作者:来自 Elastic 朱杰
开发一个成功的产品,往往需要集齐"天时、地利、人和"。其中,"天时"意味着要顺应客观环境的剧烈变化,"地利" 需要敏锐的技术嗅觉来选定赛道,"人和" 则离不开极致的工程执行力。在向量搜索进入深水区的今天,Elasticsearch 并没有盲目堆砌硬件资源,而是通过快速落地 BBQ(Better Binary Quantization 更好的二进制量化) 算法,向业界展示了什么叫做技术上的 "弯道超车"。
更多阅读:Lucene 和 Elasticsearch 中更好的二进制量化 (BBQ)
 www.bilibili.com/video/BV1eT...
www.bilibili.com/video/BV1eT...
一、 内存暴涨5倍!为什么 Elastic 的 BBQ 算法是向量搜索的救星?
在 Agent 应用席卷全球的今天,开发者们正面临一个尴尬且棘手的现实:向量搜索虽然非常有用,但它的"代价"实在太贵了。
向量搜索的 "破产" 边缘:内存与硬件的博弈
自 Facebook 开源 Faiss 以来,向量搜索技术已经历了数年的演进。业界主流方案长期依赖基于 Faiss 的各类实现,但在大模型带来的海量数据冲击下,传统堆硬件的 "暴力美学" 方案遇到了严峻的挑战。
挑战一:距离计算的算力黑洞
在高维向量搜索过程中,距离计算的开销占比超过 90%。随着向量维度的提升(如 768 维、1536 维甚至更高),计算复杂度呈线性增长。要想提高检索的 QPS 和吞吐量,首要任务就是把这个计算过程变轻、变快。
挑战二:令人咋舌的内存税
以 OpenAI 的 text-embedding-3-small 模型为例,其输出向量为 1536 维。对于包含 100 万条 向量的数据集:
-
