

Python入门:Python3基础练习题详解,从入门到熟练的 25 个实例(六)
Python入门:Python3基础练习题详解,从入门到熟练的 25 个实例(六),本文是Python3练习题(126-150)的学习教程,涵盖字符串处理、列表操作、字典使用、正则表达式等内容。文中对每道题都给出了实现代码及详细解释,如字符串转整数、列表交集与并集获取、重复元素查找、数字总和计算、字符串排序、列表合并为字典、找最大值、列表排序、提取数字、获取最后一个单词等。通过这些练习,能帮助初学者巩固基础知识,加深对Python语法和数据结构的理解,提升编程能力。

前言
Python作为一门简洁、易读、功能强大的编程语言,其基础语法是入门学习的核心。掌握好基础语法,能为后续的编程实践打下坚实的基础。本文将全面讲解Python3的基础语法知识,适合编程初学者系统学习。Python以其简洁优雅的语法和强大的通用性,成为当今最受欢迎的编程语言。本专栏旨在系统性地带你从零基础入门到精通Python核心。无论你是零基础小白还是希望进阶的专业开发者,都将通过清晰的讲解、丰富的实例和实战项目,逐步掌握语法基础、核心数据结构、函数与模块、面向对象编程、文件处理、主流库应用(如数据分析、Web开发、自动化)以及面向对象高级特性,最终具备独立开发能力和解决复杂问题的思维,高效应对数据分析、人工智能、Web应用、自动化脚本等广泛领域的实际需求。


🥇 点击进入Python入门专栏,Python凭借简洁易读的语法,是零基础学习编程的理想选择。本专栏专为初学者设计,系统讲解Python核心基础:变量、数据类型、流程控制、函数、文件操作及常用库入门。通过清晰示例与实用小项目,助你快速掌握编程思维,打下坚实根基,迈出自动化办公、数据分析或Web开发的第一步。
