随着国产芯片与 ARM 生态的快速发展,如何在 ARM 平台上构建高性能存储基础设施成为技术焦点。Linaro 是一个专注于 Arm 生态和开源软件的国际化技术组织,联合产业链上下游厂商解决共性问题,并协助企业客户在开源基础上完成产品化落地。Linaro 团队在 MLPerf Storage 测试中,对 JuiceFS 社区版(元数据采用 Redis)进行了系统压测,覆盖多种典型机器学习训练负载。
测试结果显示,系统性能在很大程度上受内存带宽和元数据访问效率影响,JuiceFS 的吞吐能力直接决定 GPU 利用率及训练效率。通过 UNet3D、ResNet-50 和 CosmoFlow 等负载的测试,分析发现:单机场景下,GPU 利用率主要受内存拷贝延迟限制;在双机或多机场景下,元数据访问和节点间同步成为主要瓶颈。文章同时提供了针对这些瓶颈的调优思路与实践结果。
总体来看,大规模 AI 训练性能调优是一个系统工程,需要从存储系统、内存带宽、CPU 调度、缓存策略等多方面协同优化,才能在 ARM 平台上实现高效的深度学习训练数据供给。
01 Arm64 与 x86_64 架构差异与并发特性概述
相比 x86,Arm 的应用范围不断扩大,已从移动端延伸至 IoT、可穿戴设备、PC、汽车和服务器,其高能效比(performance per watt)是广泛采用的关键原因。
从架构设计上看,Arm 属于 RISC(Reduced Instruction Set Computer,精简指令集计算机),x86 属于 CISC(Complex Instruction Set Computer,复杂指令集计算机)。这种设计差异也影响了处理器的执行方式。Arm64 的指令长度固定为 4 字节,而 x86 指令长度可变,大约在 1--15 字节 之间,因此 x86 往往需要更复杂的译码器。相比之下,Arm 的指令更简洁,也更依赖编译器和代码生成阶段对指令的有效组织,所以需要更长的编译时间。
从工程师可感知的角度来看,还有一些架构差异会直接影响程序行为。很多在 x86 上看起来符合直觉的代码,在 Arm 上未必如此,后面要讲到的几个容易踩坑的点,基本都与这些底层差异有关。
其中一个典型问题是原子操作对地址对齐有要求。无论是 LL/SC(Load-Link/Store-Conditional),还是 LSE(Large System Extensions),在执行原子加减等读改写操作时,通常都要求访问地址满足对齐条件。较新的 LSE2 对这一限制有所放宽,开始支持 16-byte window 内的非对齐访问。数据对齐对于 x86 来说不是必须的,但保持良好对齐有助于提升性能。参考文档: Arm Architecture Reference Manual for A-profile architecture