每个向量由 1536 个 32 位浮点数构成。
-
裸数据存储成本:仅存储这些原始向量就需要约
6GB内存。 -
索引成本:为了实现毫秒级检索,业界最常用的 HNSW(分层导航小世界图)索引还需要构建大量的图连接关系。经验数据显示,当数据量达到
1000 万时,你需要准备至少40GB的内存来维持高性能运转。
挑战三:硬件成本的"背刺"
更扎心的是硬件环境的变化。过去几年,受 AI 算力挤兑影响,高性能服务器硬件成本大幅上涨。
-
内存价格倒挂:DDR5 内存自 2023 年底以来持续上涨,令人意外的是,本该逐步退市的 DDR4 内存因产能缩减和需求外溢,涨幅甚至一度超过 DDR5。
-
算力通胀:CPU 和 GPU 的价格也在全面上扬。
在当下的生产环境中,想要全量运行 HNSW + Float32 几乎成了奢侈品的代名词。许多技术团队发现,为了支撑向量搜索功能,服务器成本竟然远远超过了业务本身的收益,这无疑是不可持续的。
二、 从 RaBitQ 到 Elastic BBQ
为了打破这个"性能与成本"的死锁,学术界一直在探索极致的量化方案。2024 年 5 月,南洋理工大学的龙程老师及 Jianyang Gao 博士在数据库顶级会议 SIGMOD 2024 上发表了重磅论文:
《RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search》 这是一种新型的二值(Binary)量化方法,其核心理念在于"极限压缩"。
RaBitQ 的技术魔力:
相比于传统的 PQ(乘积量化)和 SQ(标量量化),RaBitQ 带来的优势是颠覆性的:
32倍的极致压缩比:
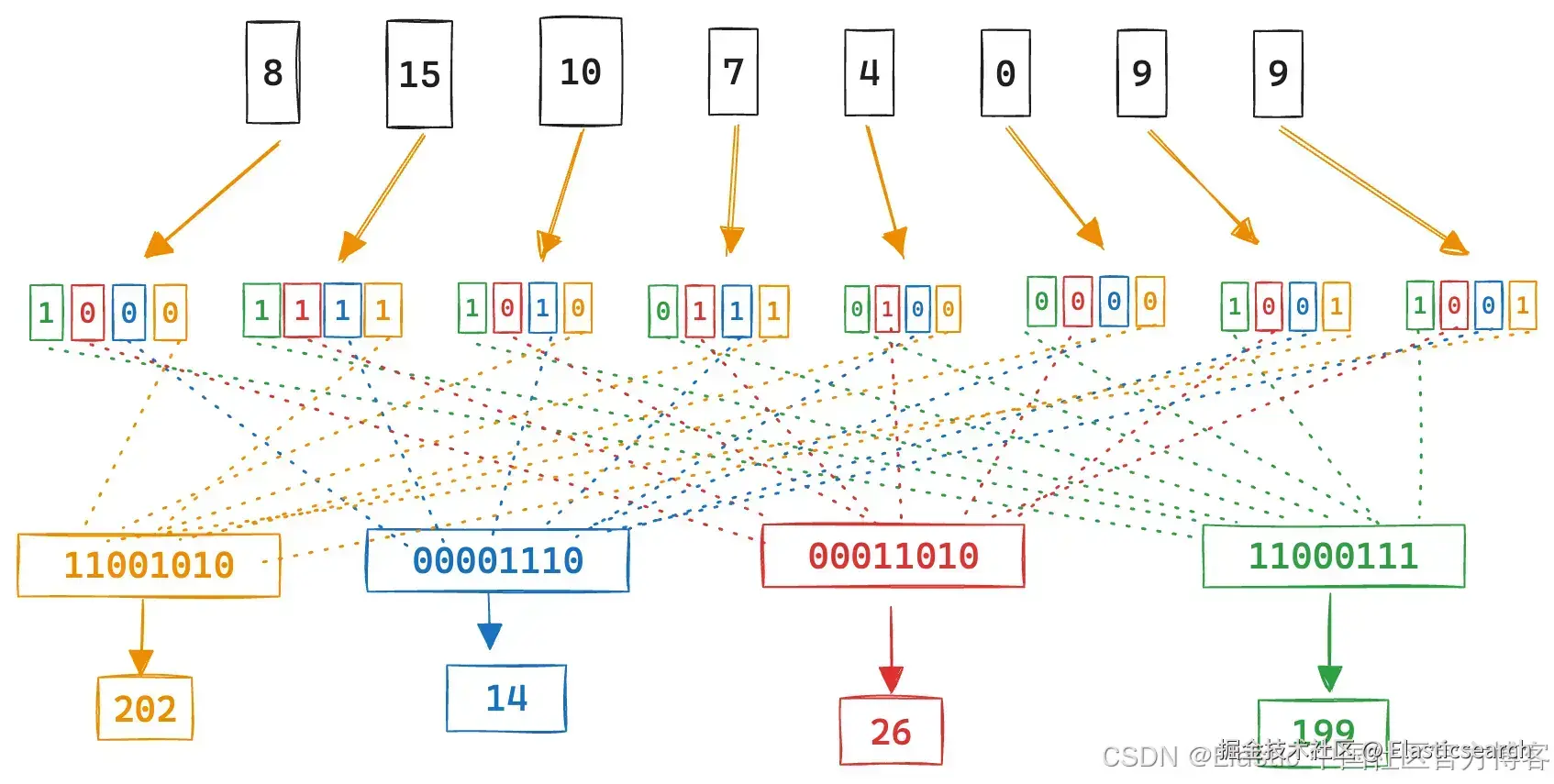
