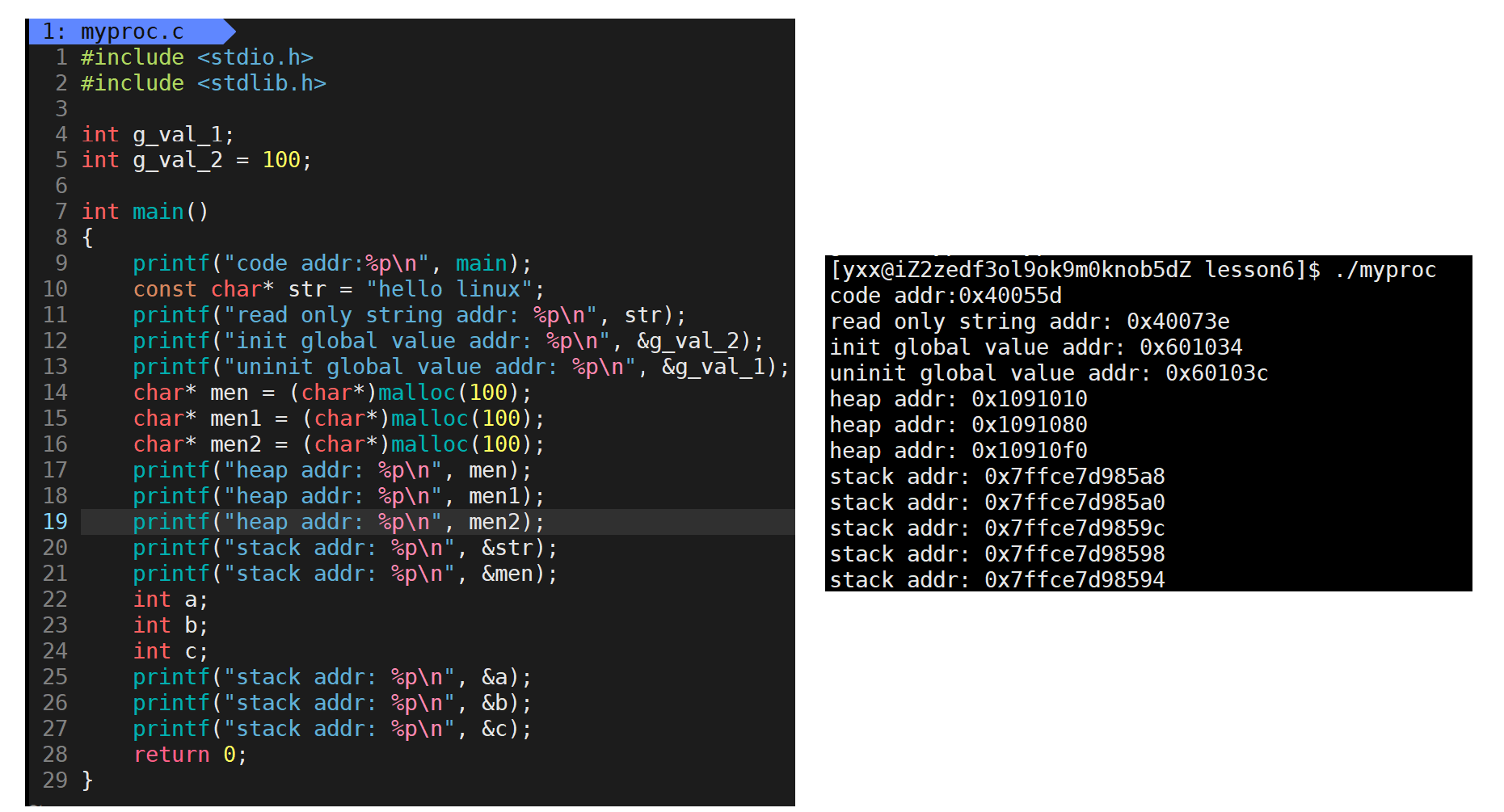
堆是不断增大,所以向上增长,堆栈相对而生。还发现堆和栈地址差别很大,一个7位地址,一个十位地址,它两之间有一大段露空。下面来验证一个语法问题,首先我们知道全局变量会一直存在,并不会随着一个函数的调用和返回释放(把未初始化和已初始化统称为全局数据区),说明只要地址空间一直在,全局数据区一直在。来看下图:
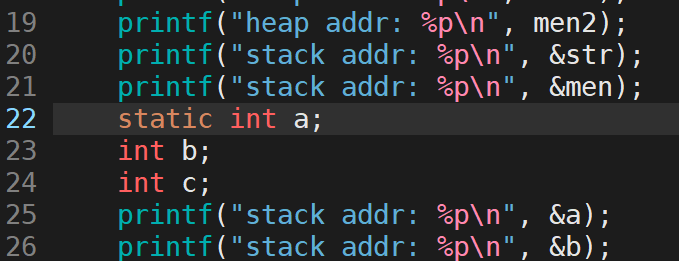
以前说如果一个函数定义了static变量,它并不随函数调用完毕而释放,首次调用只做依次初始化,往后直接用。那为什么用static变量修饰对应的a不会随函数被释放了:
没有修饰时打印出的a地址特别长,现在修饰后打印出的a地址变短了,和全局很像。因此static修饰的局部变量里,编译时候已经被编译到全局数据区了,所以不会随函数调用而释放(作用域不变)。下面继续看:
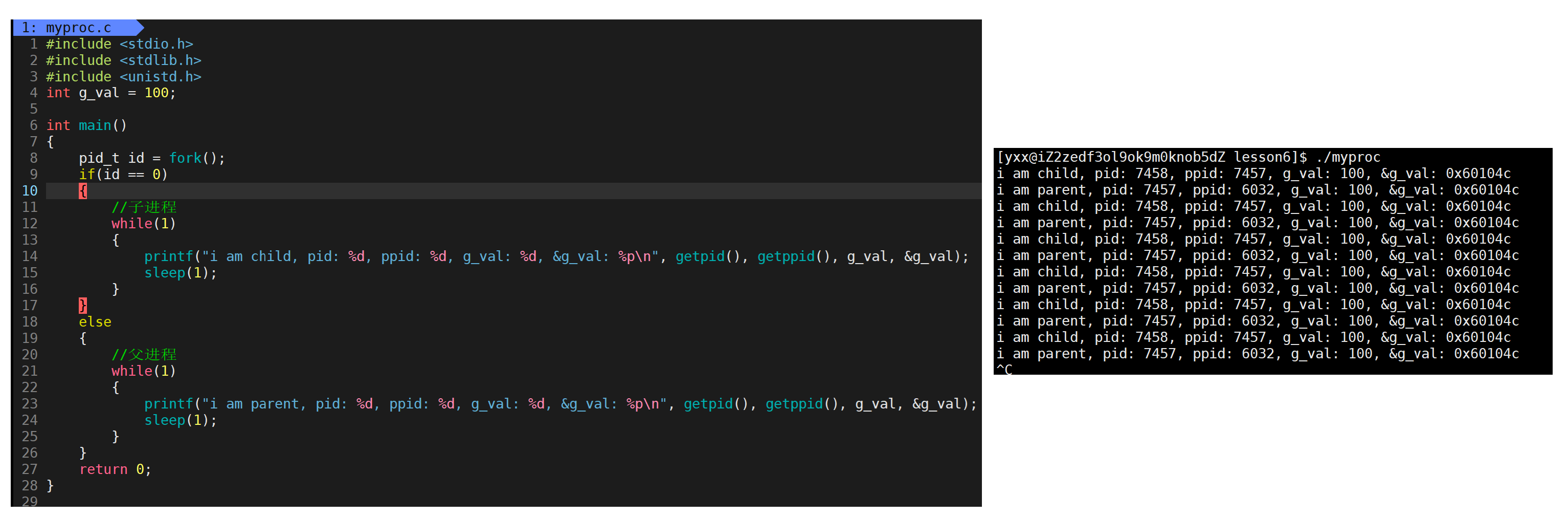
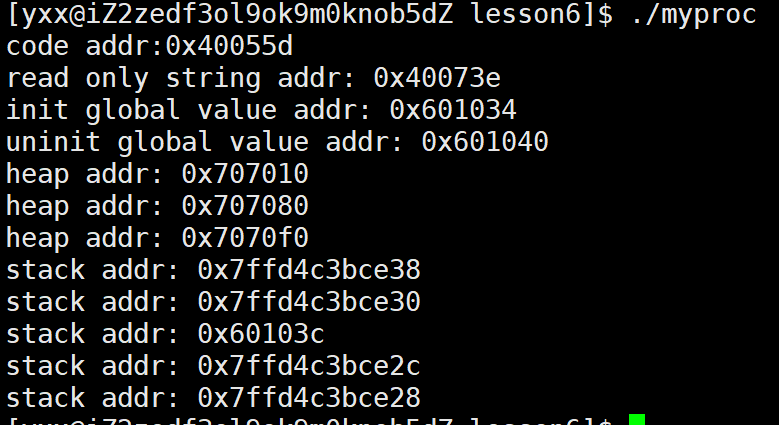
此时没什么问题,改一下代码继续看:
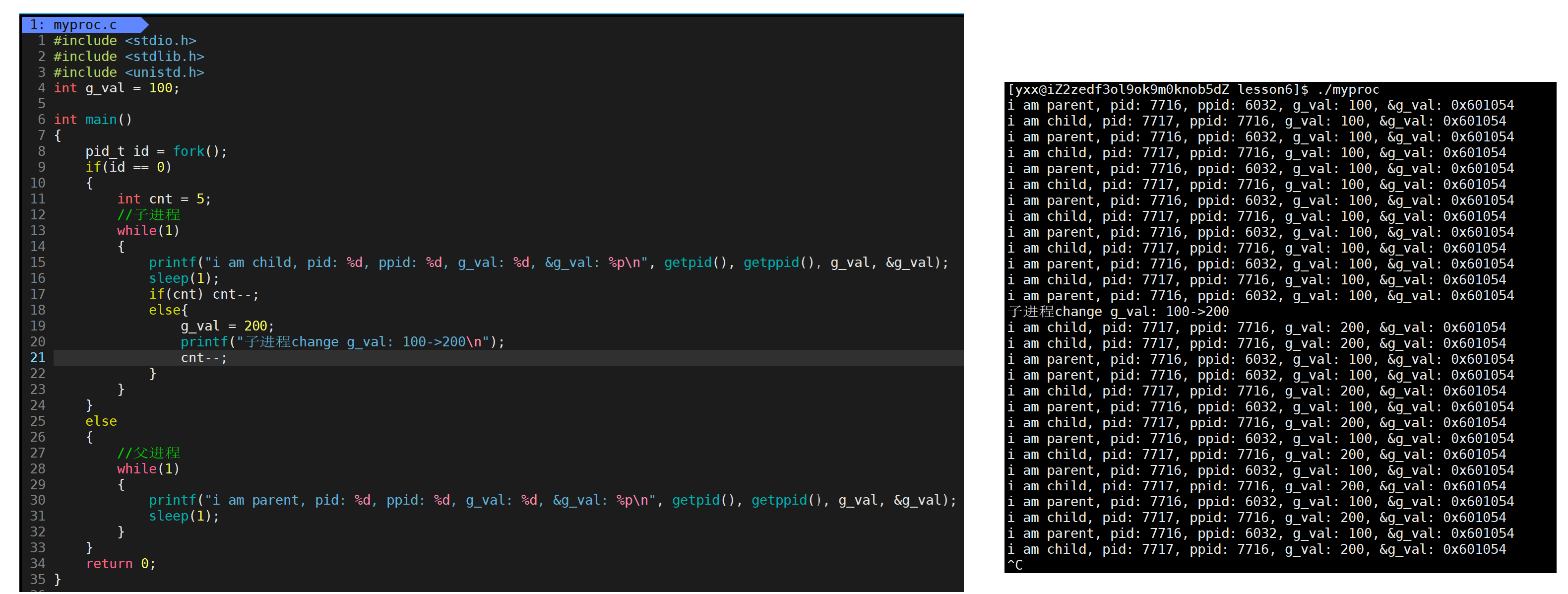
当把值由100改为200时,子进程打印时值变为了200,但父进程那里值仍然为100,而且发现它们值不同,但地址是一样的。那怎么可能同一个变量,同一个地址,同时读取,读到了不同的内容!目前可先给结论:如果变量的地址是物理地址,不可能存在上面的现象,因此上面的地址绝对不是物理地址,一般上述地址称为线性地址或虚拟地址。因此我们平时写的c/c++中,用的指针,指针里面的地址,全部都不是物理地址。
下面先引入新概念,初始理解这种现象,进而引入地址空间的概念。当我们实际运行一个程序时,本质运行起来会变成一个进程,在OS内要为该进程创建对应的PCB即task_struct结构。之前为了简化学习我们说一个进程有它的代码和数据加载到内存中的可执行程序,task_struct要能以一定方式找到代码和数据(这个是代码中最开始还没fork时匹配的一个叫父进程的东西,它有自己对应的pcb):
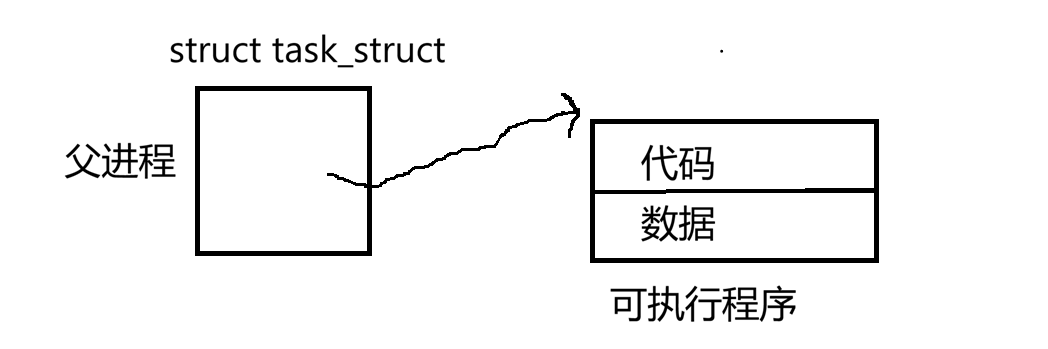
所以说进程=PCB+代码和数据。但是实际没有这样简单,在我们进程中,一旦我们创建一个父进程的东西,PCB一旦创建出来,系统为了让该进程更好的运行,除了创建pcb外,还要为该进程创建一个叫地址空间的东西,准确说叫进程地址空间。所谓进程地址空间是这样一张:
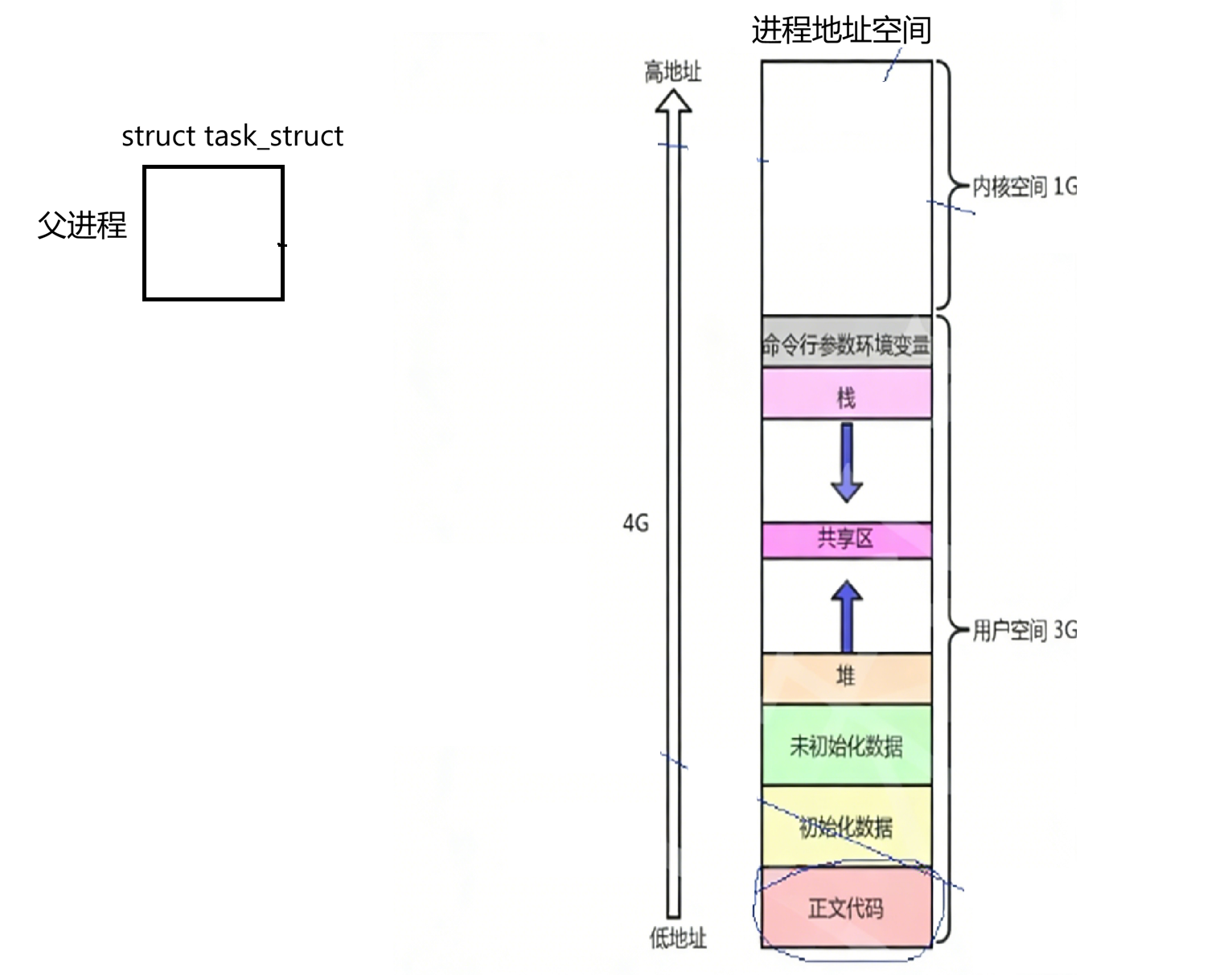
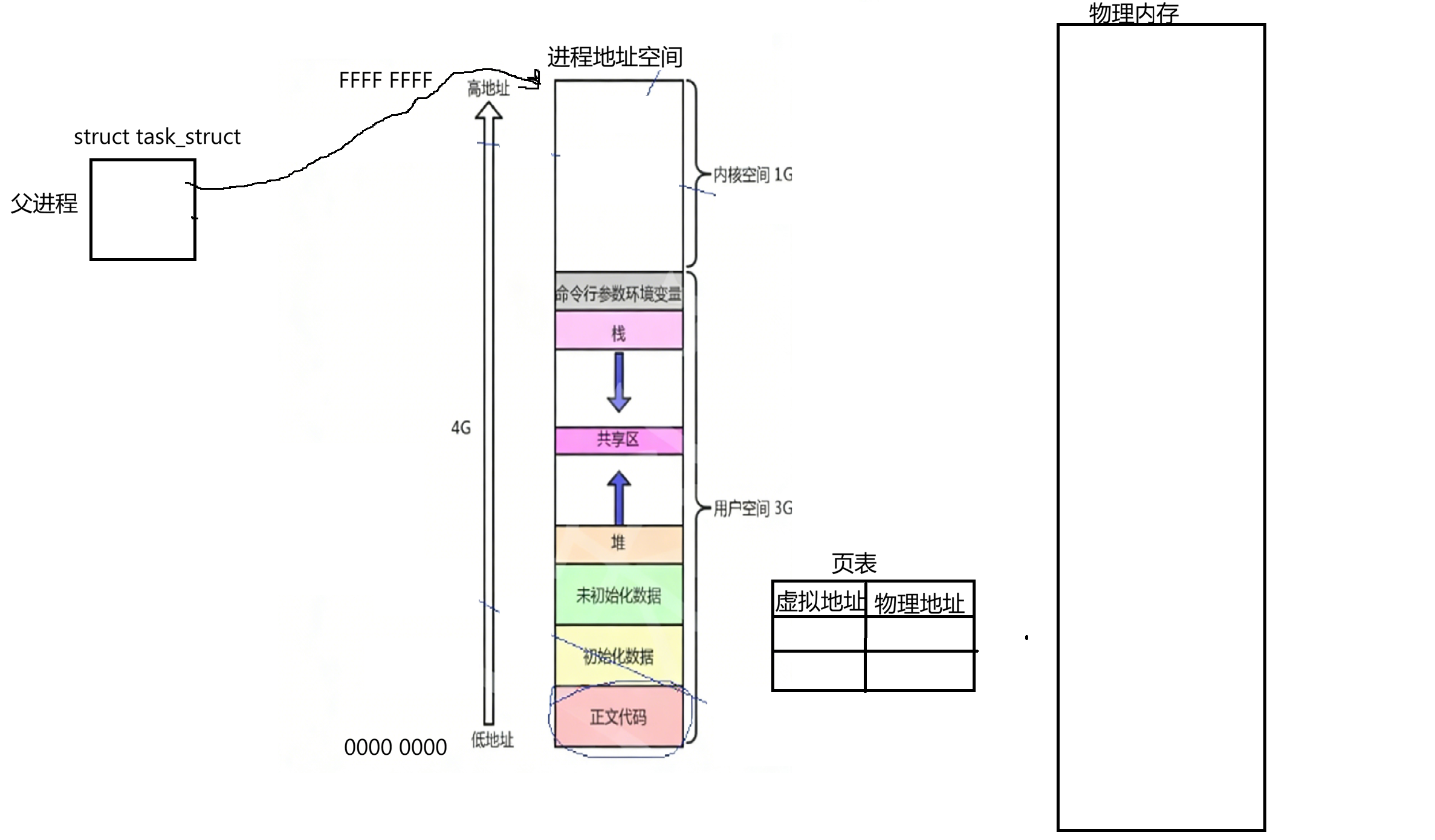
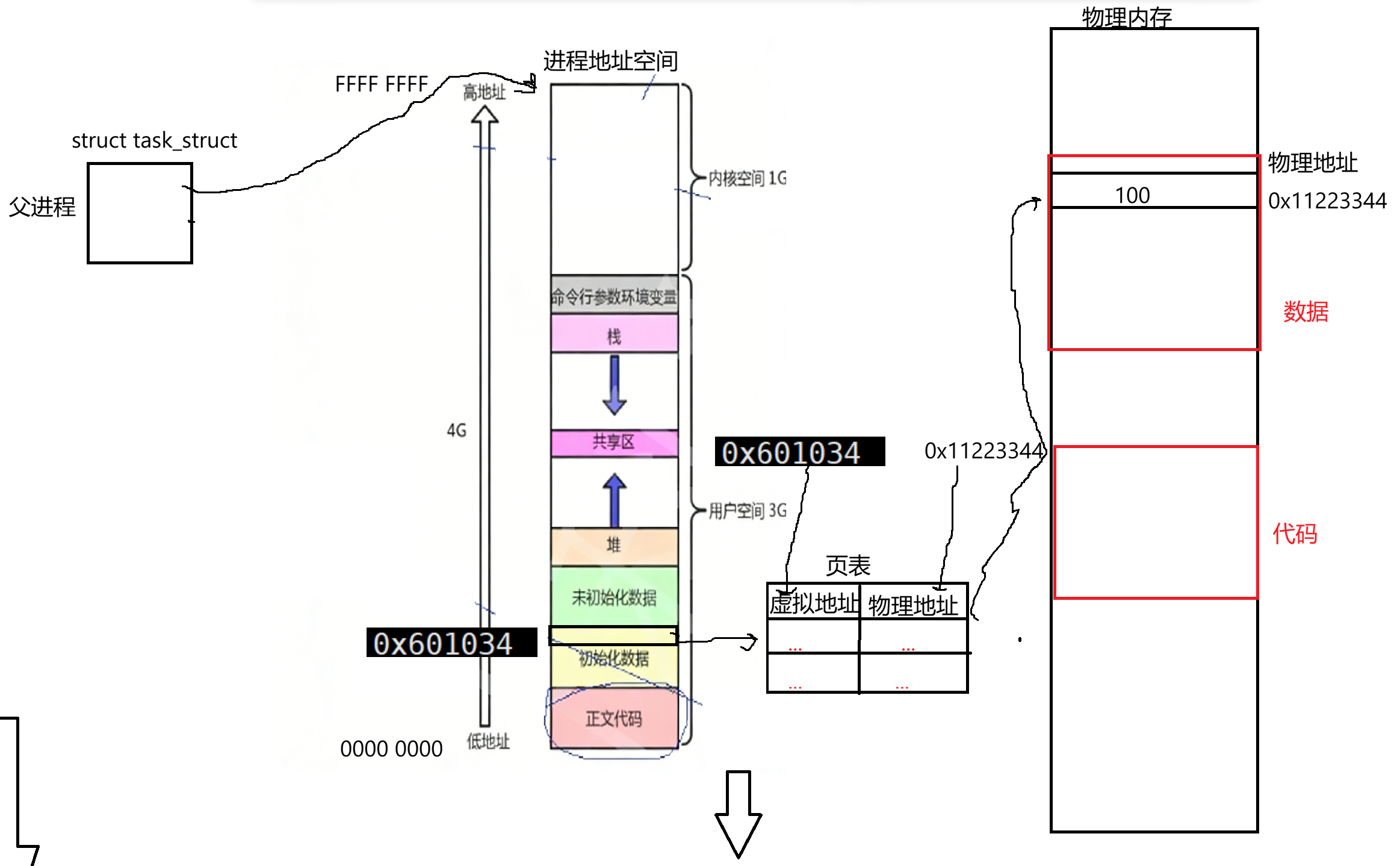
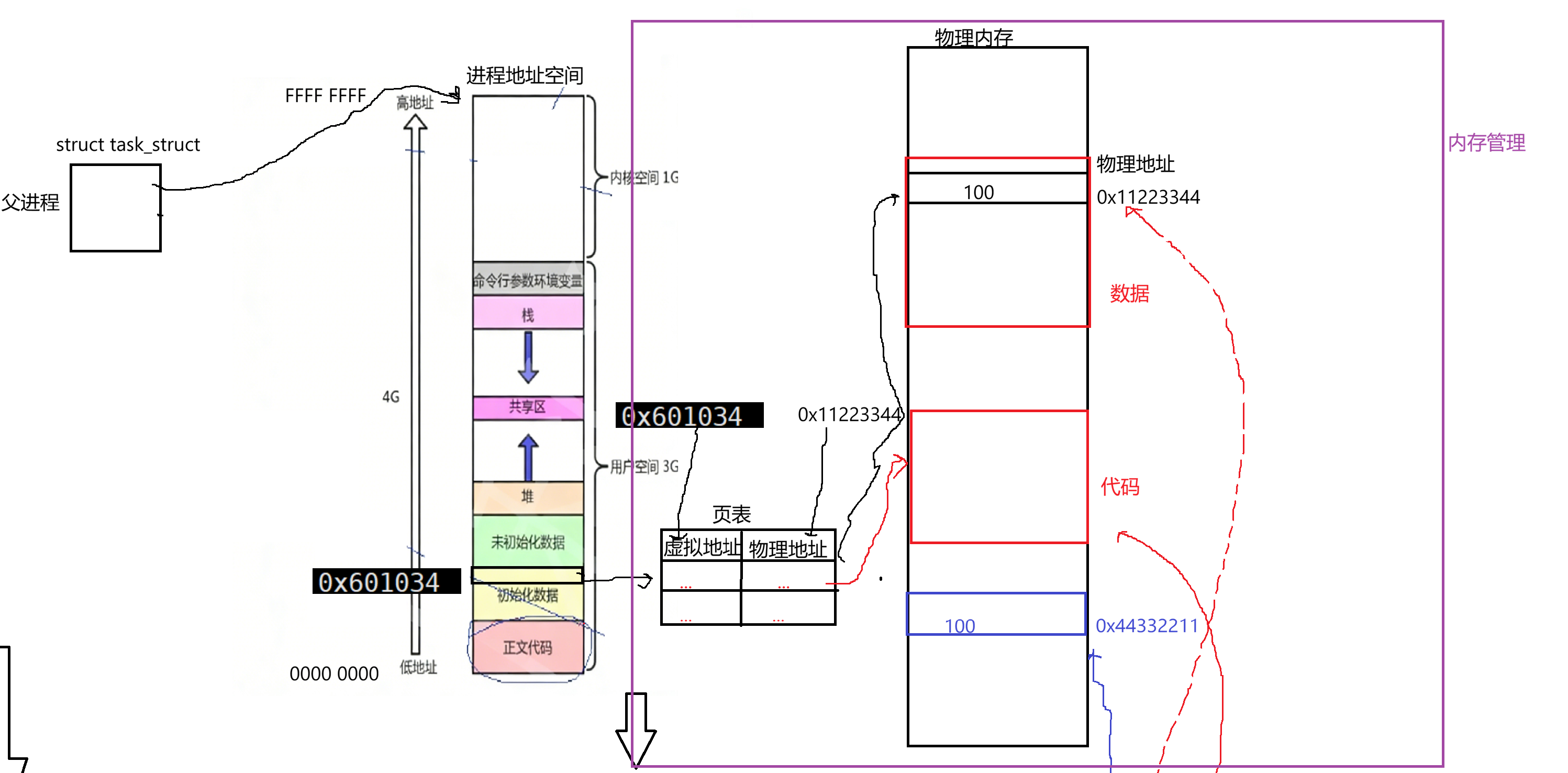
所以每个进程创建时系统都要为我们提供一个叫地址空间的东西,其中这个地址空间(以32位为例)低地址为全0,0000 0000;一直到高地址为全F,FFFF FFFF。我们平时在进行编码时所用到的地址是地址空间中所具备的地址,我们所对应的进程地址空间是内核为该进程创建的一个结构体对象,其中父进程pcb里有对应的指针指向该地址空间:
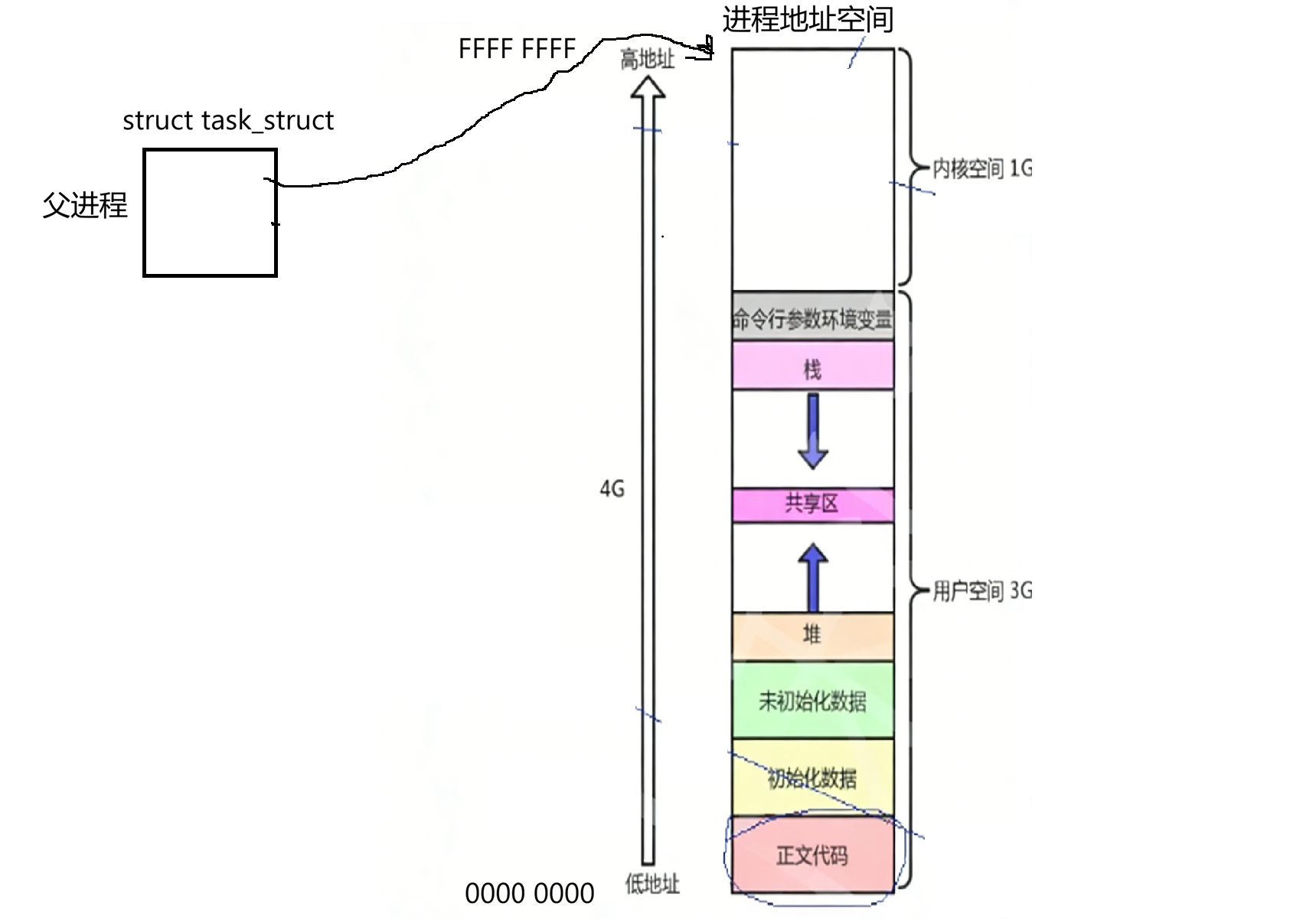
父进程在地址空间这再往后才是物理内存:
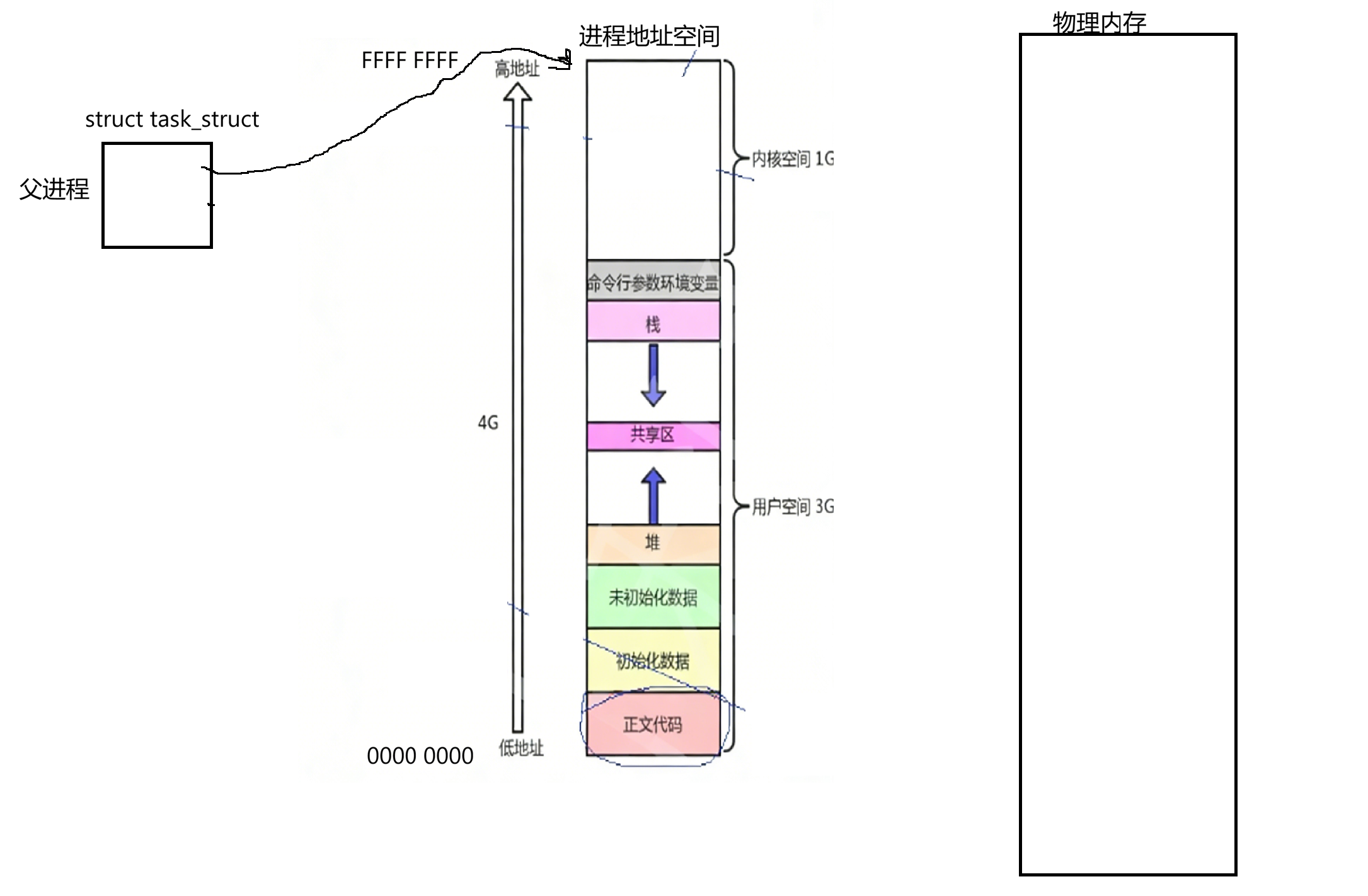
我们在编程中使用的全0到全F所展现出的这是线性或虚拟地址,这种对应地址一定要能够经过一个东西:在系统层面还要为我们当前父进程构建一个叫页表的东西,它是一种kv式的映射关系,左侧对应虚拟地址,右侧对应物理地址:
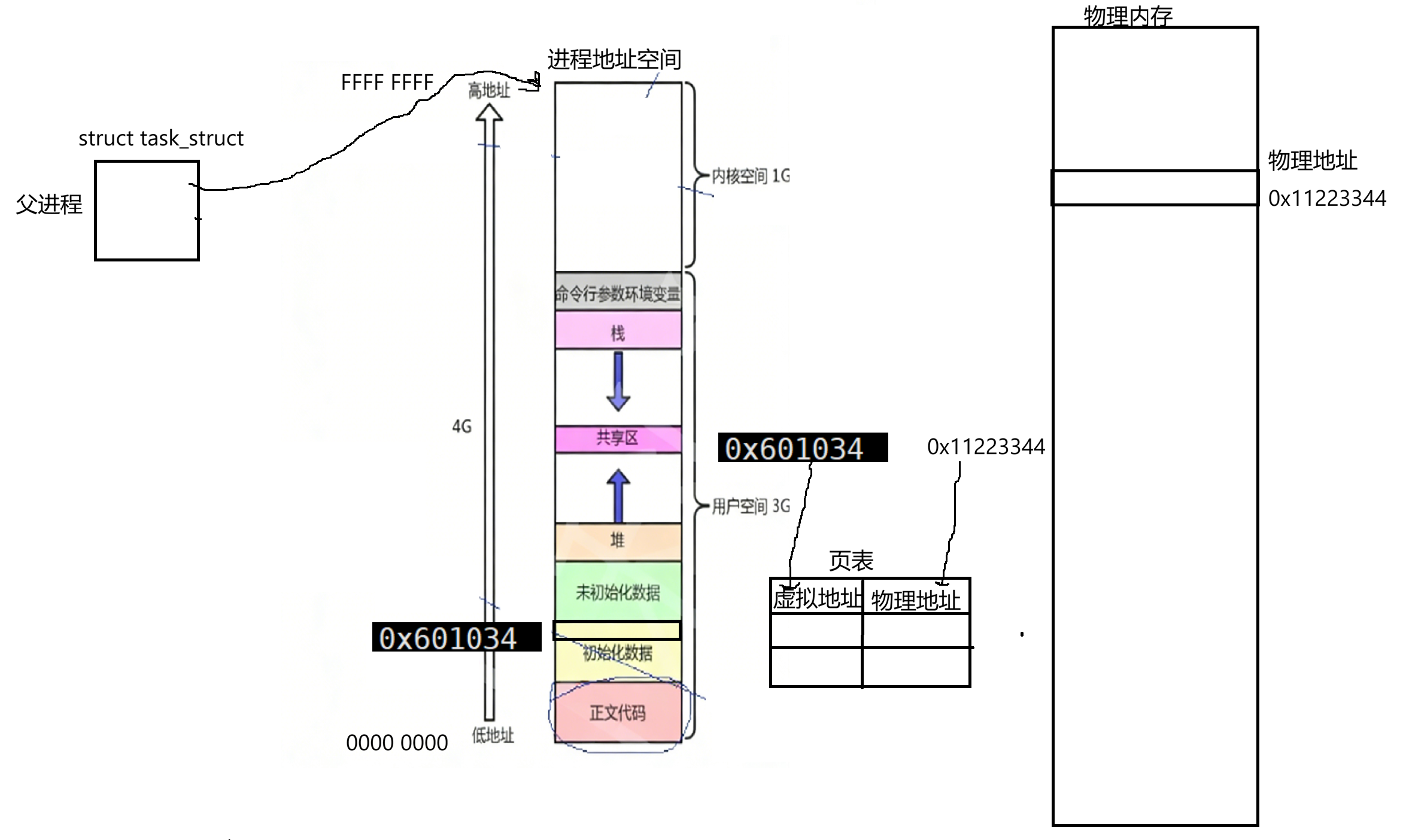
我们当前父进程它所对应的地址空间定义了个全局变量,比如已初始化全局数据区有个对应的变量。(按照前面的代码)其中该变量地址是0x601034,这个地址是我们上层在使用的全局变量所对应的地址,这个虚拟地址最后会填到页表左侧。最终通过找到页表虚拟地址,然后系统中要为该变量在内存中开辟一块空间,在物理内存上也有自身物理地址,然后填到页表:
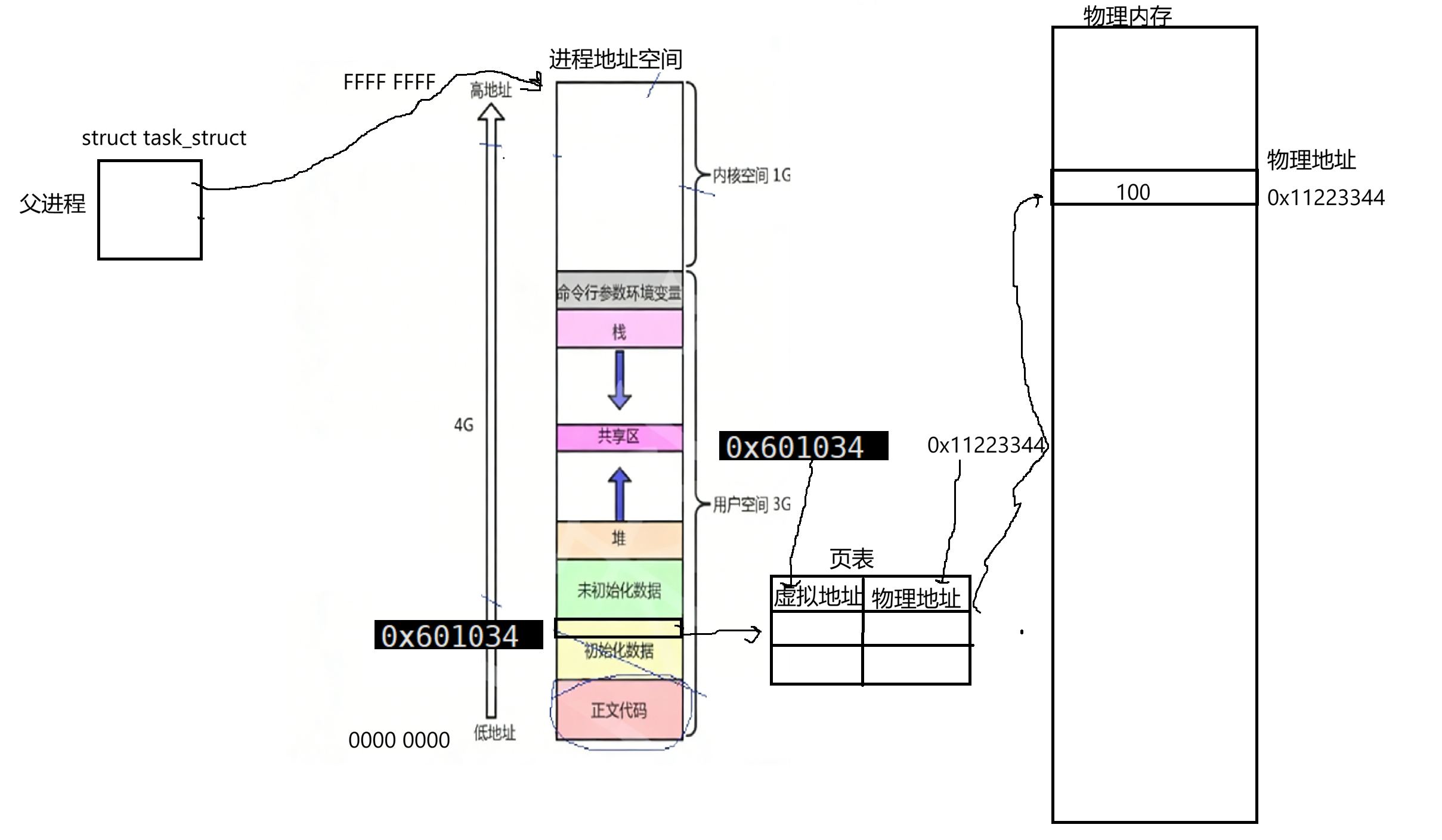
当进程在访问0x601034这个地址时,OS会自动查页表根据虚拟地址转为物理地址,就可以访问到物理地址的内容了:
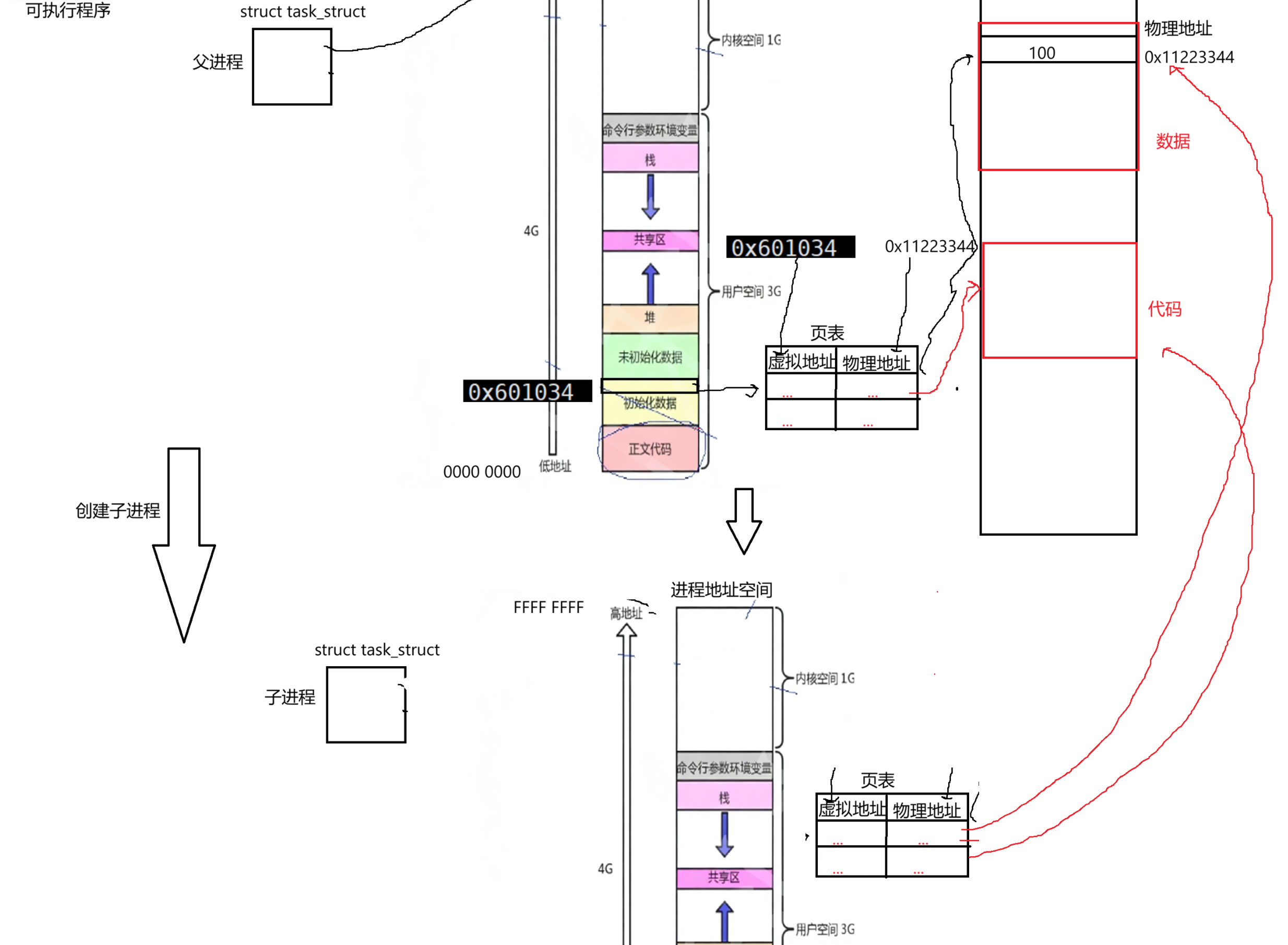
当父进程要开始创建子进程时,一定是系统中多了一个进程,多的进程也要被OS管理起来,因此也要为新的子进程创建它的pcb结构。子进程会以父进程为模板,初始化它内部结构体对象的各个种值(当然也会有它的私有数据,比如pid,ppid,优先级等)。每个进程都要有叫进程地址空间的东西,所以子进程也要把父进程的地址空间给自己拷贝一份。子进程要保证和父进程具有独立性,子进程独立性体现在它具有独立pcb,虽然很多字段是从父进程继承下来的,但也要有自己独立的地址空间,虽然地址空间中很多字段也是从父进程继承下来的。此时子进程在自己已初始化全局数据区也有个虚拟地址是0x601034:
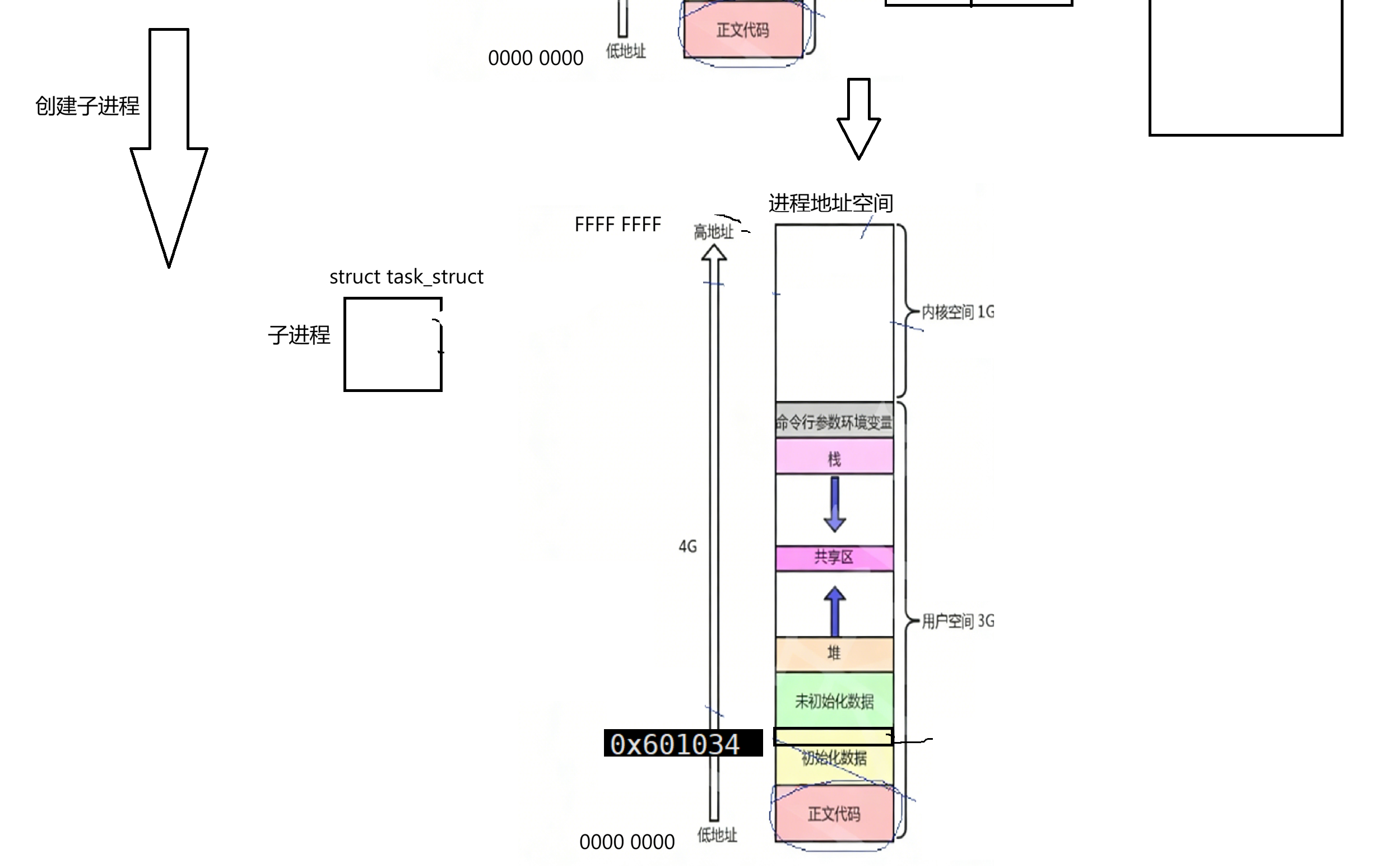
子进程也是进程,也要有自己独立的页表结构。先补充一下,父进程页表除了之前全局地址外,还有其它虚拟地址和物理地址;一个进程肯定有自己的数据和代码,数据和代码一定要保存在对应物理内存上,所以父进程可通过页表找到代码和数据:
再回头说,子进程也把父进程页表拷贝一份,此时这上面虚拟地址指的和父进程是一样的:
所以父进程和子进程可做到共享代码和数据。当子进程尝试修改g_val=200,系统识别到将0x601034进行写入,os根据虚拟地址查页表,发现此时和父进程共享,所以OS在写入之前会在内存中重新划分一段空间,比如0x44332211,把值拿过来,接着改一下物理地址,此时子进程物理地址指向不再指向父进程对应的变量,指向新申请的空间:
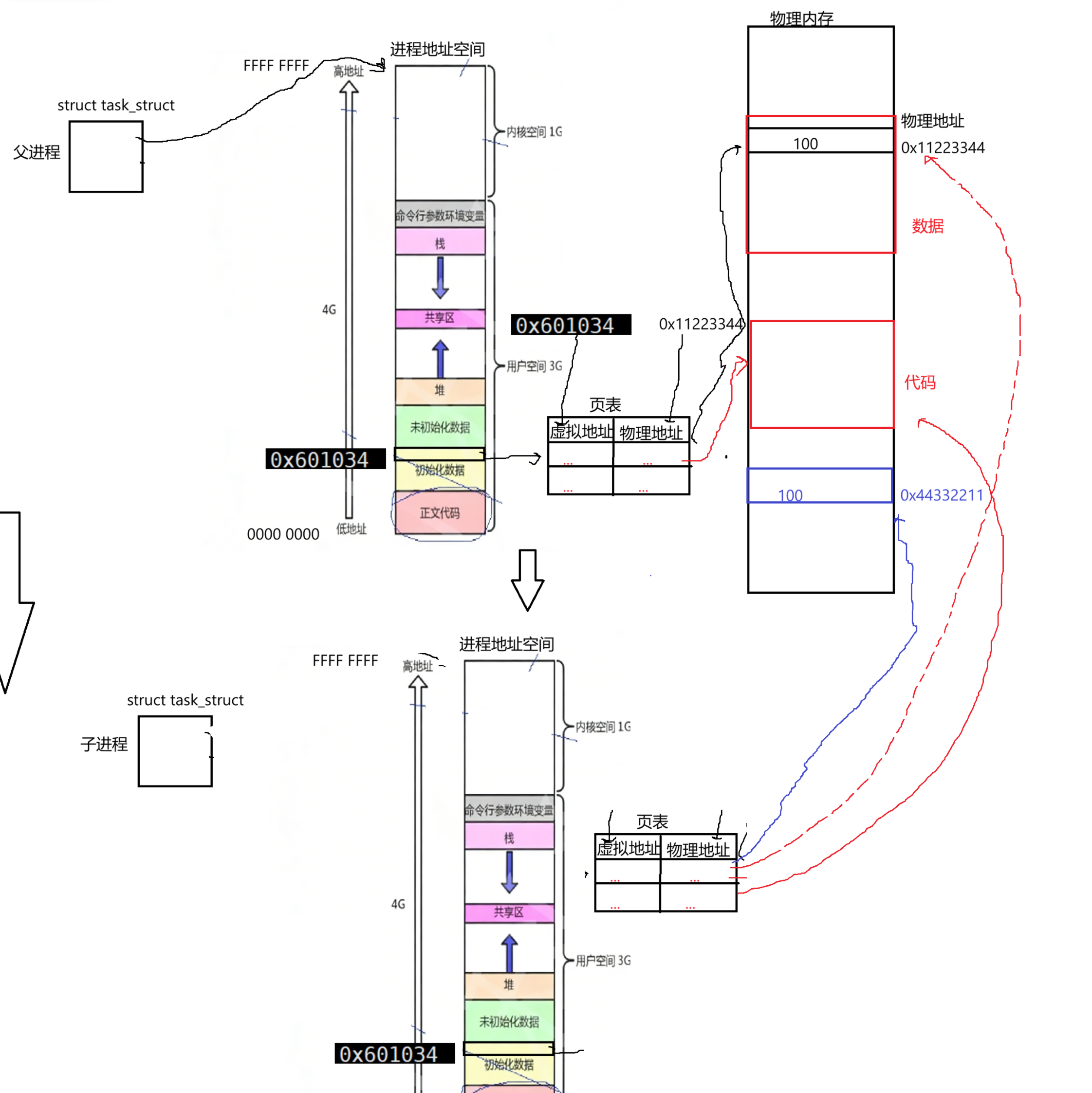
至此将父子进程对应的值在物理内存上分开了。上述先经过一个写时拷贝,这个写时拷贝是由OS自动完成的。写时拷贝的本质是重新开辟空间,但是在这个过程中,左侧的虚拟地址是0感知的,它不关心,不会影响它。此时上述完成后执行g_val=200,根据页表查找k,再找对应的v,然后将值由100改为200。因此打印地址时是一样的,因为父进程打印地址是0x601034,子进程地址空间继承自父进程打印也是0x601034,当访问的内容不一样是因为父子进程分别通过虚拟地址在页表中查物理地址,映射到物理内存看到值不一样(以上是个宏观概念)。理解上述能先说说fork的问题了,因为fork进行返回的时候,也是向pid_t的id值写入的过程,fork往后有两个进程,这两个进程都有id变量。id变量对应虚拟地址,同一个id被写入时发生写时拷贝,父子进程通过查自己页表映射到内存,所以一个变量有两个不同的值。
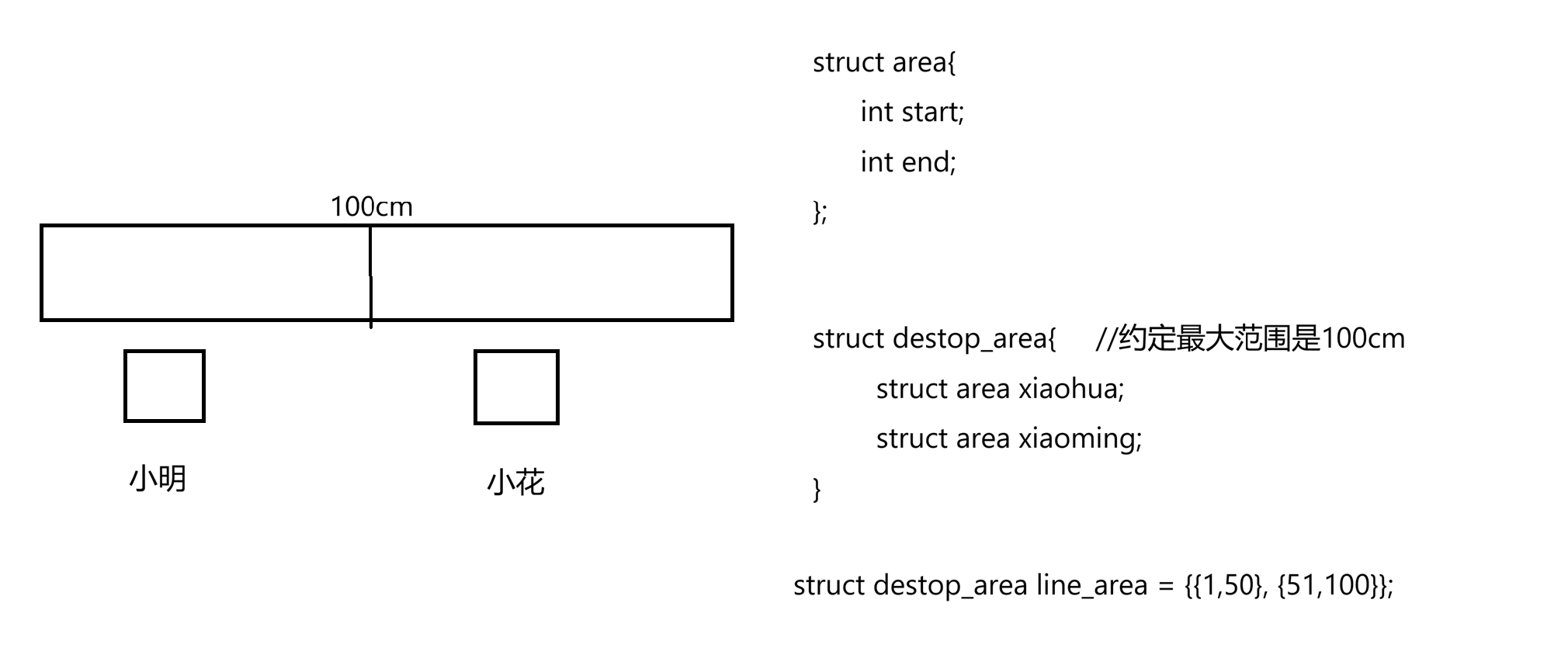
