文章目录
- [1. 概述](#1. 概述)
- [2. 实现](#2. 实现)
-
- [2.1 从一个例子开始](#2.1 从一个例子开始)
- [2.2 实现概要](#2.2 实现概要)
-
- [2.2.1 OOM-killer 触发流程](#2.2.1 OOM-killer 触发流程)
- [2.2.2 OOM-killer 的评分规则](#2.2.2 OOM-killer 的评分规则)
- [2.2.3 OOM-killer 内存回收过程](#2.2.3 OOM-killer 内存回收过程)
- [3. 小结](#3. 小结)
1. 概述
什么是 OOM-killer?简单来说,就是当系统内存严重不足时,按 OOM-killer 对进程的评分机制,选择分数最高的进程让其退出以释放内存,来满足系统对内存的紧急需求。
当然,系统也不会一上来就直接就采用 OOM-killer 这个终极杀招,在此之前,会经历内存回收(reclaim)、规整(compact),之后才轮到 OOM-killer;其次,OOM-killer 发送 SIGKILL 信号使进程退出。
当然,再怎么说,OOM-killer 仍然是一种暴力机制,强制进程终止可能造成重要数据的丢失。
OOM-killer 的评分机制主要考量进程的内存的使用量(RSS),后面将会进行分析。
2. 实现
2.1 从一个例子开始
既然 OOM-killer 终止进程的诱因是因为进程消耗了太多的内存,那就写一个只分配不释放的 oom_test.c 程序来测试一下。程序的第一版是这样的:
c
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
while (1) {
(void)malloc(1 * 1024 * 1024); // 每次分配 1MB
usleep(5 * 1000);
}
return 0;
}编译,然后在 QEMU 下运行[1](#1):
bash
root@qemu-ubuntu:~# ./oom_test等啊等,等了好久,始终没有看到系统强行终止 oom_test 程序,这是怎么回事?我们用下面的 run_oom_test.sh 脚本来观察一下:
bash
#!/bin/bash
if [ $# -ne 1 ]; then
echo "usage: $0 <count>"
exit 1
fi
./oom_test &
TEST_PID=$!
top -b -n $1 -p $TEST_PID
bash
root@qemu-ubuntu:~# ./run_oom_test.sh 50
top - 13:34:01 up 5 min, 1 user, load average: 0.07, 0.04, 0.01
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.5 us, 0.6 sy, 0.0 ni, 98.1 id, 0.6 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 510588 total, 474732 free, 9852 used, 26004 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 482984 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
955 root 20 0 35136 324 280 S 5.9 0.1 0:00.01 oom_test
top - 13:34:04 up 5 min, 1 user, load average: 0.14, 0.06, 0.01
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.1 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 510588 total, 472872 free, 11712 used, 26004 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 481124 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
955 root 20 0 356900 1960 628 S 4.6 0.4 0:00.15 oom_test
top - 13:34:07 up 5 min, 1 user, load average: 0.14, 0.06, 0.01
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.1 sy, 0.0 ni, 99.8 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 510588 total, 471012 free, 13564 used, 26012 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 479272 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
955 root 20 0 678664 3280 628 S 4.7 0.6 0:00.29 oom_test
[......]
