内核观测工具BPF实例
- BPF介绍
- BPF实例
-
- [使用 BCC 工具集(最简单)](#使用 BCC 工具集(最简单))
- [使用 libbpf + BPF 骨架(更接近生产环境)](#使用 libbpf + BPF 骨架(更接近生产环境))
- [使用 bpftool 直接加载(适合调试)](#使用 bpftool 直接加载(适合调试))
- 总结
BPF介绍
BPF 最初诞生于 1992 年,是一种用于网络数据包过滤的虚拟机技术。它允许用户空间程序向内核注入简单的过滤指令,在内核态高效过滤数据包,避免将无关数据拷贝到用户空间。鼎鼎大名的tcpdump就是基于BPF实现的。
2014 年起,内核将 BPF 扩展为 eBPF,彻底革新了其能力:
- 通用虚拟机:eBPF 指令集更接近现代 CPU 架构(64 位寄存器、复杂指令),可在内核中运行任意安全的用户定义程序。
- 挂载点扩展:不仅限于网络,可挂载到内核函数入口/出口(kprobes)、用户空间函数(uprobes)、跟踪点(tracepoints)、网络数据包处理(XDP、TC)、cgroup 等数十种事件源。perf只能对这些事件进行统计跟踪展示,而eBPF程序能在事件发生时执行用户自定义的函数。
- 安全性:eBPF 程序必须先通过验证器检查,确保不会导致内核崩溃、无限循环或访问非法内存;随后通过即时编译(JIT) 转换为原生机器码执行,性能极高。
- 内核与用户空间通信:通过 eBPF Maps(键值存储)实现内核与用户空间、以及不同 eBPF 程序之间的数据交换。
BPF实例
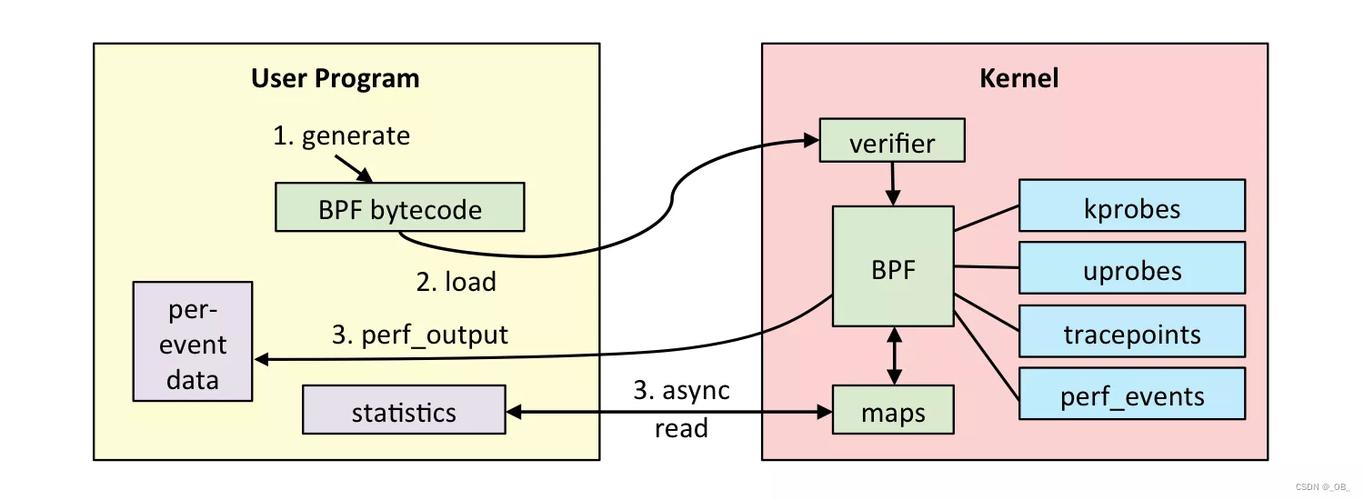
eBPF(Extended Berkeley Packet Filter)二进制程序本身不能直接在终端像普通可执行文件那样运行。它的执行有特殊的流程:你编写的 eBPF C 代码需要经过编译、加载、验证、挂载,最终由内核执行。
- 编写 eBPF 程序(通常用 C 语言)
- 通过 clang 编译成 eBPF 字节码(ELF 文件)
- 使用用户态加载程序将字节码加载到内核
- 内核验证器检查安全性后,将字节码编译为原生机器码
- 将程序挂载到指定的挂载点(如 kprobe、tracepoint、XDP 等)
- 当事件触发时,内核执行该 eBPF 程序
使用 BCC 工具集(最简单)
通过bcc工具使用python来编写bpf程序非常方便,可直接运行。
#!/usr/bin/env python3
from bcc import BPF
# eBPF C 代码作为字符串
bpf_code = """
int hello_world(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
# 加载程序
b = BPF(text=bpf_code)
# 挂载到 sys_clone 系统调用
b.attach_kprobe(event=b.get_syscall_fnname("execve"), fn_name="hello_world")
# 读取输出
b.trace_print()直接在终端运动该python文件即可看到效果。
使用 libbpf + BPF 骨架(更接近生产环境)
-
先写一个bpf钩子mybpf.c,当内核执行函数sys_enter_execve时触发我们的钩子进行输出。
#include <linux/bpf.h>
#define SEC(NAME) attribute((section(NAME), used))static int (*bpf_trace_printk)(const char *fmt, int fmt_size,
...) = (void *)BPF_FUNC_trace_printk;SEC("tracepoint/syscalls/sys_enter_execve")
int bpf_prog(void *ctx) {
char msg[] = "Hello, BPF World!";
bpf_trace_printk(msg, sizeof(msg));
return 0;
}
char _license[] SEC("license") = "GPL";// 编译方法:clang -g -O2 -target bpf -c mybpf.c -o mybpf.o -I/usr/include/x86_64-linux-gnu/
SEC("tracepoint/syscalls/sys_enter_execve") 定义挂载点为系统调用sys_enter_execve,当系统内核响应此调用时执行下面的bpf_prog函数,进行打印输出。
