ElasticSearch 怎么用,Java 开发,ES 如何使用
一、整体概述
ES 的使用,分为三步
1、创建索引库并设置映射,类似于创建数据库并创建表
2、新增文档数据,类似于给数据库中新增数据
3、查询文档数据,类似于从数据库中查询数据
二、举例说明
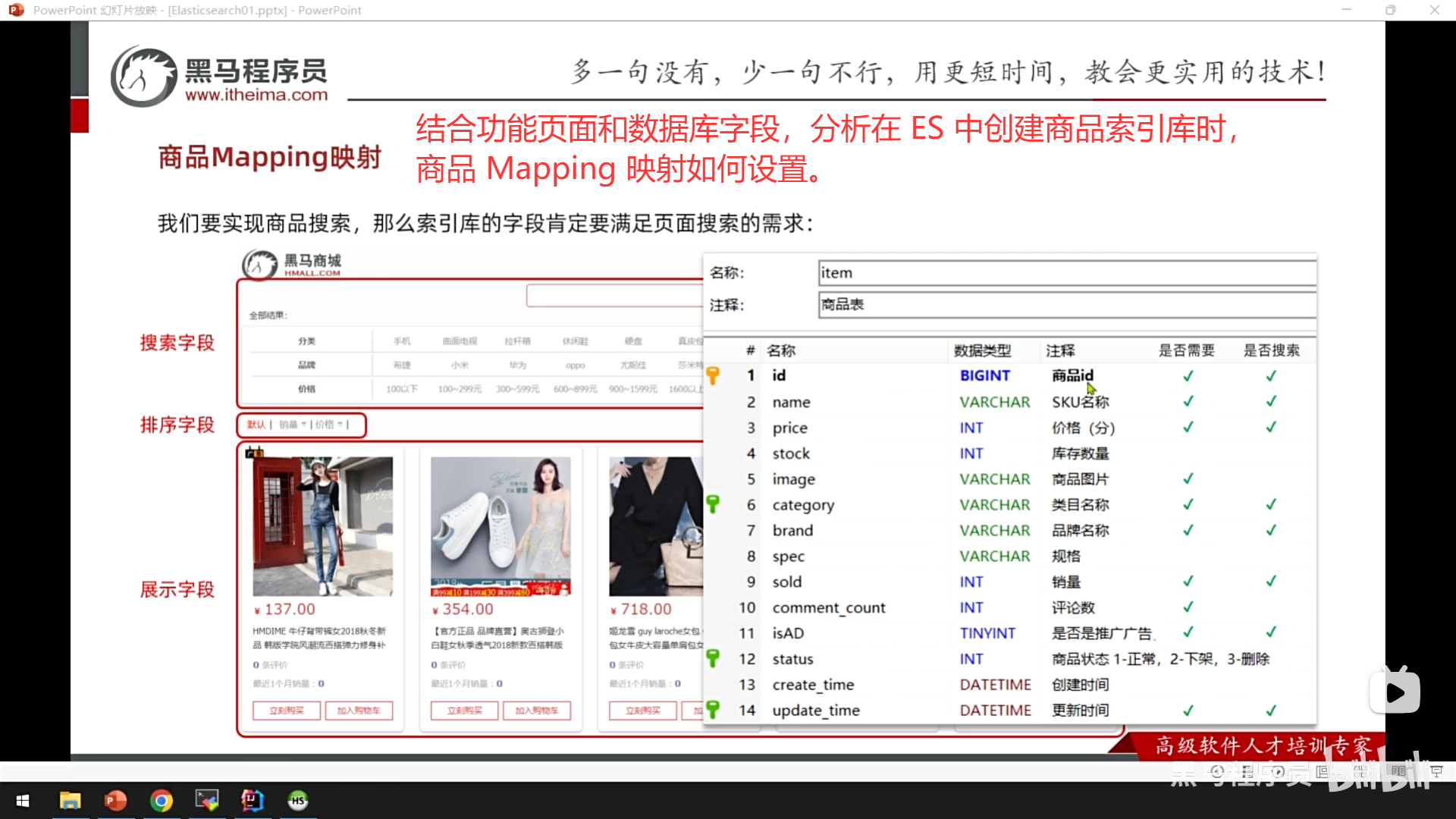
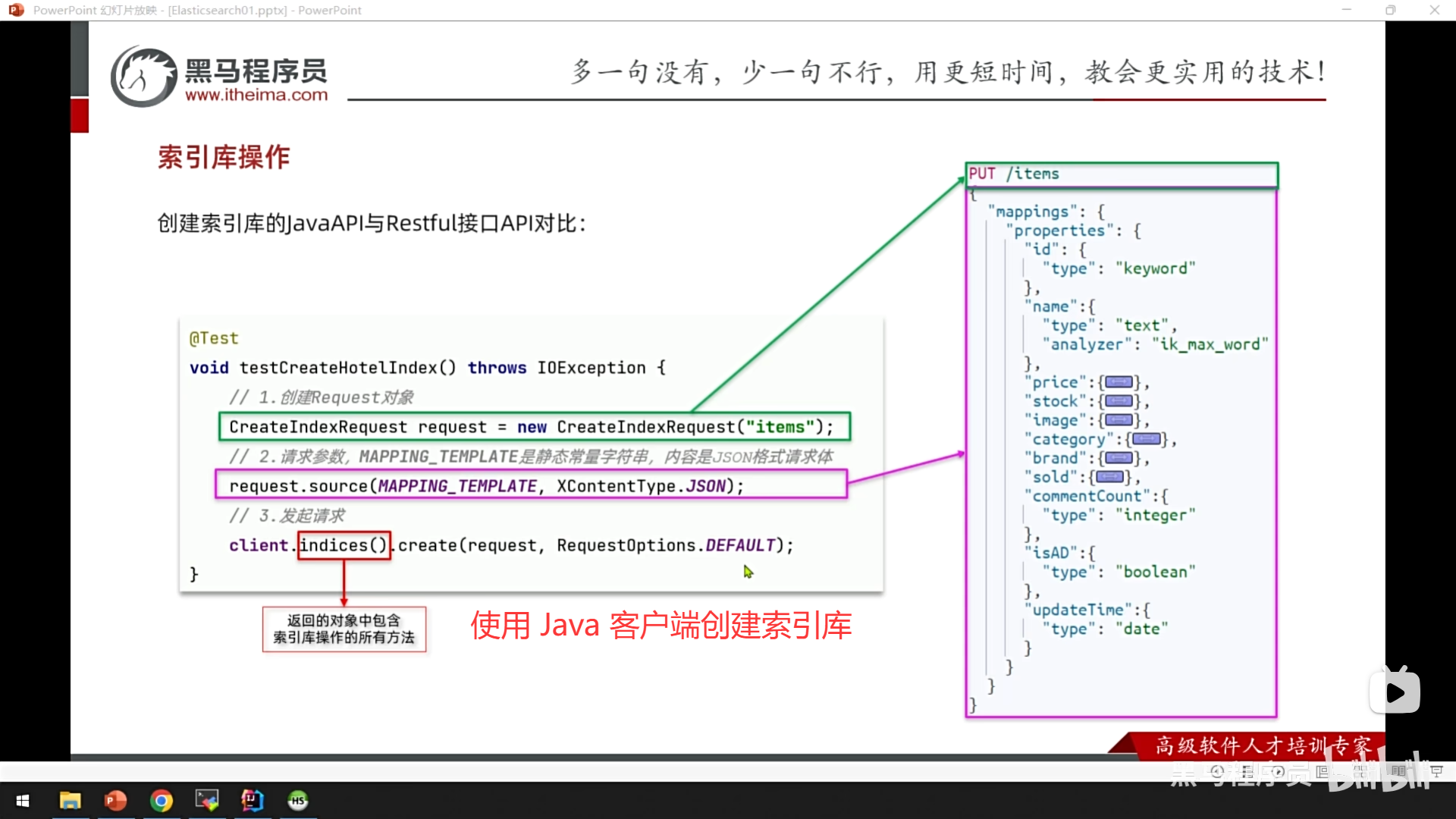
1、分析需求,创建索引库
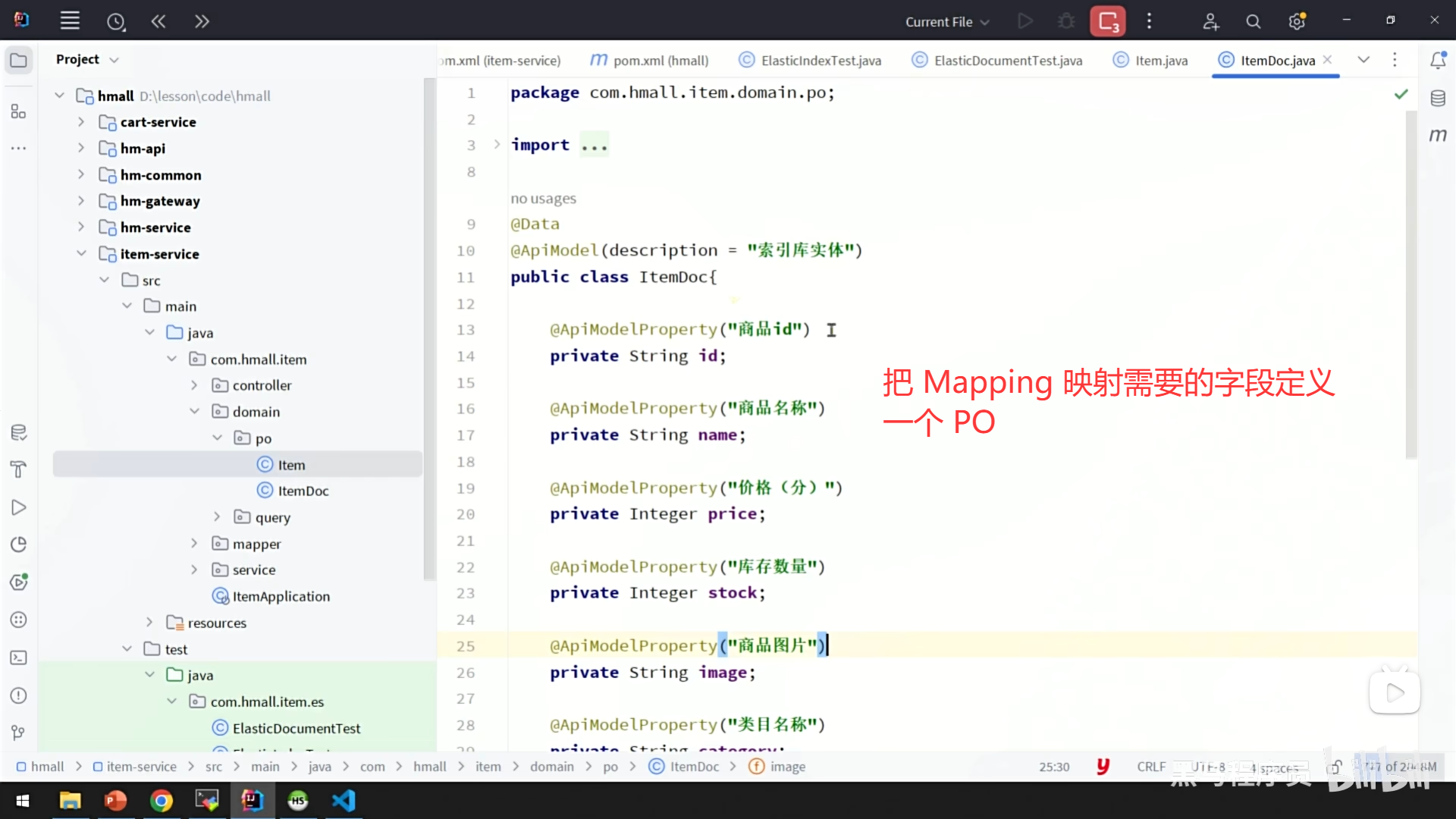
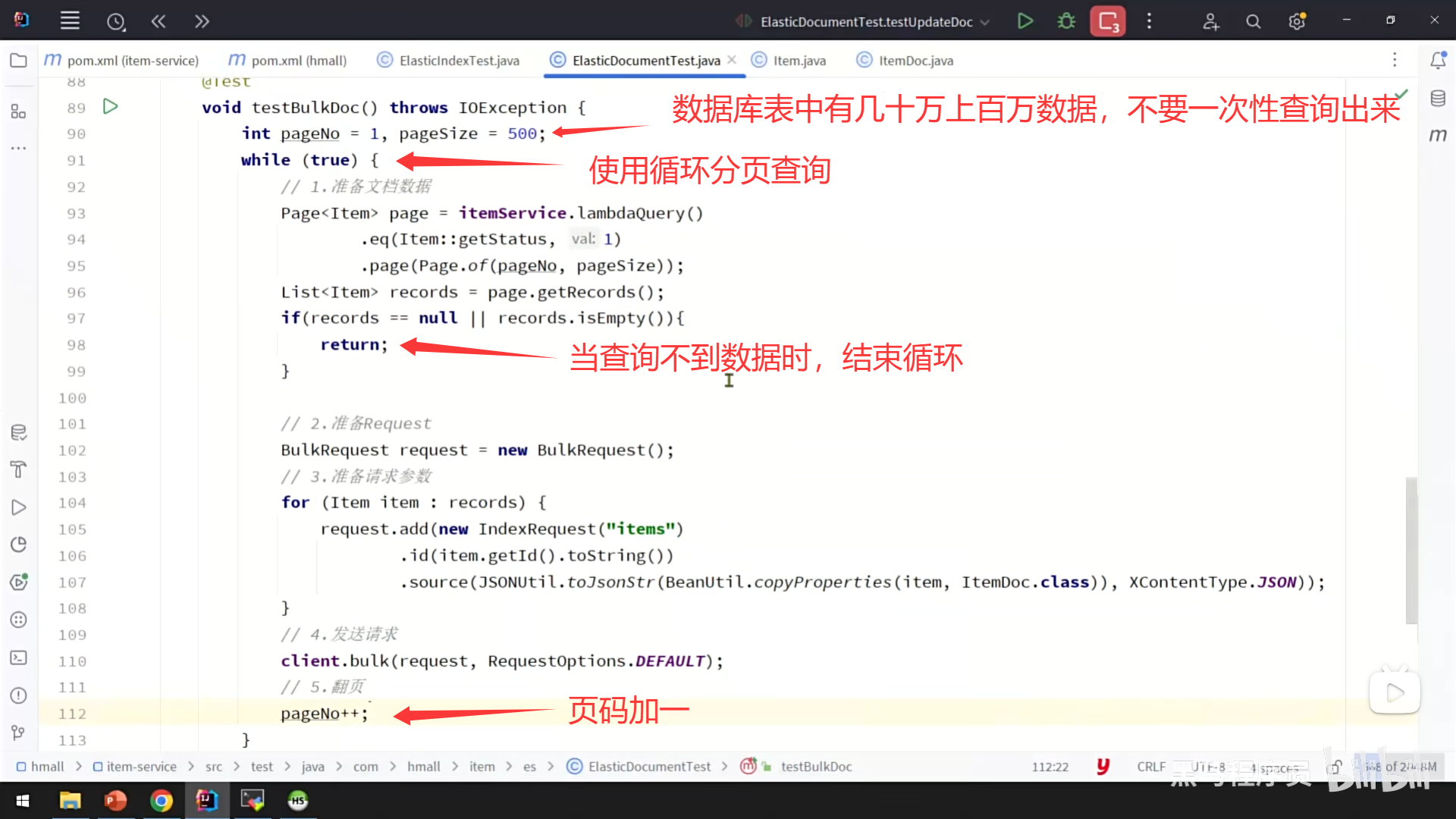
2、给索引库中添加文档数据,把数据库中相关的数据保存到 ES 索引库中
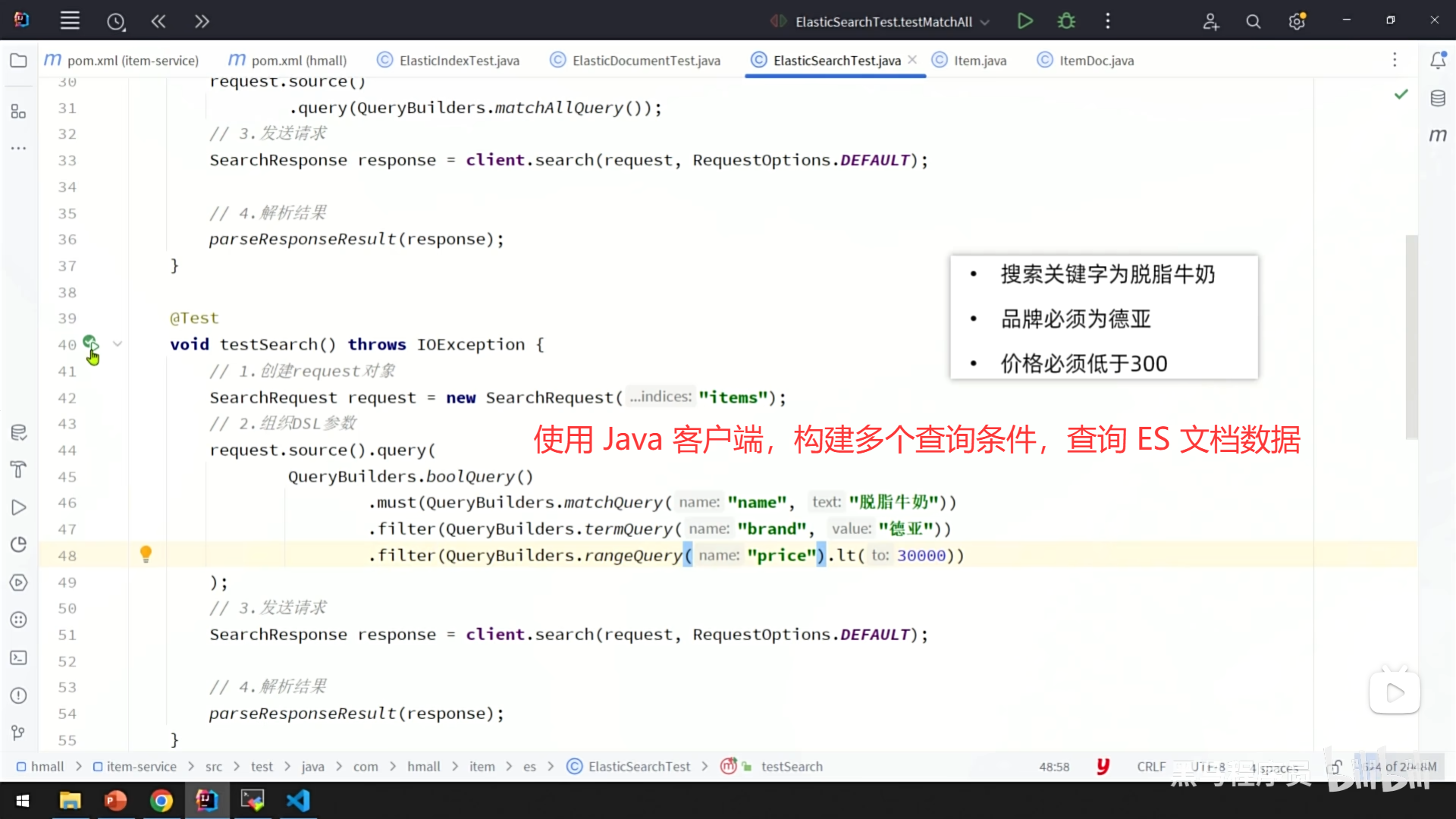
3、从索引库中查询文档数据
