前言
在前两篇文章中,我们分别从语法增强与移动语义的角度,系统地梳理了 C++11 对语言表达能力与性能模型所带来的改进。然而,C++11 的重要意义并不止于此,它还在泛型编程层面引入了一系列关键特性,使得 C++ 的抽象能力得到了显著提升
在 C++11 之前,模板在处理不定参数时往往需要借助递归展开等技巧,不仅代码冗长,而且可读性较差。为了解决这些局限,C++11 引入了可变参数模板,并配合参数包展开机制,使得任意参数个数的模板编程成为可能。此外,STL 也基于这些新特性,引入了如 emplace 系列接口以及函数包装器等工具,从而进一步提升了容器与函数调用的灵活性与性能表现
本文将围绕这些内容展开,依次介绍可变参数模板、参数包展开,emplace 接口的设计思想以及函数包装器等关键组件,从而完成对 C++11 泛型能力升级的整体认识
一. 可变参数模板
可变参数模板(Variadic Templates)是C++11引入的一项重要特性,允许模板接受任意数量和类型的参数
1. 引入背景
在 C++11 之前,实现可变参数函数只有两种相当麻烦的方案
-
C 风格的可变参数 (...): 以 printf 为例,虽然能接受任意数量的参数,但存在类型安全问题。编译器无法进行类型检查,若错误地将 std::string 传给 %d 格式符,可能导致输出乱码甚至程序崩溃
-
重复繁琐的重载: 早期的 std::tr1::tuple 实现就是典型案例。为了支持不同参数数量,开发者不得不手动写出接收 1 个、2 个、3 个......直到 10 个甚至更多参数的重载版本。这种方法代码冗余严重,维护极其困难
可变参数模板的出现,就是为了在类型安全 的前提下,用一套统一、简洁的语法处理任意数量、任意类型的参数
2. 可变参数模板基础
可变参数模板的核心在于省略号 ...。该符号在不同使用场景下具有不同的名称和功能
模板参数包(Template Parameter Pack )
在模板声明中,紧跟在 typename 或 class 后面的 ... 表示这是一个模板参数包。它代表 0 个或多个类型的集合
cpp
template <class... Args>
class MyClass {
// Args 是一个模板参数包,代表 0 到 N 个类型
};
MyClass<int> obj1;
MyClass<int, double, string> obj2;
MyClass<> obj3; // 也可以是空的函数参数包(Function Parameter Pack )
在函数声明中,紧跟在类型包名后的 ... 表示这是一个函数参数包。它代表 0 个或多个具体的对象
cpp
template <typename... Args>
void log(Args... args) {
// args 是一个函数参数包,代表 0 到 N 个实参
}我们可以使用 sizeof... 运算符去计算参数包中参数的个数
cpp
template<class... Args>
void Count(Args&&... args)
{
cout << sizeof...(args) << endl;
}
double x = 2.1;
Print(); // 包里有0个参数
Print(1); // 包里有1个参数
