1 引言:MP3的技术遗产与当代价值
MP3(MPEG-1 Audio Layer III)自1993年标准化以来,统治数字音频生态逾二十年。尽管AAC、Opus等新一代编码器在效率上已超越MP3,但截至2025年,全球存量MP3文件仍超过千亿级别,车载音响、 legacy 播放器、广播设备仍广泛支持该格式。理解MP3不仅是掌握一项技术,更是理解**感知编码(Perceptual Coding)**范式的最佳入口------所有现代有损音频编码(AAC、Opus、杜比数字)的核心思想均源于MP3奠基的心理声学模型。
本文将深入MP3编码器的数学内核,解析其子带分解、MDCT变换、掩蔽阈值计算等关键技术,并通过Python(兼容3.9-3.13)实现对LAME编码器的全参数控制,涵盖从CBR(恒定码率)到VBR(可变码率)的精细调节,以及元数据注入、批量处理管道等工程实践。
2 MP3编码的物理与信息论基础
2.1 数字音频的时空边界:采样与量化回顾
MP3处理的对象是PCM(脉冲编码调制)数据。在编码之前,模拟声波已历经采样与量化:
采样定理约束 :根据奈奎斯特-香农定理,采样频率 fsf_sfs 必须大于信号最高频率 fmaxf_{max}fmax 的两倍。MP3标准支持三种采样率:32kHz、44.1kHz(CD标准)、48kHz。这意味着MP3编码器可处理的理论最高频率分别为16kHz、22.05kHz和24kHz。
量化噪声基底 :16bit量化的理论动态范围为 20log10(216)≈96dB20\log_{10}(2^{16}) \approx 96\text{dB}20log10(216)≈96dB,而MP3的目标是在128kbps立体声码率下(压缩比约11:1),将量化噪声控制在掩蔽阈值以下,实现"透明音质"。
2.2 信息冗余的三种形态
MP3的压缩效率来源于去除三种冗余:
- 统计冗余:音频信号在时频域的幅值分布不均匀,哈夫曼编码利用此特性实现无损压缩
- 听觉冗余:人耳听觉阈值以下的信号分量(心理声学冗余)
- 时域掩蔽冗余:强信号瞬态前后短暂时间内的弱信号不可闻
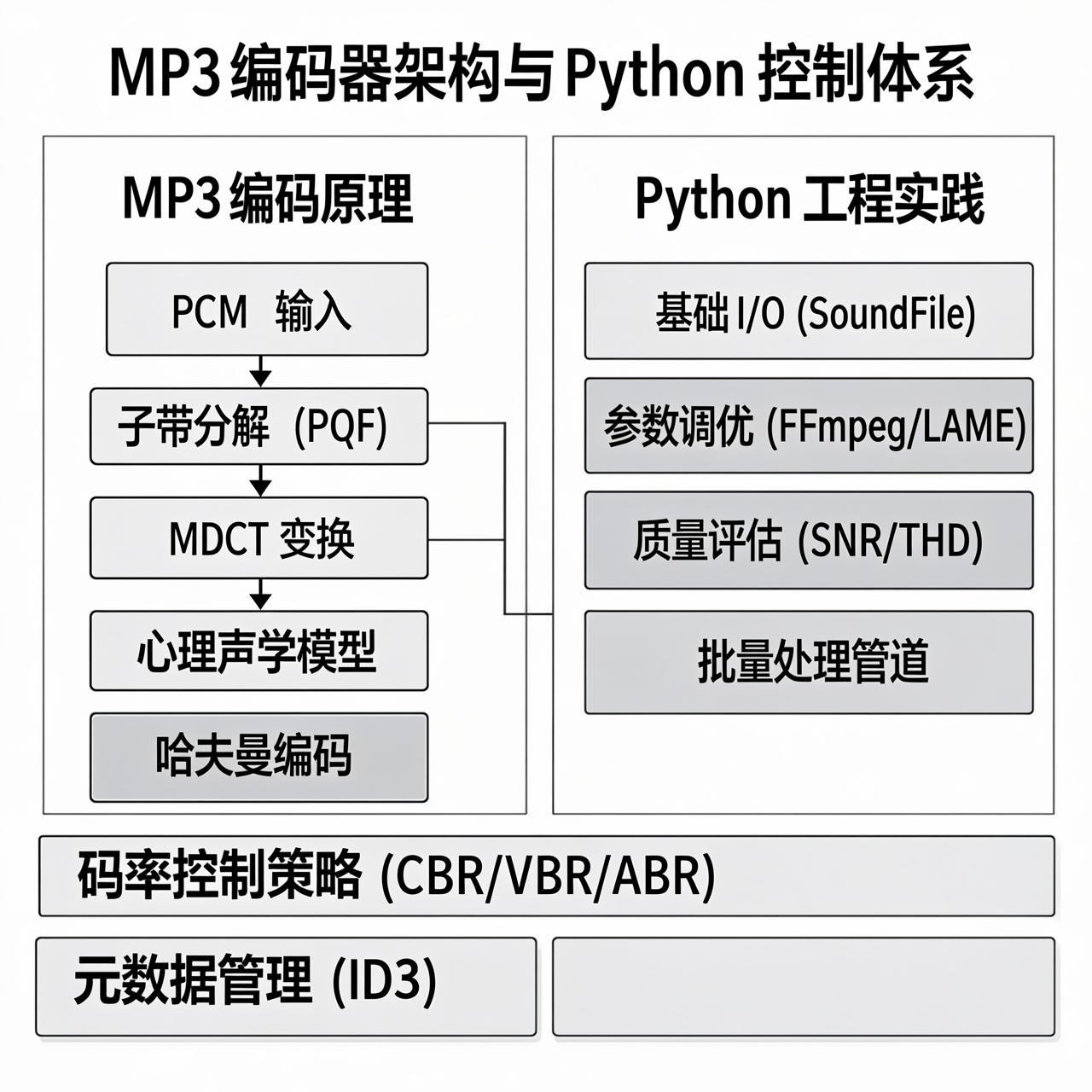
3 MP3编码器架构:分层技术栈深度解析
MP3编码器是一个复杂的分析-合成系统,其流程可划分为五个逻辑层级:
3.1 多相正交滤波器组(PQF):子带分解
MP3首先将全频带信号分割为32个等宽子带(Subband),每个子带带宽为 fs64\frac{f_s}{64}64fs(对于44.1kHz采样率,每个子带约689Hz)。这一步骤由**多相正交滤波器组(Polyphase Quadrature Filter, PQF)**实现。
数学原理 :PQF基于余弦调制滤波器组,其冲激响应为:
hk(n)=h(n)⋅cos(2k+1)π2M(n−N−12)+θkh_k(n) = h(n) \cdot \cos\left\\frac{(2k+1)\\pi}{2M}(n-\\frac{N-1}{2}) + \\theta_k\\righthk(n)=h(n)⋅cos2M(2k+1)π(n−2N−1)+θk
其中 M=32M=32M=32 为子带数,h(n)h(n)h(n) 为原型低通滤波器,kkk 为子带索引。
关键特性:
- 临界采样:32个子带每帧输出36个样本(Layer III),总样本数保持恒定
- 混叠现象:相邻子带间存在混叠,需在合成端通过特定窗函数抵消(但MP3的PQF并非完美重构滤波器组,引入固有失真)
与AAC的区别:AAC采用MDCT直接对全频带处理,省去PQF层,避免了子带边界混叠,这是AAC效率更高的原因之一。
3.2 改良离散余弦变换(MDCT):时频分析
MP3在PQF之后,对每个子带执行MDCT(Modified Discrete Cosine Transform),将时域样本转换为频域系数。MDCT是MP3区别于Layer I/II的关键创新。
变换公式 :
X(k)=∑n=02N−1x(n)⋅h(n)⋅cosπN(n+N+12)(k+12)X(k) = \sum_{n=0}^{2N-1} x(n) \cdot h(n) \cdot \cos\left\\frac{\\pi}{N}(n+\\frac{N+1}{2})(k+\\frac{1}{2})\\rightX(k)=n=0∑2N−1x(n)⋅h(n)⋅cosNπ(n+2N+1)(k+21)
其中 NNN 为块长度(MP3中长块18点,短块6点),h(n)h(n)h(n) 为正弦窗。
长块与短块自适应:
- 长块(Block Type 0):18点MDCT,频率分辨率高(93Hz/bin@44.1kHz),适合稳态信号(如长音弦乐)
