目录
[一、Attention 计算](#一、Attention 计算)
[Attention 计算详解](#Attention 计算详解)
[1. Mask 的核心作用](#1. Mask 的核心作用)
[2. 两种主要的 Mask 类型](#2. 两种主要的 Mask 类型)
[1. Padding Mask](#1. Padding Mask)
[2.Causal Mask(因果掩码 / Look-Ahead Mask)](#2.Causal Mask(因果掩码 / Look-Ahead Mask))
[二、KV cache 步骤](#二、KV cache 步骤)
[KV cache 显存计算](#KV cache 显存计算)
[三、减少KV cache](#三、减少KV cache)
[1. 为什么减少KV cache?](#1. 为什么减少KV cache?)
[1.1 更长的上下文](#1.1 更长的上下文)
[1.2 提升推理效率](#1.2 提升推理效率)
[2. MHA(multi-Head Attention)](#2. MHA(multi-Head Attention))
[3. MQA(Multi-Query Attention)](#3. MQA(Multi-Query Attention))
[4. GQA(Grouped-Query Attention)](#4. GQA(Grouped-Query Attention))
[1. Q:为什么GQA在70B大模型上的优势比7B更明显?](#1. Q:为什么GQA在70B大模型上的优势比7B更明显?)
[2. Q:如何验证某层是否适合改用GQA?](#2. Q:如何验证某层是否适合改用GQA?)
[2.1 理论依据:为什么注意力熵与GQA相关?](#2.1 理论依据:为什么注意力熵与GQA相关?)
[2.2 如何计算注意力熵?](#2.2 如何计算注意力熵?)
[2.3 阈值设定(如 < 3.5)的合理性](#2.3 阈值设定(如 < 3.5)的合理性)