三、AI 回答
Elasticsearch 怎么用:Java 开发者的核心操作指南
Elasticsearch (ES) 是一个功能强大的分布式搜索和分析引擎。对于 Java 开发者而言,理解其核心概念并将其与熟悉的关系型数据库操作进行类比,是快速上手的关键。本文将抛开具体的代码细节,专注于阐述在 Java 开发中使用 Elasticsearch 的三个核心步骤,帮助你建立起清晰的操作思路。
核心概念类比
在开始之前,我们先建立一个简单的概念映射,这有助于理解后续的操作:
- Elasticsearch 索引 (Index) ≈ 关系型数据库的数据库 (Database)
- 映射 (Mapping) ≈ 关系型数据库的表结构 (Table Schema)
- 文档 (Document) ≈ 关系型数据库表中的一行记录 (Row)
- 查询 (Query) ≈ 关系型数据库的 SELECT 语句
步骤一:创建索引库并设置映射
这相当于在关系型数据库中"创建数据库并创建表"。在存入任何数据之前,我们首先需要定义数据的存储结构和规则。
-
创建索引 (Create Index)
首先,你需要在 Elasticsearch 中创建一个索引。这个索引就是你未来存储一类相似数据(例如:商品信息、用户日志、文章内容)的逻辑容器。你可以把它想象成在 MySQL 中执行
CREATE DATABASE my_shop;。 -
设置映射 (Define Mapping)
创建索引的同时或之后,你需要为这个索引定义"映射"。映射是 ES 中极其重要的一环,它明确地告诉 Elasticsearch:
- 你的数据包含哪些字段(例如:商品ID、名称、价格、上架时间)。
- 每个字段是什么数据类型(例如:文本、数字、日期、关键词)。
- 这些字段应该如何被处理(例如:文本字段是否需要分词以便全文搜索,关键词字段是否用于精确匹配和聚合)。
