混合精度训练是一种可以大幅加速模型训练,并且减少显存占用,同时又不影响模型精度的技术。目前已经是大模型训练的默认配置。今天我们就来全面了解这项技术。
一、数据表示
首先我们先来了解一下计算机是如何表示float 32位类型的数据的。比如22.5这样一个十进制数在计算机里面是如何表示的呢?我们知道计算机里是以二进制来存储数据的。首先我们把22.5转化为它的二进制表示形式,它为10110.1。接着我们以科学计数法来表示,因为是二进制,这里转化为1.01101乘以2的4次方。
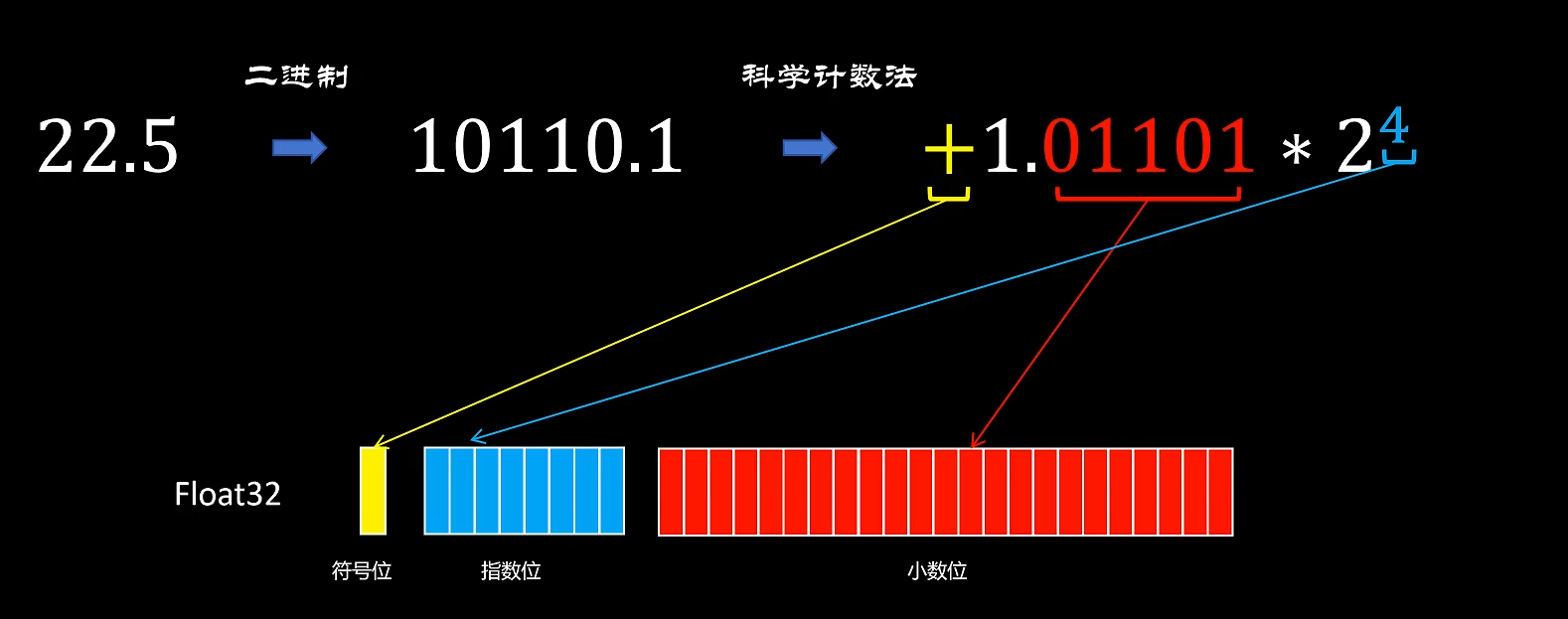
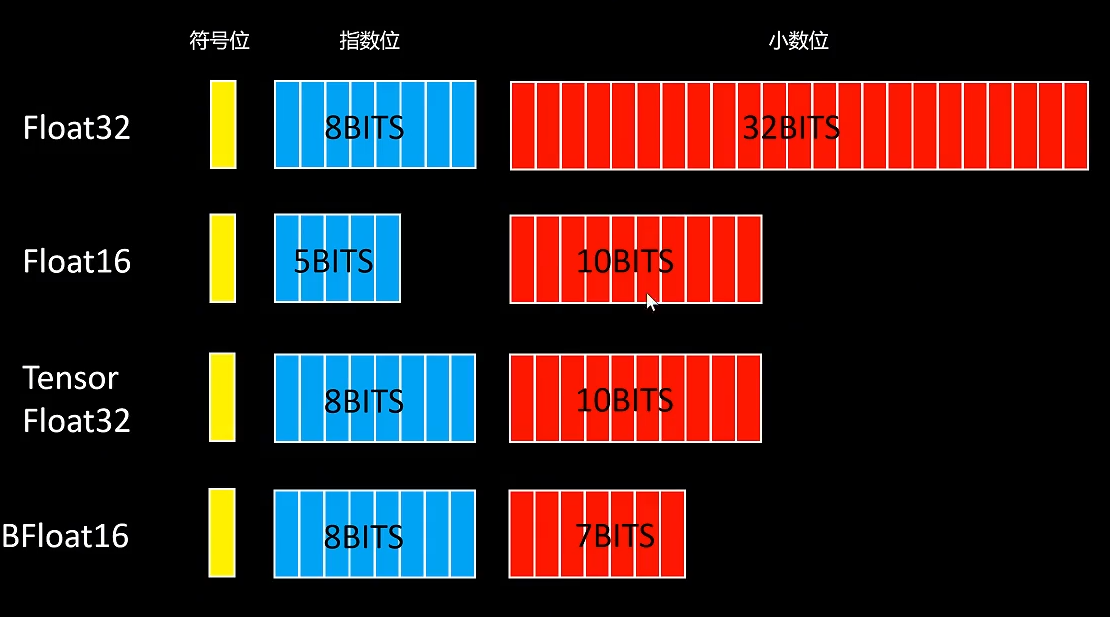
float 32,顾名思义,它用32个二进制位来表示一个浮点数。第一位是符号位,然后是八位的指数位。这里我们把指数四转化为二进制后存入,最后是23位小数位,我们将二进制的小数位存入,除了float 32还有float 16。它同样有一个符号位,指数位减少到了五位,小数位减少到了十位,同样还有Tensor float 32位,Bfloat 16位等。
二、低精度训练的优缺点
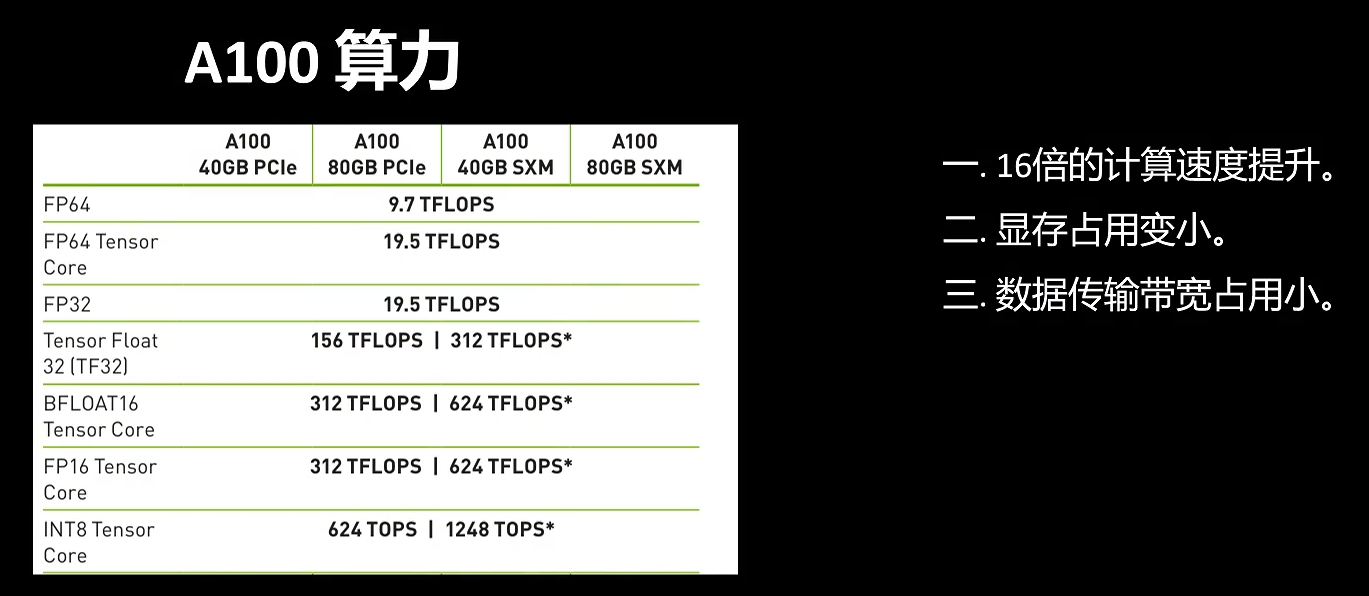
