一、docker 监控方向
1.1 运维核心职能与监控体系定位
1.1.1 运维核心关注维度
业务连续性保障:确保项目正常运行、健康度、高并发抗压能力及故障快速恢复能力。
成本与效率优化:在保障业务稳定的前提下,尽可能节省资源、降低成本。
1.1.2 运维三大核心体系
监控体系(眼睛):负责观测、判断、告警与可视化,实现故障的实时发现与预警。
日志体系(记录):负责记录与回溯,通过可视化手段辅助根因分析。
分布式追踪链(链路):追踪数据流向与业务逻辑,实现微服务架构下的全链路监控。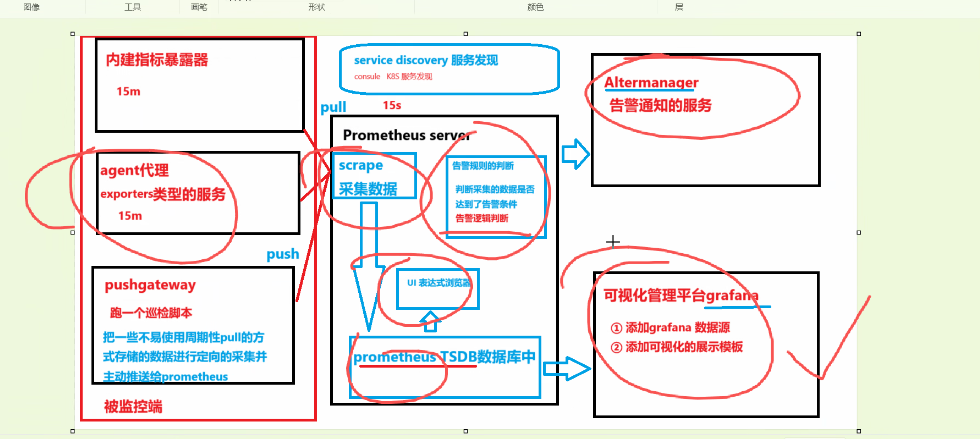
1.2 监控体系选 型与 Prometheus 优势
1.2.1 主流监控产品对比
Zabbix: 老牌全能型监控,覆盖网络、硬件、系统及应用服务,但对容器生态支持相对滞后。
**Prometheus:**专为容器和云原生设计,与 Kubernetes 生态结合紧密,是目前容器监控领域的事实标准。
1.2.2 Prometheus 的技术选型依据
容器化趋势:当前项目普遍基于 Docker 容器起步,Prometheus 天然适配容器环境。
K8s 生态协同:Prometheus 与 Kubernetes 同源于 Google 的 Borg 系统,两者结合无需复杂配置,生态成熟度高。
多维监控策略:大型企业通常采用混合监控策略(如 Zabbix + Prometheus),以覆盖不同层面的监控需求。
1.3 时序数据模型与核心概念
针对监控数据的本质,会议从数据定义、存储结构及查询逻辑三个维度进行了拆解:
1.3.1 时序数据定义与特征
数据本质:时序数据是按固定时间周期(如每秒、每分钟)采集的一系列数据点,通过串联形成趋势图,典型场景包括心电图、股票K线图及监控大屏。
采集逻辑:数据采集基于预设的时间周期(如15分钟或5分钟),在持续的时间段内(如5小时)记录每个时间刻度的数值,最终展示为数据变化趋势。
1.3.2 数据存储与查询结构
存储格式:Prometheus 作为时序数据库(TSDB),存储格式为"指标 + 标签 + 时间戳 + 样本值",其中标签用于在汇总数据中进行筛选。
查询语法:使用 PromQL 语句进行数据查询,通过指标名称结合标签筛选器(如 `instance="192.168.1.129"`)来定位特定维度的数据。
1.4 监控体系核心术语解析
1.4.1 数据实体与对象
指标与样本: 指标名称(Metric Name)定义了监控项(如 `cpu_usage`),样本数据(Sample Data)是指标在特定时间点的具体数值。
实例与对象:实例(Instance)或指标对象(Target)均指代被监控端,如服务器IP地址或MySQL服务端点。
1.4.2 数据采集与分类
指标暴露器:负责采集、格式化并暴露数据的组件,分为内建(如cAdvisor)、代理(Exporters)及Push Gateway(需手动推送)三种类型。
查询数据类型:分为即时向量(Instant Vector,单一时间点数据)和区间向量(Range Vector,指定时间范围内的数据)。
1.5 系统架构与工作流
1.5.1 混合数据采集模式
Pull 模式 :针对内建指标暴露器和Exporters,Prometheus Server 通过 Scraper 组件主动拉取(Pull)数据。
**Push 模式:**针对短期任务或无法拉取的场景,通过 Push Gateway 接收被监控端主动推送(Push)的数据。
1.5.2.组件职责与告警链路
核心组件分工:Prometheus Server 负责数据采集、存储及告警规则判断;Grafana 负责数据可视化;Alertmanager 负责告警通知分发。
告警逻辑:Prometheus 只负责判断数据是否达到告警条件,具体的通知动作(如发邮件、钉钉)由 Alertmanager 独立完成。
二、监控部分实例
2.1 可观测性与云原生监控体系
2.1.1 三大核心支柱定义
指标(Metrics) :用于观测系统运行状态的量化数据,如CPU使用率、内存占用等,侧重于趋势分析与告警。
日志(Logs) :记录系统中发生的事件详情,提供可回溯的历史记录,常用于故障排查与分析。
链路追踪(Tracing/Tracking):追踪请求在分布式系统中的流转路径,展示请求经过的具体接口或URL位置,用于性能瓶颈定位。
2.2.2 云原生与传统环境差异
