1. 背景
刚接手复杂的线上业务,生产环境突然报出接口超时或进程崩溃,面对几 GB 甚至几十 GB 的滚动日志,你是丈二和尚摸不着头脑,还是熟练敲下组合命令瞬间定位问题?这种体现个人能力的关键时刻真的很重要~
在现代分布式系统架构中,后端服务的稳定性直接决定了业务的连续性。然而在生产环境下,日志文件往往具有体积巨大 (GB 级别)、多线程并发交织 、异常堆栈冗长 以及滚动轮转频繁等特点。
对于一名 Java 后端开发人员而言,掌握高效的 Linux 日志处理指令不仅是告别"加班排障"的利器,更是体现资深工程能力的试金石。本文将立足于真实的生产环境,系统性地总结查看日志的核心命令与实战组合连招
2.生产级的日志特征与排障陷阱
日志归档机制及其对分析的影响
由于生产环境日志产生速度极快,往往服务的日志配置会通过设置大小阈值或时间周期,将当前日志(如 app.log)重命名为历史归档(如 app.log.1.gz)并创建新的空文件继续写入 。这一机制决定了开发人员在跨越长时间跨度排查问题时,必须能够灵活使用处理压缩格式的指令,而非单纯依赖基础查看命令。
日志查看命令的性能平衡与安全选择
在生产环境中,严禁直接使用 vi 或 vim 打开巨大的日志文件,因为这些编辑器会尝试将文件全部加载进内存,导致严重的 IO 阻塞甚至触发内存溢出。开发人员应根据查看深度和实时性要求,在 cat、less 和 tail 之间做出明智选择
分布式链路追踪与跨服务日志关联
在微服务时代,单机的日志分析往往只能看到局部。Java 后端开发通常依赖 MDC(Mapped Diagnostic Context)技术将 TraceId 注入日志布局中。关于分布式链路追踪的知识点,请看之前我们总结的:Spring Boot项目如何实现分布式日志链路追踪
当用户反馈请求报错时,获取该请求唯一的 TraceId 是排查的第一步。在多台服务器构成的集群中,虽然可以通过集中式日志平台(如 ELK)查看,但有时直接在服务器上通过命令行实时分析更为即时 。
- 跨文件聚合 :
grep -h "trace-123456" *.log | sort。 使用-h隐藏文件名,将散落在业务日志、中间件日志、审计日志中的相同 TraceId 记录提取出来,并按时间戳排序,还原完整的请求链路 。 - 链路完整性校验 :通过
grep配合find和xargs可以快速在整个日志目录(包含子目录)中定位链路的缺失点:find /var/log/myapp -name "*.log" | xargs grep "trace-123456"
3.核心实战命令精讲
3.1 grep:排障出场率 99% 的绝对主力
grep (Global Regular Expression Print)是查看日志实战中使用最多的命令,没有之一。它是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。核心配置项选项如下:
| 核心选项 | 动作说明 | 生产实战场景 |
|---|---|---|
-A n / -B n / -C n |
打印匹配行的 后/前/前后 n 行 |
必用! 抓取完整的 Java Exception 异常堆栈 |
-v |
反向匹配(排除) | 过滤掉心跳检测(如 grep -v "healthCheck") |
-i |