低精度计算在模型训练时可以给我们带来哪些好处呢?我们以A100的算力来看,它的FP32,也就是flow的32位的计算算力为19.5t flops,但是FP16的算力为312t flops,提升了16倍。第二点,因为float 16所占的存储只有float 32的一半,所以显存占用也会变小。还有第三点也很重要,就是在混合精度计算时,中间的激活值参数梯度都用float 16来表示。在显存和tensor core之间传输时,对显存带宽的占用也简单,所以这也可以加速模型的训练。
低精度训练可以带来这么多好处,那它有什么缺点吗?当然第一点就是表示范围的问题,它表示不了太大和太小的值。因为在神经网络训练时,一般都是绝对值很小的值,可能会导致有的参数和梯度因为太小向下溢出,从而变为零的情况。
第二点就是flow的十六数据,因为表示范围有限,在进行计算时会出现出现大数吃小数的情况。什么是大数吃小数呢?举一个例子,你在pytorch里面,如果用float 16的2048加上一个float 16的0.5,它的结果还是2048,0.5这个小数就被2048这个大数吃掉了,这是什么原因呢?2048转化为二进制,科学计数法表示为1.0乘以2的11次方。0.5转化为二进制,科学计数法表示为1.0乘以10的负1次方。这两个数相加时,小的数要转化为和大的数一样的指数表示,也就是要表示成一个数和2的11次方相乘,然后转化后的这个小数部分就成为1.0乘以2的负12次方。