另一个需要重点关注的特点是,Arm 采用的是弱内存序模型(weakly ordered / relaxed memory model),差别体现在对内存访问顺序的约束强弱不同。在多线程场景下,同样的读写操作,在 x86 上通常更容易表现为接近程序书写顺序,而在 Arm 上则允许更多重排序,因此其他线程观察到的读写顺序可能与源码顺序不一致。在 Arm 上出现的异常需要特别考虑内存序的影响。更多细节可参考 Arm 白皮书:Synchronization Overview and Case Study on Arm Architecture。
02 JuiceFS 与 MLPerf 概述
JuiceFS 是一款开源高性能分布式文件系统,基于对象存储构建,在充分利用对象存储低成本优势的同时,提供接近传统文件系统的使用体验。它支持 POSIX、HDFS SDK、Python SDK 以及 S3 兼容接口,并能适配不同类型的应用和数据处理框架;同时支持云原生扩展、数据安全与压缩,可广泛应用于 AI 训练、推理、大数据处理等场景。
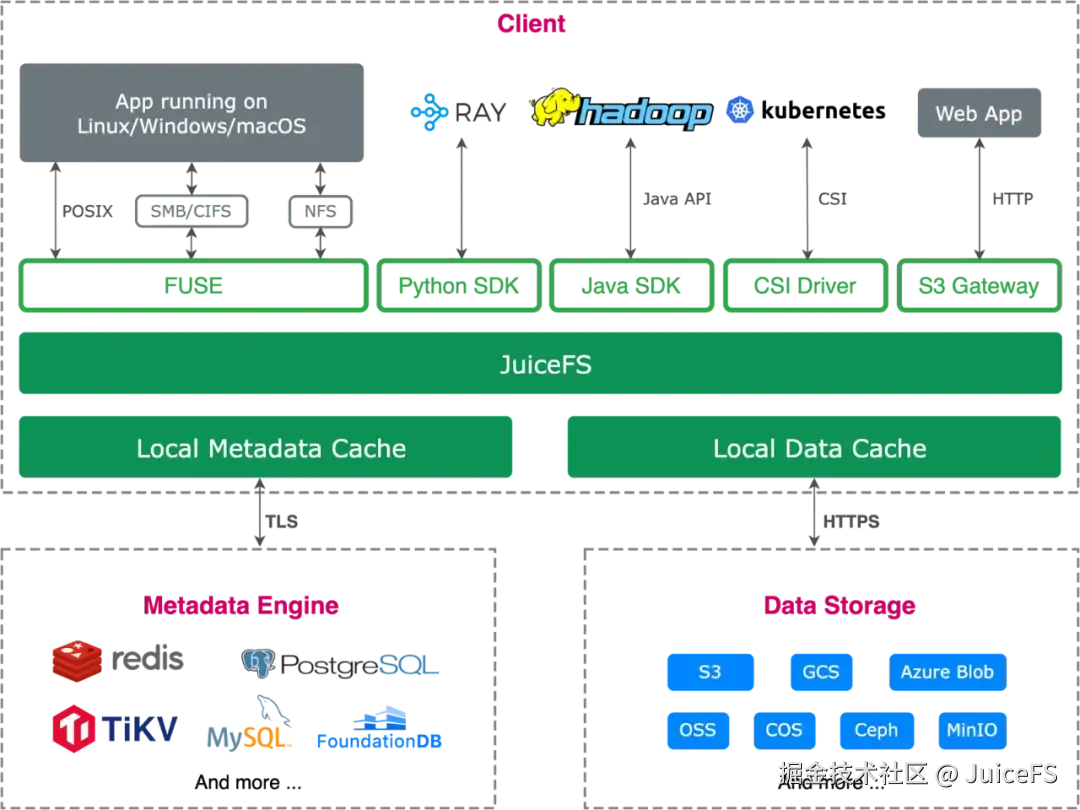
为评估 JuiceFS 在 AI 训练等高负载场景下的数据供给能力,可采用 MLPerf Storage 基准测试。该测试由 MLCommons 开发,重点衡量存储系统能否持续高效向计算侧提供数据。
2.0 版本将测试分为训练负载和检查点负载两类,其中训练负载包括 3D U-Net、ResNet-50 和 CosmoFlow,三者在样本大小和访问特征上存在显著差异,并设置了最低 GPU 利用率要求:3D U-Net 与 ResNet-50 为 90%,CosmoFlow 为 70%。
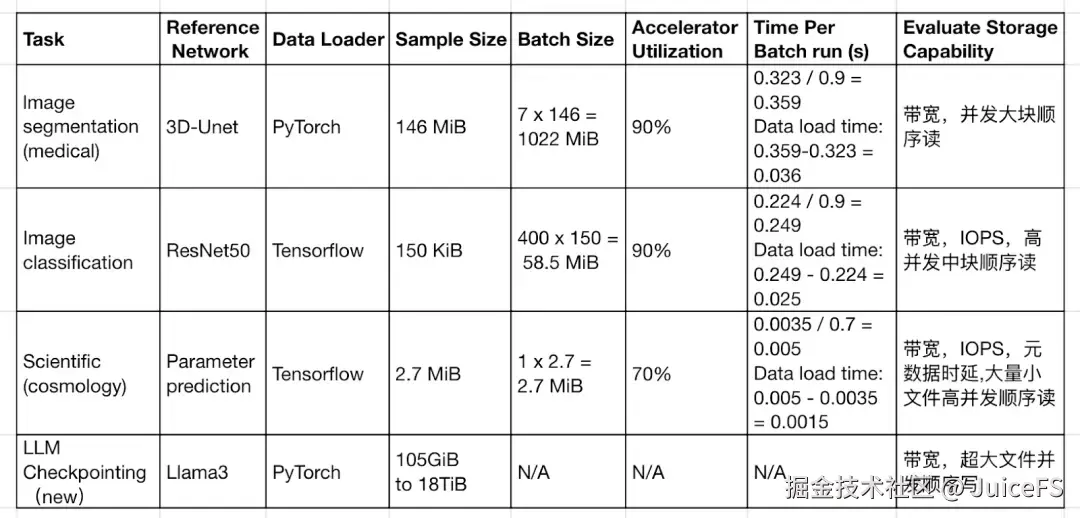
在测试流程中,数据首先从存储系统读入主机内存,再进入计算阶段。训练耗时由模拟方式复现,以模拟真实训练场景的数据流,从而无需实际部署 GPU,降低实验门槛并提升操作便利性。
03 MLPerf Storage v2.0 测试原理与调优
在介绍具体的模型测试结果之前,需要先了解分布式训练的数据访问原理,有助于读者明白 GPU 利用率、存储吞吐和性能瓶颈的成因,从而更好地理解后续的测试结果和调优策略。
分布式机器学习通常采用数据并行方式,即多个并行进程共享同一数据集,每个进程分别负责读取和处理对应的训练批次。
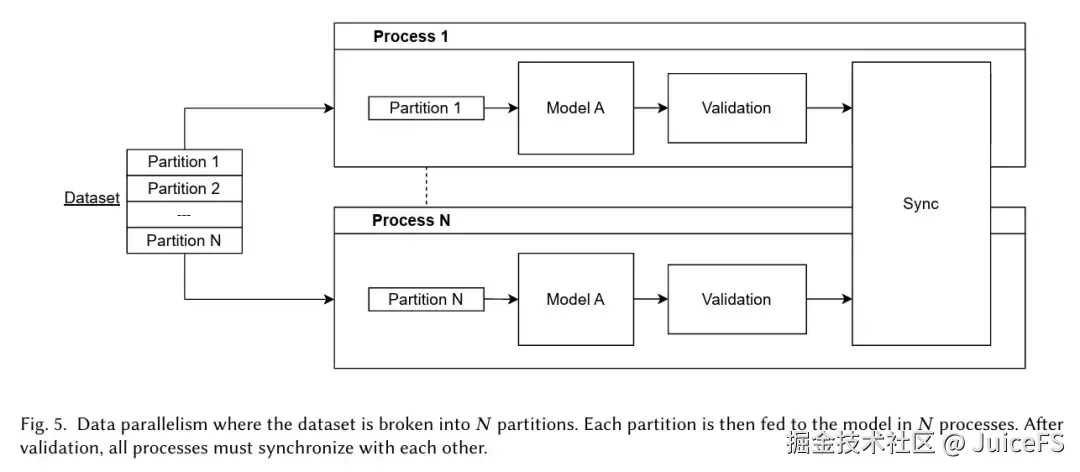
MLPerf Storage 的训练测试也遵循这一思路,每个训练进程按批次从存储系统读取数据,并通过模拟计算来评估存储系统的持续供数能力。
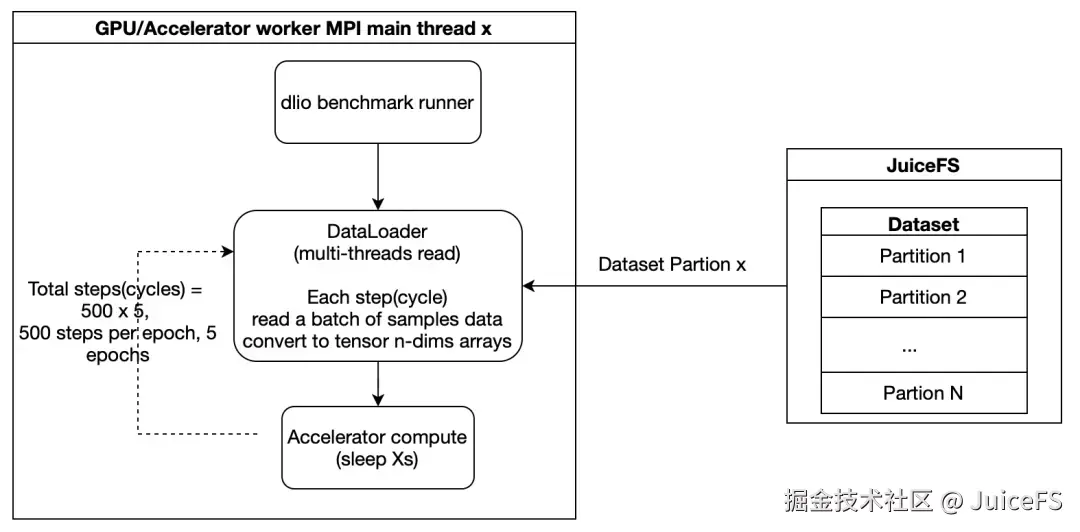