- 短块(Block Type 2):6点MDCT,时间分辨率高,适合瞬态信号(如打击乐),减少预回声(Pre-echo)失真
- 混合块(Block Type 1/3):过渡状态
时域混叠抵消(TDAC):MDCT通过50%重叠相加与特定窗函数,在合成端完美抵消混叠,实现临界采样。
3.3 心理声学模型 I/II:感知熵的计算
MP3编码器并行运行心理声学模型(通常使用Model II,更精确),计算每个频带的掩蔽阈值。
关键步骤:
-
FFT分析:对每帧576个样本( granule,粒度)进行1024点FFT,获得高分辨率频谱
-
音调性检测 :计算频谱的不可预测度(Unpredictability Measure),区分乐音(tonal)与噪声(non-tonal)成分。乐音在临界频带内产生更大掩蔽效应
-
掩蔽阈值计算:
- 同时掩蔽 :强信号频率 fmf_mfm 对其附近频率的掩蔽遵循扩散函数 SF(z)=15.81+7.5(z−zm)−17.5∣z−zm∣0.4SF(z) = 15.81 + 7.5(z-z_m) - 17.5|z-z_m|^{0.4}SF(z)=15.81+7.5(z−zm)−17.5∣z−zm∣0.4(z为Bark频率)
- 绝对听觉阈值:安静环境下的听阈曲线(ISO 226标准)
- 掩蔽阈值取极值 :Lmask(f)=max(Labsolute(f),∑mLmasking(f,fm))L_{mask}(f) = \max(L_{absolute}(f), \sum_{m} L_{masking}(f,f_m))Lmask(f)=max(Labsolute(f),∑mLmasking(f,fm))
-
信掩比(SMR)计算 :SMR=Lsignal−LmaskSMR = L_{signal} - L_{mask}SMR=Lsignal−Lmask,决定量化比特分配优先级
位分配策略:编码器将可用比特优先分配给SMR高的频带(高能量且未被掩蔽),对SMR<0的频带(掩蔽阈值高于信号)减少或分配零比特。
3.4 量化和位分配:噪声整形
MP3使用非均匀量化器 ,步长由**比例因子(Scalefactor)和全局增益(Global Gain)**控制:
xquantized=nint(∣x∣scalefactor)3/4−0.0946x_{quantized} = \text{nint}\left\\left(\\frac{\|x\|}{\\text{scalefactor}}\\right)\^{3/4} - 0.0946\\rightxquantized=nint(scalefactor∣x∣)3/4−0.0946
3/4幂律:对数域近似,模拟人耳对响度的非线性感知(韦伯-费希纳定律)。
位池(Bit Reservoir)技术:MP3允许从先前帧"借用"比特,在瞬态信号时增加比特分配,在稳态时归还,平滑码率波动,提升VBR效率。
3.5 哈夫曼编码与帧封装
量化后的频谱系数通过哈夫曼编码进一步压缩。MP3使用32个预定义哈夫曼码表(分为四区:big values、count1、zero),根据系数分布动态选择最优表。
帧结构:
- 同步头(Header):11个同步位(0xFFE),标识帧起始
- CRC校验(可选):16bit校验和,保护头部与边信息
- 边信息(Side Info):包含位分配表、比例因子、哈夫曼表选择等
- 主数据(Main Data):哈夫曼编码的频谱系数
4 MP3的码率控制策略:CBR、VBR与ABR
4.1 CBR(Constant Bitrate):恒定码率
每帧分配固定比特数(如128kbps立体声每帧约418字节)。简单但效率低,复杂段落(如交响乐)可能比特不足,简单段落(如静音)浪费比特。
4.2 VBR(Variable Bitrate):可变码率
根据信号复杂度动态调整每帧比特数。LAME编码器使用质量等级(VBR Quality Level,-V参数,0-9):
- -V0:最高质量(约245kbps),几乎透明
- -V2:推荐质量(约190kbps),透明度高
- -V5:便携质量(约130kbps),兼顾容量与音质
VBR通过心理声学模型计算所需比特数,允许位池动态管理。
4.3 ABR(Average Bitrate):平均码率
指定目标平均码率(如192kbps),编码器在此约束下灵活分配比特,兼顾VBR效率与CBR的可预测性。
5 Python全参数调优实战
5.1 环境搭建与库选择
Python操控MP3编码主要依赖FFmpeg (底层实现)与LAME(高质量MP3编码器)。我们使用三个层级:
- ffmpeg-python:直接映射FFmpeg命令行参数,功能最全
- pydub:高层抽象,适合快速处理
- lameenc:Python绑定libmp3lame,可精细控制编码器内部参数