RaBitQ 将 32 位的浮点数压缩为仅 1 位的二进制数(0 或 1)。这意味着内存占用直接缩减为原来的 1/32。
黑科技般的高精度:
通常认为二值化会严重损失精度,但 RaBitQ 通过组合随机旋转、残差量化以及无偏估计器等数学策略,有效地保留了向量在高维空间中的相对位置关系。在测试中,它的精度甚至媲美压缩比低得多的 PQ 量化。
极佳的架构兼容性:
- 适配图索引: RaBitQ 能完美嵌入 HNSW 结构。Elasticsearch 的 BBQ 正是基于此,在 HNSW 索引上实现了 RaBitQ 算法。
- 适配倒排索引:RaBitQ 同样可以结合 IVF(倒排文件),Faiss 的 IVF RaBitQ 实现便是这一路线的代表。
三、 天下武功,唯快不破:Elasticsearch 的工程化奇迹
在软件工业界,从一篇论文发表到成为工业级产品的特性,通常需要数年时间。但 Elasticsearch 团队则表现出一贯以来高效的工程执行力。
Elastic 的 BBQ 诞生时间线:
-
2024.05:SIGMOD 论文发表,Elasticsearch 向量搜索团队第一时间关注并研读。
-
2024.06:内部开启原型验证,确认理论在 Lucene 架构下的可行性。
-
2024.08-09:进行复杂的工程化改造。不仅仅是算法实现,更涉及 SIMD 指令集优化、内存布局调整等底层工作。
-
2024.10:代码贡献合并入核心引擎 Apache Lucene。
-
2024.11:产品正式上线!Elasticsearch 8.16 版本正式推出 BBQ(Better Binary Quantization)。
这一连串动作,仅仅用了不到半年时间。与之形成对比的是: Faiss 直到2025年4月才推出 IVF RabitQ,Milvus 5月才推出 IVF RabitQ,比 Elastic团队动作慢了半年。
