一、概述
1.机器学习:从有限的数据中推测规律,并用规律预测未来。
具体步骤:原始数据(数据收集) ->数据预处理 -->特征处理-->模型训练-->预测&结果
2.深度学习:需要经过多层特征转换得到一种特征表示,并用规律预测未来。【自动的】
具体步骤:原始数据(数据收集) ->底层-->中层-->高层->预测&结果
贡献度分配问题: 深度学习是层层嵌套、高度非线性的,很难知道每个层度的贡献(重要性)
3.神经网络(深度学习的一种模型,易于解决贡献度分配问题 )
三个层级:输入、隐藏 (可以多层)、输出
分类 :前馈网络、记忆网络、图网络
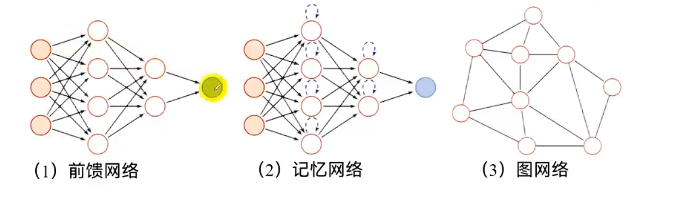
二、前馈神经网络
1.人工神经元:一个简单的线性模型
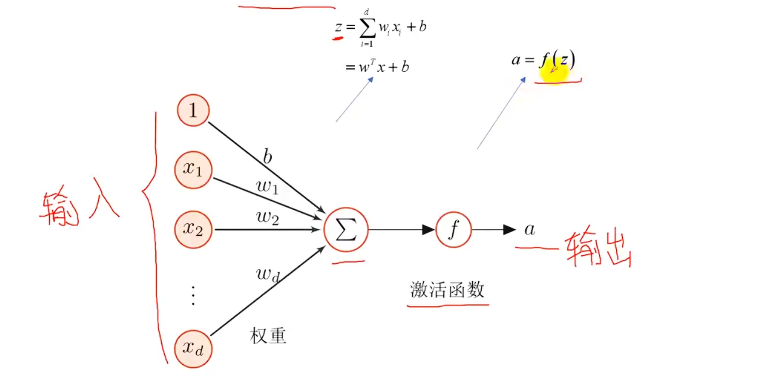
激活函数:1.连续且可导 的非线性函数 2.可以直接利用数值优化的方法来学习网络参数3.简单 高效
4.导函数的值域 要在一定的区间内5.单调递增
常见的激活函数:
| 激活函数 | 公式 / 范围 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Sigmoid | 1/(1+e−x)0~1 | 平滑、可输出概率 | 两端梯度饱和→梯度消失非零均值、收敛慢、计算贵 | 二分类输出层(少用) |
| Tanh | ex+e−xex−e−x-1~ 1 | 零均值、收敛比 sigmoid 快 | 依然梯度饱和 / 消失 | 早期 RNN、隐藏层过时 |
| ReLU | max(0,x) 0~+∞ | 极快、简单正区梯度 = 1 缓解消失 | 负区硬饱和→神经元死亡非零均值 | 隐藏层通用首选 |
| Leaky ReLU | max(αx,x) | 缓解神经元死亡、保留负梯度 | 需调超参 α | 防止 Dead ReLU |
| Softmax | 归一化指数和为 1 | 输出标准概率分布 | 数值易不稳定类别不平衡尖锐 | 多分类最后一层 |
| GELU/Swish | 平滑非线性 | 梯度更稳、效果更强 | 计算略慢 | Transformer、大模型 |