🥇 点击进入Python小游戏实战专栏, 寓教于乐,用Python亲手打造经典小游戏!本专栏通过开发贪吃蛇、飞机大战、猜数字、简易版俄罗斯方块等趣味项目,在实践中掌握Python核心语法、面向对象编程、事件处理、图形界面(如Pygame)等关键技能,将枯燥的代码学习转化为可见的成果,让学习编程充满乐趣与成就感,快速提升实战能力。
🥇 点击进入Python小工具实战专栏,告别重复劳动,用Python打造效率神器!本专栏教你开发文件批量处理、自动邮件通知、简易爬虫、桌面提醒、密码生成器、天气查询等实用小工具。聚焦os、shutil、requests、smtplib、schedule等核心库,通过真实场景案例,快速掌握自动化脚本编写技巧,解放双手,显著提升工作与生活效率,让代码真正服务于你的日常。
🥇 点击进入Python爬虫实战专栏,解锁网络数据宝库!本专栏手把手教你使用Python核心库(如requests、BeautifulSoup、Scrapy)构建高效爬虫。从基础网页解析到动态页面抓取、数据存储(CSV/数据库)、反爬策略应对及IP代理使用,通过实战项目(如电商比价、新闻聚合、图片采集、舆情监控),掌握合法合规获取并利用网络数据的核心技能,让数据成为你的超能力。
🥇 点击进入Python项目实战专栏,告别碎片化学习,挑战真实项目!本专栏精选Web应用开发(Flask/Django)、数据分析可视化、自动化办公系统、简易爬虫框架、API接口开发等综合项目。通过需求分析、架构设计、编码实现、测试部署的全流程,深入掌握工程化开发、代码复用、调试排错与团队协作核心能力,积累高质量作品集,真正具备解决复杂问题的Python实战经验。
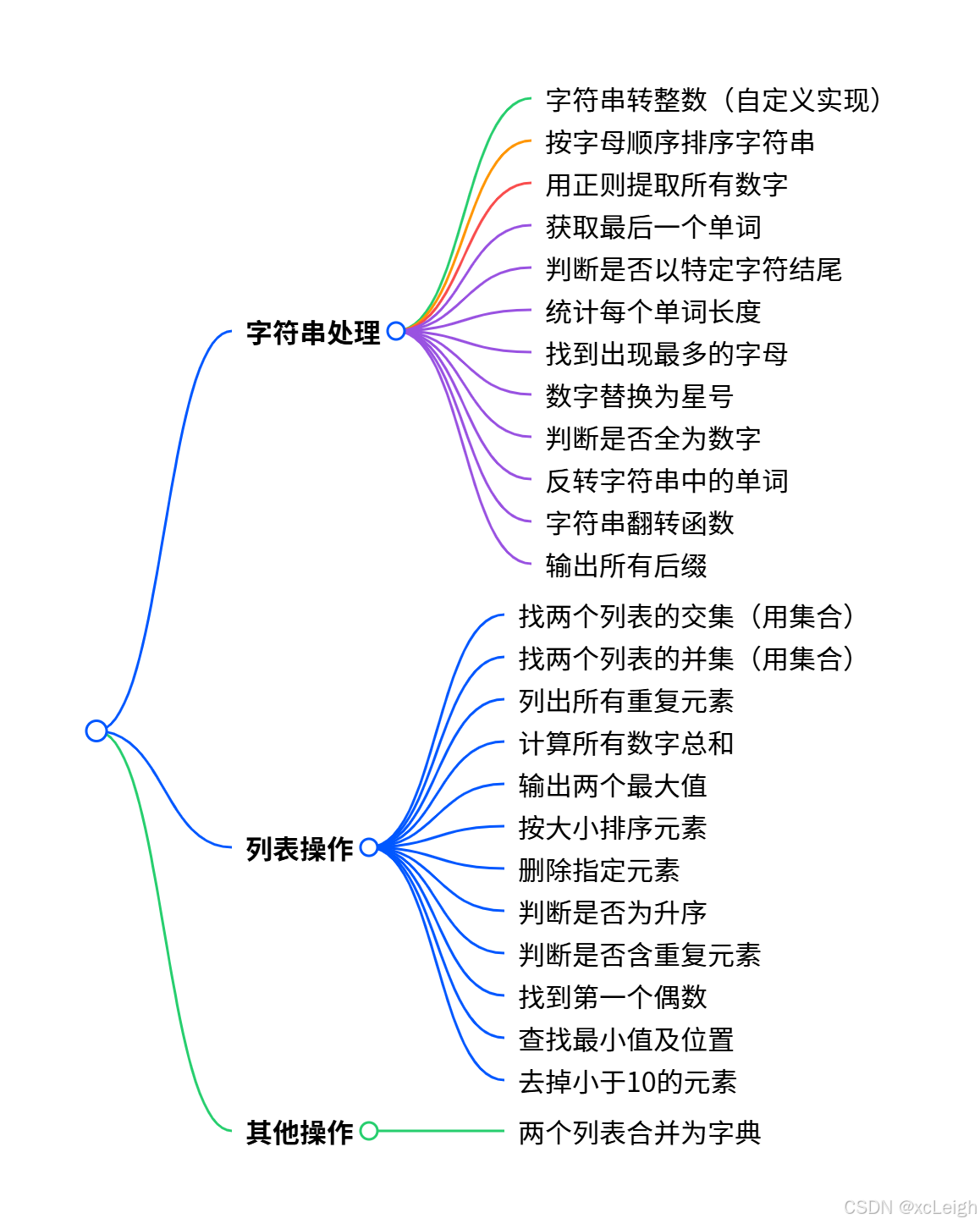
🌐 前篇文章咱们练习了 Python3基础练习题详解,从入门到熟练的 25 个实例(五) ,如果忘记了,可以去重温一下,不停的重复敲击基础代码,有助于让你更加熟练掌握一门语言。今天咱们继续,八篇教程练习题实例 ,Python3基础练习题详解,从入门到熟练的 25 个实例(六),下面开始吧!