在实现路径上也有不同:
Faiss :
倾向于 IVF + RaBitQ。IVF 结构简单,构建速度快,但在高召回率要求下,由于受限于聚类中心的划分,往往需要扫描更多的簇,导致性能衰减明显。
Elasticsearch BBQ :
选择了 HNSW + BBQ。这是一个 "强强联合" 的方案:
* HNSW 提供了目前业界最强的导航能力和召回率稳定性。
* BBQ 将 HNSW 最被人诟病的内存占用问题解决了 95%。
* 最关键的是,利用 Hamming 距离 进行位运算,在现代 CPU 上比浮点数乘加运算快得多。
四、 实测数据:BBQ 到底有多猛?
我们使用 Milvus 团队开发的 VectorDB Benchmark 进行了对比测试。虽然 VectorDB Benchmark 的局限性非常大,很难反应当下普遍采用的混合搜索的速度,只能做纯向量性能的基础参考。
测试环境与方法论:
硬件环境: AWS 虚拟机环境,选择了老中新三代机型进行比较测试,分别是 M6a M7a M8a,
- M6a 基于 AMD Zen3 架构搭配 DDR4 内存不支持 AVX512,只支持 AVX2 指令集,
- M7a 基于 AMD Zen4 架构搭配 DDR5 内存,支持半血 AVX512,因为位宽是256,所以需要2个周期执行 AVX512 指令
- M8a 则是最新的 Zen5 架构,位宽是512,满血 AVX512
- 统一采用 4xlarge 规格,16 vCPU 64GB 内存
软件环境: Ubuntu Server 24.04 LTS,Docker 启动单节点 ES 9.2.4,Docker Compose 启动 Milvus 2.6.9