2.神经网络
定义: 可以信息传递(连接主义模型 )并行 ;通过误差反向传播改进学习能力
3.前馈神经网络(FNN)
特征:
1.各神经元分别属于不同的层,层内没有链接
2.相邻两层之间的神经元全部两两相连
3.整个网络之中无反馈,从输入层到输出层单向传播
4.每一层的神经元可以接收前一层神经元的信号,并产生信号到下一层
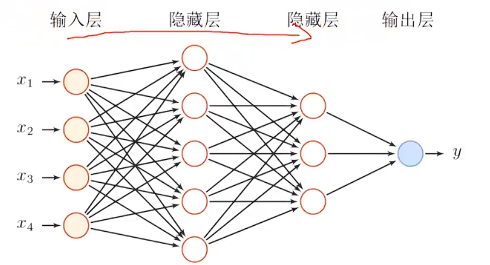
深层前馈神经网络
4.参数学习:梯度下降法
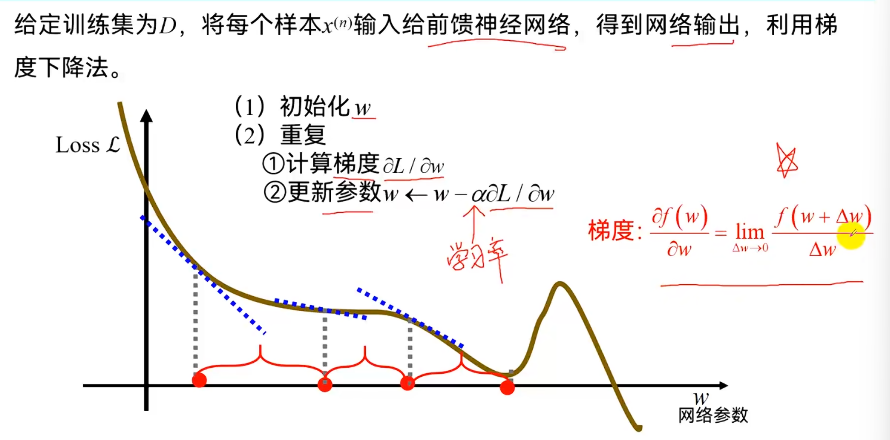
5.优化问题:
深度学习步骤:1.定义网络 2.损失函数 (误差)3.优化(参数、模型)
难点:1.参数多,解释困难 2.非凸优化问题(局部最优解)3.梯度消失问题
三、卷积神经网络
1.卷积:
用一个卷积核(滤波器)在图像上滑动,做加权求和。
作用:提取局部特征(边缘、纹理、形状)。
一维卷积:信号处理 yi= wk*xi+k
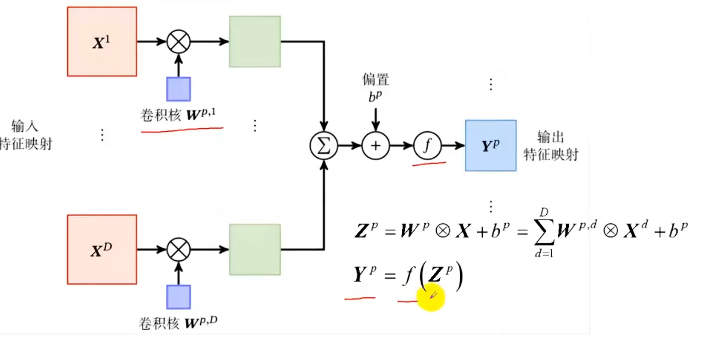
二维卷积:图像处理【卷积 常作为特征提取的有效方法,一幅图像经过卷积后得到的结果常称为:特征映射】
卷积核:大小 、 步长 :滑动时的时间间隔 **零填充:**两端补0
2.卷积神经网络(CNN)
一种具有局部链接、权重共享的深层前馈神经网络
构成:隐藏层===卷积层、汇聚层、全连接层
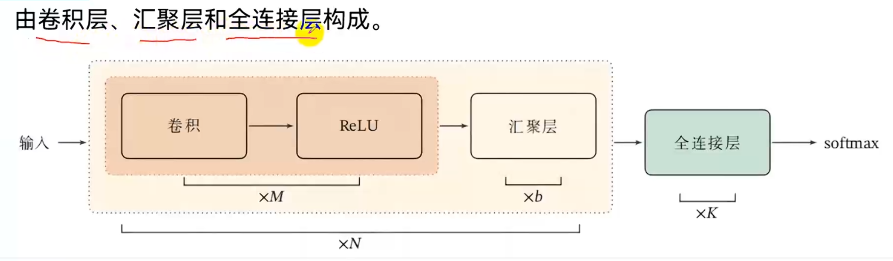
卷积层:特征提取 卷积核:特征提取器
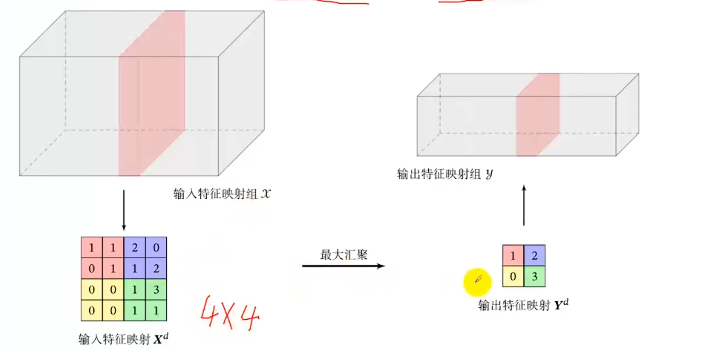
汇聚层:特征选择,降低特征数量,从而减少参数数量(池化层:pooling )
3.常见的卷积神经网络:
LeNet-5:手写识别
AlexNet :现代 使用ReLU作为非线性激活函数、防止过拟合
Inception 网络
四、循环神经网络:
1.延时神经网络:建议一个额外的延时单元,用来存储网络的历史信息,在时间维度上共享全职,以降低参数数量。在前馈网络的非输出层都添加一个延时器