-
生成骨架:
bpftool gen skeleton mybpf.o > mybpf.skel.h
-
用户端简单加载程序loader.c
gcc -o myloader loader.c -lbpf -lelf -lz 即可生成可执行程序,执行后
cat /sys/kernel/debug/tracing/trace_pipe 可查看mybpf.c程序的输出。
/ minimal_loader.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "mybpf.skel.h" // 由bpftool生成的骨架头文件static volatile int exiting = 0;
static void sig_handler(int sig) {
exiting = 1;
}int main(int argc, char **argv) {
struct mybpf *skel;
int err;// 1. 信号处理,用于优雅退出 signal(SIGINT, sig_handler); signal(SIGTERM, sig_handler); // 2. 打开BPF程序(从当前目录的mybpf.o文件) skel = mybpf__open(); if (!skel) { fprintf(stderr, "Failed to open BPF skeleton\n"); return 1; } // 3. 加载并验证BPF程序到内核 err = mybpf__load(skel); if (err) { fprintf(stderr, "Failed to load BPF skeleton: %d\n", err); goto cleanup; } // 4. 附加到内核事件(如kprobe) err = mybpf__attach(skel); if (err) { fprintf(stderr, "Failed to attach BPF skeleton: %d\n", err); goto cleanup; } printf("BPF程序加载成功!按Ctrl-C退出...\n"); // 5. 主循环,等待退出信号 while (!exiting) { sleep(1); }cleanup:
// 6. 清理资源,自动卸载BPF程序
mybpf__destroy(skel);
return err;
}
使用 bpftool 直接加载(适合调试)
查看当前bpf程序 bpftool prog list
bash
152: cgroup_device name sd_devices tag a97c143260cd9940 gpl
loaded_at 2026-03-25T14:25:08+0800 uid 0
xlated 416B jited 260B memlock 4096B
156: cgroup_device name s_thunderbird_t tag 5592a8780089fcce gpl
loaded_at 2026-03-25T14:26:17+0800 uid 1000
xlated 296B jited 164B memlock 4096B map_ids 48
172: cgroup_skb name sd_fw_egress tag 772db7720b2728e9 gpl
loaded_at 2026-03-25T15:18:08+0800 uid 0
xlated 64B jited 56B memlock 4096B
173: cgroup_skb name sd_fw_ingress tag 772db7720b2728e9 gpl
loaded_at 2026-03-25T15:18:08+0800 uid 0
xlated 64B jited 56B memlock 4096B
root@zhongsc-ThinkPad-P51:/work/bpf/linux-obser加载自己的bpf程序
bash
# 编译 eBPF 程序
clang -g -O2 -target bpf -c mybpf.c -o mybpf.o -I/usr/include/x86_64-linux-gnu/
# 加载到内核,并挂载事件
bpftool prog loadall mybpf.o /sys/fs/bpf/mybpf autoattach
# 卸载
sudo rm /sys/fs/bpf/my_prog总结
原来linux提供了如此强大的工具,让用户可以跟踪内核和用户态的任意函数,很多强大的工具都是通过它实现的,linux还有什么好玩的工具,敬请期待后续章节。