我们刚才学过float 16的小数位只有十位,它无法表示就向下溢出为零了,导致0.5这个小数被2048这个大数吃掉。所以我们自然就想到能不能通过混合精度来结合高精度和低精度的优点呢?在需要高精度时用float 32,在不需要高精度的地方用float 16呢?这就是混合精度训练要解决的问题。
三、混合精度训练
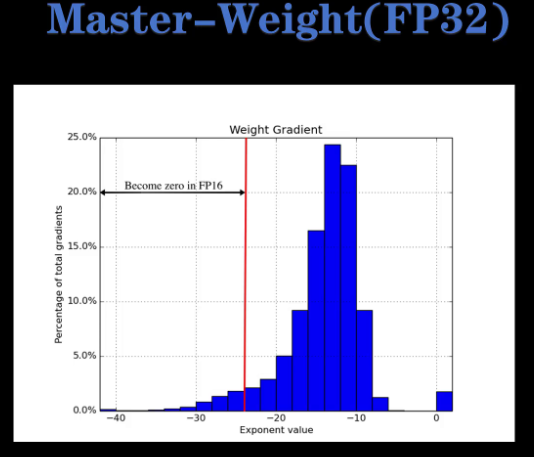
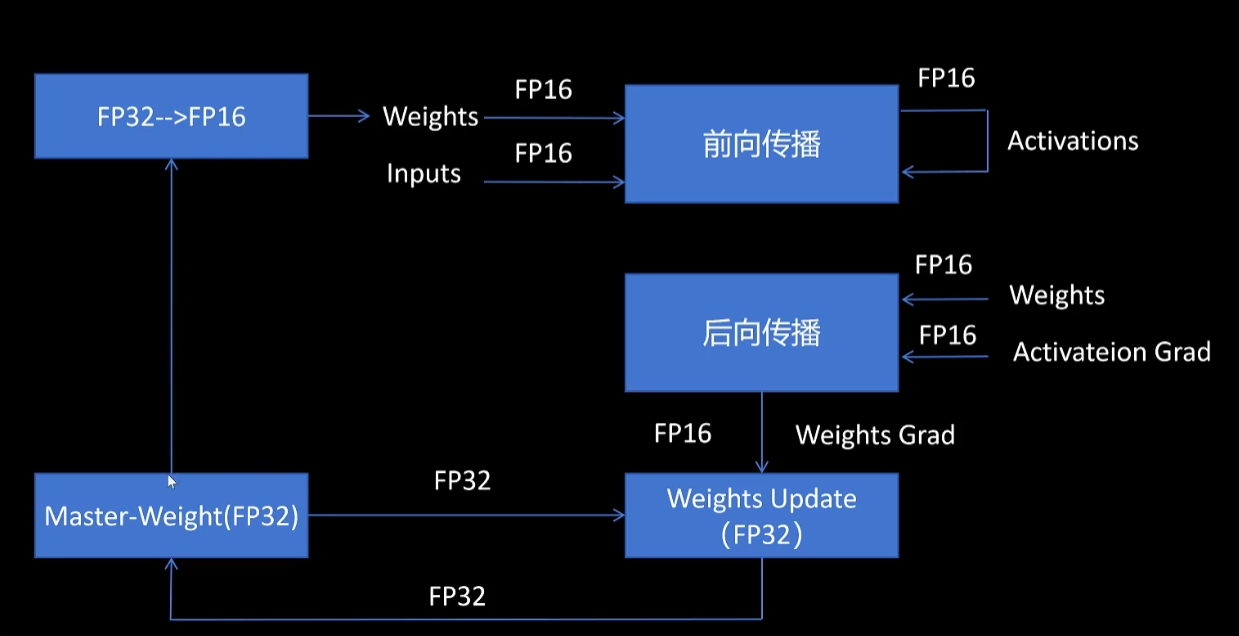
神经网络里大部分的计算都是在float 16下进行,但是优化器会同时保存一份float 32的参数值,叫做master weight。这是为什么呢?首先我们看这张图,这是在一次更新时所有的梯度值。可以看到有一部分的梯度值在flow的16精度表示范围之外,这些值的绝对值都很小。梯度更新时如果在float 16下进行,就会下溢为0起不到参数更新的作用。
还有一点就是我们刚才所说的大数吃小数的问题。因为参数值相对于梯度来说都很大,如果用float 16来表示,就会有参数值吃掉梯度值的问题。所以我们需要用float 32来保存一份模型的参数值。