为了理解测试中性能表现的来源,还需要理解 JuiceFS 客户端的数据处理链路。使用 JuiceFS 进行测试时,如图所示,其执行流程大致可分为三部分。
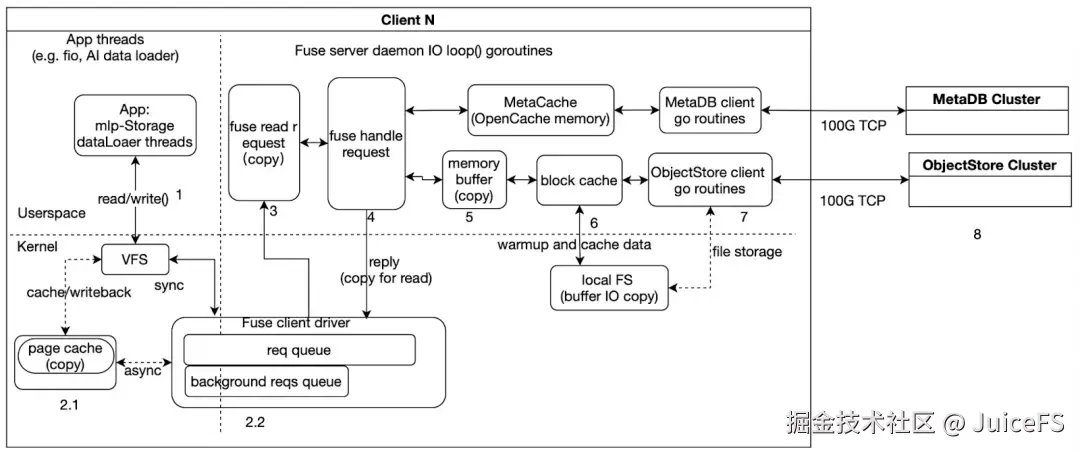
- 左侧:应用侧 I/O 线程,例如
fio或 MLPerf Storage 的DataLoader线程,负责发起read/write请求并等待请求完成。 - 中间:FUSE 守护进程中的请求处理主
goroutine,负责接收并处理来自内核态的 FUSE 请求,将文件数据放入内存缓冲区和缓存,并触发后端元数据与对象存储访问。 - 右侧:Meta client 和 ObjectStore client 的异步
goroutine,负责与后端 MetaDB 和 ObjectStore 集群进行数据与元数据交互。
从性能分析的角度看,这条链路需要重点关注两类问题。第一类是数据拷贝,对应图中的 2.1、3、4、5、6 等步骤,这些位置都会带来额外的内存复制开销,因此往往是分析延迟和 CPU 开销时的重点。
第二类是同步与异步边界。从图中可以看出,1、2、3、4、5、6 这些步骤总体属于同步路径,也就是请求发起后,需要等待当前阶段完成才能继续向下推进;而 7 属于异步路径,由后台 goroutine 负责与后端存储交互。
测试 1:Unet 3d
在这个测试中,样本为 146 MiB 的图像文件,我们主要关注大块数据的读取性能。测试结果显示:
- 单机环境下最高可稳定运行 5 块 GPU,GPU 利用率约为 50%,
- 而双机场景可支持 10 块 GPU,GPU 利用率同样约为 50%。
为了提升数据读取效率,对训练参数进行了优化:将 reader 并发线程数从 4 调整为 16,以加快数据生成速度,并将数据读取方式改为 direct I/O,以减少缓冲区和内存拷贝开销。
业务指标显示,当单机挂载 6 块 GPU 时,GPU 利用率仅为 83%,对应带宽约为 15.1 GB/s,未达到预期的高利用率目标 。进一步使用 FIO 对存储侧进行测试后发现,其带宽同样约为 15.1 GB/s,说明此时系统瓶颈已经落在 JuiceFS 客户端带宽 上,而不是 GPU 计算侧本身。
优化分析 1:绑定 CPU
为了深入分析客户端带宽受限的原因,我们对进程进行了 CPU 绑定,将其固定在 CPU1(NUMA 2、3 节点)运行。通过工具观察,48 个 CPU 核心几乎全部占满,进一步分析 top-down、memory 和 miss 指标发现,系统表现出明显 Memory Bound,主要耗时集中在内存拷贝上。这说明,在 CPU 绑定场景下,JuiceFS 性能瓶颈主要来自 CPU 处理能力和跨 NUMA 节点内存拷贝带来的额外延迟。
优化分析 2: 不进行 CPU 绑定
