前言
学习项目的过程中,我觉得自己有点太急功近利了一直跟着视频敲没有自己的思考(主要是最近在牛客读到了一位大佬👍👍👍,程序员牛肉的文章),🙌学技术不是一味的复制粘贴,特别是做项目,要边学边思考,一个功能的实现,我学会了什么技术,还有没有更好的可以替代它。
之前学的基础知识其实也没有学完,像集合,线程... 都还不知道是啥就开始学JavaWeb做项目了,在项目中使用队列存储我都一脸懵,在这里以问题的形式写一个学习笔记🤔,不仅仅是复习,也为以后的面试做准备,还有还有我的刷题网站是面试鸭呦🦆🦆🦆,嗯也看了Hello算法书
目录
先来看看哈希表的使用✌️✌️✌️
哈希表的常见操作包括:初始化、查询操作、添加键值对和删除键值对等,示例代码如下:
java
/* 初始化哈希表 */
Map<Integer, String> map = new HashMap<>();
/* 添加操作 */
// 在哈希表中添加键值对 (key, value)
map.put(84001, "小张子");
map.put(84004, "小赵子");
map.put(84010, "小刘子");
/* 查询操作 */
// 向哈希表中输入键 key ,得到值 value
String name = map.get(84001);
/* 删除操作 */
// 在哈希表中删除键值对 (key, value)
map.remove(84001);哈希表的遍历:
java
/* 遍历哈希表 */
// 遍历键值对 key->value
for (Map.Entry <Integer, String> kv: map.entrySet()) {
System.out.println(kv.getKey() + " -> " + kv.getValue());
}
// 单独遍历键 key
for (int key: map.keySet()) {
System.out.println(key);
}
// 单独遍历值 value
for (String val: map.values()) {
System.out.println(val);
}哈希表实现
📍 背景:HashMap 的结构演变:
JDK 7 及以前:数组 + 链表(拉链法)
JDK 8+:数组 + 链表 or 红黑树
一. 我们先考虑最简单的情况,仅用一个数组来实现哈希表
输入一个 key ,哈希函数的计算过程分为以下两步。
- 通过某种哈希算法 hash() 计算得到哈希值。
- 将哈希值对桶数量(数组长度)capacity 取模,从而获取该 key 对应的桶(数组索引)index :index = hash(key) % capacity
随后,我们就可以利用 index 在哈希表中访问数组中对应的数据
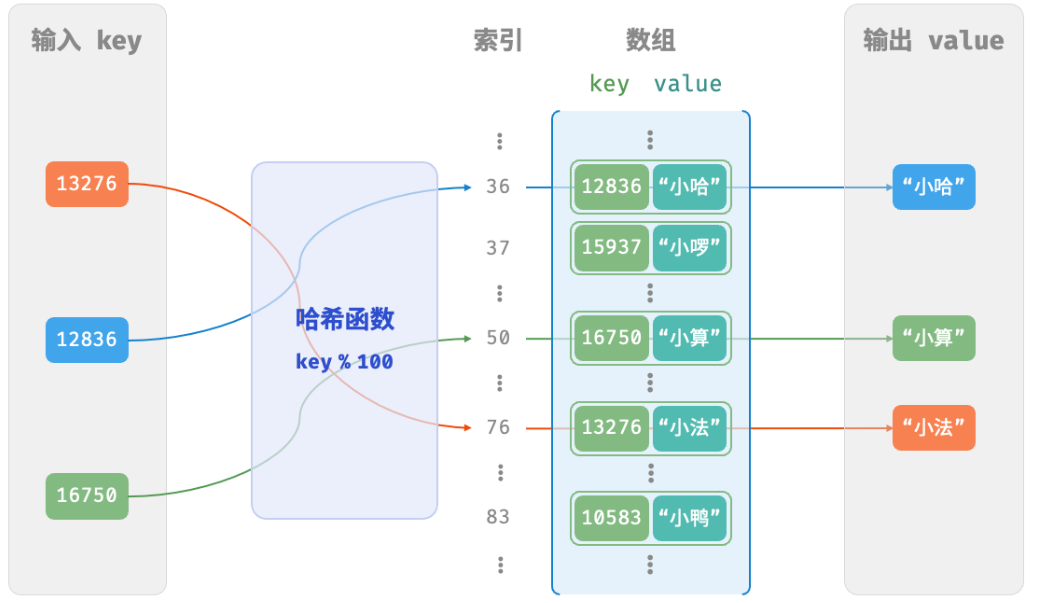
来看看代码(基于数组的哈希表)
java
/* 键值对 */
class Pair {
public int key;
public String val;
public Pair(int key, String val) {
this.key = key;
this.val = val;
}
}
/* 基于数组实现的哈希表 */
class ArrayHashMap {
private List<Pair> buckets;
public ArrayHashMap() {
// 初始化数组,包含 100 个桶