top - 13:34:28 up 5 min, 1 user, load average: 0.44, 0.14, 0.04
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 510588 total, 462828 free, 21748 used, 26012 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 471088 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
955 root 20 0 2077772 8560 628 S 5.0 1.7 0:01.29 oom_test最后发现,进程的 VIRT,RES,SHR 都只会增长到一定数值后,就不再变化了,%MEM[2](#2) 显示进程消耗的(RES)内存约占系统物理总内存的 1.7%,而且 21748 used 昭示系统消耗的总内存也才仅仅 20MB 的样子。这是怎么回事?原因是 malloc() 请求分配的内存并不会马上兑现为物理内存,系统会先只为进程分配虚拟内存空间,然后在写入虚拟内存空间时才会分配物理页面,关于这方面的更多细节,以后有机会再和大家一起讨论,在这里就不做展开了,因为这不是本文的重点。
好了,言归正传,既然程序的第一版无法触发 OOM-killer,那我们改写测试程序 oom_test.c 的第二版,如下:
c
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main(void)
{
char *ptr;
while (1) {
ptr = malloc(1 * 1024 * 1024);
memset(ptr, 0, 1 * 1024 * 1024);
usleep(5 * 1000);
}
return 0;
}再次在 QEMU 测试环境下跑起来,没一会儿,oom_test 如我们预期的那样,被系统强行干掉了:

完整的 OOM-killer 内核日志如下:
bash
[ 48.184551] oom_test invoked oom-killer: gfp_mask=0x14200ca(GFP_HIGHUSER_MOVABLE), nodemask=(null), order=0, oom_score_adj=0
[ 48.184829] oom_test cpuset=/ mems_allowed=0
[ 48.185060] CPU: 3 PID: 967 Comm: oom_test Not tainted 4.14.111 #2
[ 48.185080] Hardware name: ARM-Versatile Express
[ 48.185526] [<8010f1a0>] (unwind_backtrace) from [<8010b494>] (show_stack+0x10/0x14)
[ 48.185578] [<8010b494>] (show_stack) from [<8066385c>] (dump_stack+0x84/0x98)
[ 48.185592] [<8066385c>] (dump_stack) from [<801e35dc>] (dump_header+0x98/0x1c0)
[ 48.185608] [<801e35dc>] (dump_header) from [<801e27f4>] (oom_kill_process+0x368/0x574)
[ 48.185618] [<801e27f4>] (oom_kill_process) from [<801e31b4>] (out_of_memory+0xec/0x430)
[ 48.185629] [<801e31b4>] (out_of_memory) from [<801e854c>] (__alloc_pages_nodemask+0xfdc/0x10f4)
[ 48.185640] [<801e854c>] (__alloc_pages_nodemask) from [<80210b74>] (handle_mm_fault+0x678/0x9c4)
[ 48.185651] [<80210b74>] (handle_mm_fault) from [<80113448>] (do_page_fault+0x2a0/0x37c)
[ 48.185661] [<80113448>] (do_page_fault) from [<80101324>] (do_DataAbort+0x38/0xb4)
[ 48.185669] [<80101324>] (do_DataAbort) from [<8010c45c>] (__dabt_usr+0x3c/0x40)
[ 48.185688] Exception stack(0x9ea45fb0 to 0x9ea45ff8)
[ 48.185777] 5fa0: 59396008 00000000 000bf000 593d7000
[ 48.185833] 5fc0: 7ea88748 00000000 00000000 00000000 00000000 00000000 76f83000 7ea8872c
[ 48.185872] 5fe0: 00000000 7ea88720 000104ac 76ec5e18 200e0010 ffffffff
[ 48.185913] Mem-Info:
[ 48.186013] active_anon:122409 inactive_anon:808 isolated_anon:0
active_file:30 inactive_file:63 isolated_file:0
unevictable:0 dirty:0 writeback:0 unstable:0
slab_reclaimable:770 slab_unreclaimable:1411
mapped:69 shmem:813 pagetables:315 bounce:0
free:700 free_pcp:0 free_cma:0
[ 48.186072] Node 0 active_anon:489636kB inactive_anon:3232kB active_file:120kB inactive_file:252kB unevictable:0kB isolated(anon):0kB isolated(file):0kB mapped:276kB dirty:0kB writeback:0kB shmem:3252kB writeback_tmp:0kB unstable:0kB all_unreclaimable? yes
[ 48.186162] Normal free:2800kB min:2852kB low:3564kB high:4276kB active_anon:489548kB inactive_anon:3232kB active_file:120kB inactive_file:68kB unevictable:0kB writepending:0kB present:524288kB managed:510588kB mlocked:0kB kernel_stack:584kB pagetables:1260kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB
[ 48.186167] lowmem_reserve[]: 0 0
[ 48.186198] Normal: 58*4kB (UME) 21*8kB (UME) 10*16kB (UME) 7*32kB (UME) 2*64kB (UE) 1*128kB (M) 1*256kB (M) 3*512kB (UME) 0*1024kB 0*2048kB 0*4096kB = 2832kB