Print(1, string("xxxxx")); // 包里有2个参数
Print(1.1, string("xxxxx"), x); // 包里有3个参数这里会结合引用折叠规则实例化出以下四个函数
cpp
void Print();
void Print(int&& arg1);
void Print(int&& arg1, string&& arg2);
void Print(double&& arg1, string&& arg2, double& arg3);需要特别注意:参数包既非数组也非容器,无法通过索引直接访问。必须借助特定的展开机制才能获取其中的元素
二. 参数包展开
展开参数包方式主要有两种:经典的递归方式 和现代的逗号表达式 / 初始化列表方式。我们先从最符合直觉的递归展开聊起
1. 递归展开方式
每次通过模板特化取出一个参数,剩下的参数继续组成一个新的参数包,直到包变为空
核心步骤:
-
递归终止函数:处理最后一个参数或空包的情况
-
展开函数:取出一个参数,并递归调用自身处理剩余的
cpp
// 1. 递归中止函数
void print() { cout << "展开结束" << endl; }
// 2. 展开函数
template<class T, class... Args>
void print(T x, Args... args)
{
cout << x << endl;
// 递归调用: 把剩余包传下去
print(args...);
}
print(1, 2.1, "hello");执行流程拆解:
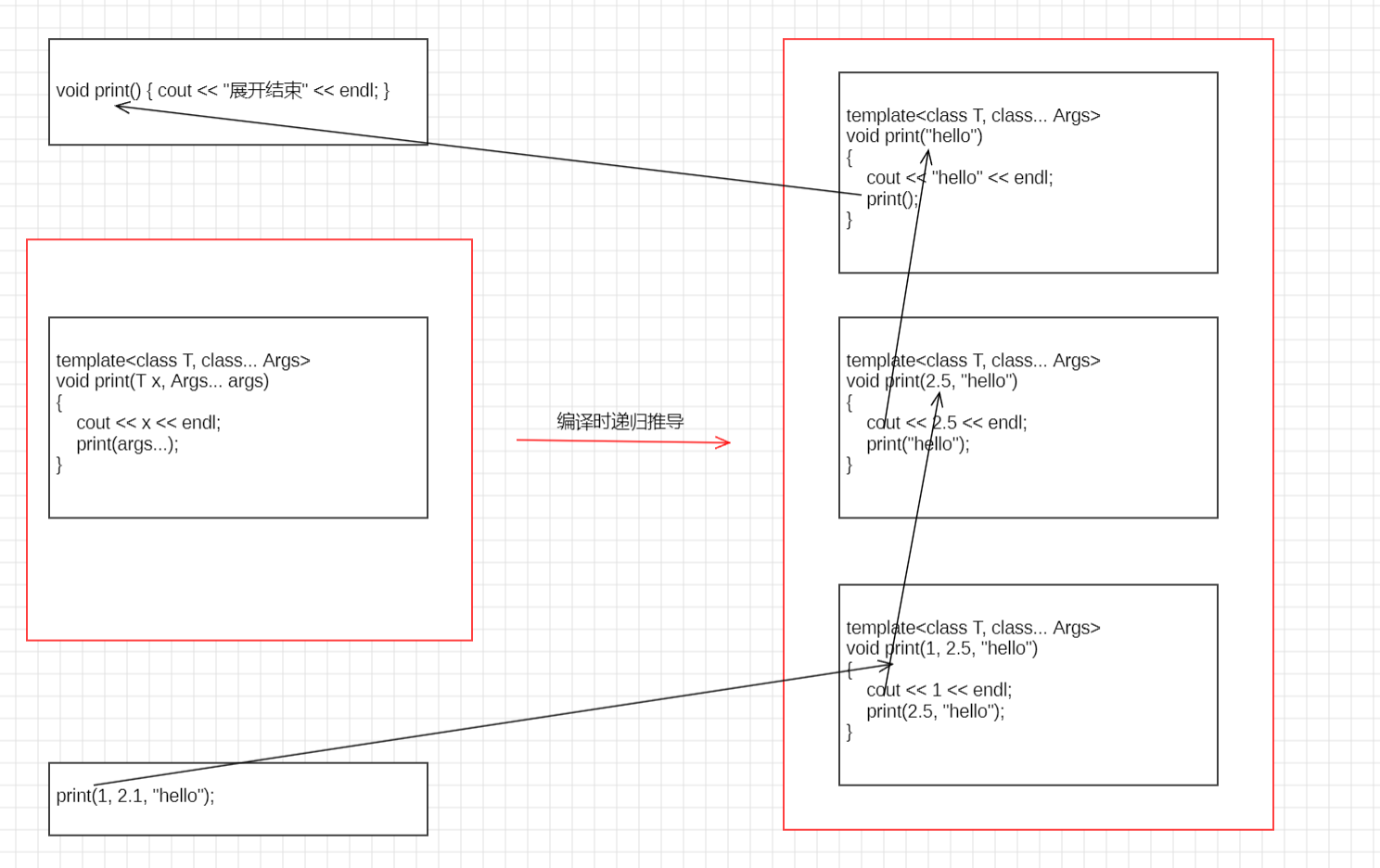
在 C++ 中,... 出现的位置非常讲究,它决定了你是要定义包还是展开包
1. 声明处的 ...(打包)
位于类型名左侧,表示我们要接收一堆参数
-
typename... Args
-
Args... args
2. 使用处的 ...(解包)
位于参数包名的右侧,表示将这个包在这里原地解开,变成以逗号分隔的参数序列。
- func(args...) 展开为 func(arg1, arg2, arg3)
2. 非递归展开(逗号表达式与初始化列表)
递归展开虽然直观,但它有一个致命弱点:编译器需要为每一层递归生成一个新的函数实例。如果参数非常多,编译压力会显著增大
方式二的核心思想是:利用数组初始化列表必须逐个初始化其元素的特性,强制编译器在一行代码内把参数包解开
我们先看这个看似古怪的语法:
cpp
template <class T>
void printItem(T t) {
cout << t << " ";
}
template <class... Args>
void ShowList(Args... args) {
int dummy[] = { (printItem(args), 0)... };
cout << endl;
}
ShowList(1, "A", 3.14);这里包含了两个核心语法点:
1. 逗号表达式 (exp1, exp2)
逗号表达式会先执行 exp1,然后丢弃其结果,返回 exp2 的结果
-
在我们的代码中:(printItem(args), 0)。编译器会先执行 printItem(args),然后把 0 存入数组
-
