目录
[1、为什么需要 KV Cache?先搞懂大模型的文本生成模式](#1、为什么需要 KV Cache?先搞懂大模型的文本生成模式)
[2、不使用 KV Cache 时,到底有多少冗余计算?](#2、不使用 KV Cache 时,到底有多少冗余计算?)
[3、使用 KV Cache 时,到底优化了什么?](#3、使用 KV Cache 时,到底优化了什么?)
1、为什么需要 KV Cache?先搞懂大模型的文本生成模式
大模型文本生成是自回归模式,一句话总结就是:一次只生成 1 个 token,把生成的 token 拼到输入末尾,再喂给模型生成下一个,循环往复直到结束。如下图所示
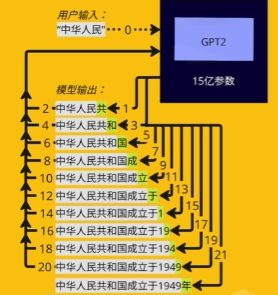 token生成图
token生成图
大模型推理是逐 token 生成的循环过程,每一轮都需要注意力计算,需要用当前新 token 的 Q,和历史所有 token 的 K 做点乘 ;而历史 token 的 K/V,是之前已经通过线性变换算好的固定结果,KV Cache 就是把这些历史 K/V 缓存下来,让后续循环不用再对历史 token 重复做线性变换重算 K/V,直接用缓存结果参与 QK 点乘运算。
KV Cache 仅优化自注意力中的冗余计算,不参与预测下一个 token 的过程,只为在Decode阶段更快算出注意力分数,从而加速推理。
总结下来三个点:
1、KV Cache应用于推理阶段(也就是K、V的值是不变的)
2、KV Cache 主要用在 Transformer 的 Decoder 解码器中
3、目的是为了消除历史 token 的 K/V 重复计算,减少整体计算量,大幅提升推理速度。
2、不使用 KV Cache 时,到底有多少冗余计算?
不用 KV Cache 的时候,模型每生成一个新 token,都要把整段序列里所有 token 的 K、V 重新算一遍;可前面那些历史 token 的 K、V,之前轮次早就算过了,完全是重复计算、白白浪费算力。
例如下面这种情况:
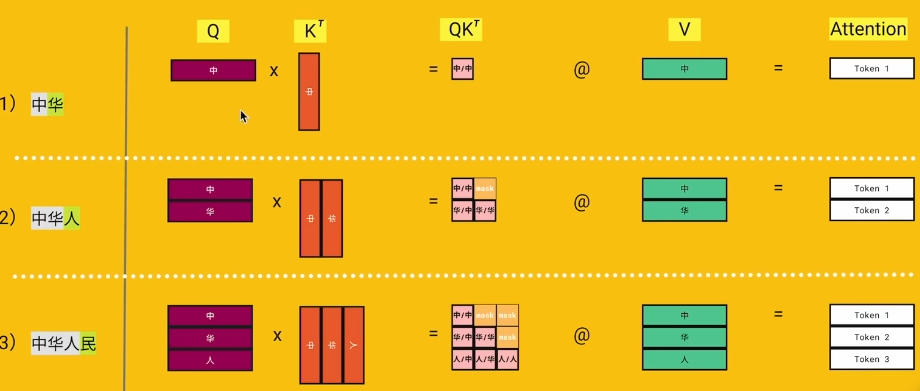
第一步,输入 "中",算一遍 "中" 的 K、V;
第二步,加了个 "华",又把 "中" 和 "华" 的 K、V 全重算了一遍 ------ 可 "中" 的 K、V 上一步刚算完,结果根本不会变啊;
第三步,再加个 "人",又把 "中、华、人" 的 K、V 全重算一遍,前面俩的又白算一遍。
不用 KV Cache 就是这样,每生成一个新 token,前面所有旧的都要跟着重算一遍,全是无效的重复计算,白白浪费算力,这就是它的冗余问题。
3、使用 KV Cache 时,到底优化了什么?