下面来谈细节,首先说地址空间究竟是什么?地址空间本质其实是用来进行以进程视角来对内存进行宏观划分的一个视角。先引出两个问题:1.什么叫做地址空间。2.如何理解地址空间的区域划分。先看第一个问题,我们知道计算机包括进程要读取对应的代码和数据,父进程或子进程一定是要被调度的------一定是它们正在cpu运行,才有各种访问内存的需求。当一个进程在cpu上正被运行时,它要访问对应的内存时,一定是要先告诉内存要访问哪一个地址,所以cpu要根据它对应的地址总线来访问我们对应的物理内存。我们以前学c语言时听过这样的话:在32位计算机中,有32位的地址和数据总线。cpu和内存可通过各种总线连接起来,因为计算机只认识二进制,对应的总线要么为0要么为1,内存中可读取总线上对应的各种0 1数据,就可在内存中获取我们想要访问的内存地址。我们通常说计算机只认识二进制,所以计算机里只有0 1。计算机里对应的内存、cpu等都有短暂存储数据能力,可想像如内存中也有地址寄存器这样的概念,因为是32位的,所以地址寄存器这只能存32位的数据。要知道内存比如能存一个比特位,是由触发器这样的硬件构成的,当给一个电脉冲,就会往触发器中充一个强电频。因此寄存器中假设有32个比特级别的存储单元,其实本质是给寄存器进行充放电的过程,高电频是1,没电频是0,这样数据在硬件上有高低电频的概念,软件上解释为0 1。这样每根地址总线经过两态组合打到寄存器这,就是告诉内存现在要访问谁。最终结论是地址总线上的0 1其实本质是高低电频,向内存中进行寻址实际上是告诉内存我要访问哪个地址,本质是cpu在向内存充电,充电后对应设备能识别出高低电频,然后能识别成0 1,然后把0 1组合形成了一个物理地址。其实计算机只认识高低电脉这样的概念,数据所有的拷贝其实是一个设备给另一个设备充放电的过程。那每一根地址总线只有0、1概念,一共有32根,所以从cpu出去到内存上0 1组合一共有2^32种,内存寻址最基本单位是字节,所以注定内存大小是2^32*8byte=4Gb,这就是一个32位计算机最多能够装载4Gb内存空间。所谓的地址空间是你的地址排列组合形成的地址范围叫地址空间,毫无疑问我们的空间范围是0\~2\^32。举个例子更好的理解:我国有960万平方千米的土地,所以我在国内游玩的空间范围是0~960万,尽管都没有游历过,但我自己知道能够访问的范围是0~960万。所以所谓的地址空间更多衡量的是进程极端情况下所能访问的物理内存的最大范围,这就是地址空间,它是一个范围型的概念。那如何理解地址空间上的区域划分呢?下面说个小故事:小时候上小学时同桌两人用一张桌子,假设桌子长100cm,那么小明和同桌小花整体使用地址空间是100cm,由于上课打闹缘故,小花在桌子中间画了个三八线,表示谁也不能过线。那小花画三八线本质是在干嘛呢?本质叫做区域划分。那如何用计算机语言表述一下小花画三八线,小明越界的动作的这种情况呢?(小花怎么知道小明越界了?小花、小明是怎么知道整体对应的地址空间是100cm呢,所以小明和小花把它们各自的地址空间管理起来)定义一个destop_area结构,约定最大范围是100cm;再定义一个区域结构,里面是开始和结束,桌子划分是填上小明和小花的区域:
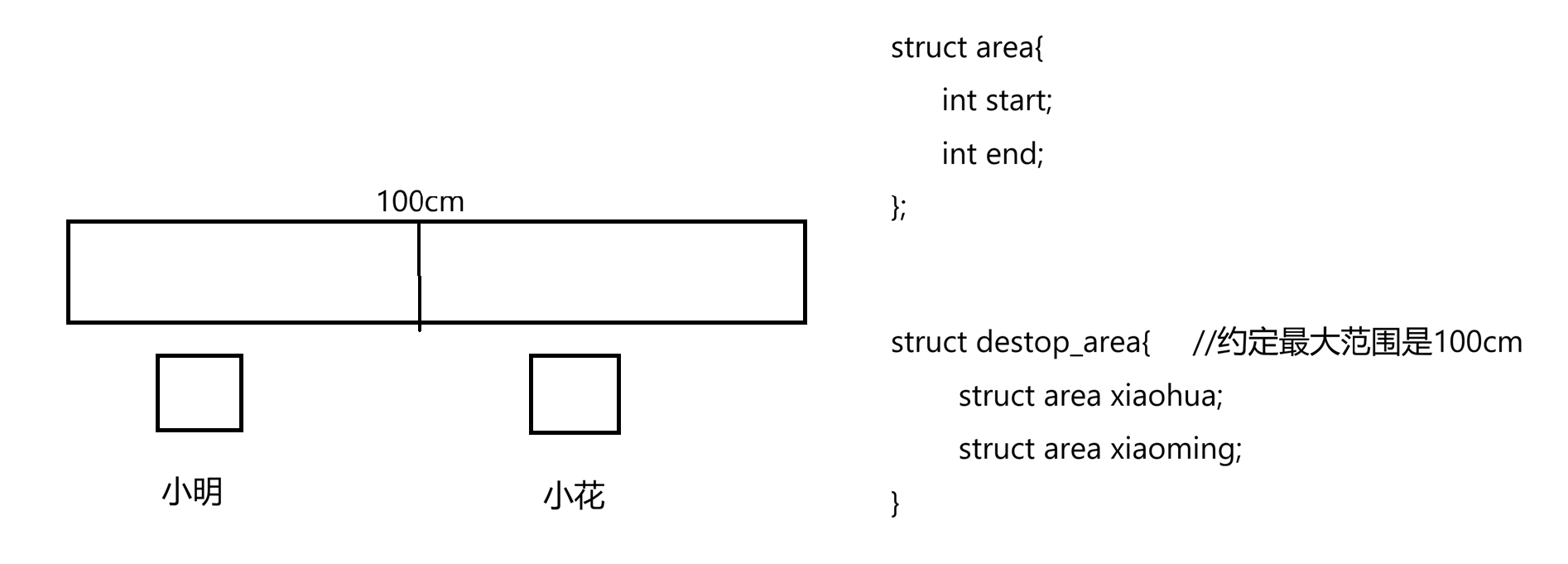 定义好区域后给小明和小花初始化划分:
定义好区域后给小明和小花初始化划分:
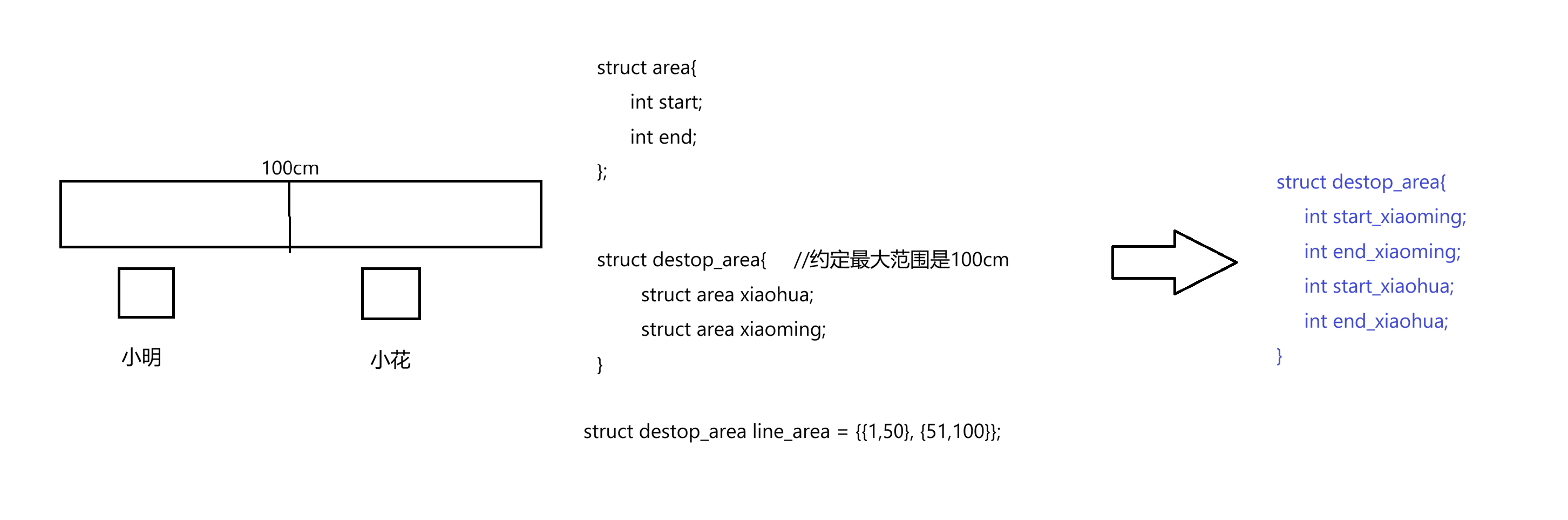
还可以再简化一下:
地址空间是约定桌子最大范围是100cm,区域划分是定义一个区域开始和结束就行了。有天小明越界了,小花很生气,把小胖区域缩小了10cm并警告他再越界还缩小。那么所谓的空间区域调整,变大或变小如何理解:
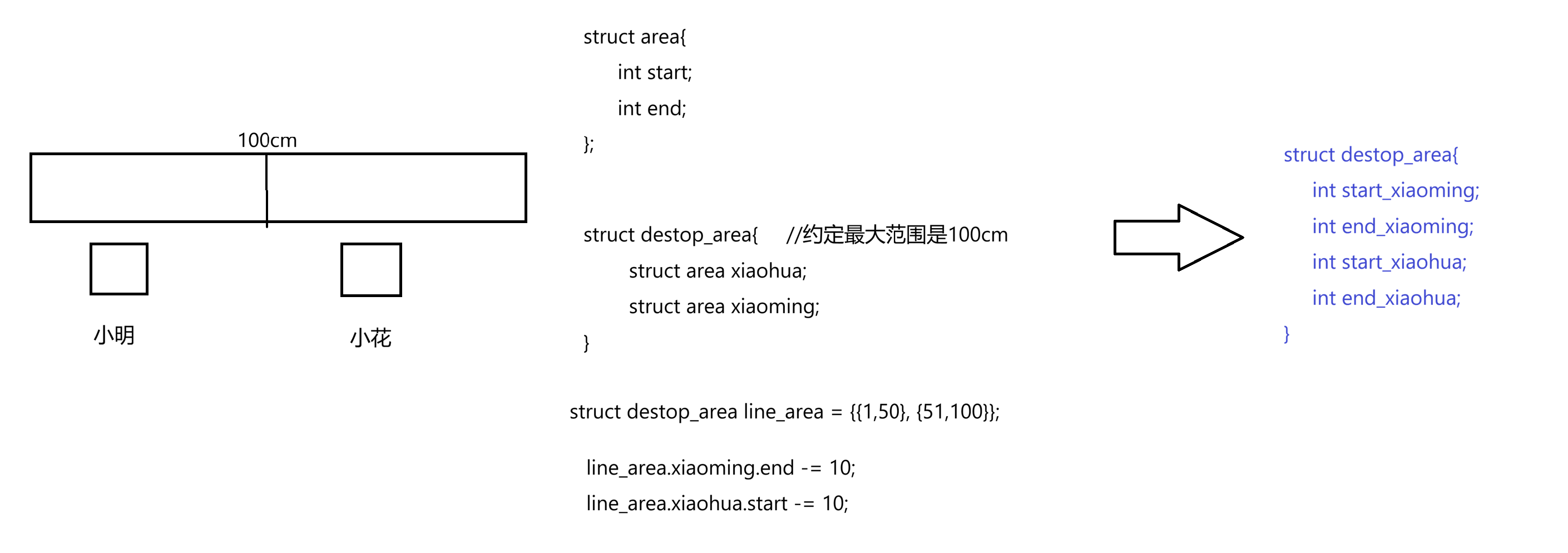
计算机中通过改end、start的值来调整区域。
下面再看:1~50是小明的,小明想申请自己空间范围上的空间时他该如何做?给小明的是1~50,意味着1~50中任意一个位置小明都可以去使用。但小明有"强迫症",把铅笔把2处,书放3处,尺子放5处......小明把自己用的东西在自己地址空间范围内保存好了。假设老师问小明书在哪里,小明给老师说在3,老师在小明对应地址空间范围内找到了编号为3处,找到了小明的书。因此不仅仅要看到给小明划分的地址空间范围是1~50,在范围内连续的空间中,每一个最小单位都可以有地址,这个地址可以被小明直接用。相当于给了小明1~50范围,小明自己刻了刻度(1cm,2cm...),再把工具放刻度处;桌子上的刻度叫小明自己空间范围内的地址,工具相当于小胖在特定地址存放的内容。因此什么是地址空间?所谓的进程地址空间,本质是一个描述进程可视范围的大小,就是这个进程能看到多大内存,地址空间内一定要存在各种区域划分,对线性地址进行start和end即可。再具体些,地址空间本质是内核的一个数据结构对象,类似于pcb一样,地址空间也是要被os管理的,既然管理就先描述再组织。进程地址空间在内核中是一个内核对象,叫struct mm_struct,为了能描述范围,里面一定这样:

因此创建一个进程时为该进程创建对应的pcb,再创建对应的mm_struct,这个结构体默认划分的区域是4GB。相当于有个4Gb大的桌子,小明,小王,小张等提前在大桌子上划分好自己的区域。每个进程的tast_struct要能够指向自己对应的mm_struct:
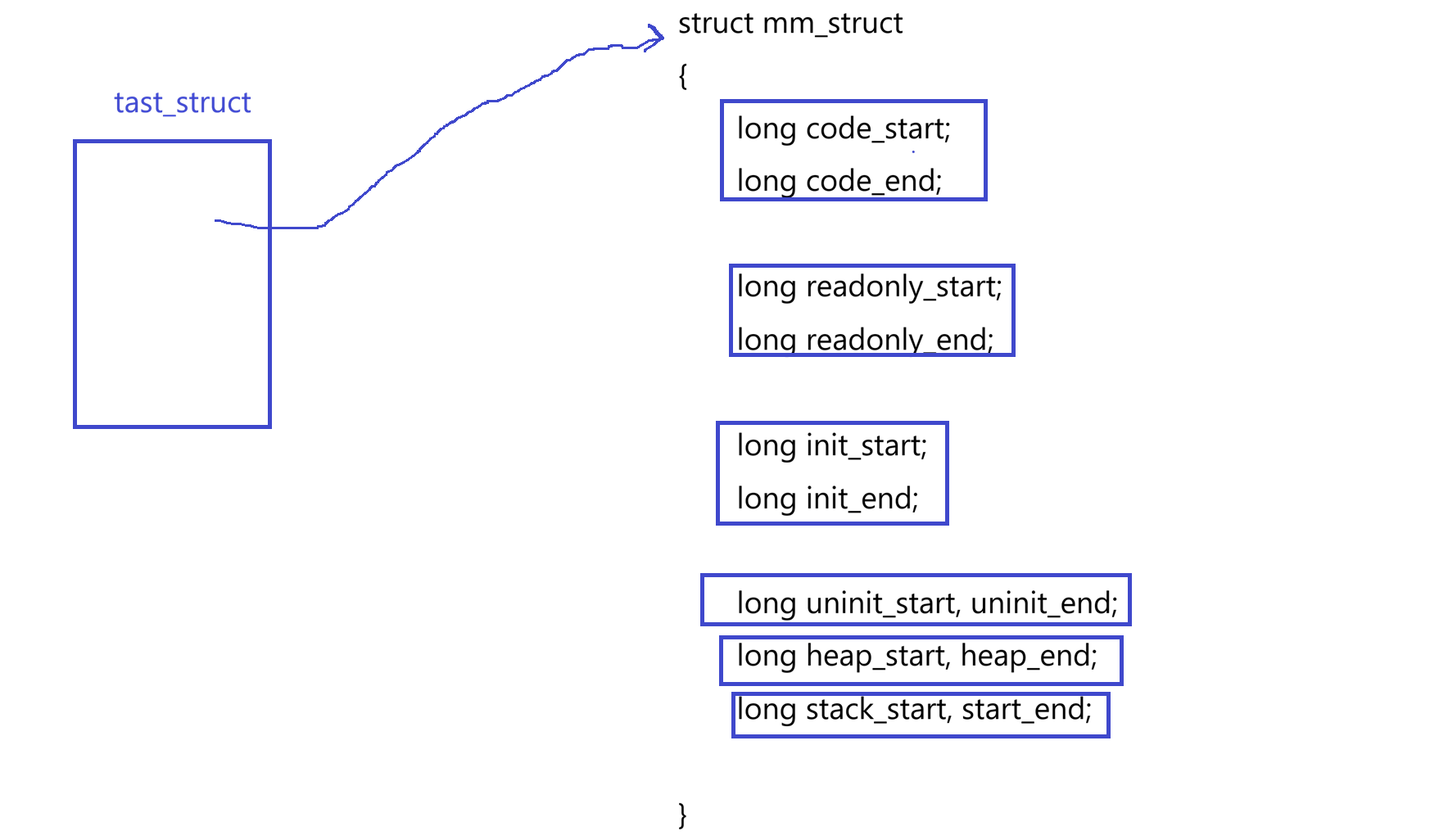