3.1 master weight
我们看一下整个训练过程。首先我们在优化器里保存了一份master weight,它是32位的。然后我们把它转化为16位,同样把input也转化为16位,在16位下进行网络前向传播,中间的激活值也是16位的。然后进行后向传播时,计算的梯度也是16位的。16位的梯度被传入优化器,优化器会将梯度转化为32位,再来更新32位的master weight,然后开始下一轮训练。
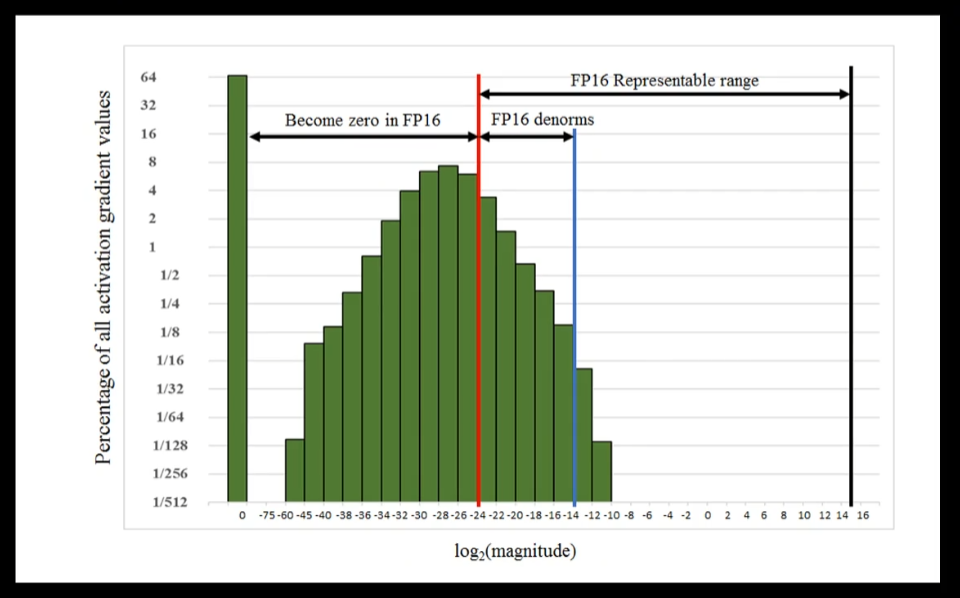
第二个需要改动的是,我们发现梯度大部分绝对值都很小。在float 16位精度表示的范围之外,比如图里所示,这一部分都是float 16表示范围之外的。但是同时float 16还有很大一部分没有被用到,没有被用到的部分都是数据比较大的部分。因为一般梯度值都很小,所以比较大的数据范围都没有被用到。那么我们可以对梯度进行缩放,把它移动到float 16可以表示的范围内。
3.2 Loss Scaling
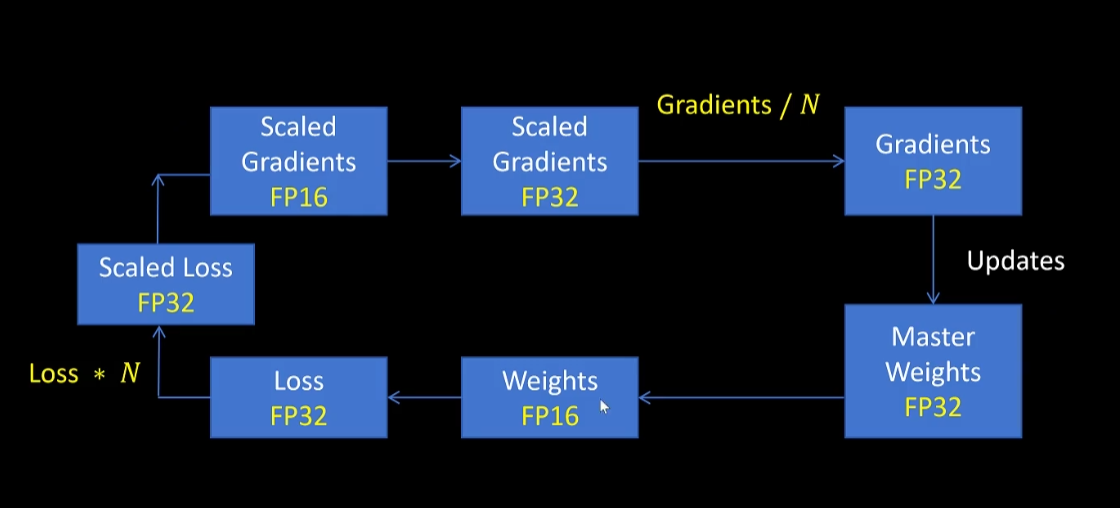
我们看一下具体过程,首先是模型里16位的参数进行前向传播计算。但是loss函数的计算是float 32位的。得到一个float 32位的loss,然后对loss进行缩放乘以N倍,这样就得到了一个缩放后的loss。然后将缩放后的loss转化为float 16进行梯度计算。因为loss经过缩放,所以得到的缩放梯度虽然是以float 16表示,但是不会精度溢出。在进行梯度更新时,我们把缩放后的梯度转化为32位,在除以之前对loss进行缩放的N这样就得到了真实的float 32位表示的梯度值了。接着用32位的梯度值更新32位的master weight就完成了一次训练。然后再将master weight转化为float 16,给模型参数进行下一次训练。
最后还要对其他一些需要保持高精度的计算进行float 32位的计算。比如这里我们看在pytorch里进行自动混合精度计算时,有的操作默认是float 16的,这里包括我们常见的线性层、卷积循环神经网络等。但是还有一些操作需要在float 32位下进行,一般都是loss函数,或者需要进行累加的操作,比如sum,因为在累加过程中,随着累加值的变大,就会出现大数吃小数的情况。一般处理的方式是矩阵乘法,在float 16位下进行,但是进行累加计算时,转化为float 32,计算完成后,再把计算结果转化为float 16位。