为什么要写个 0? 因为数组 int dummy\[\] 需要 int 类型的值,而 printItem 可能返回 void。我们需要一个统一的返回值(比如 0)来填充数组。
2. 模式展开 (pattern)...
... 会把左边的整个括号内容看作一个模式进行展开
当我们传入
cpp
ShowList(1, "A", 3.14)这一行会被编译器展开为:
cpp
int dummy[] = { (printItem(1), 0), (printItem("A"), 0), (printItem(3.14), 0) };如果你觉得声明一个没用的 dummy 数组很别扭,我们可以直接利用 std::initializer_list 的匿名对象
cpp
template <class T>
void printItem(T t) { cout << t << " "; }
template<class... Args>
void ShowList(Args... args){
// 利用匿名初始化列表展开,(void) 是为了消除 "未使用变量" 的警告
(void)std::initializer_list<int>{ (PrintItem(args), 0)... };
}甚至可以结合 lambda 表达式直接在括号里面写逻辑,不再依赖外部函数:
cpp
template <class... Args>
void ShowList(Args... args) {
(void)std::initializer_list<int>{ ([(args)] { cout << args << " "; }(), 0)... };
}3. C++17 折叠表达式
如果编译器支持 C++17,这种逗号表达式展开被官方正式标准化为折叠表达式,语法非常简单:
cpp
template <class... Args>
void ShowList(Args... args) {
(std::cout << ... << (args << " "));
}核心逻辑
**1. 左侧初始值 (std::cout):**它是折叠的起点。所有的输出最终都要流向这个标准输出流
2. 折叠符号 (...): 告诉编译器在这里展开参数包。... 在 << 中间,表示这是一个连续的链式调用
**3. 展开模式 (args << " "):**这是对包中每一个元素执行的操作。编译器会针对参数包里的每一个 arg,都生成一个 arg << " " 的动作
C++17 规定,折叠表达式必须包裹在一对圆括号中,否则编译器无法识别这种特殊的语法
假设你调用了 ShowList(1, 2, 3);,编译器在底层会把这一行代码横向展开成:
cpp
// 第一步:取出第一个元素
(std::cout << (1 << " "))
// 第二步:把上一步的结果作为左值,继续接第二个元素
((std::cout << (1 << " ")) << (2 << " "))
// 第三步:接第三个元素
(((std::cout << (1 << " ")) << (2 << " ")) << (3 << " "))三. 完美转发在参数包中的应用
在上一篇博客中,我们知道一个右值传进函数后会退化为左值。在可变参数模板中,这个问题会被成倍放大:
如果你有一个参数包,里面既有左值又有右值,你如何把它们原封不动地传给下一个函数?