[ 48.186340] 913 total pagecache pages
[ 48.186367] 0 pages in swap cache
[ 48.186376] Swap cache stats: add 0, delete 0, find 0/0
[ 48.186382] Free swap = 0kB
[ 48.186388] Total swap = 0kB
[ 48.186409] 131072 pages RAM
[ 48.186414] 0 pages HighMem/MovableOnly
[ 48.186418] 3425 pages reserved
[ 48.186425] 0 pages cma reserved
[ 48.186432] [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name
[ 48.186489] [ 786] 0 786 1687 83 6 0 0 0 systemd-journal
[ 48.186503] [ 814] 100 814 3063 46 7 0 0 0 systemd-timesyn
[ 48.186512] [ 846] 0 846 364 31 4 0 0 0 ondemand
[ 48.186521] [ 850] 0 850 340 12 4 0 0 0 sleep
[ 48.186531] [ 868] 0 868 993 150 4 0 0 0 dhclient
[ 48.186540] [ 883] 0 883 499 27 4 0 0 0 agetty
[ 48.186549] [ 884] 0 884 499 27 4 0 0 0 agetty
[ 48.186558] [ 885] 0 885 499 27 4 0 0 0 agetty
[ 48.186566] [ 886] 0 886 499 27 4 0 0 0 agetty
[ 48.186575] [ 887] 0 887 1114 101 6 0 0 0 login
[ 48.186583] [ 888] 0 888 499 27 4 0 0 0 agetty
[ 48.186592] [ 889] 0 889 1114 101 6 0 0 0 login
[ 48.186601] [ 941] 0 941 683 61 5 0 0 0 bash
[ 48.186610] [ 961] 0 961 690 88 5 0 0 0 bash
[ 48.186619] [ 967] 0 967 121864 121366 242 0 0 0 oom_test
[ 48.186633] Out of memory: Kill process 967 (oom_test) score 924 or sacrifice child
[ 48.187173] Killed process 967 (oom_test) total-vm:487456kB, anon-rss:485460kB, file-rss:4kB, shmem-rss:0kB日志详细列出了触发 OOM-killer 的调用栈,以及系统内存的使用状况、各进程(包括 oom_test 进程)的内存使用状况。系统总内存为 512MB,oom_test 一个人就占了约 476MB(487456kB),这显然到了系统能容忍的极限,只好召唤 OOM-killer 神器来降伏这头内存饕餮了。
2.2 实现概要
本文基于 Linux 4.14.111 内核进行分析。
2.2.1 OOM-killer 触发流程
现在已经有了一个 OOM-killer 的例子了,我们就以这个例子为起点,来简单的分析下 OOM-killer 实现的核心概要。上一小结 2.1 调用栈告诉我们,进程在写入没有分配物理页面的虚拟地址时,产生了 page fault,在调用 __alloc_pages_nodemask() 向 buddy 请求物理页面时,由于内存不足触发了 OOM-killer:
c
/*
* This is the 'heart' of the zoned buddy allocator.
*/
/* buddy 分配器核心,所有的分配接口最终都会进入此函数 */
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
...
/* First allocation attempt */
/*
* (1)
* 快速分配路径:
* 首先尝试从匹配分配条件的 NUMA node/zone 的当前空闲页面分配.
*/
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page)) /* 分配成功:当前空闲页面满足分配请求 */
goto out;
...
/*
* (2)
* 慢速分配路径:
* 从快速分配路径分配失败, 接下来可能要依次进行 内存回收、内存规整、OOM-killer,
* 来满足分配要求.
*/
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
...
return page; /* 返回分配的页面 */
}
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
...
/* Try direct reclaim and then allocating */
/*
* (2.1)
* 直接进行 同步内存回收(reclaim),并等待回收操作完成后,再次尝试分配。
* 这不同于唤醒 kswapd 的间接异步回收,时间上更为确定。
*/
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
/*
* (2.2)
* 尝试内存页面回收后(reclaim),分配页面仍旧失败,进行 内存规整(compact) 后再尝试分配。
*/
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
...
/* Reclaim has failed us, start killing things */
/*
* (2.3)
* 内存回收(reclaim)、内存规整(compact) 后分配仍然失败,触发 OOM-killer 再次尝试分配。
*/
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
...
}
static inline struct page *
__alloc_pages_may_oom(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac, unsigned long *did_some_progress)
{
...
/* Exhausted what can be done so it's blamo time */
/* 没辙了, 只得干掉进程来获取内存, 以满足分配要求了 */
if (out_of_memory(&oc) || WARN_ON_ONCE(gfp_mask & __GFP_NOFAIL)) {
*did_some_progress = 1;
/*
* Help non-failing allocations by giving them access to memory
* reserves
*/
/* 干掉进程都不够了, 以及触底了, 这时候就不管什么水位了, 预留内存都拿来用了 */
if (gfp_mask & __GFP_NOFAIL)
page = __alloc_pages_cpuset_fallback(gfp_mask, order,
ALLOC_NO_WATERMARKS, ac);
}
...