为了理解系统在更通用条件下的带宽限制,我们进一步观察了不绑定 CPU 的情况。通过观察可以看到,CPU 并未被完全用满,但 devkit tuner numafast 指标显示,系统中的 remote 内存访问比例高达约 80%。这意味着,大量内存访问已经跨越本地 NUMA 节点,甚至可能跨越 CPU socket,从而引入了显著的带宽损失和访问时延。
从硬件带宽特性看,跨片内存访问本身就存在明显限制。例如,在 Arm 平台上,跨 socket 的理论物理带宽约为 60 GB/s;进一步通过实测,跨片 copy 带宽在 Arm1 上约为 48 GB/s,而在两组 x86 平台上分别约为 37 GB/s 和 28 GB/s。
这说明,在不绑定 CPU 的情况下,虽然计算核表面上没有被完全耗尽,但大量跨节点、跨 socket 的远端内存访问已经成为新的主要开销来源。因此,可以推测,此时 JuiceFS 带宽无法继续提升,很可能并不是单纯受限于 CPU 算力,而是受限于跨片内存访问的带宽与时延。换言之,系统瓶颈已经从"本地 CPU 忙不过来"转移为"远端内存访问代价过高"。
综合来看,在两种场景下,JuiceFS 带宽无法提升的原因并不相同:
- 绑定 CPU 时,主要受限于 CPU 资源消耗以及大量内存拷贝带来的访问开销;
- 不绑定 CPU 时,主要受限于高比例 非本地内存访问,尤其可能是跨 socket 访问带来的带宽和时延损失。
测试 2:Resnet50
ResNet-50 测试的单个样本较小,单个样本大小约为 150 KiB,每个 batch 包含 400 个样本,每个 batch 的总数据量约 58.5 MiB。本次 I/O 测试关注 GPU 高并发下的数据加载效率及训练吞吐。测试显示系统可在大规模 GPU 下维持较高利用率:
- 单机:50 块 GPU,GPU 利用率 95%,带宽约 9.2 GB/s
- 双机:96 块 GPU,GPU 利用率 90%,带宽约 16.9 GB/s
在测试过程中,我们将关键参数 reader.read_threads 从 8 调整为 1,对于该模型(中等大小的图像模型),单线程即可满足数据供给需求。
优化分析 1: 单机性能瓶颈与内存带宽影响
在单机配置 55 块 GPU 时,GPU 利用率下降至 86%,带宽仍为 9.2 GB/s,表明系统瓶颈已转移至 JuiceFS 客户端带宽。
进一步分析发现,ResNet-50 测试采用 Buffer I/O 模式,除了读取数据外,处理数据集时的 内存拷贝会消耗一部分内存带宽。
系统内存拷贝带宽受内存通道数、内存频率及 CPU 频率影响。通过对多台配置不同的机器进行 stream 测试,得到的单机顺序读带宽与系统内存带宽测得的可比带宽一致,表明读数据吞吐能力在很大程度上取决于系统内存带宽。对于需要高吞吐、高 GPU 利用率的训练任务,建议优先选择内存带宽较高的机型,可显著提升数据供给能力和训练效率。