大家好,今天为大家带来 Python3 练习题(126-150)的详细解析和代码实现。这些练习题涵盖了字符串处理、列表操作、字典使用、正则表达式等多个方面,非常适合 Python 初学者巩固基础知识。下面我们逐个来看:
126. 实现一个字符串到整数的转换(类似 int() 函数)
这个题目要求我们自己实现字符串转整数的功能,类似 Python 内置的 int() 函数。
python
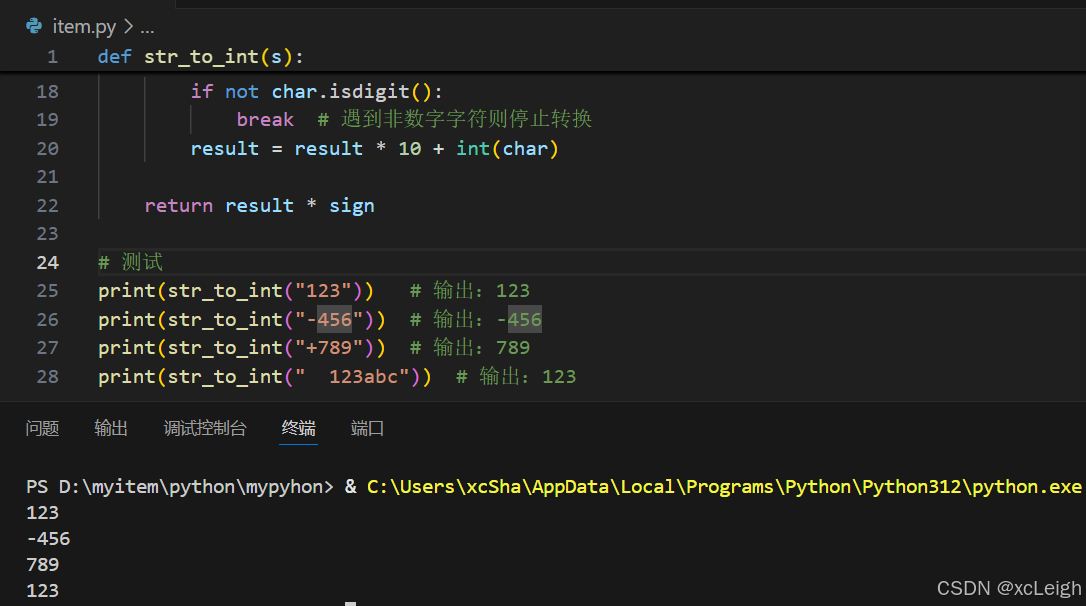
def str_to_int(s):
# 去除首尾空格
s = s.strip()
if not s:
return 0
# 处理正负号
sign = 1
if s[0] == '-':
sign = -1
s = s[1:]
elif s[0] == '+':
s = s[1:]
# 转换数字
result = 0
for char in s:
if not char.isdigit():
break # 遇到非数字字符则停止转换
result = result * 10 + int(char)
return result * sign
# 测试
print(str_to_int("123")) # 输出:123
print(str_to_int("-456")) # 输出:-456
print(str_to_int("+789")) # 输出:789
print(str_to_int(" 123abc")) # 输出:123控制台输出
代码解释:
- 首先去除字符串首尾的空格,避免空格影响转换
- 判断字符串是否为空,为空则返回 0
- 处理可能的正负号,记录符号并去除符号字符
- 遍历字符串中的每个字符,将其转换为数字并累加
- 遇到非数字字符则停止转换,返回结果乘以符号
127. 使用集合找出两个列表的交集
集合(Set)在 Python 中具有天然的集合运算能力,非常适合用来求交集。
python
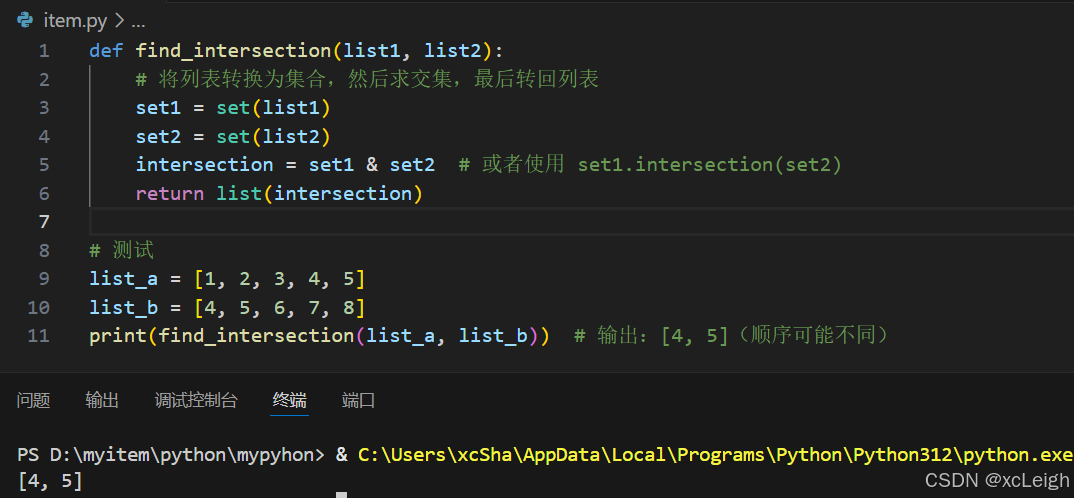
def find_intersection(list1, list2):
# 将列表转换为集合,然后求交集,最后转回列表
set1 = set(list1)
set2 = set(list2)
intersection = set1 & set2 # 或者使用 set1.intersection(set2)
return list(intersection)
# 测试
list_a = [1, 2, 3, 4, 5]
list_b = [4, 5, 6, 7, 8]
print(find_intersection(list_a, list_b)) # 输出:[4, 5](顺序可能不同)控制台输出
代码解释:
- 将两个列表分别转换为集合,利用集合的特性自动去重
- 使用 & 运算符(或 intersection() 方法)求两个集合的交集
- 将结果转换回列表并返回
128. 使用集合找出两个列表的并集
与求交集类似,我们可以使用集合来求两个列表的并集。
python
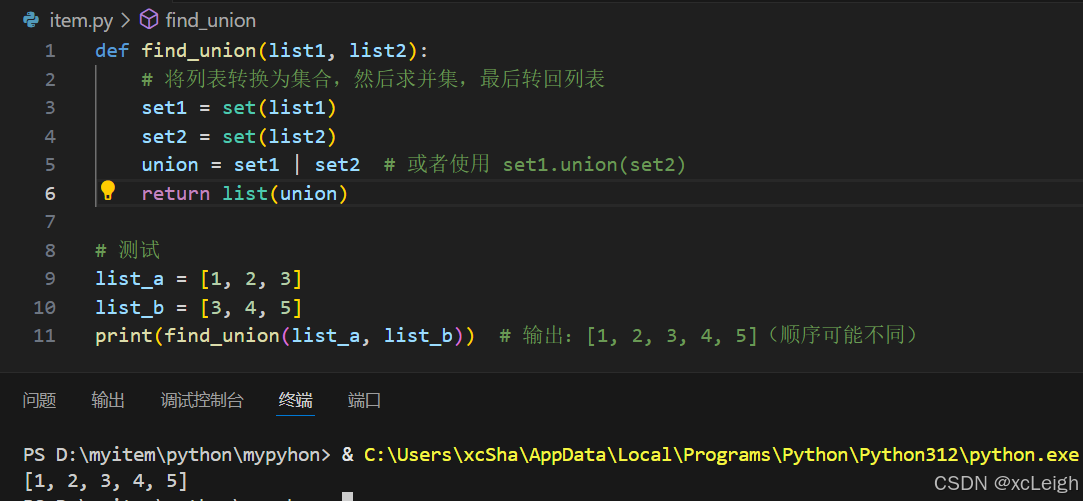
def find_union(list1, list2):
# 将列表转换为集合,然后求并集,最后转回列表
set1 = set(list1)
set2 = set(list2)
union = set1 | set2 # 或者使用 set1.union(set2)
return list(union)
# 测试
list_a = [1, 2, 3]
list_b = [3, 4, 5]
print(find_union(list_a, list_b)) # 输出:[1, 2, 3, 4, 5](顺序可能不同)控制台输出
代码解释:
- 将两个列表分别转换为集合
- 使用 | 运算符(或 union() 方法)求两个集合的并集
- 将结果转换回列表并返回,结果中不会有重复元素
129. 列出一个列表中的所有重复元素
要找出列表中的重复元素,我们可以统计每个元素的出现次数,然后筛选出出现次数大于 1 的元素。
python
def find_duplicates(lst):
# 创建一个字典来统计元素出现的次数
count_dict = {}
for item in lst:
if item in count_dict:
count_dict[item] += 1
else:
count_dict[item] = 1