一、Attention 计算
Attention 计算详解
对于 decode only 的 Transformer 架构,我们给一个输入文本,模型会输出一个回答(长度为 N),每一步根据之前 token 生成下一个 token,也就是每次推理只输出一个 token,输出的 token 会与输入 token 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终止符。
在没有KV Cache的情况下,其计算过程如下所示:
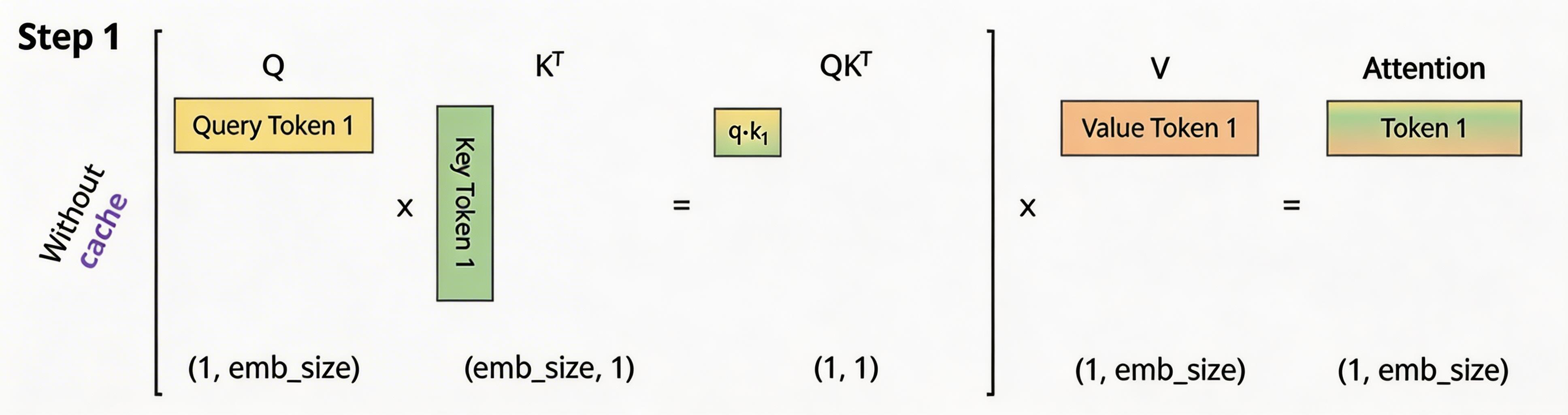
正常情况下,Attention计算公式:
为了看上去方便,我们暂时忽略scale项,因此,Attention的计算公式如下所示(softmaxed 表示已经按行进行了softmax):
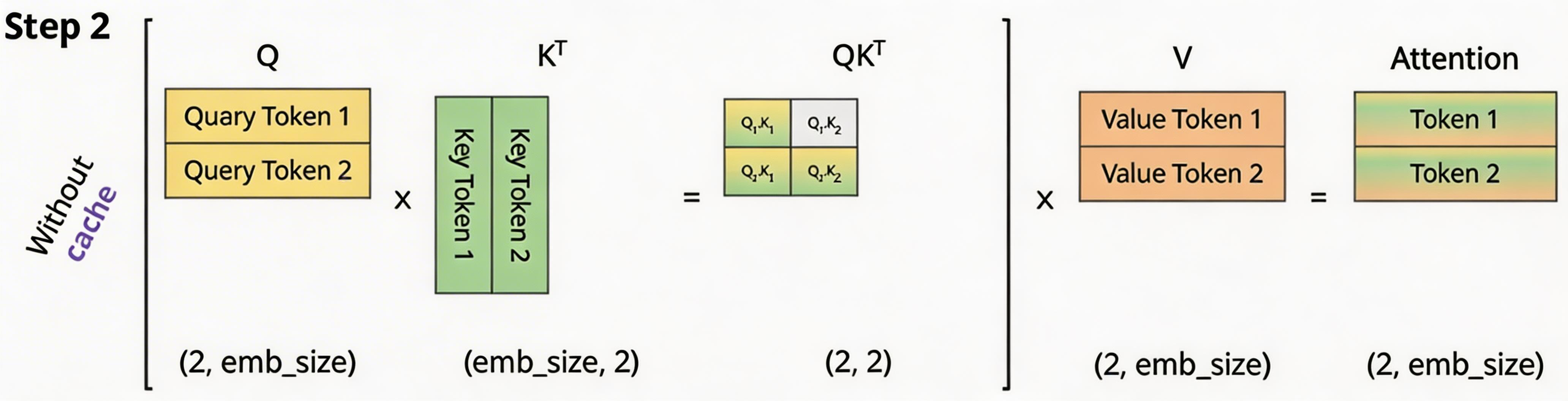
当 变为矩阵时,softmax 会针对行进行计算,详细如下(softmaxed 表示已经按行进行了softmax):
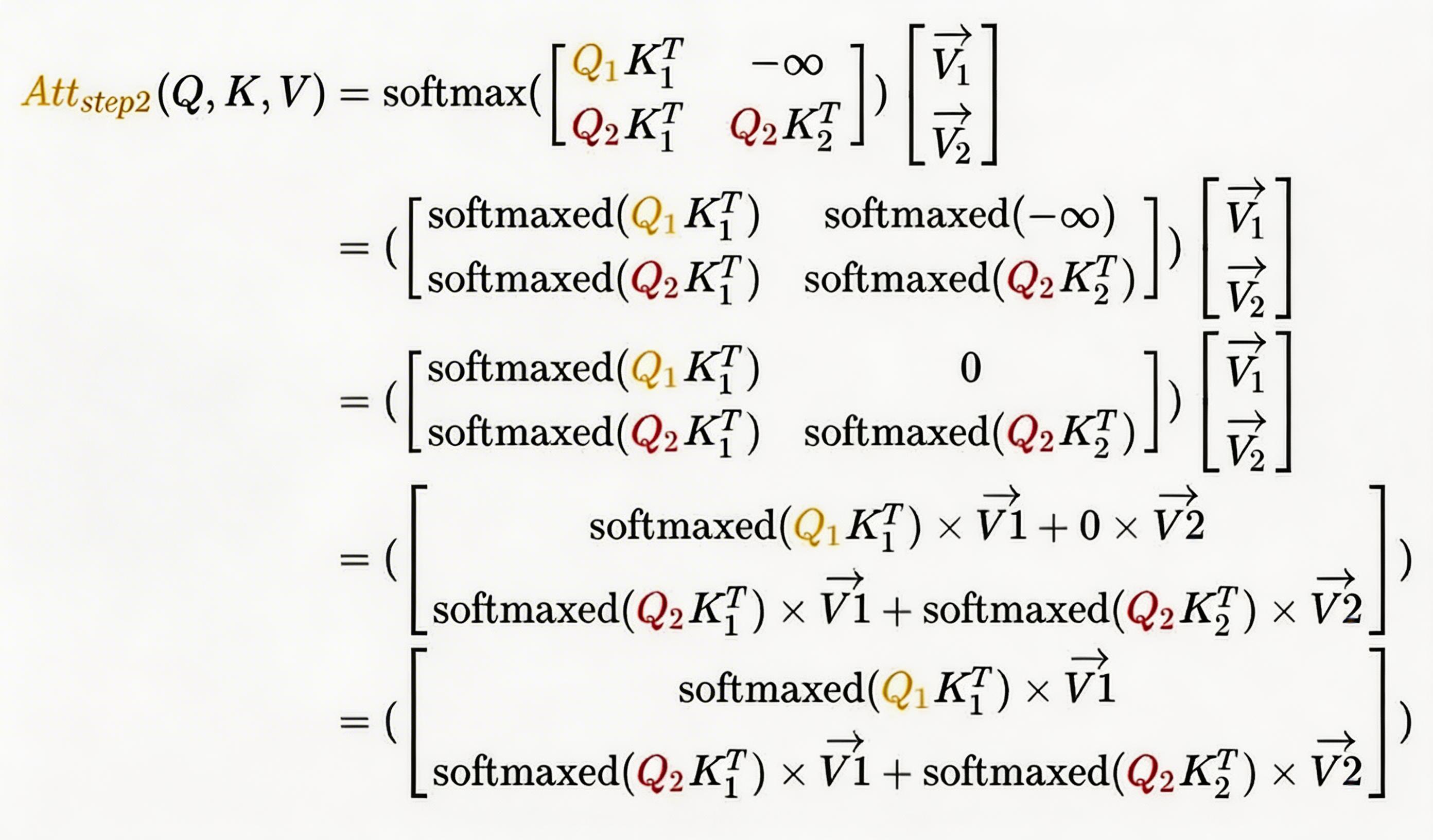
其中, 表示 Attention 的第一行,
表示 Attention 的第二行。
对于 ,由于
这个值会mask掉,你会发现,
在第二步参与的计算与第一步是完全一样的,并且
参与计算Attention时也仅仅依赖于
,与
毫无关系。
对于 ,
参与计算Attention时也仅仅依赖于
,与
毫无关系。
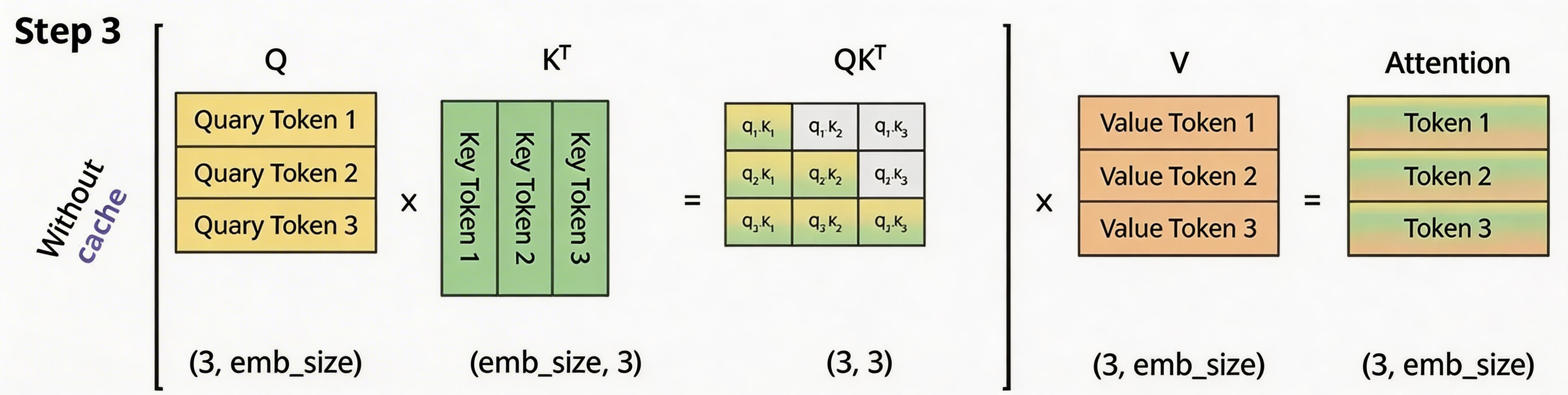
其计算方式如 Step2 所示。
对于 ,
参与计算Attention时也仅仅依赖于
。
看上面图和公式,我们可以得出以下结论:
-
当前计算方式存在大量冗余计算,每一次生成新的Token都需要计算之前的KV。
-
的计算过程中,主要与
-
每一步中,其实只需要根据