bash
# 安装依赖(Python 3.9-3.13兼容)
pip install ffmpeg-python pydub lameenc numpy
# 确保系统安装FFmpeg与libmp3lame
# Ubuntu: sudo apt-get install ffmpeg libmp3lame0
# Windows: 下载static build并加入PATH5.2 基础编码与核心参数解析
使用ffmpeg-python进行精细控制:
python
import ffmpeg
import os
def encode_mp3_advanced(input_file, output_file,
bitrate='192k',
bitrate_mode='cbr', # 'cbr', 'vbr', 'abr'
vbr_quality=2, # 0-9, 0=best
sample_rate=44100,
channels=2,
cutoff=20000, # 低通滤波频率
algorithm_quality=0): # 0-9, 0=best/slow
"""
MP3编码全参数控制
参数说明:
- bitrate: 目标码率(CBR/ABR)或VBR下限
- vbr_quality: LAME VBR质量等级(-V参数)
- algorithm_quality: 编码算法复杂度(-q:a)
- cutoff: 低通滤波截止频率(防止混叠)
"""
stream = ffmpeg.input(input_file)
# 音频编码参数构建
audio_kwargs = {
'c:a': 'libmp3lame', # 使用LAME编码器
'ar': sample_rate, # 采样率
'ac': channels, # 声道数
'cutoff': cutoff, # 低通滤波
'q:a': algorithm_quality # 算法质量(与VBR不同)
}
# 码率控制模式
if bitrate_mode == 'cbr':
audio_kwargs['b:a'] = bitrate
audio_kwargs['vbr'] = 'off'
elif bitrate_mode == 'vbr':
# LAME VBR质量等级映射
# ffmpeg使用-q:a 0-9对应LAME的-V 9-0(注意反向)
vbr_map = {0:0, 1:1, 2:2, 3:3, 4:4, 5:5, 6:6, 7:7, 8:8, 9:9}
audio_kwargs['q:a'] = vbr_map.get(vbr_quality, 2)
elif bitrate_mode == 'abr':
audio_kwargs['b:a'] = bitrate
audio_kwargs['abr'] = 1
stream = ffmpeg.output(stream, output_file, **audio_kwargs)
# 执行并捕获错误
try:
ffmpeg.run(stream, overwrite_output=True, capture_stdout=True)
print(f"编码成功: {output_file}")
except ffmpeg.Error as e:
print(f"编码错误: {e.stderr.decode()}")
# 示例:高质量VBR编码
encode_mp3_advanced(
input_file='input.wav',
output_file='output_vbr.mp3',
bitrate_mode='vbr',
vbr_quality=2, # -V2,接近透明
cutoff=19500, # 保留接近奈奎斯特频率的高频
algorithm_quality=0 # 最高质量算法(最慢)
)5.3 深度参数调节:心理声学优化
python
def encode_with_psy_tuning(input_file, output_file,
psy_model=2, # 心理声学模型(1或2)
ath_type=3, # 绝对阈值类型
nspsytune=True, # 噪声整形优化
ms_threshold=0, # Mid/Side编码阈值
disable_reservoir=False):
"""
心理声学参数精细调节(需直接使用LAME命令行或lameenc)
"""
import subprocess
cmd = [
'lame',
'--preset', 'standard', # 预设模板
'-q', '0', # 算法质量
'--vbr-new', # 新VBR算法
'-V', '2', # VBR质量
'--ath', str(ath_type), # 绝对阈值调整