1. 核心问题与解决方案
假如我们有两个函数
-
**RealWork:**这是核心功能函数。通常提供多个重载版本,分别针对左值和右值进行优化处理,以获得最佳性能。
-
**Wrapper:**这是一个模板包装器。它的存在是为了提供统一的接口,比如日志记录、性能计时,或者像容器一样延迟构造对象
当我们定义 void Wrapper(Args&&... args) 时,即便我们使用了万能引用,在 Wrapper 内部,args 这个参数包里的每一个具体参数都是有名字的左值
如果我们直接调用 RealWork(args...),那么无论外部传进来的是什么,最终调用的都会是 RealWork 的左值版本
解决方案:
要解决这个问题,我们需要在展开参数包的同时,对其中的每一个参数进行完美转发:
cpp
template<class... Args>
void Wrapper(Args&&... args){
RealWork(std::forward<Args>(args)...);
}当我们调用 Wrapper(10, string("hello"), lvalue_var) 时,它会被展开为:
cpp
RealWork(
std::forward<int>(arg1), // 转发右值 int
std::forward<string>(arg2), // 转发右值 string
std::forward<string&>(arg3) // 转发左值引用 string
);2. 语法细节:... 的落点
很多时候我们会纠结 ... 到底放哪。请记住这个准则:想让什么重复,就把 ... 放在什么的后面
-
Args...:重复类型名(定义包)
-
args...:重复变量名(简单解包)
-
std::forward<Args>(args)...:重复转发这一套动作(完美转发解包)
**请注意:**std::forward<Args...>(args...) 是错误的写法,因为这会导致编译器尝试把整个类型包塞进一个 forward 里,这在语法上是讲不通的
在编写简单功能(如打印函数 print)时,完美转发可能并非必需。然而,对于工厂函数、线程包装器或类似 vector::emplace_back 这样的容器接口实现,完美转发则成为性能优化的关键所在
通过这种方式,我们可以将参数包中的右值属性一直保留到对象最终构造的时刻,从而触发移动构造而非拷贝构造
四. emplace 系列接口
在 C++11 之后,几乎所有的 STL 容器(vector, list, deque 等)都新增了 emplace 系列接口
1. push_back 与 emplace_back 的区别
-
push_back:只接收对象。如果你传的是构造参数,它会先利用这些参数创建一个临时对象,然后再把这个对象拷贝或移动进容器
-
emplace_back:这是一种可变参数模板 ,能够接收构造参数包。它将参数包完整传递到容器最底层的存储空间,并就地构造对象
cpp
std::list<string> lt;
// push_back: 必须先有 string 对象
lt.push_back("hello"); // 1. 隐式构造临时对象 2. 移动 / 拷贝构造 3. 析构临时对象
// emplace_back: 直接传构造参数
lt.emplace_back(5, 'a'); // 直接在 list 节点内存里构造 "aaaaa",0 拷贝,0 移动2. 模拟实现:list 的 emplace 接口
为了理解参数包是如何不断往下传递的,我们来看 list 的底层模拟实现。这里的关键点在于:参数包必须在每一层都使用完美转发
第一层:emplace_back 接口