}最后,依次尝试了:
(2.1) 内存回收(reclaim)(2.2) 内存规整(compact)(即碎片整理)
都没法满足分配需求,接下来只能通过 out_of_memory() 终止进程来尝试满足分配需求了:
c
/**
* out_of_memory - kill the "best" process when we run out of memory
* @oc: pointer to struct oom_control
*
* If we run out of memory, we have the choice between either
* killing a random task (bad), letting the system crash (worse)
* OR try to be smart about which process to kill. Note that we
* don't have to be perfect here, we just have to be good.
*/
bool out_of_memory(struct oom_control *oc)
{
...
/*
* If current has a pending SIGKILL or is exiting, then automatically
* select it. The goal is to allow it to allocate so that it may
* quickly exit and free its memory.
*/
/*
* 碰碰运气, 看看是否刚好 当前进程 正要退出:
* - 进程异常退出, 自己崩了(coredump)
* - 进程在正常退出过程中
* 果真如此, 唤醒 oom_reaper() 内核线程回收 当前进程
* 的内存来满足分配需求, 不用做进一步的进程评分选择了.
*/
if (task_will_free_mem(current)) {
mark_oom_victim(current);
wake_oom_reaper(current);
return true; /* 异步回收当前进程内存, 然后返回 */
}
...
/* 检查看是不是在 oom 是要执行 panic (/proc/sys/vm/panic_on_oom) */
check_panic_on_oom(oc, constraint);
/*
* sysctl_oom_kill_allocating_task => /proc/sys/vm/oom_kill_allocating_task
* sysctl_oom_kill_allocating_task 为非 0 值, 直接终止当前分配内存的进程,
* 不做进一步评分对比了.
*
* sysctl_oom_kill_allocating_task 默认为 0 值.
*/
if (!is_memcg_oom(oc) && sysctl_oom_kill_allocating_task &&
current->mm && !oom_unkillable_task(current, NULL, oc->nodemask) &&
current->signal->oom_score_adj != OOM_SCORE_ADJ_MIN) {
get_task_struct(current);
oc->chosen = current;
oom_kill_process(oc, "Out of memory (oom_kill_allocating_task)");
return true;
}
select_bad_process(oc); /* 评分选出"最坏"的进程 */
/* Found nothing?!?! Either we hang forever, or we panic. */
/* 太难为人了, 大家都是一时瑜亮,实在选不出来, 系统只好崩溃罢工了 */
if (!oc->chosen && !is_sysrq_oom(oc) && !is_memcg_oom(oc)) {
dump_header(oc, NULL);
panic("Out of memory and no killable processes...\n");
}
if (oc->chosen && oc->chosen != (void *)-1UL) {
/* 终止选中的进程 oc->chosen */
oom_kill_process(oc, !is_memcg_oom(oc) ? "Out of memory" :
"Memory cgroup out of memory");
/*
* Give the killed process a good chance to exit before trying
* to allocate memory again.
*/
schedule_timeout_killable(1);
}
return !!oc->chosen; /* 返回 true 表示有选择终止进程, 反之则表示没有选择终止进程 */
}2.2.2 OOM-killer 的评分规则
看下 select_bad_process() 怎么评分选目标进程的:
c
static void select_bad_process(struct oom_control *oc)
{
if (is_memcg_oom(oc))
... // cgroup memcg 情形,读者自行研究吧
else {
struct task_struct *p;
rcu_read_lock();
/* 评估系统中所有进程(不包括进程内除 group leader 外的其它线程) */
for_each_process(p)
if (oom_evaluate_task(p, oc))
break;
rcu_read_unlock();
}
oc->chosen_points = oc->chosen_points * 1000 / oc->totalpages;
}
static int oom_evaluate_task(struct task_struct *task, void *arg)
{
struct oom_control *oc = arg;
unsigned long points;
if (oom_unkillable_task(task, NULL, oc->nodemask))
goto next;
/*
* This task already has access to memory reserves and is being killed.
* Don't allow any other task to have access to the reserves unless
* the task has MMF_OOM_SKIP because chances that it would release
* any memory is quite low.
