名词解释:
APM : application performance monitoring 应用性能监控
监控黄金三项,或者叫可观测三件套:
metrics :指标,比如Prometheus
traces: 链路,工具如skywalking
logs: 日志,比如ELK
P99: percentile 百分位数,也就是百分之99的请求是在多少毫秒以内完成的
QPS: queries per second,每秒请求数
RT: response time,响应时间
什么是监控?监控的作用是什么?
首先回答这两个问题,再说怎么实现监控。
- 什么是监控?
第一印象是摄像头。那为什么要有摄像头,摄像头是干嘛用的?
比如防止别人偷东西,可以留证据,可以根据摄像头拍到的数据来推测前因后果。如果摄像头还会吱吱吱叫,或者自动打电话,那就有了告警功能。
这些词语可能都是从英文翻译过来的。
监控是monitor,一般我们翻译成班长、哨兵。
其实这两个词挺准确的,班长,就是看着班上的同学,保持一定的纪律性,如果有问题,也不是自己直接处理,一般是告诉老师。
哨兵,感觉就是站在长城的那个塔上,巡逻。瞭望。还有站在海上的瞭望塔上,灯塔上,看着到处。如果有问题,也不是自己直接处理,也是拉警报或者放狼烟来告知处理的人。
所以监控主要是监视和告警。
告警是alert,拉警报的意思。
那么从服务的领域来说,从运维的领域来说,什么是监控,监控的作用是什么?
首先我们要明白,为什么要搞监控。
这个是从经济和人类社会活动的角度来讲。先从大的方面来讲吧。
人们要生活,要过更好的生活,就要生产更多的劳动成果来与别的人们的劳动成果交换。
那么你想换别人好的东西,或者换的东西数量多。那么你的东西就得好。
那么现在别人需要什么呢?人们需要和朋友亲人以及客户供应商的关系聊天,甚至是包括陌生人聊天。那么就需要一个微信这样的工具,如果你提供了微信这样的工具,然后有很多人用这个微信,那么你就可以利用用户的关注和停留来赚钱,比如说你在微信朋友圈打广告,那么广告商知道你的朋友圈有很多人看,所以愿意出钱给你,让你帮忙在微信上放他们的广告。同理,小程序广告、公众号广告、视频号广告、小游戏广告这些都是你这个微信产品的收入来源。
那么你怎么让自己的微信这款产品一直被大家喜欢呢。最起码,你得保证核心功能的稳定吧。比如用户A给用户B发消息,他得能够准确且低延时的收到吧,所以你的微信产品不能说动不动连不上网了,动不动登录不上了。你的数据库和服务都应该要稳定。如果只是内部测试,个别人再使用,那么对于服务器数据库网络带宽等的性能要求不高,能用就行,比如都部署在同一台物理服务器或者虚拟机上都行。但如果这个社交产品微信,是给上亿人使用的,甚至上十亿人使用的,那么牵扯的问题就多了,要涉及多个数据中心,多个集群,要高可用。数据库也要有集群,也要有高可用,主从同步,备份这些,还有存储集群的管理,还有网络的可用性管理,还有数据安全的管理。也就是计算存储网络,包括应用的接口性能,延迟,以及数据库的慢sql,如无索引导致的等等。这些庞大的基础设施以及应用,以及前后端服务接口的稳定性,面对高并发如何处理。首先,这些是要做的事情,我们可以一步步把这些规划好,做好架构设计,细节统统都考虑到位。然后让服务运行起来。这个时候服务就可以用了,可以服务上亿用户,然后你能和合作伙伴一起赚钱。广告商给你打钱,你把广告发到朋友圈小程序小游戏公众号视频号等上面。那么你设计好了之后,怎么保证它不出问题呢。比如说哪里的网络抖动了,哪里的存储满了,哪里的计算资源不够用了,比如内存持续升高,java程序的垃圾回收没做好,内存没释放等等。这么庞大的一个系统,我们难以做到设计和部署好了之后就不用管了。如果你不管的期间,这个微信用不了了,通信有问题,甚至支付有问题,这种问题出现几次,谁还敢用微信。那么竞争对手的机会就来了。所以你和合作伙伴的产品的稳定性很重要,那么第一步是做好设计架构和部署,第二步就是要上监控,我们通过监控可以看到方方面面,最主要是的应用接口的监控,接口有没有延迟,P99是多少,有没有请求错误,错误率是多少。