buckets = new ArrayList<>();
for (int i = 0; i < 100; i++) {
buckets.add(null);
}
}
/* 哈希函数 */
private int hashFunc(int key) {
int index = key % 100;
return index;
}
/* 查询操作 */
public String get(int key) {
int index = hashFunc(key);
Pair pair = buckets.get(index);
if (pair == null)
return null;
return pair.val;
}
/* 添加操作 */
public void put(int key, String val) {
Pair pair = new Pair(key, val);
int index = hashFunc(key);
buckets.set(index, pair);
}
/* 删除操作 */
public void remove(int key) {
int index = hashFunc(key);
// 置为 null ,代表删除
buckets.set(index, null);
}
/* 获取所有键值对 */
public List<Pair> pairSet() {
List<Pair> pairSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
pairSet.add(pair);
}
return pairSet;
}
/* 获取所有键 */
public List<Integer> keySet() {
List<Integer> keySet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
keySet.add(pair.key);
}
return keySet;
}
/* 获取所有值 */
public List<String> valueSet() {
List<String> valueSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
valueSet.add(pair.val);
}
return valueSet;
}
/* 打印哈希表 */
public void print() {
for (Pair kv : pairSet()) {
System.out.println(kv.key + " -> " + kv.val);
}
}
}哈希冲突与扩容
用数组实现难免会有些局限:用哈希函数的计算:index = hash(key) % capacity 当查询学号为 12836 和 20336 的两个学生时,我们得到:
java
12836 % 100 = 36
20336 % 100 = 36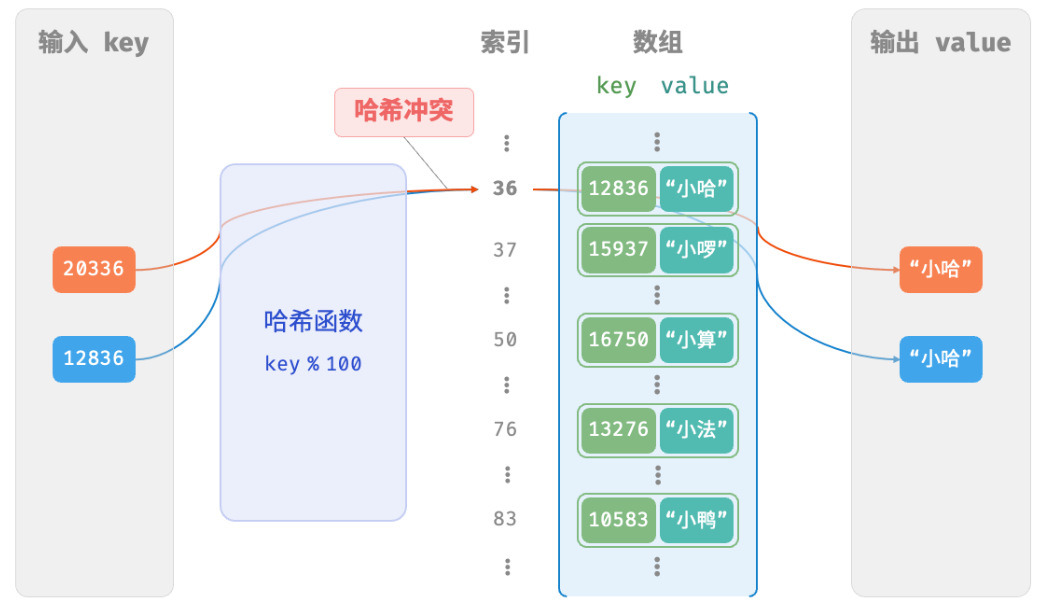
二. 我们运用链表来实现hash表:
链式地址(separate chaining)将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。

来看看什么是红黑树
从最基础的二叉树 出发,逐步深入到二叉搜索树 (BST),再引出其缺陷,最后讲解红黑树(Red-Black Tree)是如何解决这些问题的
1.1 什么是二叉树?