技术底座差异:传统环境基于Linux操作系统,聚焦Web、LB、数据库等;云原生环境基于容器与虚拟化(如K8s、OpenStack),资源池化程度更高。
组件生态演变:云原生环境下,日志收集倾向于使用Loki替代ELK/EFK;链路追踪常用Jaeger、Zipkin、SkyWalking等组件。
2.2 Prometheus核心架构与原理
2.2.1 系统架构与职责划分
数据采集与存储:Prometheus Server 负责通过Pull模式抓取数据,并存储在TSDB(时序数据库)中。
告警与可视化:Alertmanager 负责告警通知(如微信、钉钉),Grafana负责多维度数据可视化展示。
特殊场景处理:Pushgateway用于接收短生命周期任务(如脚本、批处理任务)主动推送的数据,解决Pull模式无法覆盖的场景。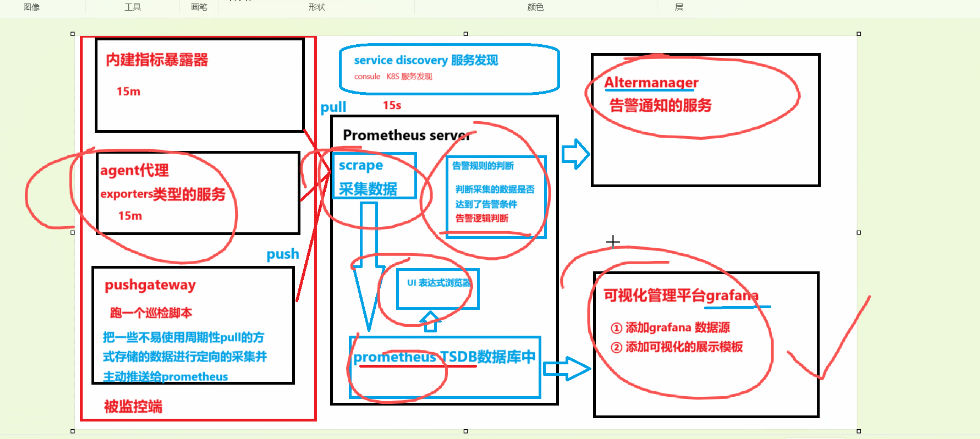
2.2.2 数据模型与查询机制
时序数据存储:数据以"指标名称+标签集+时间戳+样本值"的结构存储在TSDB中,支持高效的时间序列查询。
查询语言(PromQL):支持瞬时向量(Instant Vector)和区间向量(Range Vector)查询,通过指标名和标签筛选定位具体数据。
2.3 Prometheus实战部署与配置
2.3.1 服务端部署与启动
二进制部署流程:解压安装包至`/usr/local`目录,修改启动脚本路径后,直接执行`./prometheus`启动服务,监听9090端口。
配置文件结构:`prometheus.yml`包含全局配置(抓取间隔、告警规则重载间隔)、告警规则文件路径及抓取任务配置。
2.3.2 数据采集配置验证
默认自监控:启动后默认抓取本地`localhost:9090/metrics`端点数据,可通过表达式浏览器查看基础指标。
抓取任务定义:Scrape配置中定义了Job名称(如prometheus)及静态目标(targets),结合全局抓取间隔实现周期性数据拉取。
2.4 Node Exporter数据采集实战
2.4.1 组件部署与启动
多节点部署:将Node Exporte r二进制文件分发至各被监控节点(129、130、131),移动至`/usr/local/bin`并配置为系统服务启动。
端口冲突规避:Node Exporter默认占用9100端口,需注意与ELK中ES Head插件(同端口)的冲突问题。
2.4.2 数据暴露验证
指标端点访问:通过访问`http://IP:9100/metrics\`可查看节点系统指标(CPU、内存、磁盘等)。
防火墙配置:确保被监控节点的防火墙已关闭,否则Prometheus无法拉取数据。
2.5 Prometheus 多节点监控配置与原理
2.5.1 静态配置与多节点采集
配置文件修改:在 `prometheus.yml` 中新增 `job_name` 为 `nodes` 的静态配置,指定了三个目标节点的 IP 地址(110.129, 110.130, 110.131),并强调了 YAML 缩进格式的准确性。
数据源验证:配置完成后重启服务,通过 `Status` 页面确认三个节点的数据均被成功采集,状态显示为 `UP`。
2.5.2 偏移采集机制(Scrape Offset)
时间偏移现象:虽然配置文件中定义了 15 秒的采集间隔,但实际采集时间(Last Scrape)显示为 5 秒、6 秒和 11 秒,存在明显差异。
错峰采集原理:Prometheus 为避免在高并发场景下(如数百个节点同时上报)对自身造成瞬时压力,会自动在设定的采集时间点(如 15 秒)前后进行偏移,实现错峰数据下载。
2.6 Grafana 可视化展示集成
2.6.1 数据源配置与模板导入
多数据源支持:Grafana 被定义为独立的强大服务,支持对接 Prometheus、OpenTSDB、InfluxDB、Elasticsearch 等多种数据源。
模板导入方式:推荐使用 `Import` 功能,通过输入模板 ID(如 1860, 12486)或上传 JSON 文件的方式快速导入预设的监控面板。
2.6.2 企业级可视化实践
交互式筛选:演示了企业环境中通过点击节点名称或图表参数(如 CPU 模式切换)来过滤和查看特定维度的数据。
展示效果优化:指出可视化界面应避免过度堆砌导致信息过载,建议通过合理的交互设计提升可读性。
总结
bash
docker 作为工具使用了
监控体系 核心定位和作用
elk 基础架构 --》迭代进阶补强 elfk (filebeat 采集文件的 Fluentd 容器日志采集)
