1.2 深度学习核心概念:神经网络直觉理解
不讲公式,只讲直觉。
本文适合谁:对"神经网络"这个词感到神秘的读者,以及想理解"为什么深度学习这么厉害"的零基础程序员。读完这篇,你会对神经网络是什么、为什么能学习、为什么叫"深度"、以及为什么AI需要GPU,有清晰的直觉理解------不需要看一行数学公式。
本文阅读时间:约13分钟
为什么要理解神经网络?
你可能会问:我只是想写Agent应用,学这么底层的东西有必要吗?
答案是:不需要深入,但需要有感觉。
就像你开车不需要懂发动机原理,但如果知道"发动机冷的时候油耗高""急加速最耗油",你就能更聪明地用车。
神经网络的直觉理解,能让你:
- 明白为什么LLM会"幻觉"(不是bug,是结构性特点)
- 理解为什么模型越大越贵(参数越多,计算量指数级增长)
- 理解为什么Embedding能做语义搜索(向量空间的几何性质)
- 在遇到模型性能问题时,能判断是数据问题还是模型问题
好,开始。
神经网络到底是什么?先别被名字吓到
"神经网络"这个名字听起来很高深,但它其实只是一个数学函数。
输入一些数字,经过一堆计算,输出另一些数字。
就这么简单。
那为什么叫"神经网络"?因为它的设计灵感来自大脑。
1943年,神经生理学家 Warren McCulloch 和数学家 Walter Pitts 发表了一篇论文,第一次用数学公式描述了神经元的工作方式------他们发现,大脑里的神经元就是在做"接收信号、超过阈值就激活、向下传递"这样的简单操作。这个洞察催生了人工神经网络的想法:用数学节点模仿神经元,把它们连接成网络,看能不能让计算机也"学习"。
但这只是灵感来源,不是真的在模拟大脑。神经网络不理解这个世界,它只是在做大量的数学运算。
理解神经网络,你只需要搞清楚三件事:
- 它长什么样?(结构)
- 它怎么"学习"?(训练过程)
- 为什么层数多了("深度")就更强?
神经网络长什么样?
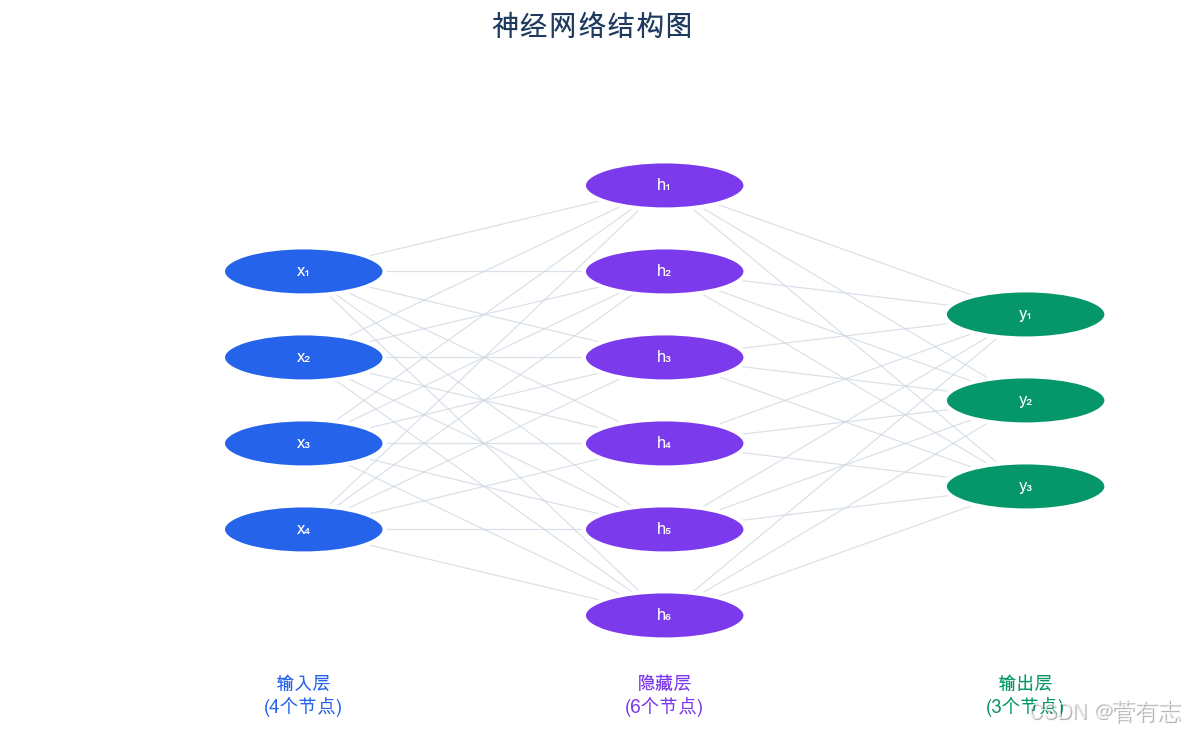
图2.2:神经网络结构:输入层、隐藏层与输出层
按照AWS的定义:神经网络使用类似于人脑的分层结构中的互连节点或神经元。 它由三种层组成:
输入层 → 隐藏层1 → 隐藏层2 → ... → 输出层用一个具体例子来理解:假设我们要训练一个神经网络,判断一张图片里是猫还是狗。
-
输入层:接收原始数据。一张100×100的图片,有10000个像素,每个像素有RGB三个颜色值,输入层就有30000个节点,每个节点接收一个数字(0到255之间的颜色值)。
-
隐藏层:中间的"处理层",负责从原始数据里提取有用的信息。可以有很多层------从几层到几百层。这就是"深度"的来源。
-