| 单 CPU 内存拷贝带宽数据 | JuiceFS 单机部署读带宽 | |
|---|---|---|
| Arm3 | Arm3: 171 GB/s | 25.3 GiB/s |
| Arm2 | 114 GB/s | 21.6 GiB/s |
| Arm1 | 106 GB/s | 18.3 GiB/s |
| x862 | 90 GB/s | 17.9 GiB/s |
| x861 | 82 GB/s | 16.6 GiB/s |
优化分析 2:双机扩展瓶颈与分布式限制
在多节点部署中,除了单机性能限制外,跨节点内存访问、网络传输和元数据延迟会成为新的瓶颈,因此在单机分析之后进行双机测试,有助于识别这些分布式约束并指导系统优化。
在双机场景下,理论上可以支持 100 块 GPU,但实际测试中只能达到 96 块 GPU。通过分析发现,每个操作的读取延迟有所增加。尽管文件数据已缓存在本地盘上,元数据访问延迟仍然成为主要限制因素。
为解决这一问题,对系统进行了多方面优化:
- 将 CPU 核心分组,保证训练线程与 I/O 线程在同一 NUMA 节点上运行。
- 将纯数据处理和元数据访问分别分配到不同 CPU 核心和存储路径上。
- 调整 Redis 缓存和本地缓存策略,减少高并发访问元数据时的延迟。
经过上述调优后,双机场景能够稳定支撑 100 块 GPU 运行,GPU 利用率达到预期水平。
测试 3:cosmoflow
与之前的模型相比,这个模型的单样本数据量更小,这也意味着对 I/O 和元数据访问的要求更高。在单机和双机场景下,CosmoFlow 测试显示:
- 单机:最高稳定 10 块 GPU(偶尔可撑到 12 块 GPU),GPU 利用率约 75%,带宽约 5.6 GB/s
- 关键参数调整:将
reader.read_threads从 4 调整为 1,每次读取 batch 数据量为 2 MiB,单线程即可满足数据供给需求。
优化分析 1:单机瓶颈:内存拷贝限制 GPU 利用率
当尝试增加 GPU 数量超过 10 块时,发现 GPU 利用率下降。分析日志和性能数据后发现:
- 数据读取时间增加,而元数据访问延迟变化不大。
- 文件数据已缓存在本地盘上,磁盘队列未满,延迟也不高,因此瓶颈不在存储设备。
- 使用性能分析工具观察发现,关键瓶颈操作主要集中在 内存拷贝(memcopy),数据读取流程中多次拷贝操作的延迟累积,导致整体读取时间增加。
由此推测,当系统使用更多内存带宽时,内存拷贝延迟成为限制读取性能和 GPU 利用率的主要因素。
优化分析 2:双机瓶颈:分布式同步与元数据延迟
在双机场景下,尝试 20 块 GPU 时,第一轮测试 GPU 利用率明显偏低。进一步分析发现:
- 一台机器已开始训练,而另一台机器仍在进行 Dataset 预处理,包括读取文件列表和分片操作。