'--nspsytune' if nspsytune else '--no-nspsytune',
'-m', 's' if ms_threshold >= 0 else 'j', # 立体声模式
'--reservoir' if not disable_reservoir else '--nores',
input_file,
output_file
]
result = subprocess.run(cmd, capture_output=True, text=True)
return result.returncode == 0
# 说明:
# --ath: 调整心理声学模型中的绝对听觉阈值,正值降低阈值(更保守编码)
# --nspsytune: 启用噪声整形与心理声学微调,提升微弱信号质量
# -m s: 简单立体声(独立编码左右声道),适合相位差异大的录音
# -m j: 联合立体声(Mid/Side编码),利用声道间相关性节省比特5.4 使用 lameenc 进行原生 LAME 控制
lameenc库提供Pythonic的LAME接口,支持比特池深度、VBR模式等内部参数:
python
import lameenc
import numpy as np
def encode_numpy_to_mp3(audio_array, sample_rate, output_file,
bitrate_mode=lameenc.VBR_MEDIUM,
quality=2):
"""
直接从NumPy数组编码MP3
audio_array: float32或int16数组,形状(samples,)或(samples, channels)
"""
# 确保数据格式
if audio_array.dtype != np.int16:
# 转换为16bit PCM(LAME期望输入)
audio_int16 = (audio_array * 32767).astype(np.int16)
else:
audio_int16 = audio_array
# 确定声道数
channels = 1 if audio_int16.ndim == 1 else audio_int16.shape[1]
# 初始化编码器
encoder = lameenc.Encoder()
encoder.set_bit_rate(128) # 基础码率(VBR下为最小值)
encoder.set_sample_rate(sample_rate)
encoder.set_channels(channels)
encoder.set_quality(quality) # 算法质量
encoder.set_vbr_mode(bitrate_mode) # VBR_MEDIUM, VBR_DEFAULT等
encoder.set_vbr_quality(4) # 0-9
# 编码
mp3_data = encoder.encode(audio_int16.tobytes())
mp3_data += encoder.flush() # 刷新缓冲区
with open(output_file, 'wb') as f:
f.write(mp3_data)
# 生成测试信号并编码
sample_rate = 44100
duration = 10
t = np.linspace(0, duration, int(sample_rate * duration))
# 生成1kHz正弦波+高频噪声(测试低通滤波)
signal = 0.5 * np.sin(2 * np.pi * 1000 * t) + 0.1 * np.random.randn(len(t))
signal = signal.astype(np.float32)
encode_numpy_to_mp3(signal, sample_rate, 'test.mp3',
bitrate_mode=lameenc.VBR_HIGHEST, quality=0)5.5 元数据与ID3标签精细控制
MP3的元数据存储在ID3标签中(ID3v1/v2.3/v2.4)。使用eyed3(兼容Python 3.9+)或mutagen进行高级标签操作:
python
from mutagen import File
from mutagen.mp3 import MP3
from mutagen.id3 import ID3, TIT2, TPE1, TALB, TYER, COMM, APIC
def add_comprehensive_metadata(mp3_file,
title="Unknown",
artist="Unknown",
album="Unknown",
year="2024",