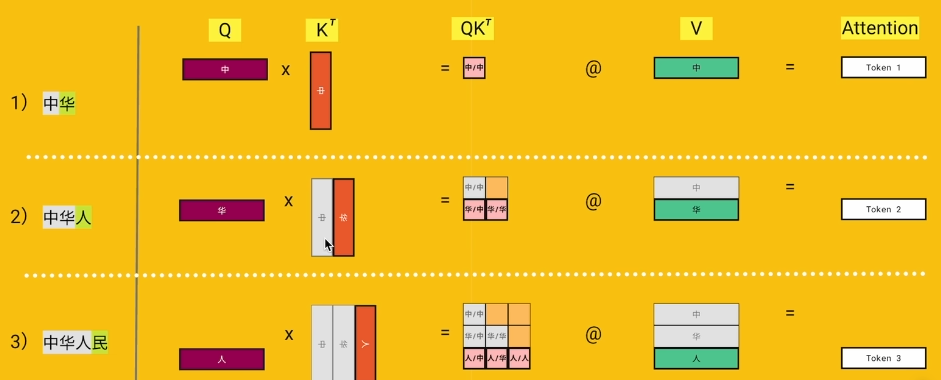
与
灰色部分就是已经缓存到显存里的 KV Cache,就是之前轮次算好的历史 token 的 ,直接复用,不用重算。
**输出的 token 变为只有 1 个,核心原因是:**用了 KV Cache 的 Decode 阶段,每一轮我们只输入 1 个新 token 的 Q 矩阵,Q 有多长,Attention 输出就有多长。
4、为什么长上下文会提高显存占用和时延?
4.1显存占用线性增长的核心原因
显卡中存储的 KV Cache,占用空间会随着 token 数量的增加呈线性增长。本质原因是:大模型自回归生成的每一轮,历史 token 对应的 K、V 矩阵一旦计算完成,结果就固定不变,会一直缓存在显存里给后续所有轮次复用。简单说就是:有多少个 token,就要在显存里存多少份对应的 K、V 数据,上下文越长、token 总数越多,KV Cache 占用的显存就越大。
4.2推理时延飙升的核心原因
Prefill(模型读问题阶段) :自注意力的核心,是计算每个 token 和其他所有 token 的关联度(也就是QKT矩阵乘法)。上下文每多一个 token,就要额外计算它和前面所有 token 的关联度,计算量会随 token 总数呈平方级增长,上下文越长,预处理耗时就会直接暴涨。
Decode(模型生成答案):就算用了 KV Cache 省去了历史 K、V 的重复计算,每生成一个新 token,也要用新 token 的 Q,和显存里缓存的所有历史 K 做关联度计算。上下文越长、缓存的历史 K 越多,单步生成的耗时就越长,整体推理时延自然会跟着飙升。
5、Prefill与Decode的异同
5.1、底层计算逻辑完全一致
二者执行完全相同的 Transformer 层全流程计算,共享同一套自注意力计算公式
都需要完成:输入 token 嵌入向量的线性变换生成 Q/K/V、计算 token 间关联度、softmax归一化得到注意力权重
5.2、计算速度差异
Prefill 阶段**:**一次性输入全量 prompt 的 n 个 token,耗时核心是全量 prompt 的 O (n²) 自注意力计算,KV 写入显存是耗时可忽略的收尾操作.
Decode 阶段:读写都有,核心开销是每轮读取全量历史 KV Cache 的访存操作,写入仅追加 1 个新 token 的 KV,耗时可忽略。
5.3、总结
所以Prefill 阶段完全无法享受 KV Cache 的提速收益,因为它的核心任务之一就是从零初始化、构建 KV Cache,无任何历史缓存可复用,必须全量计算所有 prompt token 的 K/V;KV Cache 的所有提速价值,都体现在后续的 Decode 生成阶段。