目录
[一. 什么是内核链表](#一. 什么是内核链表)
[1.1 内核链表的本质:](#1.1 内核链表的本质:)
[1.2 内核链表的优点](#1.2 内核链表的优点)
[二. 内核链表的相关函数与宏](#二. 内核链表的相关函数与宏)
[2.1 节点的声明](#2.1 节点的声明)
[2.2 头节点的初始化](#2.2 头节点的初始化)
[2.3 链表的插入函数](#2.3 链表的插入函数)
[2.4 链表的删除函数](#2.4 链表的删除函数)
[2.5 链表的遍历方法](#2.5 链表的遍历方法)
[2.6 容器宏(container_of)](#2.6 容器宏(container_of))
[三. 思考](#三. 思考)
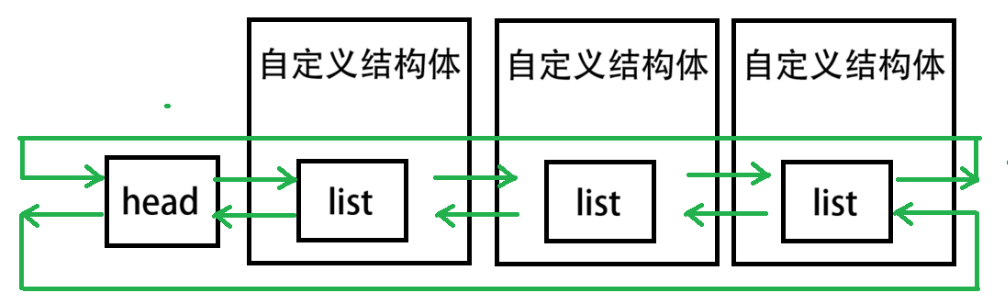
一. 什么是内核链表
1.1 内核链表的本质:
双向循环、带头节点的链表

1.2 内核链表的优点
不将数据存储在链表结点中,而是将结点嵌入到要存储的数据中。
该链表可以用来存储任意类型的数据,增强代码的复用性。
注:自定义结构体不嵌入头节点(本文称这个自定义结构体为宿主结构体)
二. 内核链表的相关函数与宏
2.1 节点的声明
内核链表的定义在头文件 <types,h> 中:
cpp
struct list_head {
struct list_head *next, *prev;//下一个节点指针,上一个节点指针
};2.2 头节点的初始化
内核链表头节点的初始化:
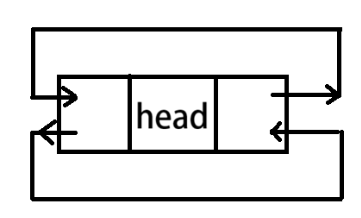
1、方法一:由两个宏来完成:
cpp
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)2、方法二:由函数完成:
cpp
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}3、二者的区别:
|---------------------------------|-----------------------------------------|
| LIST_HEAD 宏 | INIT_LIST_HEAD 函数 |
| 只需要传入一个变量名即可,宏在编译期间完成声明+初始化 | 需要传一个类型为 struct list_head的指针,来完成初始化 |
4、WRITE_ONCE的作用:
保证 CPU 每次都从内存重新读取变量的值,而不是用寄存器中暂存的值(与volatile类似)
2.3 链表的插入函数
1、链表核心插入函数:
cpp
//核心插入函数
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
cpp
if (!__list_add_valid(new, prev, next))
return;这条语句的作用: 进行各种出错检查,比如:
检查new、prev、next 是否为 NULL
检查new 是否已经在一个链表中
检查prev->next 是否真的等于 next(确保 prev 和 next 是相邻的)
检查new 是否等于 prev 或 next(防止自插入)等其他错误情况
2、链表的头插与尾插:
cpp
//头插
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
//尾插
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}2.4 链表的删除函数
1、链表的核心删除函数:
将prev与next这两个节点连接起来,绕过中间节点
cpp
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}2、不同功能的删除函数:
cpp
//删除entry并且将这个节点的prev指针置空
static inline void __list_del_clearprev(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->prev = NULL;
}
//带调试检查的删除
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
//删除节点并且毒化其prev与next指针
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}毒化指针的目的: 一旦代码错误地通过这样的节点进行链表操作(如 list_del 已经删除过的节点,或访问 next/prev 字段),会因访问非法地址而触发错误。
2.5 链表的遍历方法
四个遍历宏:
cpp
struct list_head *pos;//pos为内核链表指针类型
//前两个是普通遍历,后两个为安全遍历
//从头向尾遍历
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
//从尾向头遍历
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); pos = pos->prev)
//安全的正向遍历