comment="Encoded with Python",
cover_image=None):
"""
添加完整ID3v2.4标签与封面
"""
try:
audio = MP3(mp3_file)
except:
audio = MP3()
audio.filename = mp3_file
# 添加ID3标签(如果不存在)
if audio.tags is None:
audio.add_tags()
tags = audio.tags
# 文本帧
tags["TIT2"] = TIT2(encoding=3, text=title) # UTF-8编码
tags["TPE1"] = TPE1(encoding=3, text=artist)
tags["TALB"] = TALB(encoding=3, text=album)
tags["TYER"] = TYER(encoding=3, text=year)
tags["COMM"] = COMM(encoding=3, lang='eng', desc='Comment', text=comment)
# 封面图片
if cover_image and os.path.exists(cover_image):
with open(cover_image, 'rb') as img:
tags["APIC"] = APIC(
encoding=3, # UTF-8
mime='image/jpeg', # 或 image/png
type=3, # 封面
desc='Cover',
data=img.read()
)
# 保存(ID3v2.4标准)
tags.save(mp3_file, v2_version=4)
# 验证Xing/Info标签(VBR头)
info = audio.info
print(f"编码信息: {info.bitrate_mode}, {info.bitrate}kbps, {info.sample_rate}Hz")
# 使用示例
add_comprehensive_metadata(
'output.mp3',
title="Python生成的MP3",
artist="AI Composer",
album="Algorithmic Music",
cover_image="cover.jpg"
)5.6 批量处理与管道优化
python
import os
from concurrent.futures import ProcessPoolExecutor, as_completed
from pathlib import Path
def batch_encode(input_dir, output_dir,
target_bitrate='192k',
max_workers=4,
preserve_structure=True):
"""
批量MP3编码(并行处理)
"""
input_path = Path(input_dir)
output_path = Path(output_dir)
output_path.mkdir(parents=True, exist_ok=True)
# 收集任务
tasks = []
for ext in ['*.wav', '*.flac', '*.aiff']:
for file in input_path.rglob(ext):
if preserve_structure:
rel_path = file.relative_to(input_path)
out_file = output_path / rel_path.with_suffix('.mp3')
out_file.parent.mkdir(parents=True, exist_ok=True)
else:
out_file = output_path / f"{file.stem}.mp3"
tasks.append((file, out_file))
def encode_single(args):
infile, outfile = args
try:
(
ffmpeg
.input(str(infile))
.output(str(outfile),
acodec='libmp3lame',
audio_bitrate=target_bitrate,
ar=44100,
loglevel='error')
.overwrite_output()
.run()
)
return (infile, True, None)
except Exception as e:
return (infile, False, str(e))