这就是进程地址空间,所以一个进程能初步知道它的代码、数据、堆等在哪里。
下面来重新看什么叫进程,以及进程地址空间为什么要有?下面来说个故事:假设有个美国人,我们叫老美,他是当地的大富翁,他身上有10亿美金。老美有4个私生子,分别是私生子1 2 3 4。私生子是私下出生的,意味着它们对对方的存在并不知道。这个老美给4个私生子都分别说过以后这10个亿都是你的,也就是老美给每个人都画了一个大饼。在私生子1 2 3 4中,他们都认为将来自己会继承这些财产,每个人都不知道对方的存在,每一个人都认为自己未来会具有10亿家产。平时私生子1 2 3 4向自己老爹要一点钱花时老美都会为他们分别打钱,他们都认为不管他们现在要多少钱未来他们都会有10个亿的。其中大富翁在这代表的是OS,每个私生子代表OS的一个个进程,这里画的大饼称为进程地址空间。因此每个进程启动时,OS要给进程构建一个进程地址空间,OS用地址空间这样的数据结构表征每一个进程所能看到内存的空间范围,每一个进程向地址空间申请一块内存就正常给。那为什么有地址空间?1.每个进程可以统一视角看待内存,不用让进程特殊性的记录自己的代码、数据等在物理内存的什么地方。以前进程直接访问内存,现在进程访问内存要经过中间转化过程(地址空间+页表),为啥这样做?再看个小故事:小王过年总会有很多压岁钱,当小时候拿着压岁钱去买东西总会买一些自己不要的东西,就是乱花钱现象严重。有一天妈妈找到小王说把压岁钱给妈妈保管,小王买什么再妈妈这里取钱再去买,相当于以前小王和商店直接交易,现在中间多了妈妈。小王有一天想买文具盒,妈妈给钱同意了;小王有一天想买游戏机,妈妈怕影响学习没有同意。这个过程中妈妈存在的意义是在花钱事情上不要让小王过多犯错,妈妈可以对小王要花的钱进行判定,若花的是'非法的'钱可以提前拦截。以前直接访问内存,万一越界进程挂了都是小事,主要影响别人问题就大了。现在加了虚拟地址空间到页表映射,一旦访问的区域没在虚拟页表中进行申请,页表中没映射条目,所以中间转换过程可对虚拟到物理内存进行系统级别的检查,从而有效拦截非法操作。因此虚拟地址空间存在意义是增加进程虚拟地址空间可以让我们访问内存的时候,增加一个转换过程,在这个转换过程中可以对我们的寻址请求进行检查,所以一旦异常访问,直接拦截,该请求不会到达物理内存,保护物理内存。