备注(Mask):
1. Mask 的核心作用
Mask 的主要目的是:在计算注意力时,忽略无效或未来的位置信息。
具体来说,Mask 用于两种常见场景:
-
Padding Mask:忽略填充(padding)部分
-
Causal Mask(或 Look-Ahead Mask):防止模型在生成当前 token 时"偷看"未来的 token
2. 两种主要的 Mask 类型
1. Padding Mask
-
场景:处理变长序列时,将短序列填充到统一长度
-
问题:填充的 token(如
[PAD])不应参与注意力计算 -
解决方法:使用 Padding Mask 将这些位置的注意力分数设为
-inf,softmax 后权重为 0示例:假设 padding 位置为 0
mask = (input_ids != tokenizer.pad_token_id) # True 表示有效 token
mask = mask.unsqueeze(1).unsqueeze(2) # 扩展维度以匹配注意力矩阵
2.Causal Mask(因果掩码 / Look-Ahead Mask)
-
场景:自回归生成(如 GPT),模型逐个生成 token
-
问题:在预测第 t 个 token 时,不能依赖第 t+1 及之后的信息
-
解决方法:使用上三角矩阵作为 mask,屏蔽未来位置
import torch
def create_causal_mask(seq_len):
# 创建一个上三角矩阵,对角线以下为 1,以上为 0
mask = torch.tril(torch.ones(seq_len, seq_len))
return mask.unsqueeze(0).unsqueeze(1) # (1, 1, seq_len, seq_len)使用
scores = scores.masked_fill(mask == 0, -1e9)
这确保了每个位置只能关注它自身及之前的位置,符合自回归假设。