# 筛选出出现次数大于1的元素
duplicates = [item for item, count in count_dict.items() if count > 1]
return duplicates
# 测试
my_list = [1, 2, 3, 2, 4, 5, 3, 6]
print(find_duplicates(my_list)) # 输出:[2, 3]控制台输出
代码解释:
- 创建一个字典用于记录每个元素出现的次数
- 遍历列表,更新每个元素的出现次数
- 使用列表推导式筛选出出现次数大于 1 的元素
- 返回这些重复元素组成的列表
130. 计算列表中所有数字的总和
计算列表中所有数字的总和,可以使用循环累加,也可以使用 Python 内置的 sum() 函数。
python
def calculate_sum(lst):
# 方法1:使用循环
total = 0
for num in lst:
total += num
return total
# 方法2:使用内置函数
# return sum(lst)
# 测试
numbers = [1, 2, 3, 4, 5]
print(calculate_sum(numbers)) # 输出:15控制台输出
代码解释:
- 初始化一个变量 total 为 0
- 遍历列表中的每个数字,将其加到 total 上
- 返回 total 的值
- 也可以直接使用 Python 内置的 sum() 函数,更加简洁
131. 按字母顺序对字符串进行排序
要按字母顺序对字符串进行排序,我们可以先将字符串转换为列表,排序后再转换回字符串。
python
def sort_string(s):
# 将字符串转换为列表,排序后再连接成字符串
sorted_chars = sorted(s)
return ''.join(sorted_chars)
# 测试
my_string = "python"
print(sort_string(my_string)) # 输出:"hnopty"代码解释:
- 使用 sorted() 函数对字符串进行排序,sorted() 会返回一个排序后的字符列表
- 使用 join() 方法将排序后的字符列表连接成字符串
- 返回排序后的字符串
132. 将两个列表合并成一个字典
将两个列表合并成一个字典,其中一个列表作为键,另一个列表作为值。
python
def merge_to_dict(keys, values):
# 使用 zip() 函数将两个列表合并为字典
# 只合并到较短列表的长度
return dict(zip(keys, values))
# 测试
key_list = ['name', 'age', 'gender']
value_list = ['Alice', 25, 'female']
result_dict = merge_to_dict(key_list, value_list)
print(result_dict) # 输出:{'name': 'Alice', 'age': 25, 'gender': 'female'}代码解释:
- 使用 zip() 函数将两个列表中的元素一一对应地组合起来
- 使用 dict() 函数将 zip 对象转换为字典
- 如果两个列表长度不同,结果字典的长度将与较短的列表相同
133. 实现一个函数,输出一个数字列表中的两个最大值
要找出列表中的两个最大值,我们可以先排序,也可以通过一次遍历找到。
python
def find_two_largest(numbers):
if len(numbers) < 2:
return None # 列表元素不足两个
# 初始化两个最大值
first_max = second_max = float('-inf')
for num in numbers:
if num > first_max:
# 如果当前数字大于第一个最大值,则更新两个最大值
second_max = first_max
first_max = num
elif num > second_max:
# 如果当前数字大于第二个最大值,但小于第一个最大值,则更新第二个最大值
second_max = num
return first_max, second_max
# 测试
num_list = [5, 2, 9, 1, 7]
print(find_two_largest(num_list)) # 输出:(9, 7)代码解释:
- 先判断列表长度,如果不足两个元素则返回 None
- 初始化两个最大值变量为负无穷
- 遍历列表中的每个数字:
- 如果数字大于第一个最大值,则更新第二个最大值为原来的第一个最大值,同时更新第一个最大值
- 如果数字大于第二个最大值但小于第一个最大值,则只更新第二个最大值
- 返回找到的两个最大值
134. 将给定列表的元素按大小排序
对列表进行排序,可以使用列表的 sort() 方法(原地排序)或内置的 sorted() 函数(返回新列表)。
python
def sort_list(lst):
# 方法1:使用 sorted() 函数,返回新列表
return sorted(lst)
# 方法2:使用 list.sort() 方法,原地排序
# new_lst = lst.copy()
# new_lst.sort()
# return new_lst
# 测试
my_list = [3, 1, 4, 1, 5, 9, 2, 6]
print(sort_list(my_list)) # 输出:[1, 1, 2, 3, 4, 5, 6, 9]代码解释:
- 这里使用了 sorted() 函数,它会返回一个新的排序后的列表,不改变原列表
- 也可以使用列表的 sort() 方法,该方法会直接修改原列表
- 默认是升序排序,如果需要降序,可以添加 reverse=True 参数
135. 使用正则表达式从字符串中提取所有数字
要从字符串中提取所有数字,我们可以使用 re 模块的 findall() 函数。
python
import re
def extract_numbers(s):
# 使用正则表达式提取所有数字
# \d+ 匹配一个或多个数字
numbers = re.findall(r'\d+', s)
# 转换为整数
return [int(num) for num in numbers]
# 测试
my_string = "abc123def456ghi789"
print(extract_numbers(my_string)) # 输出:[123, 456, 789]代码解释:
- 导入 re 模块,用于处理正则表达式
- 使用 re.findall(r'\d+', s) 查找字符串中所有的数字序列
- \d+ 是一个正则表达式模式,表示匹配一个或多个数字
- 将提取到的数字字符串转换为整数并返回
136. 获取字符串的最后一个单词
要获取字符串的最后一个单词,我们可以先去除首尾空格,然后按空格分割,再取最后一个元素。
python
def get_last_word(s):
# 去除首尾空格,然后按空格分割
words = s.strip().split()
if not words:
return "" # 字符串为空或只包含空格
return words[-1]
# 测试
my_string = "Hello world, this is a test"
print(get_last_word(my_string)) # 输出:"test"代码解释:
- 使用 strip() 方法去除字符串首尾的空格
- 使用 split() 方法按空格分割字符串,得到一个单词列表
- 如果列表为空(字符串为空或只包含空格),返回空字符串
- 否则返回列表的最后一个元素,即最后一个单词
137. 删除列表中的指定元素
删除列表中的指定元素,可以使用列表推导式,也可以使用循环遍历删除。
python
def remove_element(lst, element):
# 方法1:使用列表推导式
return [item for item in lst if item != element]
# 方法2:使用循环
# new_lst = []
# for item in lst:
# if item != element:
# new_lst.append(item)
# return new_lst
# 测试
my_list = [1, 2, 3, 2, 4, 2]
print(remove_element(my_list, 2)) # 输出:[1, 3, 4]代码解释:
- 使用列表推导式遍历原列表,只保留不等于指定元素的项
- 返回新的列表,原列表不会被修改
- 这种方法会删除所有等于指定元素的项
138. 判断列表是否为升序
判断列表是否为升序,即判断每个元素是否小于或等于后一个元素。
python
def is_ascending(lst):
# 遍历列表,检查每个元素是否小于等于下一个元素
for i in range(len(lst) - 1):
if lst[i] > lst[i + 1]:
return False
return True