压测软件: vectordbbench 修改了Elastic Cloud 代码适配自建 ES
数据集 :Cohere 100万条768 维度向量,这是目前 RAG 场景中非常典型的中高维数据。
核心指标:QPS(每秒查询数)与 Recall(召回率)曲线
这里有一个需要注意的技术细节:Segment 数量对齐
这是目前网上做向量性能测试通通忽略的一个技术细节,容易造成大量不公平的对比结果。在默认配置下,Elasticsearch 导入 100万数据后生成 Segment 数量要远高于 Milvus。每一个 Segment 本质上都是一个独立的 HNSW 小图。查询时需要遍历所有小图并合并结果。而 Milvus 通常会根据配置生成较大的 Segment。为了保证测试的严谨性,我们调整了vdbbench ES 默认的 Force Merge 到一个 Segment 的逻辑,将 Elasticsearch 的 Segment 强制合并为 6 个,与 Milvus 的 Segment 数量保持一致。
Vectordbbench 测试命令行示例
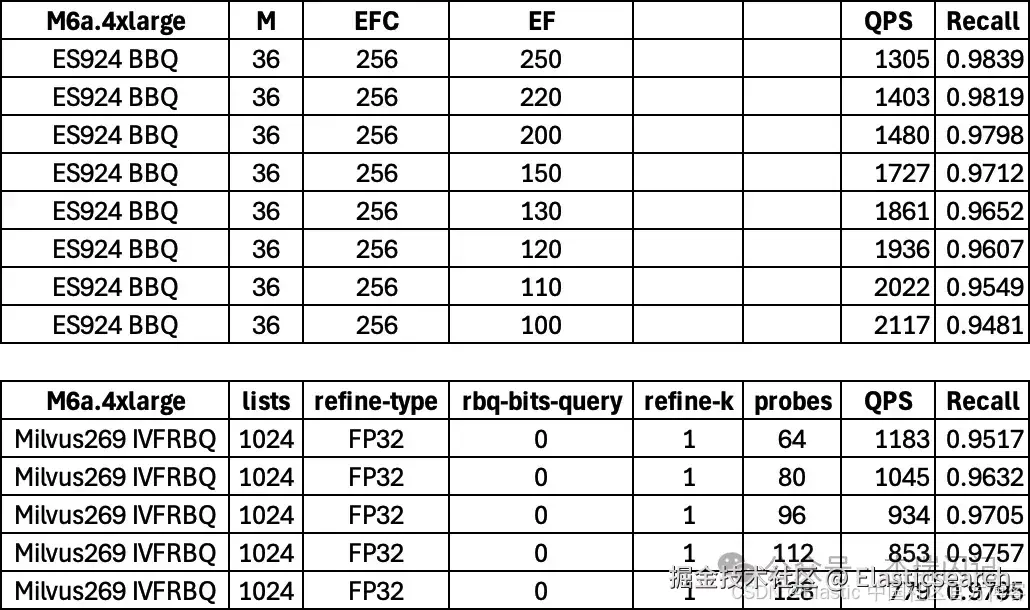
ES BBQ
- 构建参数 m=36 ef-construction=256 ForceMerge 到6个 Segments
- 搜索参数 k=100 通过不同的 num-candidates (100~250) 获得不同 Recall 下的 QPS
python
`
1. vectordbbench elasticcloudhnswbbq --drop-old --load --cloud-id 'https://10.0.0.1:9200' --password 'PWD'
2. --case-type Performance768D1M --number-of-shards 1