第二个层面是集群,比如k8s集群的namespace级别的资源如何,服务的资源,pod的数量,存活数量,重启与否这些。第三个层面是基础设施层面,比如说物理服务器或者虚拟机的计算资源、存储资源、网络资源如何,数据库的计算存储网络的资源如何。从应用到平台到资源级别的监控,我们需要一目了然,看一看看板就知道什么是什么情况了。那如果说要监控的内容非常多呢。需要非常多的看板看,所以需要雇佣多个人来看。那么在这种情况下,如果谁漏看了,会不会有问题呢。会有问题,而且造成的用户心中形象的损失比较大,会影响用户的使用和信任,那么用户用的少了,广告费也就赚的少了。这个是不想看到的。那么怎么办呢?第三步就是在架构设计部署、监控之后,要加上一个告警,告警的方式有很多,常用的是聊天机器人,比如说企微机器人,还有邮件告警、短信告警、电话告警这些。
总的来说,监控是干嘛用的?对于公共或者个人人身和财产安全来说,是保护安全的。
对于商业行为来说,是监控自己的系统的稳定性的。巡检是主动去发现问题,告警是被动知道问题。总而言之,目的是为了让自己的服务稳定,用户体验好,一方面能稳定用服务的功能,一方面还能赚广告费等的钱。
这个就像我们传统的制造业造出来的东西,你的东西既得能用,而且得质量好。也就是用的久,质量稳定。
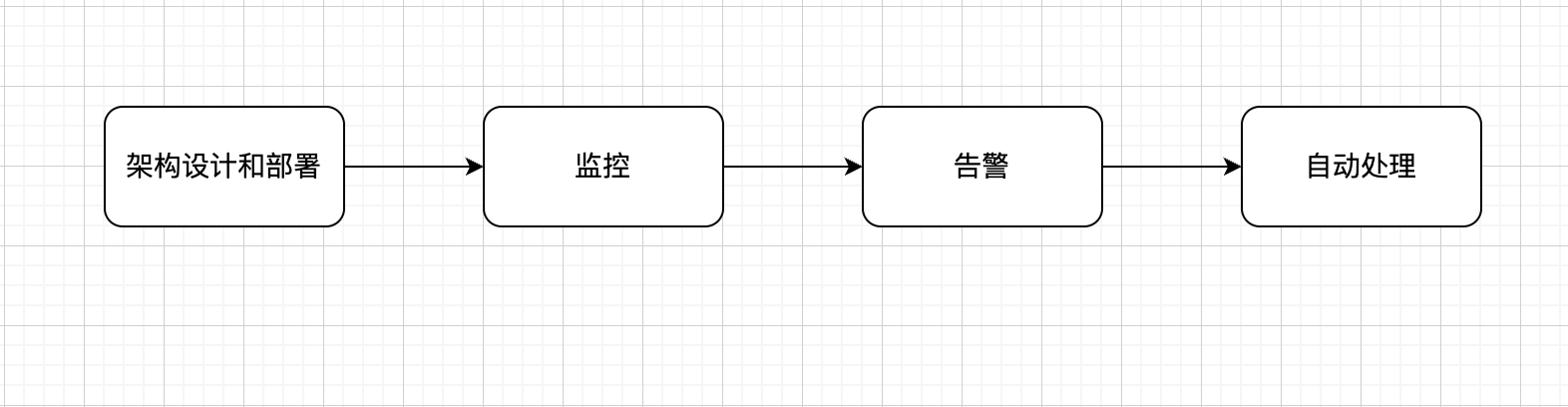
那么在互联网时代,你制造的东西就是你的网站,PC端的话是你的网站,移动互联网端的话一般是你的APP。那么如何让你的产品运行的稳定呢?首先是从架构设计和部署方面就做好规划,资源以及集群的规划。第二步就是要做好监控,第三步是要做好告警,第四步如果能够做好自动处理那就更好了。
所以说,我们先弄清楚监控是什么,为什么要有监控,监控的作用是什么?没有监控会怎么样?
如果用芒格的思维来说,就是反过来想,总是反过来想。那就是如何让自己的互联网生意失败?
那么从业务上来讲,其中一个方法就是让服务不稳定,一会不能用了一会又不能用了,这样的情况持续久了,该产品的用户就没了。这个生意就做不下去了。那么如果让自己的服务不稳定呢?其中一个方法就是不监控,有问题了再说,这就不行,这样会中断业务。
所以我们做好监控的价值是什么呢?
就是不让业务服务中断。有中断的风险的话,提前知道。好提前处理和预防。
所以要做好监控,让自己的服务的稳定性得到可观测。
同时做好告警,因为人不会一直看着监控页面。如果有问题,可以有聊天机器人在群里发消息,或者给运维的人发短信,或者发邮件。
所以说这个监控是从业务的角度来看,比较重要。如果说架构设计和部署做的好,能够让稳定性来到90%,那么监控管理的就是这10%的风险点,如果有问题能够提前知道,而不是等问题发生了才知道。
就像芯片的良率,正常的比如是90%,那么监控的价值,就是让其提高到接近100%,或者说达到99%。那么这个价值看着数量不是很大,但正可能是与竞争对手的差距就在这里。
比如之前米聊先出来,微信后出来,但是微信为什么能超过米聊呢。其中一个原因可能就是,米聊会出各种不稳定的问题,而微信很少出现。所以用户就用开微信了。用户就是这么挑剔。所以要得到用户,就得对自己产品的稳定性提出更高的要求。因为是生产环境,而不是测试环境,所以产品质量是关键,感觉就像第二名与第一名的差距。就像社交工具,第一名可能会有头部效应,用的人越多,就越多,第二名就被马太效应赶走了。市场竞争就这样。
所以监控是产品获得市场的一个关键。
那么说到这个监控,有个说法是监控黄金三项,是什么呢?
metircs、logs、trace
metrics是监控指标,包括应用接口层面的、应用平台层面的,比如k8s集群各个指标、还有基础设施层面的,比如底层服务器的计算存储网络数据库中间件等的资源情况
trace是链路,比如skywalking监控整个服务的链路的延迟和连接情况,能够可视化的展示,一眼看出来到底是哪个接口相应慢,或者返回错误码。
logs是日志系统,比如ELK和腾讯云CLS的日志系统,可以区分业务和环境来建立不同的topic来看日志。
可以总结为,metrics发现问题、trace定位问题、logs解决问题。