下面谈一下页表,现在知道每个进程都有pcb结构task_struct,每个进程创建时都要有自己对应的地址空间struct mm_struct,它里面是划分好的一个个的内存区域,task_struct里有对应的mm_struct*指向自己对应的地址空间。同时知道有物理内存,地址空间内每个都有它的地址,当进程要访问内存,它当前一定正在运行。系统为了能线性地址到物理地址转化,系统会为该进程维护页表结构。其中页表结构可认为有三个字段,可把它想象成映射表。要用它也得找到页表,每个当前正在执行的进程,它页表起始地址在cpu内有一个寄存器,叫做cr3寄存器,这个寄存器会保留当前进程页表的起始地址:
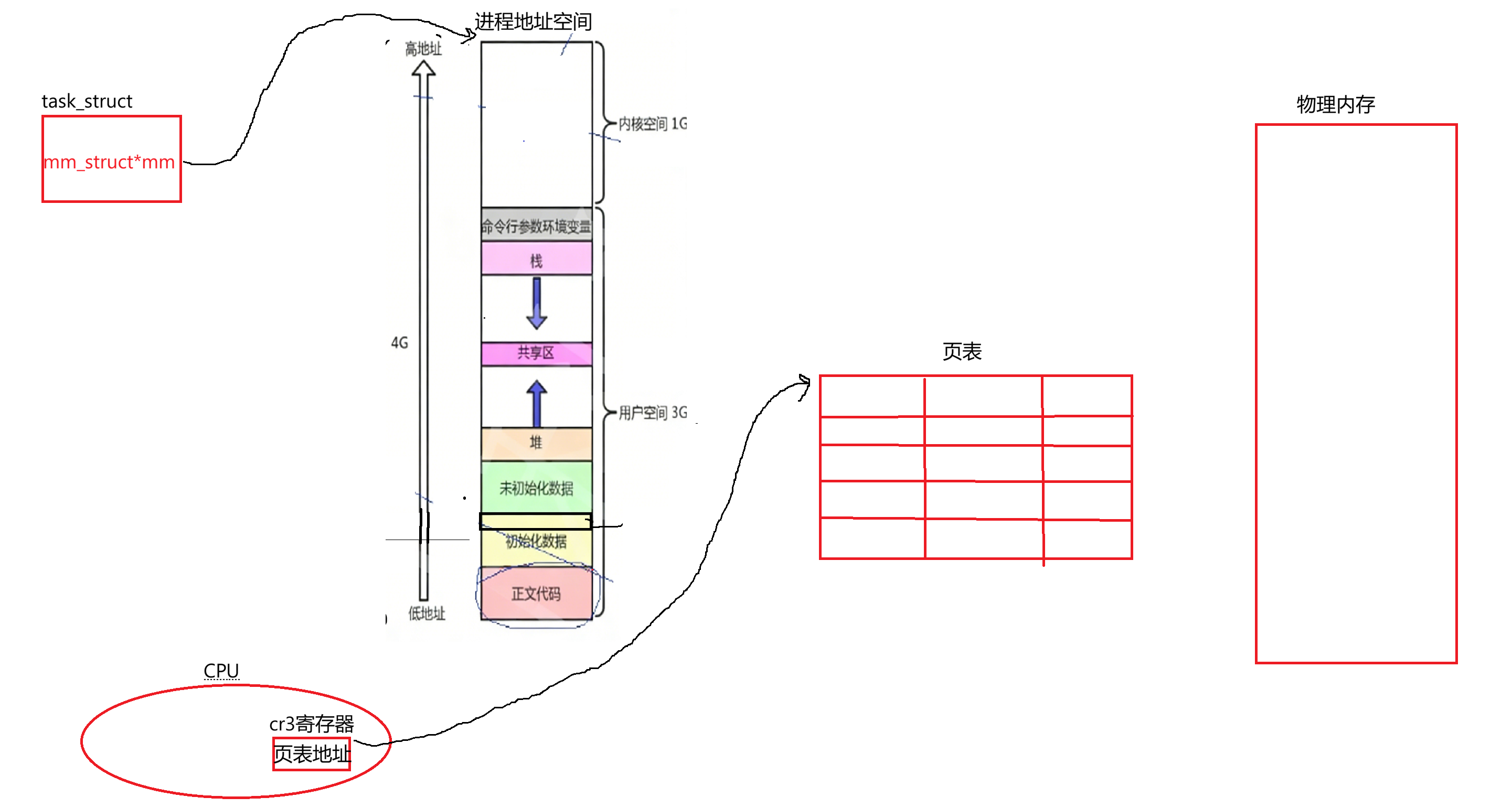
所以当前正在运行进程页表的地址可在它里面找到。假如当前进程被切换走了,不担心找不到页表,里面存的地址本质上属于进程的硬件上下文。所以进程不运行切换走了,会把寄存器中的内容带走,回来时把曾经保存的页表地址子再恢复上来,因此可以找到。假设虚拟地址是0x123456,访问的物理地址是0x312,里面存了100。进程启动时左侧填写虚拟地址,右侧填写物理地址,此时页表指向物理地址:
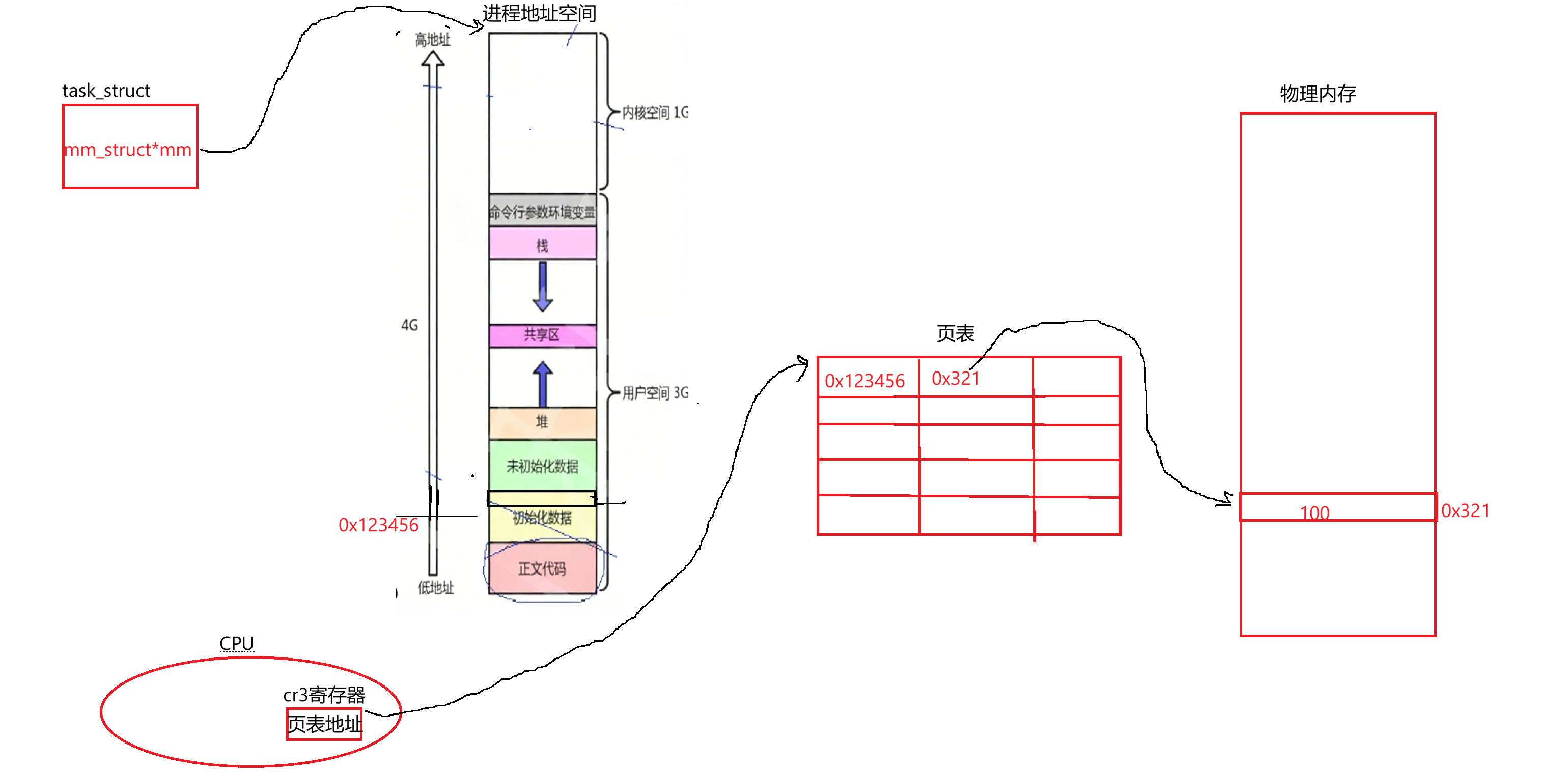
这都没有问题。下面关于页表再说个知识点:当我们要访问对应数据时,对应的代码、字符常量区我们知道它是只读的,那怎么知道要访问的区域只能读还是只能写等等呢?所以页表条目中还有对应的标志位来标识当前访问的物理内存能干嘛(0、1的位图)。假设有段代码,只需维护好页表:
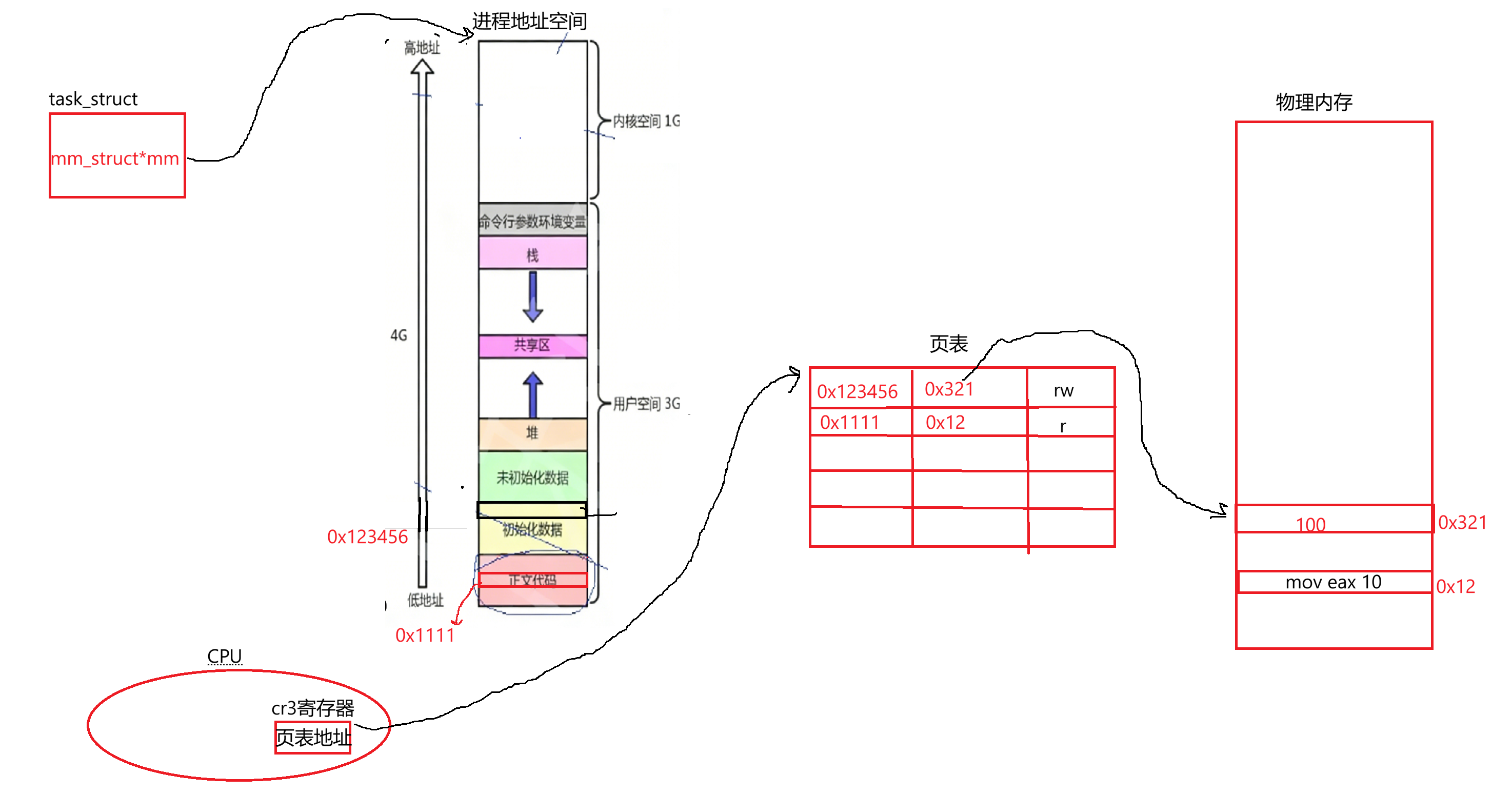
当访问代码时可查到权限是r,若尝试向该位置写入,页表发现权限只读,直接进行拦截,所以页表能提供很好的权限管理。
下面理解一个曾经的历史问题:
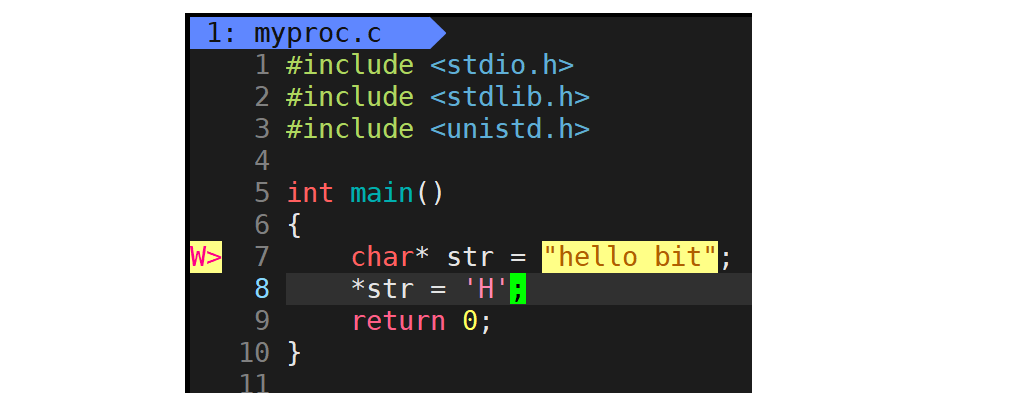
按以前理解这个字符串中常量在内存常量区,只能被读取不能被修改。现在问题是我们经常说代码是只读的,字符常量区是只读的,为什么?那如果是这样说,那磁盘中的程序是如何加载到只读区域的?所以物理内存是没有读写概念的,程序可写进去,想写想读都可以。只读只写是因为页表中映射关系中标识了只读,所以超出权限操作时OS会拦截进程才会挂了。曾经说过进程是可以被挂起的,一个进程运行时物理内存恰好不足,进程当前处于阻塞状态,系统把进程所对应的代码和数据腾出来以便内存使用。问题是怎么知道进程挂起了。进程状态里没有挂起,那你怎么知道进程的代码和数据在不在内存呢?如果代码和数据在内存,并且状态是R,说明在运行;若代码和数据在内存,状态是S,说明被阻塞,那怎么知道被挂起了?