3. --number-of-replicas 0 --refresh-interval 60s
4. --use-force-merge True --num-concurrency 30,40,60
5. --m 36 --ef-construction 256 --num-candidates 100 --k 100
`AI写代码Milvus IVF RabitQ
- 构建参数 lists=1024 refine=True refine-type=FP32
- 搜索参数 probes=128 rbq-bits-query=0 refine-k=5
可以看到 IVF RabitQ 的构建参数和搜索参数比 BBQ 复杂,这对于实际应用是非常大的挑战,极大地增加了使用的复杂度,所以我们测试了大量的组合,选择了最好的成绩进行了对比。
压测结果:
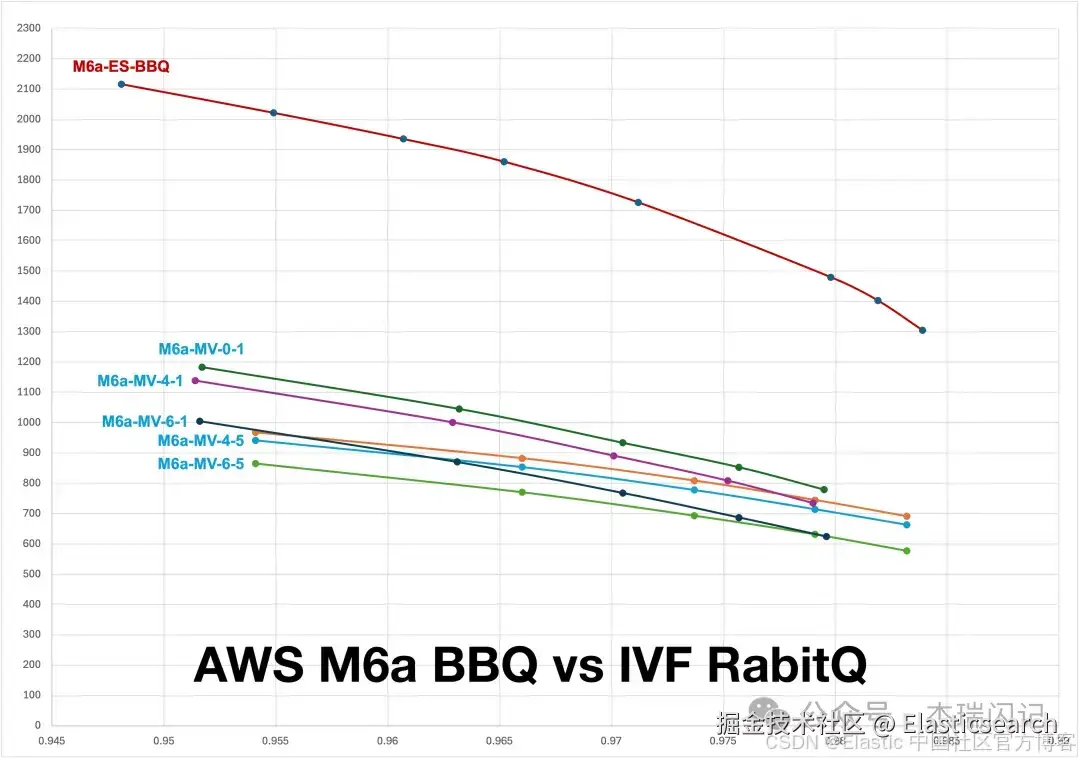
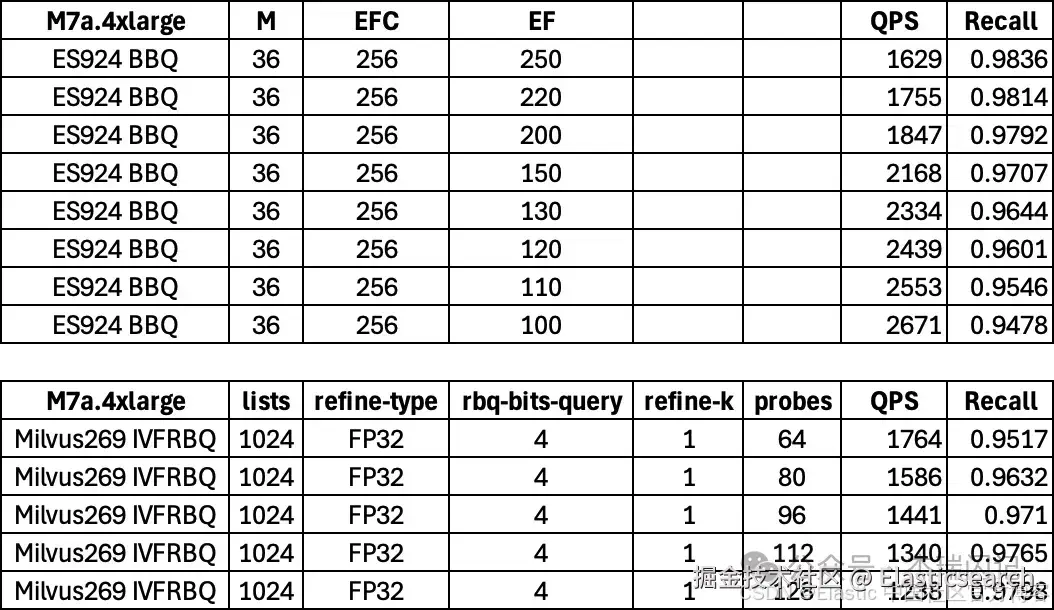
测试 1:M6a 4xlarge 单节点对比
可以看到在老的 M6a 平台上面(缺乏AVX512指令),BBQ比Milvus IVF RabitQ最好性能高出 75%~85%
测试 2:M7a 4xlarge 单节点对比
在主流硬件平台上面,BBQ 比 Milvus IVF RabitQ 最好性能高出 45%~50%
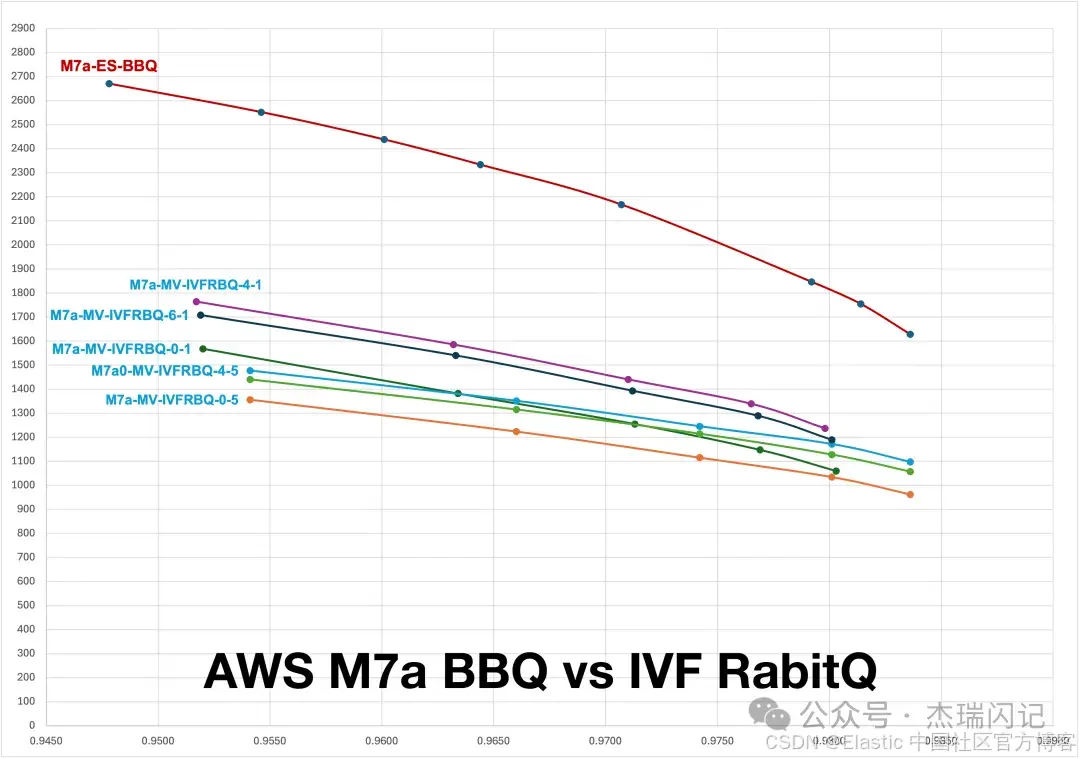
结合上面 2 个平台比较,BBQ 对于老硬件、特别是不支持 AVX512 指令的 CPU 更加友好,用较弱的硬件都能跑出较高的成绩,相反 Milvus 纯粹靠的是硬件算力