*/
if (!is_sysrq_oom(oc) && tsk_is_oom_victim(task)) {
if (test_bit(MMF_OOM_SKIP, &task->signal->oom_mm->flags))
goto next;
goto abort;
}
/*
* If task is allocating a lot of memory and has been marked to be
* killed first if it triggers an oom, then select it.
*/
if (oom_task_origin(task)) {
points = ULONG_MAX;
goto select;
}
points = oom_badness(task, NULL, oc->nodemask, oc->totalpages);
if (!points || points < oc->chosen_points)
goto next;
/* Prefer thread group leaders for display purposes */
if (points == oc->chosen_points && thread_group_leader(oc->chosen))
goto next;
select:
if (oc->chosen)
put_task_struct(oc->chosen);
get_task_struct(task);
oc->chosen = task;
oc->chosen_points = points;
next:
return 0;
abort:
if (oc->chosen)
put_task_struct(oc->chosen);
oc->chosen = (void *)-1UL;
return 1;
}
unsigned long oom_badness(struct task_struct *p, struct mem_cgroup *memcg,
const nodemask_t *nodemask, unsigned long totalpages)
{
long points;
long adj;
/*
* 有些进程对 oom-killer 是免疫的:
* - 首进程 (PID == 1)、内核线程、其它情形
* - 内核线程
* - 其它情形
*/
if (oom_unkillable_task(p, memcg, nodemask))
return 0;
p = find_lock_task_mm(p);
if (!p)
return 0;
/*
* Do not even consider tasks which are explicitly marked oom
* unkillable or have been already oom reaped or the are in
* the middle of vfork
*/
/*
* /proc/<PID>/oom_score_adj 设为 -1000 的进程是对 oom-killer 免疫的.
* /proc/<PID>/oom_score_adj 值的范围是 [-1000, 1000], 值越大, 分越高,
* 越容易被 oom-killer 选中.
*/
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN ||
test_bit(MMF_OOM_SKIP, &p->mm->flags) ||
in_vfork(p)) {
task_unlock(p);
return 0;
}
/*
* The baseline for the badness score is the proportion of RAM that each
* task's rss, pagetable and swap space use.
*/
/* 内存使用量越多, 分越高 */
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +
atomic_long_read(&p->mm->nr_ptes) + mm_nr_pmds(p->mm);
task_unlock(p);
/*
* Root processes get 3% bonus, just like the __vm_enough_memory()
* implementation used by LSMs.
*/
/* root 权限进程会有轻微的保护, 减掉约 3% 的分数 */
if (has_capability_noaudit(p, CAP_SYS_ADMIN))
points -= (points * 3) / 100;
/* Normalize to oom_score_adj units */
adj *= totalpages / 1000;
points += adj;
/*
* Never return 0 for an eligible task regardless of the root bonus and
* oom_score_adj (oom_score_adj can't be OOM_SCORE_ADJ_MIN here).
*/
return points > 0 ? points : 1;
}从 select_bad_process() 的逻辑可以看到,主要有以下几种因素影响进程的评分:
- 内存使用量,越多分数越高
- /proc/PID/oom_score_adj 权重值,越大分越高,如果值为 -1000,则对 oom-killer 完全免疫
- root 权限进程可获得轻微减分
- 有些进程对 oom-killer 完全免疫:首进程(PID == 1)、内核线程、其它情形
- /proc/PID/oom_adj 已弃用, 对其写入会映射到 /proc/PID/oom_score_adj
注意,select_bad_process() 只评估了系统中所有的 group leader 进程,但不包括它们包含的线程,后续会在 oom_kill_process() 终止目标进程前,做进一步的评估。
2.2.3 OOM-killer 内存回收过程
最后,来看看 OOM-killer 终止进程、回收内存的过程:
c
static void oom_kill_process(struct oom_control *oc, const char *message)
{
struct task_struct *p = oc->chosen; /* 选中的进程 */
unsigned int points = oc->chosen_points;
struct task_struct *victim = p;
struct task_struct *child;
struct task_struct *t;
struct mm_struct *mm;
unsigned int victim_points = 0;
...
bool can_oom_reap = true;
...