输出层:输出最终结果。判断猫还是狗,输出层就有2个节点------一个代表"是猫的概率",一个代表"是狗的概率"。
一个神经元在做什么?
网络里每一个节点叫一个神经元。它做的事情极其简单,只有三步:
第一步 :把所有输入的数字,分别乘以一个"重要程度"(叫权重),然后加起来。
输出 = 输入1 × 权重1 + 输入2 × 权重2 + 输入3 × 权重3 + ...第二步 :再加一个可以调节的数(叫偏置),让结果更灵活。
第三步 :通过一个"开关"函数(叫激活函数),决定要不要"激活"这个神经元------类似于"这个信号够不够强,要不要传下去"。
就这三步,每个神经元都在做同样的事。
听起来很简单对吧?确实很简单。神经网络强大的地方不在于每个神经元有多聪明,而在于把几百万个简单神经元连在一起,就能处理极其复杂的问题。
类比:一只蚂蚁很弱,但几百万只蚂蚁的蚁群能建造复杂的巢穴、找到最优的食物路径。神经网络也是这个道理------简单单元的大规模组合,涌现出复杂能力。
神经网络怎么"学习"?
这是最关键的问题。神经网络里有成千上万个权重(参数),一开始这些权重都是随机的------网络什么都不会,就像一个刚出生什么都不懂的婴儿。
"学习"的本质,就是反复调整这些权重,让网络的输出越来越接近正确答案。
我用一个射击训练的类比来解释这个过程。
射击训练类比
想象你是一个新兵,第一天学打靶:
-
你端起枪瞄准(随机猜测)------什么都不会,靠感觉瞄。第一枪打出去,偏了一大截。
-
教官告诉你偏了多少(计算损失) ------"你打偏了10环,偏左了3格,偏高了2格"。这个"偏了多少"在神经网络里叫损失(Loss) ,用损失函数来计算预测结果和正确答案之间的差距。
-
分析是哪个环节出了问题(反向传播) ------是站姿不对?握枪姿势有问题?还是呼吸没控制好?找出每个环节对"打偏"这件事的"贡献比例"。这个过程在神经网络里叫反向传播(Backpropagation)------从输出层的错误,一层一层往回计算,找出每个权重对最终错误负有多少"责任"。
-
朝正确方向调整(梯度下降) ------知道了每个动作的问题在哪里,就稍微调整一点。站姿稍微挺直一点,握枪稍微用力一点。每次只调一小步,而不是大幅度改变------因为改太多可能越改越糟。这叫梯度下降(Gradient Descent)。
梯度下降的类比:你蒙着眼睛站在山上,想走到最低点(最低点代表损失最小)。你感受一下脚下的坡度,朝最陡的下坡方向走一步。再感受,再走一步。一步步走,最终走到山谷。
- 重复几万次------每次打一枪,得到反馈,微调动作。打了几万枪之后,你成了神枪手。神经网络也是这样------见过足够多的训练样本,权重被调整到了合适的值,它就"学会了"。
为什么叫"反向传播"?