首先建立一个共识:现代OS,几乎不做任何浪费空间和浪费时间的事情;其次如果打大型游戏,计算机物理内存才4/8G,游戏几个G,这充分证明OS对大文件可实现分批加载。假设加载了500M空间,但代码是一行行跑的,短期内可能只用了5M,那剩下的495M用提前加载到内存吗?不会,OS对可执行程序加载采用的是惰性加载方式(真实在物理内存中用多少给多少)。因此比如正文代码段分批加载时有500M,页表中左侧把对应的虚拟地址都填上,物理地址这什么都不填。并且页表中还有个字段,它也是一种标记位,代表对应的代码和数据是否已经被加载到内存。当我们在访问虚拟地址时,查对应的页表,先看标志位,若标志位是1表示已经被加载,直接读物理地址找到物理内存中的区域访问;若发现对应代码和数据没有加载到内存,此时OS要触发一个概念叫缺页中断,就会找到可执行程序并在物理内存中申请一块内存把它加载进去,在把地址填到页表中,然后再恢复到当时要访问的过程,此时就能访问了。所以进程在被创建的时候是先创建内核数据结构,再加载对应的可执行程序。现在访问内存,经过虚拟地址转物理地址发现访问的内存不在系统当中,所以触发缺页中断重新申请内存。那申请哪方面内存?加载可执行程序哪一部分?一切完成后物理地址怎么填页表里?整个缺页中断过程是由OS来做,整个上述过程称为Linux的内存管理模块。整个上述过程当前进程并不知道,没有管过:
所以有页表存在,进程管理不用关心内存管理,进程要的内存只管用虚拟地址,没有了OS会自动调内存管理功能。因此为啥有地址空间第三点出来了,因为有地址空间和页表的存在,将进程管理模块和内存管理模块进行解耦合(各干各的事,有问题OS会出面)。
再重新理解一下什么叫进程:进程=内核数据结构(tast_struct && mm_struct && 页表)+程序的代码和数据。所以进程在切换时不仅切换pcb,也要切换地址空间,也要切换页表。这都不是问题,只要切换了进程pcb,所匹配的地址空间自动被切换,pcb指向对应的地址空间;页表地址cr3寄存器属于进程上下文,进程寄存器上下文切换,页表自动切换,归根结底进程切换仅需把进程cpu内上下文切换就都切换了。那总说进程有独立性,那它是怎么做到的?1.每个进程有pcb,mm_struct,页表,在内核数据结构上独立。2.在物理内存中加载的代码和数据,页表上虚拟地址可完全一样,物理地址可不一样,就可使每个进程代码和数据解耦。再来看代码数据加载到物理内存中任意位置无所谓,页表左侧虚拟地址可呈现一个连续线性空间给进程,这样可让进程以统一视角看待内存,把无序变有序。