二、KV cache 步骤
一个典型的带有 KV Cache 的推理过程包含以下两个阶段:
-
预填充阶段:输入一个 prompt 序列,为每个 transformer 层生成 Key Cache 和 Value Cache(KV cache)。
-
解码阶段:使用并更新 KV Cache,一个接一个地生成 token,当前生成的 token 依赖于之前已经生成的token。
KV cache 显存计算
|----|----------------------------------|----------------------------------------|
| 符号 | 含义 | 说明 |
| 2 | Key 和 Value 两部分 | 每个 token 都会生成 K 和 V 两个向量,需要分别缓存 |
| L | 层数(Number of Layers) | Transformer 模型的层数(如 Llama-3-8B 有 32 层) |
| S | 序列长度(Sequence Length) | 当前已处理的总 token 数(prompt + 已生成的 token) |
| H | 注意力头数(Number of Attention Heads) | 多头注意力的头数(如 32) |
| D | 头的维度(Head dimension) | 每个注意力头的向量维度 |
| T | 数据类型大小(Type Size) | 每个数值占用的字节数(fp16或bf16为 2 字节,fp32为 4 字节) |
-
单个 token 的 K/V 向量大小:
H × D(所有头拼接起来) -
单层的缓存大小:
S × H × D(S 个 token) -
所有层的缓存大小:
L × S × H × D -
Key 和 Value 两部分:
2 × L × S × H × D -
乘以数据类型大小:
2 × L × S × H × D × T
三、减少KV cache
1. 为什么减少KV cache?