因为计算方向和正常流程相反。
正向(预测时):输入 → 隐藏层 → 输出(得到预测结果)
反向(训练时):输出的错误 → 隐藏层 → 输入(找出每个权重的责任比例)
这两个方向的传播,加上梯度下降的权重调整,合在一起就是神经网络训练的完整过程。
为什么叫"深度"学习?
"深度"指的是层数多。
- 浅层网络:1-2个隐藏层,处理简单任务
- 深层网络:几十到几百层,GPT-4有96层,一些新模型超过100层
层数越多,能学到的东西越"抽象":
以识别人脸为例:
第1层:学到边缘(横线、竖线、斜线)
第2层:学到纹理(皮肤质感、头发纹理)
第3层:学到局部结构(眼睛的形状、鼻子的形状)
第4层:学到人脸的整体组合(眼睛在上方、嘴在下方)
更深的层:学到"这是哪个人"的高级特征每一层都在上一层的基础上,提取更高级的特征。这就是为什么深层网络比浅层网络强------它能学到更抽象、更有用的表示。
类比:学画画。第一天学画直线和曲线,第二天学画基本形状(圆、方、三角),第三天学画五官,第四天学画整张脸,第五天学画人物组合......每一天都在前一天的基础上,学更高级的技能。神经网络的每一层,就是这样一步步抽象的。
为什么深度学习需要GPU?
你可能听说过AI公司疯抢GPU,但不知道为什么CPU不够用。这里解释清楚。
CPU和GPU的本质区别
CPU(中央处理器) 是通用处理器,有几个到几十个强大的核心。它擅长处理复杂的、有先后顺序的逻辑任务------比如运行操作系统、处理数据库查询、执行复杂的条件判断。
GPU(图形处理器) 最初是为了渲染游戏画面设计的。游戏画面有几百万个像素,每个像素的颜色需要独立计算------这是一个天然的并行任务。所以GPU被设计成有几千个小核心,每个核心不强,但可以同时处理几千个简单计算。
神经网络训练的本质是什么?