显式地定义映射是一个非常好的实践,它可以避免 Elasticsearch 的"动态映射"功能可能带来的数据类型误判,确保数据存储和搜索行为完全符合你的预期。这就像在设计数据库表时,你会明确定义
id是INT类型,name是VARCHAR类型一样。
步骤二:新增文档数据
这一步就相当于"给数据库表中新增数据"。当你定义好索引和映射后,就可以开始向其中添加数据了。
-
准备数据对象
在你的 Java 应用中,你会有一个或多个 Java 对象(POJO),比如一个
Product对象,它包含了id,name,price等属性。 -
序列化与索引
使用 Elasticsearch 的 Java 客户端,你将这个
Product对象发送给 ES 服务器。客户端会自动将这个 Java 对象转换(序列化)成 JSON 格式的文档。然后,你指定这个文档应该存入哪个索引,并可以为它指定一个唯一的 ID(类似于数据库的主键)。 -
存储完成
Elasticsearch 接收到这个 JSON 文档后,会根据你之前定义的映射规则,对数据进行解析和存储。如果指定的 ID 已经存在,ES 会执行更新操作;如果不存在,则执行创建操作。这个过程对你来说是透明且高效的。
步骤三:查询文档数据
这是数据应用中最核心的环节,相当于"从数据库中查询数据",但 Elasticsearch 的查询能力远比传统 SQL 的 SELECT 语句丰富和灵活。
-
构建查询请求
你需要告诉 Elasticsearch 你想找什么。通过 Java 客户端提供的类型安全的 DSL(领域专用语言),你可以像搭积木一样构建复杂的查询条件。例如:
- 全文搜索:查找商品名称或描述中包含"智能手机"的所有商品。
- 精确过滤:查找分类为"电子产品"且价格低于 5000 元的商品。
- 范围查询:查找上个月新上架的所有商品。
- 组合查询:将以上条件组合起来,实现更精细的筛选。
-
执行查询与处理结果
将构建好的查询请求发送给 Elasticsearch。ES 会迅速在其分布式索引中进行计算,并返回一个结果集。这个结果集通常包含:
- 总命中数:符合你查询条件的文档总数。
- 文档列表:实际匹配到的文档数据(即你的 Java 对象)。
- 其他信息:如相关性评分、聚合结果等。
最后,你的 Java 程序会接收这些 JSON 格式的结果,并由客户端自动转换(反序列化)回你的
Product对象列表,方便你进行后续的业务逻辑处理或在界面上展示。
通过这三个清晰的步骤------定义结构、添加数据、查询数据------你就掌握了在 Java 中使用 Elasticsearch 的核心流程。这种模式与操作关系型数据库的思路一脉相承,让你能够更平滑地过渡到 NoSQL 搜索技术的应用开发中。