忽略大小写 | 搜索 exception 或 Exception 均可命中 |
-E |
支持扩展正则表达式 | grep -E "1-9+" |
-h |
隐藏文件名 | 多文件聚合查找时,让输出更纯粹 |
展示命令示例之前先看看日志文件结构:
lua
plasticene-admin % ls
app-debug-2026-03-25.0.log app-error.log app-interface.log
app-debug.log app-info.log app-warn-2026-03-25.0.log
app-error-2026-03-25.0.log app-interface-2026-03-25.0.log app-warn.log常见日志查找是根据请求的traceId或者代码里面info输出的关键字查找的,如常用的根据traceId查找
bash
grep '2037009686800355328' *.log结果如下所示:
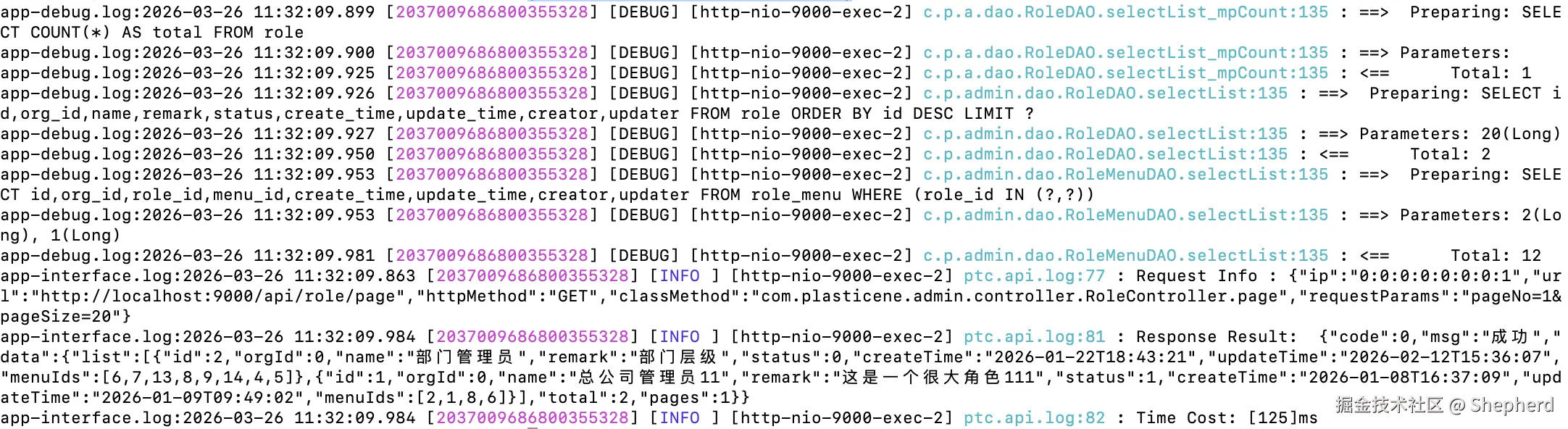
可以看到默认显示了具体的文件名和对应查找到的日志信息,但是我们一般是想按照请求链路时间顺序查看日志,而不是根据文件分开展示,不方便根据实际调用链路追踪,命令如下:
bash
grep -h '2037009686800355328' *.log | sort注意:默认情况下sort 会将查找到整行作为一个字符串 进行比较,按照字符的 ASCII/Unicode 编码顺序排序,所以加上了选项-h:不显示文件名,这样每行以时间开头。
结果如下所示:
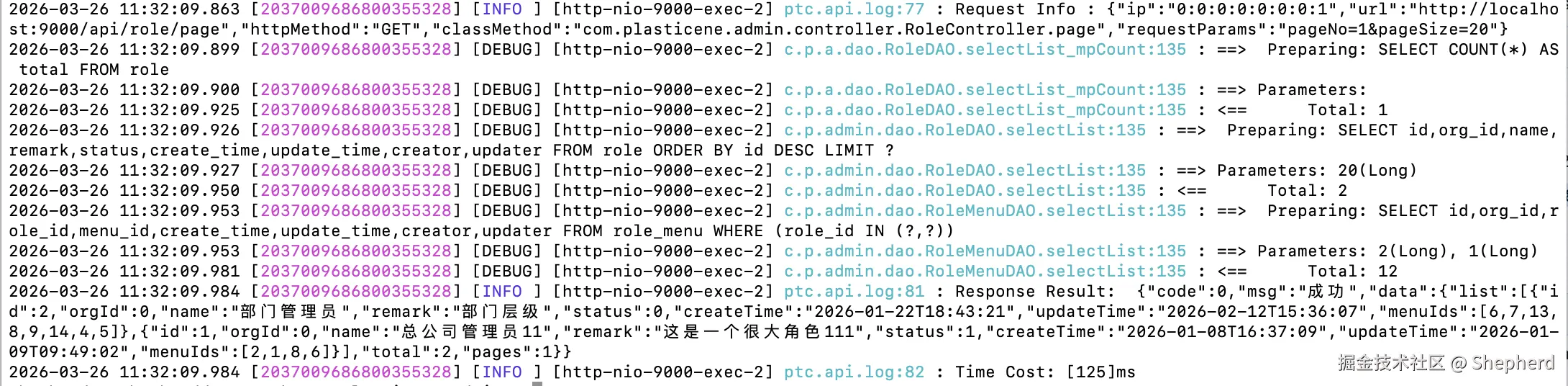
可以看到日志根据时间顺序展示了,碍于篇幅问题,下面我只会展示示例命令,不再展示结果输出了~
如果你的日志格式时间不是放到最前面,如:
sql
app-debug.log:[2036988356092674048] [DEBUG] [2026-03-26 10:07:25.026] [http-nio-9000-exec-1@72976] com.plasticene.admin.dao.UserDAO.selectList_mpCount debug : ==> Preparing: SELECT COUNT(*) AS total FROM user那就得调整下sort命令的使用:
bash
grep '2036988356092674048' *.log | sort -t '[' -k4,4说明:
-t '[':使用[作为字段分隔符-k4,4:按第4个字段(时间戳字段)排序
这样可以将所有文件中的日志按时间顺序排列
不过强烈建议日志格式第一列设置成时间,这样简洁明了,也方便查询
在生产环境中,grep真正的威力在于对上下文(Context)的捕捉。Java 的异常堆栈通常跨越数十行,如果只搜索 "Exception" 关键字而不带上下文,会丢失最有价值的栈顶调用信息。使用选项 -A (After)、-B (Before) 和 -C (Context) 参数来输出匹配显示行的上下行内容信息
比如说请求某个接口报错了,根据traceId去查看error日志:
lua
grep '2036706972224598017' app-error.log结果只是展示一行,根本看不到异常信息:
css
[2036706972224598017] [ERROR] [2026-03-25 15:29:17.797] [http-nio-9000-exec-1@65245] com.plasticene.boot.web.core.global.GlobalExceptionHandler exceptionHandler : 【系统异常】正确的姿势是
lua
# 抓取报错及其后面的 50 行堆栈信息
grep -A50 '2036706972224598017' app-error.log再比如有些调用三方接口的请求参数和响应结果在info中进行换行格式化输出,这时候也需要查看上下文关联相关信息:
perl
grep -C5 '2036706972224598017' app-info.log | grep 'url地址'使用正则表达式匹配:
csharp
# 1. 查看所有超过1000ms的请求
grep -E '耗时[[0-9]{4,}]毫秒' interface.log
# 2. 统计数量
grep -E '耗时[[0-9]{4,}]毫秒' interface.log | wc -l
# 3. 统计数量
grep -cE '耗时[[0-9]{4,}]毫秒' interface.log最后谈谈和cat命令的关联使用,如cat app-info.log | grep '2036706972224598017' 和grep '2036706972224598017' app-info.log效果是一样的,但cat 会启动一个额外的进程并通过管道传递数据,这在处理 GB 级别的生产日志时会产生不必要的 CPU 和 I/O 开销。直接运行 grep "pattern" filename 效率更高,大日志文件完全不建议使用cat,cat更适合查看小型配置文件或系统状态,直接屏幕展示。
3.2 tail
在屏幕上显示指定文件的末尾若干行,不指定行数时默认显示末尾10行。命令选项如下:
css
-c, --bytes=NUM 输出文件尾部的NUM(NUM为整数)个字节内容。
-f, --follow[={name|descript}] 显示文件最新追加的内容。"name"表示以文件名的方式监视文件的变化。
-F 与 "--follow=name --retry" 功能相同。
-n, --line=NUM 输出文件的尾部NUM(NUM位数字)行内容。
--pid=<进程号> 与"-f"选项连用,当指定的进程号的进程终止后,自动退出tail命令。
-q, --quiet, --silent 当有多个文件参数时,不输出各个文件名。
--retry 即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项"--follow=name"连用。
-s, --sleep-interal=<秒数> 与"-f"选项连用,指定监视文件变化时间隔的秒数。
-v, --verbose 当有多个文件参数时,总是输出各个文件名。
--help 显示指令的帮助信息。
--version 显示指令的版本信息。tail 命令在开发联调和实时监控中几乎是不可或缺的。通过 -f (follow) 参数,开发人员可以持续观察文件的末尾追加内容 。