- 由于 CosmoFlow 数据量较大,高索引文件的读取耗时较长,导致两台机器未能同步开始训练,第一轮 GPU 利用率下降。
为解决该问题,在代码中加入同步机制,确保所有节点在开始训练前完成 Dataset 预处理。经过该调整后,双机测试能够稳定支撑 20 块 GPU,GPU 利用率达到预期水平。
04 总结
首先,MLPerf Storage 通过不同样本、文件和 batch 大小的组合,考察文件系统的各项能力,包括大中小块顺序读能力、文件并发性能、总读带宽、元数据访问时延、文件读取时延以及文件操作的稳定性。在只读文件场景下,充分利用高速近端缓存(包括原数据和元数据缓存)可以显著提升读取性能。需要注意,文件越小,对 IOPS 和延迟的要求越高。
其次,我们发现系统的内存和带宽对性能影响显著。在 Memory copy 密集型的应用中,内存拷贝不仅消耗内存带宽,同时也占用 CPU,表面上会出现"CPU 忙"的假象,实际上 CPU 大部分时间是在等待数据。测试结果显示,系统内存带宽对 JuiceFS 的吞吐能力有决定性影响,这也为选择服务器提供了参考标准:内存带宽越高的系统,其存储吞吐性能也越好。
第三,Go 运行时对 NUMA 的感知有限,对于大规模 CPU 核心运行场景,性能可能不如小规模核心运行。对于多 NUMA 系统,应尽量避免跨 NUMA,尤其是跨 CPU socket 的访问,因为跨 socket 内存带宽通常较低(约几十 GB/s),会增加延迟并影响整体性能。因此,实际部署时只需要分配足够的 CPU 核心即可,无需过度使用全部核心,以避免额外的内存访问延迟。
第四,在系统层面还有一些潜在优化点。例如,对于 Memory copy 密集的操作,部分 Arm 新系统提供了针对内存访问的指令优化,我们与 Arm 社区合作,将配置提升推送到社区中,新系统可以显著提升内存拷贝效率,在部分场景中带宽提升可达数十个百分点。
此外,对于涉及大量内核与用户态交互的操作,例如文件读写和元数据处理,可以通过优化用户态与内核态的交互,减少不必要的调用次数,从而降低延迟。实践中也发现,将文件处理尽量集中在同一生产节点内,避免跨 NUMA 或跨 socket 的访问,可以进一步提升性能和稳定性。
最后,系统配置优化也体现在缓存策略上。例如,在单机高负载场景下,通过调整 JuiceFS 的内存缓存策略,减少无效内存带宽占用,可以有效提高 GPU 利用率和存储吞吐。整体来看,MLPerf Storage Benchmark 是一个系统工程,需要文件系统、内存带宽、CPU 调度和缓存策略等多方面配合,才能达到最优性能。
我们希望本文中的一些实践经验,能为正在面临类似问题的开发者提供参考,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。