/* 如果选中的进程刚好正在退出, 唤醒 oom_reaper() 回收进程内存资源即可 */
task_lock(p);
if (task_will_free_mem(p)) {
mark_oom_victim(p);
wake_oom_reaper(p); /* 唤醒 oom_reaper() 回收进程 @p 资源 */
task_unlock(p);
put_task_struct(p);
return; /* 返回 */
}
task_unlock(p);
...
pr_err("%s: Kill process %d (%s) score %u or sacrifice child\n",
message, task_pid_nr(p), p->comm, points);
read_lock(&tasklist_lock);
/*
* 如果 p 的子进程中有任何一个使用有不同的 mm, 则 oom_badness() 评分
* 最高的那个子进程将被牺牲,以换取其父进程的生存。此举旨在在释放内
* 存的同时,尽可能减少已完成的工作量。
*
* 为什么这样设计? 父进程可能包含 一组线程 和 一组子进程, 那么进程 p
* 的得分是由这些进程的内存消耗组成的, 那其中谁对得分贡献最高呢? 如果
* p 的 子进程 和 p 共享 mm, 那就不分彼此了, p 就代表了所有线程 和 子
* 进程 的得分, 无需再细究; 但如果有子进程有自己的 mm, 那它的得分贡献
* 就得评估一下了, 看是不是在 p 的 所有子进程 中最突出, 如果是, 那就
* 将它作为目标终止掉了.
*/
get_task_struct(p);
for_each_thread(p, t) {
list_for_each_entry(child, &t->children, sibling) {
unsigned int child_points;
if (process_shares_mm(child, p->mm))
continue;
/*
* oom_badness() returns 0 if the thread is unkillable
*/
child_points = oom_badness(child,
oc->memcg, oc->nodemask, oc->totalpages);
if (child_points > victim_points) { /* 如果是当前得分最高的子进程 @child, */
put_task_struct(victim);
victim = child; /* 子进程 @child 成为新目标 */
victim_points = child_points;
get_task_struct(victim);
}
}
}
put_task_struct(p);
read_unlock(&tasklist_lock);
p = find_lock_task_mm(victim);
if (!p) { /* 初始选定的目标进程 p 已经退出 */
put_task_struct(victim);
return; /* 直接返回 */
} else if (victim != p) { /* 新选定的 child 进程代替 p 进程被终止, 因为它对评分贡献最高 */
get_task_struct(p);
put_task_struct(victim);
victim = p;
}
/* Get a reference to safely compare mm after task_unlock(victim) */
mm = victim->mm;
mmgrab(mm);
...
/*
* We should send SIGKILL before granting access to memory reserves
* in order to prevent the OOM victim from depleting the memory
* reserves from the user space under its control.
*/
/* 给进程发 SIGKILL 信号, 给它机会自动退出, 尽量避免数据损失 */
do_send_sig_info(SIGKILL, SEND_SIG_FORCED, victim, true);
...
pr_err("Killed process %d (%s) total-vm:%lukB, anon-rss:%lukB, file-rss:%lukB, shmem-rss:%lukB\n",
task_pid_nr(victim), victim->comm, K(victim->mm->total_vm),
K(get_mm_counter(victim->mm, MM_ANONPAGES)),
K(get_mm_counter(victim->mm, MM_FILEPAGES)),
K(get_mm_counter(victim->mm, MM_SHMEMPAGES)));
task_unlock(victim);
/*
* 目标进程 mm 关联的内存要被回收了, 如果还有其它 thread group
* 内的其它进程也共享了目标进程的 mm, 意味着它们也无法再使用这
* 些内存, 自然也要被终止.
*/
rcu_read_lock();
for_each_process(p) {
/* 没有和目标进程 victim 共享 mm, 无需考量 */
if (!process_shares_mm(p, mm))
continue;
/* 和目标进程 victim 同 thread group 的进程在前面已经考察过了, 不必重复考量 */
if (same_thread_group(p, victim))
continue;
/* 首进程对 oom-killer 免疫 */
if (is_global_init(p)) {
can_oom_reap = false;
set_bit(MMF_OOM_SKIP, &mm->flags);
pr_info("oom killer %d (%s) has mm pinned by %d (%s)\n",
task_pid_nr(victim), victim->comm,
task_pid_nr(p), p->comm);
continue;
}
/*
* No use_mm() user needs to read from the userspace so we are
* ok to reap it.
*/
/* 内核线程没有 mm, 也即对 oom-killer 免疫, 无需考量 */
if (unlikely(p->flags & PF_KTHREAD))
continue;
/*
* 进程 @p 和 目标进程 @victim 共享了 mm, 需要被终止:
* 发送 SIGKILL 信号让其终止.