在真实的生产场景中,由于存在日志轮转,建议使用 tail -F 而非 tail -f。-F 选项会自动检测文件名的变化。当 app.log 达到阈值被重命名为 app.log.1 时,tail -f 会停止工作,而 tail -F 则会尝试重新打开名为 app.log 的新文件,从而保证监控的连续性 。此外,配合 -n 参数可以指定初始查看的行数,如 tail -n 100 -f app.log,这在重启服务后检查初始化日志是否正常时非常有用
bash
tail file #(显示文件file的最后10行)
tail -n +20 file #(显示文件file的内容,从第20行至文件末尾)
tail -c 10 file #(显示文件file的最后10个字节)
tail -25 app-info.log # 显示 mail.log 最后的 25 行
tail -f app-info.log # 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F app=info.log # 等同于--follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
3.3 sed
sed(Stream Editor,流编辑器)是排查问题查看日志的"瑞士军刀"。它最大的优势在于非交互式 处理:它不需要像 vim 那样将整个文件加载到内存中,而是逐行读取并处理。这使得它在处理 GB 级别的生产日志时既安全又高效。
有时候我们没办法得到准确traceId或者关键字信息通过grep去快速过滤日志,只知道一个大概的时间范围,这时候sed就能排上用场了:
c
sed -n '/2026-03-26 10:15/, /2026-03-26 10:20/p' app-info.log 经验贴士 :模式匹配是"精确匹配"。如果 10:20:00 这一秒刚好没日志,sed 可能会一直打印到文件末尾。建议匹配到分钟即可
sed的功能挺强大的,关于sed的详细信息请看:wangchujiang.com/linux-comma...
3.4 awk
awk 实际上是一门完整的文本处理编程语言。对于 Java 开发来说,它最强大的地方在于能把"非结构化"的日志看作"结构化"的表格,非常适合处理 Nginx 访问日志、Tomcat 日志或进行 JVM 性能数据的二次统计
awk 按行读取文件,默认以空格或制表符将每行切分成多个列(Fields)。
$0:表示当前整行内容。$1, $2...$n:表示第一列、第二列,以此类推。$NF:表示最后一列(Number of Fields,在不知道列数时极好用)。NR:当前处理的是第几行(Number of Records)。FS:输入字段分隔符,默认为空格,可通过-F修改
假如日志的最后一列打印耗时
arduino
192.168.1.10 - - [26/Mar/2026:00:01:01 +0800] "GET /api/user/info HTTP/1.1" 200 512 1.205那么统计超过1s以上的请求命令如下:
dart
# 打印时间、请求路径和具体的耗时数值
awk '$NF > 1.0 {print $1, $7, $NF}' access.logawk功能也很强大,详细信息请看:wangchujiang.com/linux-comma...