神经网络训练,本质上是大量的矩阵乘法。
什么是矩阵乘法?举个例子:假设你有一个有1000个神经元的隐藏层,和一个有1000个输入,你需要计算这1000个输入分别乘以1000个权重再相加------这就是1000×1000 = 100万次乘法和加法,在一层里。一个有几百层的大模型,一次前向计算涉及的乘加法次数是天文数字。
而且这些计算都是独立的------不同神经元的计算不依赖彼此------所以可以完全并行。
一个直观的比喻
CPU是一个数学天才教授。他一次只能解一道题,但每道题都解得飞快,能处理各种复杂的逻辑和条件判断。
GPU是一个小学生军团,里面有几千个学生,每人同时做一道简单的乘法题。
训练神经网络更像后者------不需要复杂逻辑,只需要同时做几百万道简单的乘加法。
这也是为什么英伟达(NVIDIA)在AI时代变成了最值钱的公司之一------它的GPU,成了AI时代的"铲子"。当所有人都在"淘金",卖铲子的最赚钱。
GPU的稀缺性
2024年,一块顶级的A100 GPU售价约一万美元,H100约三万美元。一家大型AI公司训练一个旗舰模型,需要同时运行几千块GPU,持续数月。这就是为什么训练大模型的成本动辄上亿美元。
对于应用开发者来说,这意味着:我们调用的每一次API,背后都有昂贵的算力在支撑。理解这个成本结构,有助于你在设计系统时做出合理的架构决策(比如什么时候批量处理比实时处理更划算)。
三种重要的网络结构
深度学习发展出了几种专门针对不同数据类型的网络结构。了解它们,你就能理解为什么不同任务用不同的模型。
CNN(卷积神经网络):图像的专家
擅长处理:图像、视频
CNN的核心思想是:图片里的特征(比如一只猫的耳朵)不管出现在图片的哪个位置,都应该能被识别出来。
它用一个"滑动窗口"在图片上扫描,检测局部特征------这就是"卷积"操作。就像你用放大镜一寸一寸地检查一张照片,每次只看一小块区域,记录这块区域有没有你要找的特征。
一个生活化例子:你在人群中找一张特定的脸,你的眼睛会自动扫描整个视野,不管这张脸在左边还是右边、上方还是下方,只要出现就能被你识别。CNN对图片的处理方式与此类似------它学会了识别"猫耳朵"这个局部特征,不管这个耳朵出现在图片的哪个角落。
应用:人脸识别、医疗影像分析(X光、CT扫描)、自动驾驶中的行人和红绿灯检测、手机拍照的美颜功能。
RNN(循环神经网络):序列的专家
擅长处理:文本、语音、时间序列
普通神经网络处理每个输入都是独立的,不记得"之前说了什么"。但语言不是这样的------"我喜欢苹果,因为它很好吃",要理解"它"指的是苹果,必须记住前面说过的内容。
RNN有"记忆"------它允许某些节点的输出"倒流"回来影响之前节点的输入,形成一个循环。实际效果是:处理当前词的同时,把上一步的"状态"(记忆)也带进来,就像一个会把上文记在脑子里再处理下文的读者。
一个生活化例子:想象你在听一篇故事的朗读。每听到一个新词,你不是独立处理这个词,而是联系前面已经听到的所有内容来理解它。RNN的工作方式类似------每处理一个词,都把"到目前为止我理解了什么"带进去。
问题:长文本时记忆会"衰减"------读了100个词之后,第1个词的信息在网络内部几乎消失了(就像你听了很长的故事后,开头的细节越来越模糊)。这个问题催生了后来的Transformer。
应用:早期的机器翻译、语音识别、文本生成。现在大多数场景已被Transformer取代,但RNN的基本思想------用状态记忆历史------在Agent系统设计中仍然有影响。
Transformer:当前的统治者
擅长处理:文本,以及越来越多的其他模态
2017年Google发表了一篇论文,标题叫《Attention Is All You Need》(注意力就是你所需要的一切)。这篇论文里的Transformer架构,改变了整个AI领域。
按照AWS的定义:Transformer是将输入序列转换为输出序列的神经网络架构,核心是自注意力机制,能同时查看序列的所有部分。
Transformer解决了RNN的核心问题:
RNN必须一个词一个词地处理,就像你必须按顺序读一本书,读到第100页时很难精确回忆第1页的某个细节。