cpp
template<class... Args>
void emplace_back(Args.. args){
// 转发给 emplace,在尾部迭代器处插入
emplace(end(), std::forward<Args>(args)...);
}第二层:emplace 接口
cpp
template<class... Args>
iterator emplace(iterator pos, Args... args){
// 1. 先拿到当前节点
Node* cur = pos._node;
Node* prev = cur->_prev;
// 2. 创建新节点,这里把参数包传给节点的构造函数
// 必须使用完美转发来保持属性
Node* newNode = new Node(std::forward<Args>(args)...);
// 3. 链表链接逻辑
prev->_next = newNode;
newNode->_prev = prev;
newNode->_next = cur;
cur->_prev = newNode;
return iterator(newNode);
}第三层:ListNode 的构造函数
在这里,参数包终于遇到了 T(容器存储的数据类型)的构造函数
cpp
template<class T>
struct ListNode
{
T _data;
ListNode* _prev;
ListNode* _next;
template<class... Args>
ListNode(Args... args)
: _data(std::forward<Args>(args)...) // 完美转发给 T 的构造函数
, _prev(nullptr)
, _next(nullptr)
{}
}3. 为什么 emplace 会更高效
通过上面的模拟实现,我们可以发现 emplace 的设计思想是:延迟构造
-
链路传递:参数包像一个密封的包裹,通过 std::forward 在 emplace_back -> emplace -> ListNode 之间传递
-
原地构造:只有到了最后 _data(std::forward<Args>(args)...) 这一步,包裹才被打开,直接在 _data 的内存空间上调用 T 的构造函数
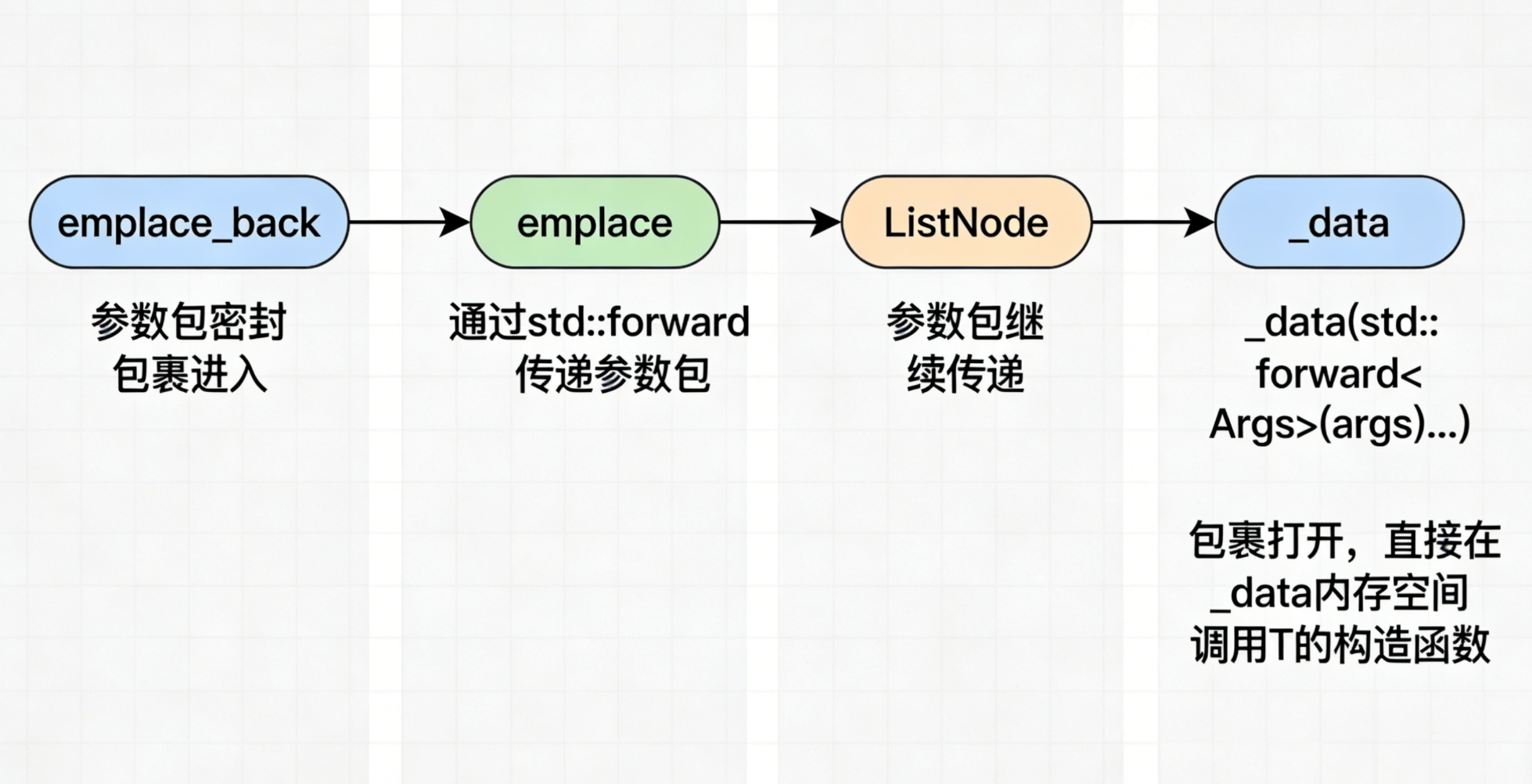
对比总结:
push_back 可能需要搬运
emplace_back 则是省去了搬运的过程
如果在 list 类写了打印语句,你会观察到惊人的区别:
-
调用 push_back(T(args...)):看到 Constructor -> Move/Copy Constructor -> Destructor
-
调用 emplace_back(args...):只看到 Constructor
这就是为什么我们建议:"推荐以后使用 emplace 系列替代 insert 和 push 系列"。它在功能上完全兼容,且在传构造参数时性能上限更高
五. 函数包装器
在 C++ 中,可调用对象的种类繁多:函数指针、仿函数、Lambda 表达式。
这种多样性虽然灵活,但给模板编程带来了麻烦:如果一个模板需要接收一个函数,它的类型该怎么写? 这就是 std::function 和 std::bind 解决的问题
1. std::function
std::function 是一个类模板,它可以包装任何形式的可调用对象,只要它们的参数类型和返回值类型匹配
引入背景
如果没有包装器,下面的三个东西在编译器眼里是完全不同的类型:
cpp
// 1. 函数指针