3.5 less
less 是 一个强大且安全的日志查看工具。与 more 不同,less 采用了延迟加载技术,仅在用户翻页时读取文件内容,这使其在处理数 GB 规模的文件时依然能保持瞬间响应
在生产分析中,less 的交互快捷键是提高排查效率的关键。通过 /pattern 可以进行向下搜索,而 ?pattern 则支持向上回溯搜索 。在搜索结果中,按下 n(next)跳转到下一个匹配项,N 则回到上一个。如果需要实时观察日志并具备随时停下来检索的能力,执行 less +F <filename> 是最佳选择。这种模式下,less 的行为类似于 tail -f,但用户只要按下 Ctrl+C 就能立刻切换回浏览模式,进行前后翻页或关键字搜索,分析完毕后再按 F 即可恢复实时监控 。
| Less 交互命令 | 动作说明 | 实用技巧 |
|---|---|---|
Space / f |
向下翻一页 | 快速扫描最近的大段输出 。 |
b |
向上翻一页 | 寻找报错堆栈的起始位置 。 |
G |
跳转到文件末尾 | 快速到达最新生成的日志记录 。 |
g |
跳转到文件起始 | 检查服务启动阶段的初始配置加载 。 |
&pattern |
仅显示匹配行 | 类似于实时过滤,隐藏所有不相关的噪音日志 。 |
-N |
显示行号 | 配合代码库定位具体的报错行 。 |
比如说上面根据sed查看指定时间区间的日志,如果日志量过大会刷屏,这时候就可以通过less进行分屏翻页:
c
sed -n '/2026-03-26 10:15/, /2026-03-26 10:20/p' app-info.log | less3.6 查看压缩归档日志
生产环境中,为了防止磁盘爆满,历史日志通常会被压缩为 .gz 格式。Linux 提供了专门用于操作压缩文本的指令集。这些指令会在后台使用流式解压并直接将数据传给分析引擎,避免了生成中间文件的开销 。
| 压缩指令 | 对应原始指令 | 应用场景 |
|---|---|---|
zgrep |
grep |
在多天的归档压缩包中查找一个特定的 TraceID 。 |
zless |
less |
查看一周前的历史日志归档,寻找配置更改的痕迹 。 |
zcat |
cat |
将压缩日志流导向 awk 或 sed 进行离线数据分析 。 |
zmore |
more |
快速翻阅归档文件内容 。 |
4. 实战组合拳
真正体现排障效率的,是把基础命令串联起来形成数据流(Pipeline)。以下是几个我在做复杂业务系统(如定时任务调度、长链路工作流)时常用的高阶组合拳。
连招一:快速统计指定时间段内的特定业务执行频次
场景:排查"逾期任务自动撤销"定时任务在特定时间段内究竟触发了多少条记录。
bash
sed -n '/15:00/,/15:30/p' app-info.log | grep "逾期任务自动撤销" | wc -l连招二:统计出现次数最多的 Top 10 异常(巡检必备)
场景:系统巡检时,想知道当前 error 日志里哪种异常最为泛滥。
bash
# 提取带有 Exception 的行,用 awk 打印最后一列(通常是异常类名),去重统计并倒序排列,取前 10
grep "Exception" app-error.log | awk '{print $NF}' | sort | uniq -c | sort -nr | head -n 10连招三:捕捉慢请求并提取耗时接口
场景 :Nginx 或业务网关日志中,抓取耗时大于 1000ms 的请求路径。 (假设日志格式:[时间] "GET /api/user" 200 1.205,耗时在最后一列)
bash
awk '$NF > 1.0 {print $7}' access.log | sort | uniq -c | sort -nr | head -n 10连招四:跨多文件、多目录的海量捞针
场景:一个请求跨越了多个微服务模块,日志被分散在不同的子目录下,你想强行找出包含该 TraceId 的所有日志文件并定位。
lua
# 配合 find 和 xargs,在整个 /var/log/ 目录下地毯式搜索
find /var/log/myapp -name "*.log" | xargs grep "2036706972224598017"5. 总结
在云原生和集中式日志(ELK / SkyWalking)大行其道的今天,熟练掌握 Linux 原生日志命令似乎显得有些"复古"。但作为一名资深研发,总会遇到集中日志平台延迟、崩溃,或者需要登录跳板机直连隔离环境排查底座问题的时刻。
这些命令就像是开发者手中的瑞士军刀,平时藏于终端,关键时刻拔剑出鞘,一针见血。