# 测试
print(is_ascending([1, 2, 3, 4, 5])) # 输出:True
print(is_ascending([1, 3, 2, 4, 5])) # 输出:False代码解释:
- 遍历列表,从第一个元素到倒数第二个元素
- 对于每个元素,检查它是否大于下一个元素
- 如果找到任何一个元素大于下一个元素,返回 False
- 如果遍历完所有元素都满足升序条件,返回 True
139. 判断字符串是否以特定字符结尾
判断字符串是否以特定字符结尾,可以使用字符串的 endswith() 方法。
python
def ends_with_char(s, char):
# 确保 char 是单个字符
if len(char) != 1:
return False
# 使用 endswith() 方法判断
return s.endswith(char)
# 测试
my_string = "Hello world"
print(ends_with_char(my_string, "d")) # 输出:True
print(ends_with_char(my_string, "l")) # 输出:False代码解释:
- 首先检查输入的字符是否是单个字符
- 使用字符串的 endswith() 方法判断字符串是否以指定字符结尾
- 返回布尔值结果
140. 统计字符串中每个单词的长度
要统计字符串中每个单词的长度,我们可以先分割字符串得到单词列表,再计算每个单词的长度。
python
def word_lengths(s):
# 分割字符串得到单词列表
words = s.split()
# 计算每个单词的长度,返回一个字典
return {word: len(word) for word in words}
# 测试
my_string = "Hello world this is a test"
print(word_lengths(my_string))
# 输出:{'Hello': 5, 'world': 5, 'this': 4, 'is': 2, 'a': 1, 'test': 4}代码解释:
- 使用 split() 方法分割字符串,得到单词列表
- 使用字典推导式创建一个字典,键是单词,值是单词的长度
- 返回这个字典
141. 判断列表中是否包含重复元素
判断列表中是否包含重复元素,可以使用集合来实现,因为集合中不能有重复元素。
python
def has_duplicates(lst):
# 如果列表长度大于集合长度,则说明有重复元素
return len(lst) != len(set(lst))
# 测试
print(has_duplicates([1, 2, 3, 4, 5])) # 输出:False
print(has_duplicates([1, 2, 3, 2, 5])) # 输出:True代码解释:
- 将列表转换为集合,集合会自动去除重复元素
- 比较原列表和集合的长度
- 如果长度不同,说明原列表中有重复元素,返回 True
- 否则返回 False
142. 找到字符串中出现最多的字母
要找到字符串中出现最多的字母,我们可以统计每个字母的出现次数,然后找出次数最多的。
python
def most_frequent_letter(s):
# 只考虑字母,忽略其他字符和大小写
letters = [c.lower() for c in s if c.isalpha()]
if not letters:
return None # 没有字母
# 统计每个字母出现的次数
count_dict = {}
for letter in letters:
count_dict[letter] = count_dict.get(letter, 0) + 1
# 找到出现次数最多的字母
max_count = max(count_dict.values())
# 可能有多个字母出现次数相同且都是最多
most_frequent = [letter for letter, count in count_dict.items() if count == max_count]
return most_frequent
# 测试
my_string = "Hello world, this is a test string."
print(most_frequent_letter(my_string)) # 输出:['t']代码解释:
- 首先过滤出字符串中的字母,并转换为小写,统一大小写
- 如果没有字母,返回 None