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
//安全的反向遍历
#define list_for_each_prev_safe(pos, n, head) \
for (pos = (head)->prev, n = pos->prev; \
pos != (head); \
pos = n, n = pos->prev)安全性说明:
cpp
struct list_head *pos, *n;
for (pos = (head)->next, n = pos->next;
pos != (head);
pos = n, n = pos->next)
{
// 可以安全地执行 list_del(pos);
}2.6 容器宏(container_of)
核心思想: 从 list_head 成员指针反推出整个结构体指针
cpp
//获取偏移量
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
//容器宏
//ptr->指向member的指针
//type->宿主结构体类型
//member->内核链表节点在结构体中的名字
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \
!__same_type(*(ptr), void), \
"pointer type mismatch in container_of()"); \
((type *)(__mptr - offsetof(type, member))); })先看 offset 这个宏的作用:
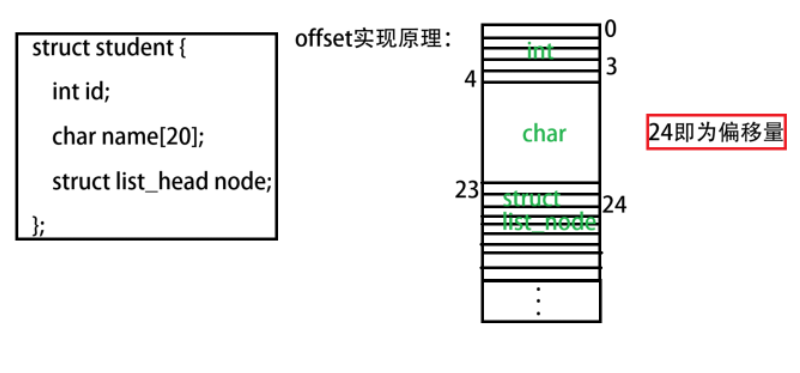
container_of 作用:
这个宏可以简化理解为:
cpp
#define container_of(ptr, type, member) \
((type *)((char*)ptr - offsetof(type, member)))先获取宿主结构体中 struct list_head 这个成员的地址,然后强转成char* 类型,对其减去偏移量,即可得到宿主结构体的地址。
在学习了这个宏之后,又可以得到另一种遍历方式:每次遍历获取得到宿主结构体,对宿主结构体
进行遍历
cpp
//ptr:宿主结构体中指向member的指针
//type:宿主结构体类型
//member:宿主结构体中 struct list_head 的成员名
//pos:宿主结构体指针
//获取存放ptr指向的member的宿主结构体的地址
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
//判断循环链表是否结束
#define list_entry_is_head(pos, head, member) \
(&pos->member == (head))
//获取第一个宿主结构体的地址
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
//获取下一个宿主结构体的地址
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
//遍历所有宿主结构体
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_next_entry(pos, member))typeof的作用: 通常用于**编写类型安全的宏,**它允许宏根据传入参数的类型来声明临时变量
传参时注意事项:
1、这里一层一层分析,最终得到了 list_for_each_entry这个宏应该传入什么参数
2、由下面的分析过程可知:list_for_each_entry 这个宏的作用就是在遍历内核链表上的宿主结构体,要想从头节点开始遍历,就要传入内核链表的头节点指针; 要想保存每一次遍历的宿主结构体,就要传入一个宿主结构体指针 ;最后,由于这个宏里面又使用了container_of这个宏,就必须传入在宿主结构体中声明的内核链表名称是什么。



示例代码:
头文件:
cpp
#ifndef _KERNEL_LIST_H
#define _KERNEL_LIST_H
struct list_head{
struct list_head *next;
struct list_head *prev;
};
//获取存储数据的结构体的首地址
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) \
((type *)((char*)ptr - offsetof(type, member)))
//遍历内核链表--遍历链表节点
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
//获取存放ptr指向的member的宿主结构体的地址
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
//判断循环链表是否结束
#define list_entry_is_head(pos, head, member) \
(&((pos)->member) == (head))