# 并行执行
with ProcessPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(encode_single, task): task for task in tasks}
for future in as_completed(futures):
infile, success, error = future.result()
if success:
print(f"✓ {infile.name}")
else:
print(f"✗ {infile.name}: {error}")
# 使用示例
batch_encode('./raw_audio', './mp3_output', target_bitrate='256k', max_workers=4)5.7 质量评估与客观指标
python
import numpy as np
import librosa
import soundfile as sf
def calculate_audio_metrics(original, compressed):
"""
计算MP3编码的客观质量指标
返回:
- snr: 信噪比(dB)
- thd: 总谐波失真(%)
"""
# 加载并对齐(MP3延迟通常为1152样本)
orig, sr = librosa.load(original, sr=None, mono=True)
comp, _ = librosa.load(compressed, sr=sr, mono=True)
# 对齐长度(MP3帧边界可能导致长度差异)
min_len = min(len(orig), len(comp))
orig = orig[:min_len]
comp = comp[:min_len]
# 计算误差信号
error = orig - comp
# SNR计算
signal_power = np.mean(orig ** 2)
noise_power = np.mean(error ** 2)
snr = 10 * np.log10(signal_power / noise_power)
# 近似THD计算(简化版)
thd = np.sqrt(np.mean(error ** 2)) / np.sqrt(np.mean(orig ** 2)) * 100
return {
'snr_db': snr,
'thd_percent': thd,
'delay_samples': 1152 # MP3典型帧长
}
# 评估不同码率
for bitrate in ['128k', '192k', '320k']:
encode_mp3_advanced('test.wav', f'test_{bitrate}.mp3',
bitrate=bitrate, bitrate_mode='cbr')
metrics = calculate_audio_metrics('test.wav', f'test_{bitrate}.mp3')
print(f"码率 {bitrate}: SNR={metrics['snr_db']:.2f}dB, THD={metrics['thd_percent']:.3f}%")6 现代视角:MP3的局限与替代方案
尽管MP3具有极佳的兼容性,但在现代应用中需注意其技术局限:
- 频率截断:即使320kbps CBR,MP3的低通滤波通常在16-20kHz(取决于编码器),而AAC/Opus可保留更多高频细节
- 瞬态响应:预回声控制不如AAC的瞬时噪声整形(TNS)或Opus的Hybriv模式
- 空间音频:MP3仅支持2声道立体声,无法原生承载5.1/7.1或对象音频(需依赖MP3 Surround等非标准扩展)
迁移建议:
- 归档场景:使用FLAC(无损)或Opus(高压缩率无损感知)
- 流媒体:采用AAC(浏览器兼容)或Opus(WebRTC强制标准)
- 遗留兼容:MP3 320kbps CBR仍是最大兼容性的"安全选择"
7 总结
MP3编码器的复杂性在于其多层信号处理架构------从PQF的子带分解到MDCT的时频分析,从心理声学模型的掩蔽计算到哈夫曼编码的熵优化。通过Python的ffmpeg-python与lameenc库,我们不仅能调用这些功能,更能精细调节心理声学参数、VBR质量曲线与元数据结构。
在Python 3.13时代,尽管部分遗留音频库因标准库变更(如audioop移除)而失效,但基于soundfile、pydub与ffmpeg的现代工具链依然稳健。掌握MP3的参数调节艺术,不仅是理解数字音频压缩原理的最佳实践,更是维护海量 legacy 音频资产、优化存储与传输效率的必备技能。当面对"128kbps是否足够"或"VBR vs CBR如何选择"的工程决策时,深入理解本文阐述的心理声学模型与编码器内部机制,将助你做出数据驱动的技术选择。