*/
do_send_sig_info(SIGKILL, SEND_SIG_FORCED, p, true);
}
rcu_read_unlock();
if (can_oom_reap)
wake_oom_reaper(victim); /* 唤醒 oom_reaper() 内核线程回收进程资源 */
mmdrop(mm);
put_task_struct(victim);
}从 out_of_memory() 开始,在整个 OOM-killer 回收内存的过程中,遇得到两大类场景:
两次遇到进程(正常或异常)正在退出的场景,这时候会通过wake_oom_reaper()直接唤醒oom_reaper内核线程直接回收退出进程的内存资源- 经过一些列评分然后选中要终止的目标进程的场景,最终唤醒
oom_reaper内核线程回收目标进程的内存资源。
这两类场景最后都殊途同归了:都唤醒了 oom_reaper 内核线程回收内存。oom_reaper 是 OOM-killer 内存回收过程的最后阶段,这里展开细节分析:
c
static void wake_oom_reaper(struct task_struct *tsk)
{
if (!oom_reaper_th)
return;
/* mm is already queued? */
if (test_and_set_bit(MMF_OOM_REAP_QUEUED, &tsk->signal->oom_mm->flags))
return;
get_task_struct(tsk);
spin_lock(&oom_reaper_lock);
tsk->oom_reaper_list = oom_reaper_list;
oom_reaper_list = tsk;
spin_unlock(&oom_reaper_lock);
trace_wake_reaper(tsk->pid);
wake_up(&oom_reaper_wait); /* 唤醒 oom_reaper() 内核线程回收进程 @tsk 的资源(内存等) */
}
static int oom_reaper(void *unused)
{
while (true) {
struct task_struct *tsk = NULL;
wait_event_freezable(oom_reaper_wait, oom_reaper_list != NULL);
spin_lock(&oom_reaper_lock);
if (oom_reaper_list != NULL) {
tsk = oom_reaper_list;
oom_reaper_list = tsk->oom_reaper_list;
}
spin_unlock(&oom_reaper_lock);
if (tsk)
oom_reap_task(tsk); /* 回收进程 @tsk 的资源(内存等) */
}
return 0;
}
#define MAX_OOM_REAP_RETRIES 10
static void oom_reap_task(struct task_struct *tsk)
{
int attempts = 0;
struct mm_struct *mm = tsk->signal->oom_mm;
/* Retry the down_read_trylock(mmap_sem) a few times */
/* 回收进程的内存资源 */
while (attempts++ < MAX_OOM_REAP_RETRIES && !oom_reap_task_mm(tsk, mm))
schedule_timeout_idle(HZ/10);
if (attempts <= MAX_OOM_REAP_RETRIES) /* 成功回收 */
goto done;
/* 回收失败 */
pr_info("oom_reaper: unable to reap pid:%d (%s)\n",
task_pid_nr(tsk), tsk->comm);
...
done:
tsk->oom_reaper_list = NULL;
/*
* Hide this mm from OOM killer because it has been either reaped or
* somebody can't call up_write(mmap_sem).
*/
set_bit(MMF_OOM_SKIP, &mm->flags);
/* Drop a reference taken by wake_oom_reaper */
put_task_struct(tsk);
}
static bool oom_reap_task_mm(struct task_struct *tsk, struct mm_struct *mm)
{
bool ret = true;
mutex_lock(&oom_lock);
if (!down_read_trylock(&mm->mmap_sem)) {
ret = false;
...
goto unlock_oom;
}
...
if (test_bit(MMF_OOM_SKIP, &mm->flags)) {
up_read(&mm->mmap_sem);
...
goto unlock_oom;
}
...
/* 回收 mm 管理/映射 的 物理内存 */
__oom_reap_task_mm(mm);
pr_info("oom_reaper: reaped process %d (%s), now anon-rss:%lukB, file-rss:%lukB, shmem-rss:%lukB\n",
task_pid_nr(tsk), tsk->comm,
K(get_mm_counter(mm, MM_ANONPAGES)),
K(get_mm_counter(mm, MM_FILEPAGES)),
K(get_mm_counter(mm, MM_SHMEMPAGES)));
up_read(&mm->mmap_sem);
...
unlock_oom:
mutex_unlock(&oom_lock);
return ret;
}
void __oom_reap_task_mm(struct mm_struct *mm)
{
struct vm_area_struct *vma;
/*
* Tell all users of get_user/copy_from_user etc... that the content
* is no longer stable. No barriers really needed because unmapping
* should imply barriers already and the reader would hit a page fault
* if it stumbled over a reaped memory.