- 创建一个字典统计每个字母出现的次数
- 找到最大的出现次数
- 找出所有出现次数等于最大次数的字母并返回
143. 将字符串中的所有数字替换为星号
将字符串中的所有数字替换为星号,可以使用正则表达式,也可以使用循环。
python
import re
def replace_numbers_with_asterisk(s):
# 方法1:使用正则表达式
return re.sub(r'\d', '*', s)
# 方法2:使用循环
# result = []
# for char in s:
# if char.isdigit():
# result.append('*')
# else:
# result.append(char)
# return ''.join(result)
# 测试
my_string = "abc123def456ghi789"
print(replace_numbers_with_asterisk(my_string)) # 输出:"abc***def***ghi***"控制台输出
代码解释:
- 这里使用了
re.sub()函数,它可以将匹配正则表达式的部分替换为指定字符串 r'\d'是匹配单个数字的正则表达式模式- 将所有匹配到的数字替换为星号
* - 也可以通过循环遍历每个字符,判断是否为数字并替换,最后拼接成新字符串
144. 在列表中找到第一个偶数
要找到列表中的第一个偶数,只需遍历列表并判断每个元素是否为偶数即可。
python
def find_first_even(lst):
for num in lst:
# 检查是否为整数且是偶数
if isinstance(num, int) and num % 2 == 0:
return num
return None # 没有找到偶数
# 测试
numbers = [1, 3, 5, 4, 7, 8]
print(find_first_even(numbers)) # 输出:4
print(find_first_even([1, 3, 5, 7])) # 输出:None代码解释:
- 遍历列表中的每个元素
- 先判断元素是否为整数(避免非数字类型报错),再判断是否为偶数(
num % 2 == 0) - 找到第一个满足条件的偶数后立即返回
- 如果遍历完列表都没有找到偶数,返回
None
145. 查找列表中的最小值及其位置
查找列表中的最小值及其位置,可以通过遍历列表记录最小值和对应的索引。
python
def find_min_and_index(lst):
if not lst:
return None # 列表为空
min_value = lst[0]
min_index = 0
for i in range(1, len(lst)):
if lst[i] < min_value:
min_value = lst[i]
min_index = i
return min_value, min_index
# 测试
numbers = [5, 2, 9, 1, 7, 1]
print(find_min_and_index(numbers)) # 输出:(1, 3)代码解释:
- 先判断列表是否为空,为空则返回
None - 初始化最小值为列表第一个元素,对应的索引为 0
- 从第二个元素开始遍历列表:
- 如果当前元素小于记录的最小值,则更新最小值和索引
- 遍历结束后,返回最小值和其首次出现的索引
146. 判断字符串是否由数字组成
判断字符串是否全为数字,可以使用字符串的 isdigit() 方法。
python
def is_all_digits(s):
# 空字符串返回False
if not s:
return False
# 检查所有字符是否都是数字
return s.isdigit()
# 测试
print(is_all_digits("12345")) # 输出:True
print(is_all_digits("123abc")) # 输出:False
print(is_all_digits("")) # 输出:False代码解释:
- 首先判断字符串是否为空,空字符串返回
False - 使用
isdigit()方法检查字符串中的所有字符是否都是数字 - 该方法对 Unicode 数字也有效(如中文数字"一二三"返回
False,阿拉伯数字"123"返回True)
147. 去掉列表中所有小于10的元素
可以通过列表推导式筛选出大于等于10的元素。
python
def remove_less_than_10(lst):