elkf + kafka 集群(MQ)
监控体系:专业属于搞清楚就可以了
监控基本职能:
1、数据观测与采集
2、数据存储、查询
3、监控数据的可视化
4、告警通知(判断是否需要告警 + 告警信息通知给管理人员)
监控体系有这么几个市场使用率比较高的产品:
1、zabbix 老牌的监控产品 (网络、硬件、系统、应用服务、容器等等方向的监控)
⭐⭐2、prometheus 擅长的是容器及容器相关技术体系的监控,比如⭐k8s、docker swarm、apache messos
3、夜莺监控(前身小米开发的)
4、云监控产品ARMS(阿里云)
prometheus 专业术语
① 数据类型:时序数据(按照指定时间周期(1s)采集每个时间节点的数据)
② 时序数据库:prometheus(本身就是一个 TSDB 时序数据库)
存储数据的方式如下:
Prometheus 存:
┌──────────────────────────────────────┬───────┬───────┐
│ 指标 + 标签 │ 时间戳 │ 值 │
├──────────────────────────────────────┼───────┼───────┤
│ cpu_usage{host="web01",mode="idle"} │ 10:00 │ 85 │
│ cpu_usage{host="web01",mode="idle"} │ 10:01 │ 82 │
│ cpu_usage{host="web01",mode="idle"} │ 10:02 │ 90 │
│ cpu_usage{host="web02",mode="idle"} │ 10:00 │ 70 │
└──────────────────────────────────────┴───────┴───────┘
③ 时序数据的表达/查询方式(prometheus 的查询语法:⭐PromQL语句)
cpu_usage{instance="192.168.110.129",core='0',mode='idle'}[10:00] 85
1)cpu_usage : cpu使用率(指标名称)
2)instance:第一个标签名
3)"192.168.110.129":第一个标签值,以此类推
4)85: 样本值
④ 实例/指标对象 :都指的是被监控端
⑤ 查询数据的表示类型:
即时向量数据/瞬时数据
区间向量数据/区间数据
⑥ 采集并暴露数据的对象:指标暴露器
prometheus 指标暴露器通常有3种:
1)第一种是服务自带的,例如 cadvisor
2)第二种是需要安装的agent代理:exporters 这类专门用于采集、格式化、暴露的服务
3) 第三种是运维/开发人员自己写的代码/脚本任务
#访问http://192.168.110.129:9090/metrics 指标暴露器的数据
prometheus_http_requests_total{code="200",handler="/graph"} 1
docker run -d \
--name prometheus \
-p 9090:9090 \
-v /opt/prom_config/prometheus.yml:/etc/prometheus/prometheus.yml \
-v prometheus-data:/prometheus \
prom/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/prometheus
双休日作业:
1、docker-compose 管理的elkf 做完
2、docker-compose 若依的问题收尾
3、容器化改造,完成nginx 容器的监控、并且能够在grafana中展示出来 (监控ruoyi前端的数据) (docker容器化nginx里面跑一个export,
4、整理本周内容
先把prometheus 传统部署跑通(exporter --》prometheus server scrape ---》ui 表达式浏览器中看到targets ---》
grafana展示出来(建立图表模板))
容器化"改造" :
nginx 容器改造的时候建议:
1、考虑好用什么镜像(不一定直接用:nginx:1.25.3)
2、建议先在传统环境中,把nginx 安装好 exporter安装好,确认prometheus能采集到nginx-exporter的数据