二叉树(Binary Tree) 是一种树形数据结构,其中每个节点最多有两个子节点:左孩子和右孩子。
bash
A
/ \
B C
/
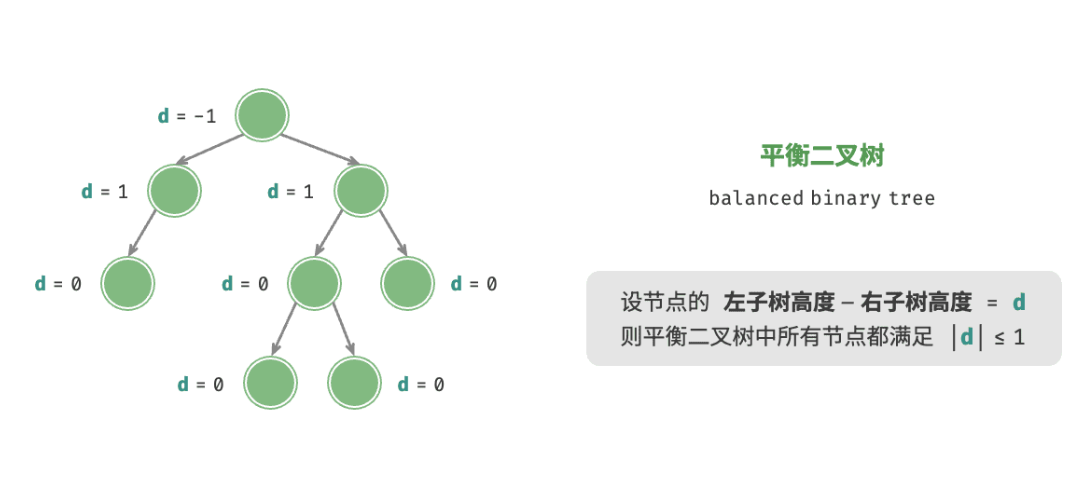
D1.2 什么是平衡二叉树?
平衡二叉树(balanced binary tree)中任意节点的左子树和右子树的高度之差的绝对值不超过 1
1.3. 什么是二叉搜索树?
二叉搜索树(Binary Search Tree, BST) 是一种特殊的二叉树,满足以下性质:
- 对于任意节点 node:
- 左子树中所有节点的值 < node 的值;
- 右子树中所有节点的值 > node 的值;
- 左右子树也都是 BST。
java
50
/ \
30 70
/ \ / \
20 40 60 80-
搜索二叉树的优点 :
查找、插入、删除 平均时间复杂度为 O(log n)(当树"平衡"时)。 -
致命缺陷:可能退化
如果插入的数据是有序的(如 1, 2, 3, 4, 5),BST 会变成一条链
bash
1
\
2
\
3
\
4
\
5⚠️此时:查找 5 需要遍历 5 次 → 时间复杂度 O(n)
3. 如何让 BST 自动平衡?→ 引入平衡树
为了解决 BST 退化问题,科学家提出了自平衡二叉搜索树,主要有两类:
AVL 树( 平衡二叉搜索树 ) :严格平衡(左右子树高度差 ≤ 1)AVL 树既是二叉搜索树,也是平衡二叉树,同时满足这两类二叉树的所有性质,因此是一种平衡二叉搜索树(balanced binary search tree)。
红黑树:近似平衡(最长路径 ≤ 2 × 最短路径)
4. 红黑树(Red-Black Tree)
4.1 红黑树是什么?
红黑树 是一种带颜色标记的自平衡二叉搜索树。它在 BST 的基础上,给每个节点增加一个颜色属性(红或黑),并通过5条规则强制树保持"近似平衡"。
4.2 红黑树的 5 条核心规则(性质)
- 每个节点是红色或黑色
- 根节点必须是黑色
- 所有叶子节点 (NIL 节点)都是黑色
注意:这里的"叶子"指空指针(nullptr),视为黑色哨兵节点 - 红色节点的两个子节点必须是黑色
即:不能有两个连续的红色节点 - 从任意节点到其所有 NIL 叶子的路径上,黑色节点 数量相同
这个数量称为 黑高(Black Height)
关键推导:
- 设黑高为 bh(从根到 NIL 的黑色节点数)
- 最短路径:全是黑色节点 → 长度 = bh
- 最长路径:红黑交替(因不能连续红)→ 长度 ≤ 2 × bh
🧩🧩因此:最长路径 ≤ 2 × 最短路径
4.3 红黑树的复杂度
- 查找:
红黑树查找时间复杂度: O(log n) ,因为其也是二叉搜索树呢 - 添加:
- 添加先要从根节点开始找到元素添加的位置, 时间复杂度: O (log n)
- 添加完成后 要旋转操作, 复杂度为O(log n)
- 故时间复杂度为: O(log n)
- 删除:
从根节点开始找到被删除元素的位置, 时间复杂度度O(log n)
完成后 要旋转操作, 复杂度为O(log n)
故时间复杂度为: O(log n)
🙌🙌🙌 最后总结一下吧:
HashMap的实现原理:
- 底层使用hash表数据结构, 即数组+ (链表 | 红黑树) ( JDK1.8之前采用拉链法(数组加链表), JDK1.8之后采用数组+链表+红黑树( 链表长度大于8且数组长度大于64则会从链表转化为红黑树 ) )
- 添加数据时, 计算key值确定元素在数组中的下标
- key相同则替换
- 不同则存入链表或者红黑树
- 获取数据通过key的hash计算数组下标获取元素
也是因为以上结构大大减少增删改查的时间复杂度
小白啊!!!写的不好轻喷啊🤯如果觉得写的不好,点个赞吧🤪(批评是我写作的动力)
...。。。。。。。。。。。...
...。。。。。。。。。。。...