# 保留大于等于10的元素
return [num for num in lst if num >= 10]
# 测试
numbers = [5, 12, 8, 15, 3, 20, 9]
print(remove_less_than_10(numbers)) # 输出:[12, 15, 20]代码解释:
- 使用列表推导式遍历原列表
- 只保留满足条件
num >= 10的元素 - 返回新列表,原列表不会被修改
148. 将字符串中的单词反转
将字符串中的单词反转(如"Hello world"→"world Hello"),可以先分割单词再反向拼接。
python
def reverse_words(s):
# 分割单词,再反转列表,最后拼接
words = s.split()
reversed_words = words[::-1]
return ' '.join(reversed_words)
# 测试
my_string = "Hello world this is a test"
print(reverse_words(my_string)) # 输出:"test a is this world Hello"代码解释:
- 使用
split()方法按空格分割字符串得到单词列表 - 使用切片
[::-1]反转单词列表 - 使用
join()方法将反转后的单词列表拼接成字符串,单词间用空格分隔
149. 实现一个字符串翻转的函数
翻转字符串可以使用切片操作,也可以通过循环实现。
python
def reverse_string(s):
# 方法1:使用切片
return s[::-1]
# 方法2:使用循环
# reversed_str = ''
# for char in s:
# reversed_str = char + reversed_str
# return reversed_str
# 测试
my_string = "Python"
print(reverse_string(my_string)) # 输出:"nohtyP"代码解释:
- 切片
s[::-1]表示从字符串末尾开始,步长为 -1,即反转字符串,简洁高效 - 循环方法通过遍历每个字符,将其拼接到结果字符串的前面,也能实现翻转
- 两种方法都返回新字符串,不修改原字符串
150. 输出一个字符串的所有后缀
字符串的后缀指从每个位置开始到结尾的子串(如"abc"的后缀为"abc""bc""c")。
python
def get_all_suffixes(s):
# 从索引0到len(s)-1,依次取子串
return [s[i:] for i in range(len(s))]
# 测试
my_string = "test"
print(get_all_suffixes(my_string)) # 输出:['test', 'est', 'st', 't']代码解释:
- 使用列表推导式遍历字符串的索引(从 0 到长度-1)
- 对于每个索引
i,取子串s[i:](从i位置到字符串结尾) - 返回所有后缀组成的列表
总结
以上就是 Python3 练习题 126-150 的详细解析和实现。这些题目覆盖了 Python 中字符串、列表、字典、集合等核心数据结构的操作,以及正则表达式的基础应用。通过练习这些题目,可以帮助初学者加深对 Python 语法和数据结构的理解,提高编程能力。
如果大家在练习过程中有任何疑问,欢迎在评论区留言讨论!
💡下一篇咱们学习 Python3基础练习题详解,从入门到熟练的 25 个实例(七)!
附录:扩展学习资源
- 官方资源 :
- Python官网:https://www.python.org
- PyPI:https://pypi.org(查找第三方库)
- 安装包等相关文件(另附带pycharm工具),网盘下载地址:https://pan.quark.cn/s/649af731037c
- 学习资料视频和文档资源,网盘下载地址: https://pan.quark.cn/s/ee16901a8954
- 本专栏特色资源 :
- 代码资源仓库:CSDN专属资源在线获取
- 海量Python教程 :关注公众号:xcLeigh,获取网盘地址
- 一对一答疑 :添加微信与博主在线沟通(
备注"Python专栏")
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注 :本文撰写于CSDN平台 ,作者:xcLeigh (所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