*/
set_bit(MMF_UNSTABLE, &mm->flags);
/* 释放所有 vma 映射的物理内存 */
for (vma = mm->mmap ; vma; vma = vma->vm_next) {
if (!can_madv_dontneed_vma(vma))
continue;
/*
* Only anonymous pages have a good chance to be dropped
* without additional steps which we cannot afford as we
* are OOM already.
*
* We do not even care about fs backed pages because all
* which are reclaimable have already been reclaimed and
* we do not want to block exit_mmap by keeping mm ref
* count elevated without a good reason.
*/
if (vma_is_anonymous(vma) || !(vma->vm_flags & VM_SHARED)) {
struct mmu_gather tlb;
tlb_gather_mmu(&tlb, mm, vma->vm_start, vma->vm_end);
unmap_page_range(&tlb, vma, vma->vm_start, vma->vm_end,
NULL); /* 通过取消虚拟地址区间的页表映射, 来释放物理页面 */
tlb_finish_mmu(&tlb, vma->vm_start, vma->vm_end);
}
}
}到此,OOM-killer 回收内存的过程结束。
3. 小结
用一副流程图来小结下 OOM-killer 回收内存的过程:
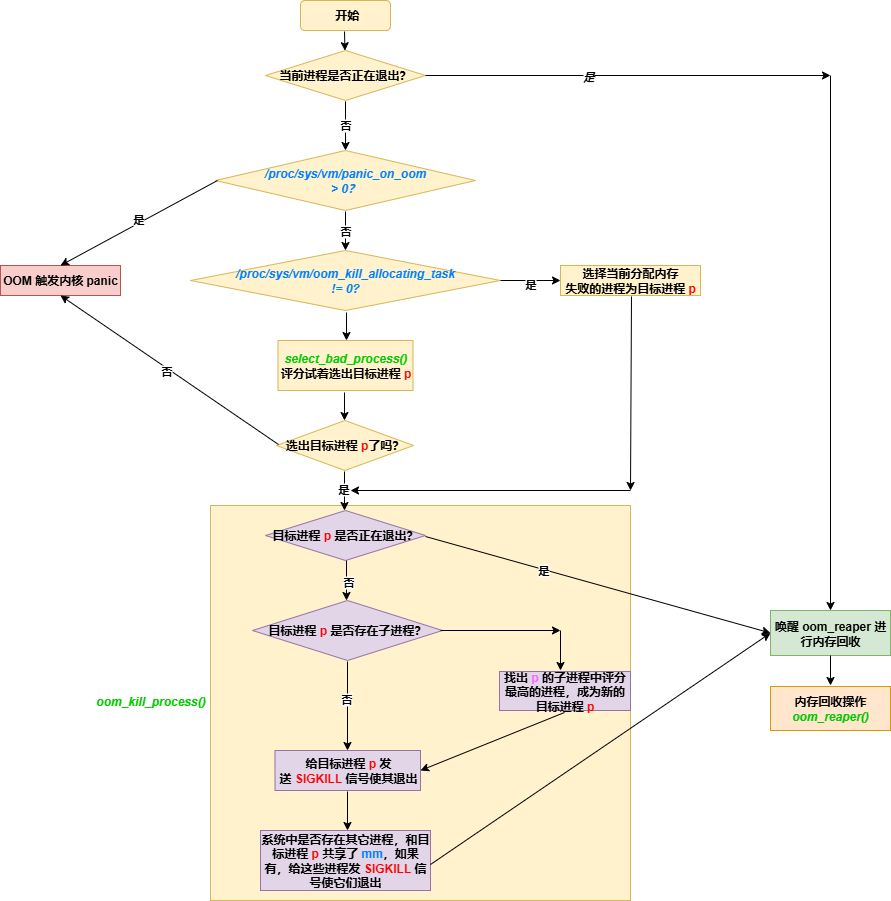
上图中,没有涉及 memcg 的细节,另外,对于 /proc/sys/vm/oom_kill_allocating_task 的描述不精确,细节可参考函数 check_panic_on_oom()。