1.1 更长的上下文
众所周知,LLM 的推理过程通常在 GPU 上进行。然而,单张 GPU 的显存容量是有限的。一部分容量需要用来存放模型的参数和前向计算的激活值,这部分的大小主要取决于模型的体量,选定模型后就成为了一个固定值。另一部分容量则用来存放模型的 KV Cache,它的大小不仅与模型体量有关,还随着模型输入长度的增加而动态增长。当 Context 长度足够长时,KV Cache 的大小将占据主导地位,甚至可能超出一张GPU甚至一台机器(包含8张GPU)的总显存容量。
1.2 提升推理效率
在GPU上部署模型时,我们遵循的原则是:能在一张卡上部署的,就不要跨多张卡;能在一台机器上部署的,就不要跨多台机器。这是因为"卡内通信带宽 > 卡间通信带宽 > 机间通信带宽"。由于"木桶效应",模型部署时跨的设备越多,受到设备间通信带宽的制约就越大。
因此,减少 KV Cache 的目的是为了在更少的设备上推理更长的 Context,或者在相同的 Context 长度下实现更大的推理 batch size,从而提升推理速度或增加吞吐总量。最终目的都是为了降低推理成本
2. MHA(multi-Head Attention)
原始架构:每个注意力头都有独立的 Query、Key 和 Value 投影矩阵。
-
优点:模型表达能力最强,能捕捉最丰富的特征。
-
缺点:
-
KV Cache 显存占用最高:每个头都维护自己的 K 和 V,显存占用 = num_heads × head_dim × seq_len。
-
训练和推理成本高
-
3. MQA(Multi-Query Attention)
核心思想:所有注意力头共享同一组 Key 和 Value,只有 Query 是每个头独立的。
-
优点:
-
KV Cache 显存大幅降低:从
num_heads份 K/V 变为 1 份,显存占用接近 MHA 的1/num_heads。 -
推理速度显著提升,尤其在长序列生成时。
-
-
缺点:模型表达能力略有下降,精度可能微降。
-
应用:Google 的 PaLM 模型采用 MQA; 适合对推理延迟要求极高的场景。
4. GQA(Grouped-Query Attention)
核心思想:MHA 和 MQA 的折中方案。将 num_heads 分为 num_groups 组,每组内共享 K/V。
-
优点:
-
显存占用和推理速度介于 MHA 和 MQA 之间。
-
在速度和精度之间取得良好平衡。
-
-
缺点:实现比 MHA 复杂。
-
应用:Llama-2-70B、Llama-3 系列使用 GQA。
四、Q&A
1. Q:为什么GQA在70B大模型上的优势比7B更明显?
→ 大模型的注意力头维度更高(d_model=8192),KV投影参数占比更大,分组共享的收益呈超线性增长。
2. Q:如何验证某层是否适合改用GQA?
计算该层注意力矩阵的熵值,若熵值<3.5(高确定性注意力),可安全改用GQA
2.1 理论依据:为什么注意力熵与GQA相关?
-
GQA的核心:将多个Query头(Query Heads)映射到更少的Key/Value头(KV Heads)上进行共享。
-
潜在风险:如果不同Query头关注的是完全不同的信息源(即注意力分布差异大),强行共享KV头会导致信息混淆,损害模型性能。
-
注意力熵:衡量注意力权重分布的"集中度"。
-
低熵(如 < 3.5):注意力集中在少数几个token上,分布尖锐。说明模型决策很"确定",对KV信息的多样性要求低,适合GQA。
-
高熵(如 > 5.0):注意力分布平坦,分散在很多token上。说明模型在"犹豫",需要更丰富的KV信息,不适合GQA或需谨慎使用。
-
🔍 类比:如果一个老师(Query)只关注班里最优秀的一个学生(高确定性),那么多个老师共享这个"优秀学生名单"(KV)是合理的。但如果每个老师关注的学生都不同,共享名单就会出错。
2.2 如何计算注意力熵?
在模型推理过程中,获取某一层的注意力权重 attn_weights(形状为 [batch_size, num_heads, seq_len, seq_len]),然后计算其熵:
2.3 阈值设定(如 < 3.5)的合理性
-
阈值
3.5是一个经验性阈值。对于一个长度为n的均匀分布,其最大熵为log(n)。-
例如,
seq_len=1024时,最大熵为log(1024) ≈ 6.93。 -
熵值
3.5大约是最大熵的一半,表明分布已经相当集中。
-
-
经验法则:
-
熵 < 3.5:注意力高度集中,强烈推荐使用GQA。
-
3.5 ≤ 熵 < 5.0:中等集中度,可以尝试GQA,但需评估性能。
-
熵 ≥ 5.0:注意力分散,不建议使用GQA,应保持MHA。
-