double add_func(double x, double y) { return x + y; }
// 2. 仿函数
struct add_obj {
double operator()(double x, double y) { return x + y; }
};
// 3. Lambda
auto add_lambda = [](double x, double y) { return x + y; }; 如果你想写一个 map 来存储这些加法函数,你根本无法定义它的 Value 类型。而 std::function 完美解决了这个难题
cpp
#include <functional>
typedef std::function<double(double, double)> func;
std::unordered_map<int, func> mp;
mp[0] = add_func; // 包装函数指针
mp[1] = add_obj(); // 包装仿函数
mp[2] = add_lambda; // 包装 lambda2. std::bind
如果说 std::function 是容器,那么 std::bind 就是一个适配器。它可以把一个函数的参数提前绑定,或者调整参数的顺序,生成一个新的可调用对象
核心思想:
-
固定参数:比如一个函数需要 3 个参数,你可以绑定其中 2 个,让它变成只需要 1 个参数的新函数。
-
调整顺序:利用占位符 std::placeholders::_1, _2 等
cpp
void Sub(int a, int b) { cout << a - b << endl; }
// 绑定第一个参数为 10,_1 表示新函数的第一个参数传给 Sub 的第二个位置
auto sub10 = std::bind(Sub, 10, std::placeholders::_1);
sub10(5); // 等价于 Sub(10, 5),输出 5
// 交换参数顺序
auto subRev = std::bind(Sub, std::placeholders::_2, std::placeholders::_1);
subRev(5, 10); // 等价于 Sub(10, 5),输出 5在实际开发中,std::function 和 std::bind 经常配合使用,最典型的场景就是回调函数和线程池
场景演示:
假设你正在写一个按钮类 Button,你希望点击按钮时能执行某个对象的某个成员函数。但成员函数默认有一个隐藏的 this 指针,类型匹配非常麻烦
cpp
class Player {
public:
void Jump(int height) { cout << "Player Jumped " << height << "m" << endl; }
};
// 按钮的回调接口
std::function<void(int)> onClick;
Player p1;
// 使用 bind 绑定 this 指针,将成员函数转化为普通 function 包装的对象
onClick = std::bind(&Player::Jump, &p1, std::placeholders::_1);
onClick(2); // 输出:Player Jumped 2m实战案例:LeetCode 155. 逆波兰表达式求值
题目描述:
给你一个字符串数组 tokens ,表示一个根据逆波兰表示法表示的算术表达式。请你计算该表达式。返回一个表示表达式值的整数
示例1:
输入: tokens = "2", "1" , "+" , "3" , "\*"
输出: 9