Transformer用了一个叫**注意力机制(Attention)**的设计:处理每个词时,可以直接"看到"整个句子里所有其他词,然后计算它们之间的相关性,根据相关性加权关注。就像你可以把整篇文章摆在面前,随时翻到任何一页对照。
一个具体例子:
"银行倒闭了,河岸边的人都很担心"
当Transformer处理"银行"这个词时,它会同时看到"倒闭"、"河岸"等词,发现"河岸"和"银行"同时出现,就能判断这里的"银行"更可能是"河岸"的意思,而不是"金融机构"。
这就是注意力机制------根据上下文,灵活决定每个词该"关注"哪些其他词。
一个生活化例子:你在看一篇文章,遇到"他"这个代词,你需要判断"他"指的是谁。你不是只看前一句话,而是扫描整篇文章,找到最近一个匹配的男性角色。Transformer做的事情和这个完全一样------而且它对整篇文章里每个词都同时做这个操作。
另一个优势:并行计算
RNN必须一步一步处理(第2步依赖第1步的结果),无法并行,训练很慢。
Transformer可以同时处理所有词,大幅提升了训练速度------这让训练超大模型成为可能。
ChatGPT、Claude等所有主流大语言模型,都基于Transformer架构。
大语言模型的本质
LLM(大语言模型)本质上是一个超大的Transformer。
训练目标极其简单:预测下一个词。
给模型看"今天天气很",让它预测下一个词。答案是"好",就给奖励;答案是"坏",就调整权重。就这样,在互联网上的几乎所有文字上,重复训练几千亿次。
但就是这么简单的目标,在足够大的数据和模型上,产生了令人惊讶的能力:理解语义和上下文、逻辑推理、代码生成、多语言翻译、角色扮演,甚至某种程度的常识推理。
这种"规模涌现"------当模型规模超过某个阈值后,突然出现训练时没有明确教过的新能力------是当前AI最神奇的现象之一。没有人完全理解为什么会这样。但它确实发生了。
你需要学到什么程度?
不同目标的读者,需要理解的深度不同:
如果你是Agent应用开发者(本课程大多数读者):
- 不需要:自己训练模型、调整网络结构、写PyTorch代码
- 需要理解:LLM的局限------为什么会幻觉、为什么不能精确计算数学、为什么会"遗忘"超出上下文窗口的内容
- 需要理解:Embedding(向量化)的基本原理------这是RAG系统的核心基础
- 需要理解:Transformer的基本思想------帮你理解LLM的行为特点
本章的这篇文章,达到了应用开发者需要的程度。
如果你想做AI工程师(深度方向):
- 需要:掌握PyTorch基础(第5章会介绍)
- 需要:理解Transformer架构的细节(注意力的计算方式、位置编码等)
- 可以先跳过:CNN、RNN的数学细节(除非你做计算机视觉相关工作)
如果你想做AI研究:
- 需要:深入掌握所有架构的数学细节
- 需要:理解训练技巧(学习率调度、正则化、批归一化等)
- 需要:能读懂最新论文、复现实验结果
本课程的目标是让你成为优秀的Agent开发者,所以我们不会深入神经网络的数学细节。第5章深度学习基础会带你动手写基础的PyTorch代码,帮你建立更具体的感受。
小结
| 概念 | 一句话理解 |
|---|---|
| 神经网络 | 很多简单计算单元连在一起的数学函数,输入数字,输出数字 |
| 权重/参数 | 神经网络里可以调整的数字,代表每个输入的"重要程度" |
| 训练 | 反复调整权重,让预测结果越来越接近正确答案 |
| 损失函数 | 衡量预测结果和正确答案之间差距的公式,差距越大损失越高 |
| 反向传播 | 从输出的错误出发,找出每个权重对错误负有多少"责任" |
| 梯度下降 | 朝着减少错误的方向,一步步调整权重的算法 |
| 深度 | 层数多,能学到更抽象的特征 |
| GPU | 几千个小核心可以同时做矩阵乘法,是神经网络训练的基础设施 |
| CNN | 擅长图像,用滑动窗口检测局部特征,不管特征在哪个位置 |
| RNN | 擅长序列,有记忆机制,但长文本会遗忘 |
| Transformer | 用注意力机制同时关注所有位置,现在大语言模型的基础 |
| LLM | 超大Transformer,训练目标是预测下一个词,能力从规模中涌现 |
下一篇,看强化学习------从游戏AI到ChatGPT背后的训练机制。