KV Cache ( Key-Value Cache,键值缓存) 是大语言模型在推理(生成回答)阶段最核心的加速黑科技 ,同时也是吞噬显卡内存(VRAM)的头号杀手。
如果把大模型生成文章比作**"做一道极其复杂的连环数学大题"** ,那么 KV Cache 就是大模型手边的**"草稿纸"** 。
你之前提到,大模型读长文档时会变慢。理解了 KV Cache,你就理解了大模型的**"** 内存 墙" 到底在哪。
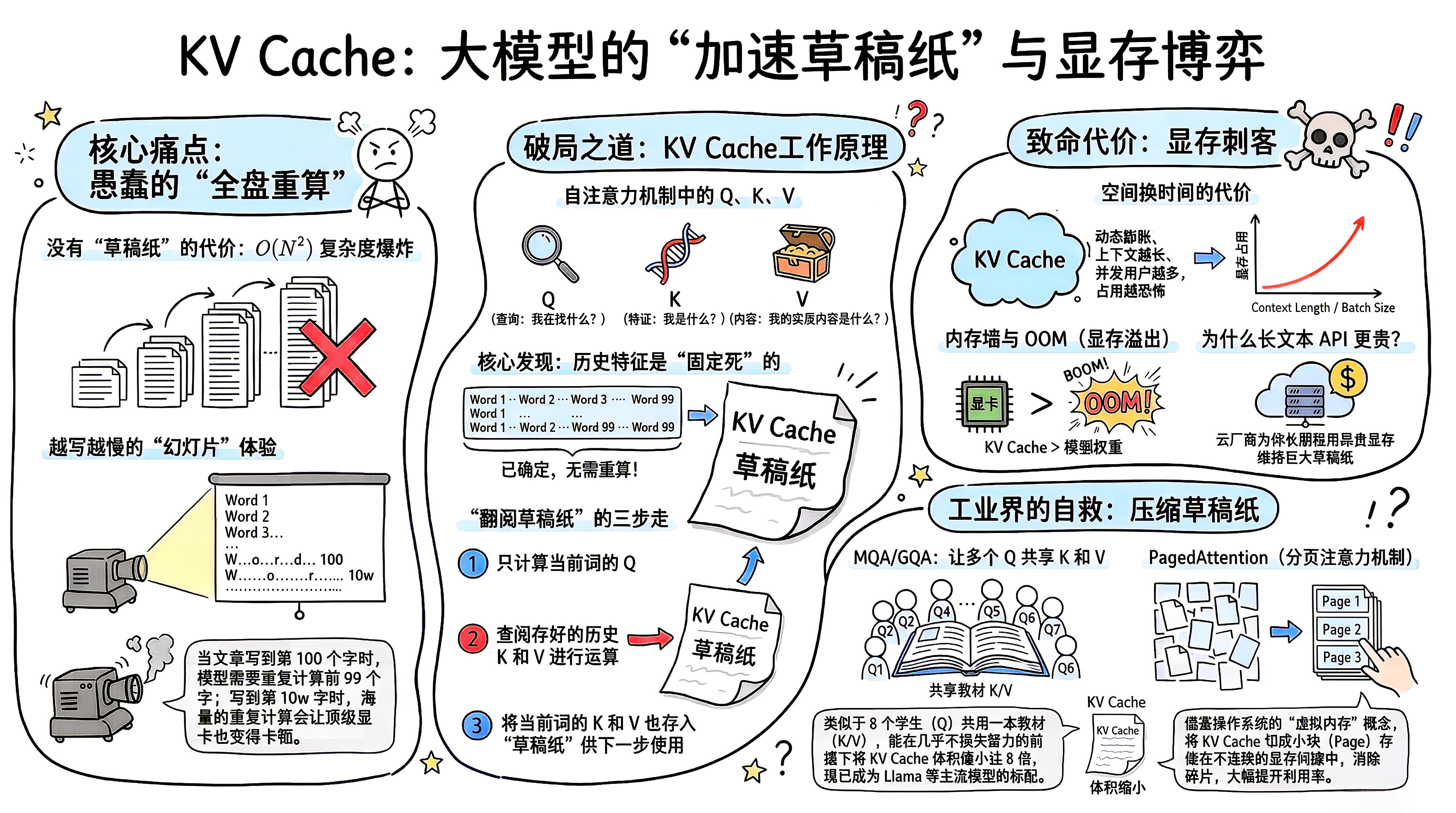
1.🛑 核心痛点:愚蠢的"全盘重算"
我们先回忆一下大模型是怎么说话的------NTP (猜下一个词),它是一个字一个字往外蹦的(这叫自回归生成)。
假设你想让模型写一首诗,目前已经生成了 99 个字,现在要生成第 100 个字。
-
没有草稿纸 (无 KV Cache) 的做法:
-
模型把前 99 个字全部读一遍,进行复杂的矩阵乘法,算出第 100 个字。
-
要算第 101 个字时,模型又得把前 100 个字从头到尾重新算一遍。
-
-
代价:随着文章越来越长,计算量呈 O(N^2) 爆炸式增长。前面算过的结果被反复丢弃、反复重算。如果文章有十万字,这种重算会让最顶级的显卡也卡成幻灯片。
2.💡 破局之道:把"旧相好"存起来 (KV Cache 原理)
科学家们回头看了一眼我们之前聊过的自注意力机制 (Self-Attention),发现了一个极其明显的偷懒机会。
在注意力机制中,每个词都会生成三个向量:
-
Q (查询):我在找什么?