**解释:**该算式转化为常见的中缀算术表达式为: ((2 + 1) * 3) = 9
示例2:
输入: tokens = "4", "13" , "5" , "/" , "+"
输出: 6
**解释:**该算式转化为常见的中缀算术表达式为: (4 + (13 / 5)) = 6
核心思路:
-
建立一个从"运算符字符串"(如 "+")到 "运算逻辑"(包装好的函数)的映射表 std::map<string, std::function<...>>
-
将 "遍历栈的操作" 与 "具体的数学运算" 分离
-
无论是什么运算符统一通过 mapop(left, right) 调用,无需关心内部是 Lambda 还是普通函数
代码演示:
利用 std::function 配合 Lambda 表达式,代码可以做到非常精简:
cpp
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
// 核心:使用包装器统一定义运算符逻辑
unordered_map<string, function<int(int, int)>> opFuncMap = {
{ "+", [](long long a, long long b) { return a + b; } },
{ "-", [](long long a, long long b) { return a - b; } },
{ "*", [](long long a, long long b) { return a * b; } },
{ "/", [](long long a, long long b) { return a / b; } }
};
for(const string& s : tokens)
{
// 如果在 map 中找到了该运算符
if(opFuncMap.count(s))
{
int right = st.top(); st.pop();
int left = st.top(); st.pop();
// 通过包装器直接调用,消除了繁琐的 switch-case
st.push(opFuncMap[s](left, right));
}
else
{
// 如果是数字,直接转换入栈
st.push(stoi(s));
}
}
return st.top();
}
};复杂度分析
-
时间复杂度:O(N)
-
遍历整个 tokens 数组需要 O(N)
-
在 unordered_map 中查找运算符的时间复杂度为 O(1)
-
-
空间复杂度:O(N + M)
-
栈 st 最多存储 O(N) 个操作数
-
unordered_map 存储了 M 个包装器对象
-
该方案遵循开闭原则 (OCP):如果题目以后增加了求幂 (^) 或取模 (%) 运算,我们只需要在 unordered_map 里增加一行初始化代码,而不需要修改核心循环逻辑
总结
总结来看,C++11 的可变参数模板与 STL 扩展机制,本质上是一场围绕"解耦"与"效率"的革新。可变参数模板打破了形参个数的限制,完美转发保证了参数属性的正确传递,而 emplace 则通过就地构造消除了不必要的拷贝开销。与此同时,std::function 与 std::bind 统一了可调用对象的抽象,使逻辑的组织更加灵活
从底层语法层面的参数包机制,到高层应用中的复杂表达式构建,这一系列特性共同构成了现代 C++ 泛型编程的重要基石。它不仅让代码更加简洁与通用,也使开发者能够在保持抽象性的同时获得接近底层的执行效率
当真正掌握这些机制之后,开发者将不再依赖冗余的函数重载与重复的拷贝逻辑,而是能够以更高层次的抽象方式组织代码,在泛型编程的复杂场景中从容应对