2.循环神经网络(RNN ):通过使用带自反馈的神经元,能够处理任意长度的时序数据
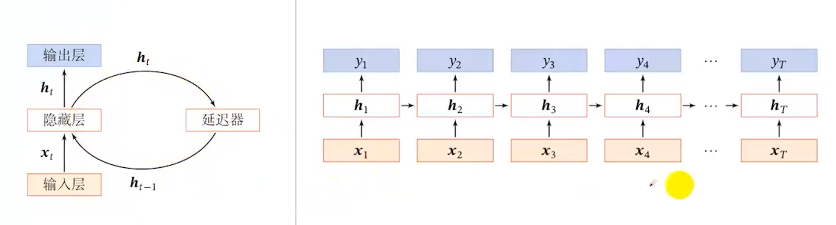
3.简单循环网络(SRN):只有一个隐藏层
应用:情感分类、中文分词、信息抽取(自然语言方面NLP)
长短期记忆网络:
1.梯度爆炸:深度网络反向传播时,梯度指数级增大,导致参数更新过大、训练崩溃。
梯度消失:梯度越来越小,趋近 0,网络学不动
2.长程依赖问题:RNN 处理长序列时,早期信息因梯度消失无法影响后续输出。
【类似读书读到后期,忘记了前面出现过的人物】
3.基于门控的神经网络:在普通 RNN 基础上,加入门控机制(Gate) ,用来控制信息的保留、遗忘、更新 ,解决 RNN 的梯度消失 和长程依赖问题。
长短期记忆网络:是一种改进型循环神经网络(RNN) ,专门解决普通 RNN 的梯度消失 和梯度爆炸**问题。**引入门控机制来控制信息的累计速度,包括有选择的加入新信息,有选择地以往之前积累的信息。
五、网络优化与正则化:
1.网络优化:找一个模型使经验或者结构风险最小化【模型选择、参数学习】
2.优化算法:梯度下降法:随机梯度下降、小批量梯度下降
| 方法 | 每次迭代用多少数据 | 优点 | 缺点 | 实际使用 |
|---|---|---|---|---|
| 批量梯度下降 BGD | 全部样本 | 梯度准确、收敛稳定 | 速度极慢、占内存大、无法处理大数据 | 几乎不用 |
| 随机梯度下降 SGD | 1 个样本 | 速度最快、易跳出局部最优 | 梯度噪声大、震荡严重、收敛不稳定 | 较少单独用 |
| 小批量梯度下降 MBGD | 一小批样本(batch size) | 速度快、梯度稳定、适合并行 | 需要调节 batch size | 深度学习主流 |
3.数据预处理:
标准化: 归一化(最大最小规范化)、Z-Score标准化。
分箱:建立分类模型时,将连续变量离散化,降低过拟合的风险
4.网络正则化:避免过拟合,提高泛化能力
正则化两种思路:
1.增加优化约束---》数据增强
2.干扰优化过程----》权重衰减、随机梯度下降、提前停止