-
K (特征):我是什么?
-
V (内容):我的实质内容是什么?
天才的发现:
当模型生成第 100 个字时,前 99 个字的 K (特征) 和 V (内容) 已经是固定死的了,绝对不会再变!
所以,正确的做法是:
-
当前词出击 :只计算当前这第 100 个字的 Q。
-
翻阅草稿纸 :用这个 Q ,去跟前面 99 个字已经提前存好 的 K 和 V 直接相乘。
-
记入草稿纸 :算完之后,把第 100 个字自己的 K 和 V 也存进内存里,供第 101 个字查阅。
这个专门用来存放历史 K 和 V 向量的 显存 空间,就叫 KV Cache。 有了它,计算时间复杂度直接从平方级降到了线性 O(N),模型的吐字速度瞬间起飞!
3.⚔️ 致命代价:用空间换时间的"显存刺客"
天下没有免费的午餐。KV Cache 虽然极大地提升了速度,但它带来了一个极其恐怖的副作用:吃 显存。
-
模型的参数(权重)是固定的,比如占据了 80GB 显存。
-
但是,KV Cache 的大小是动态的。
-
你输入的上下文越长(Context Length),要存的 K 和 V 就越多。
-
同时用这个模型的人越多(Batch Size),系统要为每个人单独开辟的 KV Cache 就越大。
-
-
结果 :当上下文达到 128k 甚至 1M 时,装载 KV Cache 所需要的显存,甚至会远远超过模型本身的体积 。你的显卡不是因为算力不够卡住了,而是因为内存 被 KV Cache 撑爆了 ( Out of Memory , OOM )。
这就是为什么各大云厂商的 API 接口,长文本的收费通常比短文本贵得多的底层原因------因为他们要为你长期租用极其昂贵的 显存 来维持这块"草稿纸"。
4.🛠️ 工业界的自救:如何压缩草稿纸?
为了解决 KV Cache 太大的问题,近年来(尤其是 Llama 2 和 Llama 3 时代),AI 架构师们发明了几种极其聪明的变种架构:
A. MQA (多查询注意力) / GQA (分组查询注意力)
-
原理 :既然 K 和 V 太占地方,那我们让几个不同的 Q "共享" 同一组 K 和 V。
-
效果:就像是一个小组的 8 个学生(Q)共用一本教材(K 和 V)。这能在几乎不损失模型智商的前提下,把 KV Cache 的体积缩小 8 倍!现在的顶级开源模型几乎全标配 GQA。
B. PagedAttention (分页注意力机制 / vLLM)
-
原理:借鉴了操作系统的"虚拟内存"概念。以前的 KV Cache 必须在显存里找一块连续的巨大空地,导致很多碎片浪费。现在把它切成一个个小块(Page),哪里有空隙就塞在哪里。
-
效果:大幅提升了显卡的利用率,是目前云端部署大模型的最强神器(vLLM 框架的核心)。
总结
KV Cache 是一场**"用空间换时间"** 的极致交易。
大模型之所以能行云流水地打字,正是因为显卡里有一片隐秘的内存,默默地替它记住了之前说过的每一句话的数学特征。