//获取第一个宿主结构体的地址
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
//获取下一个宿主结构体的地址
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
//遍历所有宿主结构体--这里是对宿主结构体进行遍历
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_next_entry(pos, member))
//初始化头节点--内核链表:带头循环双链表
//
//编译时宏
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
//运行时函数,初始化
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
//插入节点
static inline void __list_add(struct list_head *new,struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
//头插
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
#endif源文件:
cpp
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include"kernel_list.h"
#define NAMESIZE 20
typedef struct stu{
char name[NAMESIZE];
int id;
int math;
int chinese;
struct list_head node;
}stu;
//打印数据
void print(stu *pdata)
{
printf("name:%s\tid:%d\tmath:%d\tchinese:%d\n",pdata->name,pdata->id,
pdata->math,pdata->chinese);
}
int main()
{
srand(time(NULL));
stu *pdata;
//初始化头节点
LIST_HEAD(head);
int i = 0;
for(i = 0; i < 7; i++){
pdata = malloc(sizeof(stu));
if(pdata == NULL){
printf("malloc error\n");
exit(1);
}
pdata->id = i;
pdata->math = rand() % 100 + 1;
pdata->chinese = rand() % 100 + 1;
snprintf(pdata->name, NAMESIZE, "stu:%d",i);
//pdata->node.next = NULL;
//pdata->node.prev = NULL;
INIT_LIST_HEAD(&pdata->node);//使用函数初始化
//头插
list_add(&pdata->node, &head);
}
//遍历--遍历内核链表
/* struct list_head *cur = NULL;
list_for_each(cur, &head){
pdata = container_of(cur, struct stu, node);
printf("%s\n",pdata->name);
print(pdata);
}*/
//遍历--遍历宿主结构体
stu *pos = NULL;
list_for_each_entry(pos, &head, node)
print(pos);
return 0;
}结果:
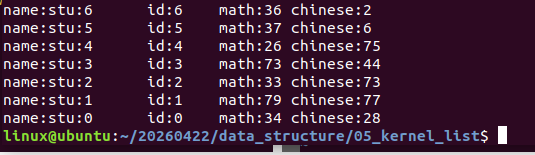
三. 思考
在查看内核链表源码时,发现类似下面的函数即被static修饰,又被inline修饰,有什么用?
1、inline:
inline (内联)是一个优化建议 ,指示编译器尝试将函数的代码直接嵌入到每个调用点,而不是生成一次函数体并通过 call 指令跳转。其优点:
消除函数调用开销:省去压栈、跳转、返回等指令。
提高指令缓存局部性:小函数展开后,调用处的代码更紧凑。
允许更多优化:编译器可以基于调用上下文进一步优化(如常量传播)。
但 inline 不强制内联,具体实现还得看编译器,类似关键字register
2、static:
static修饰的函数失去了外部链接属性
那这里static修饰的函数还可以被外部使用吗?注意,这里函数定义在头文件中,当.c文件包含此头文件时,在编译时展开头文件,相当该源文件独自拥有了这样一个函数,这样的作用是当多个 .c 文件包含同一个头文件时,不会出现"重复定义"错误
3、将而二者结合使用的优点:
将两者结合,产生一个可在头文件中安全定义、作用域私有、且适合内联优化的小函数。具体表现为:
-
无链接冲突:每个编译单元拥有自己的副本,不会出现符号重复定义。
-
高效执行:多数情况下函数会被内联展开,性能等同于宏,但比宏更安全(类型检查、副作用评估正常)。
-
代码可读性:用函数封装,参数和返回值清晰,避免宏的括号陷阱和多次求值问题。