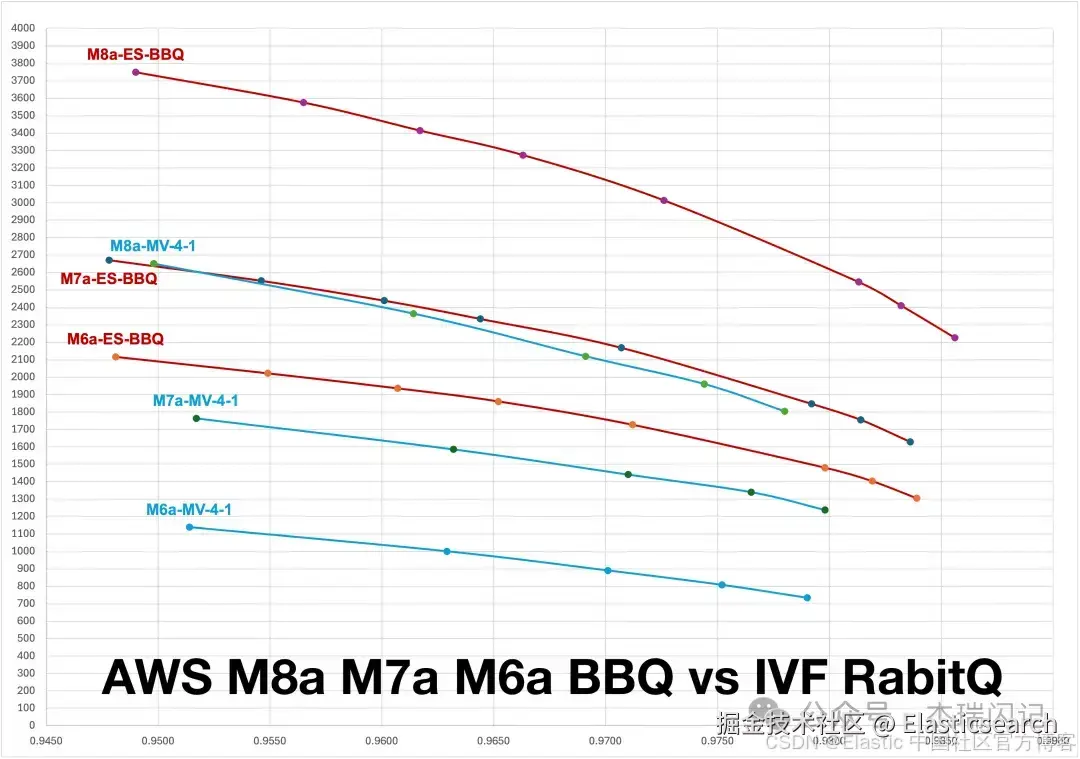
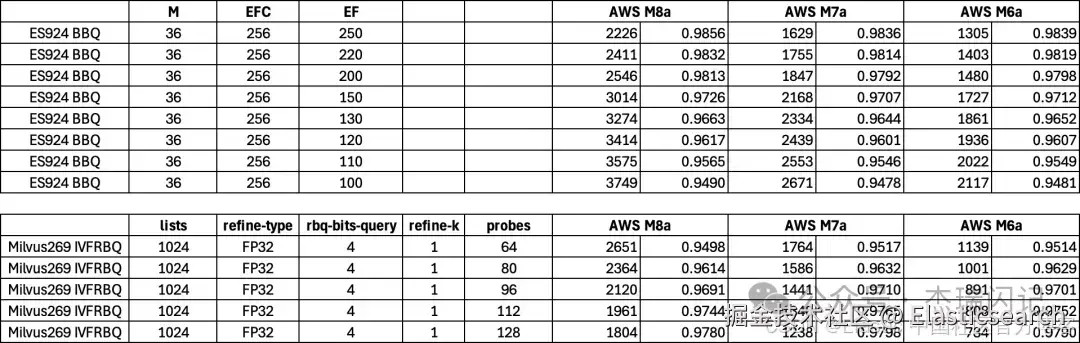
测试 3:M6a M7a M8a 三平台对比
结合三代平台一起看,BBQ 几乎是越级碾压,旧平台碾压 Milvus 在新平台的性能,可以看到这最新的M8a 平台大幅度领先,BBQ 在老平台 M7a 的性能就可以超越 IVF RabitQ 在 M8a 平台的性能,BBQ 甚至在 M6a 平台的性能可以超越 IVF RabitQ 在 M7a 上性能的 15%~25%
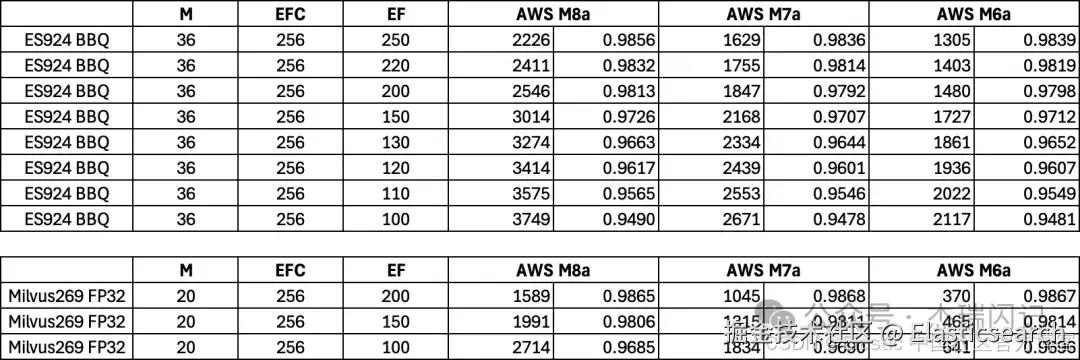
测试 4:M6a M7a M8a 三平台 BBQ 和 Milvus HNSW Float32 对比
ES BBQ 的性能也大幅度超越 Milvus HNSW FP32,而且比 Float32 节省大量内存,而且从图中可以看出,Milvus 算力依赖十分严重,老平台 M6a 因为缺乏 AVX512 指令,性能非常低,BBQ的性能几乎是其 3 - 4 倍

五、 总结
Elasticsearch BBQ 的出现,标志着向量搜索从"暴力堆硬件"的时代,正式迈入了"算法换成本"的精细化运营时代。
-
如果你正为每个月高昂的云主机账单发愁;
-
如果你受限于老旧的硬件环境,没有DDR5内存,无法支持AVX512指令;
-
或者你只是单纯想体验"榨干 CPU 每一个比特"的技术快感;
那么,Elasticsearch 8.16 + 的 BBQ 算法,就是你目前能找到的最优解。 这不仅是一次算法的升级,更是 Elastic 团队对技术趋势精准预判和超强执行力的完美注脚。
4月18日 北京 Elastic中国AI搜索技术大会 赶紧免费抢座位!
