自 KAT-Coder-Pro V1 发布以来,我们持续收到来自一线开发者的宝贵反馈与建议。这些真实的使用洞察,驱动我们在实际应用场景中不断打磨拓展 KAT 系列模型的能力边界。
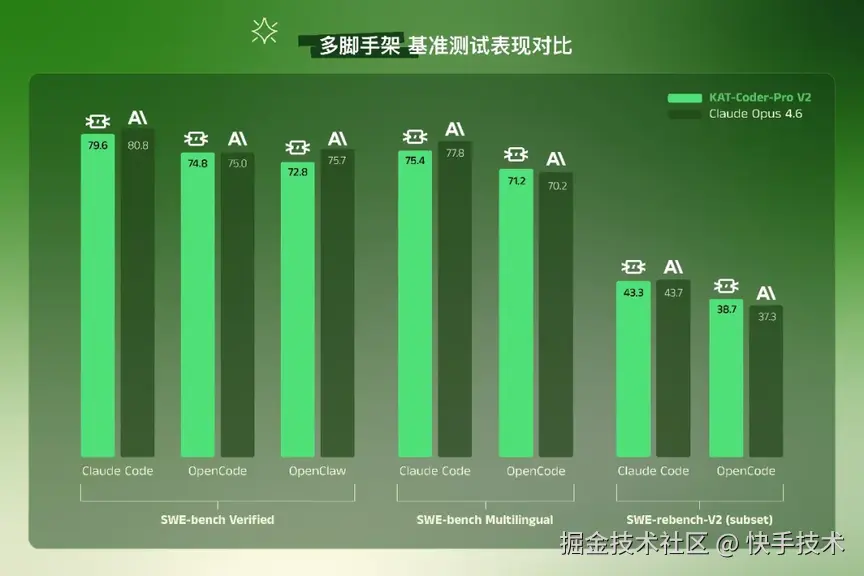
KAT-Coder-Pro V2 是 KwaiKAT 最新打造的旗舰级 Agentic Coding 模型。在 Agentic 场景下,KAT-Coder-Pro V2 具备强大的脚手架泛化能力 ,兼容 10 多种主流的 AI 编码工具,例如 Claude Code、Cline、Kilo、OpenCode,提供更大的灵活性。并针对 OpenClaw 进行了专项训练与深度优化,能够从容应对真实世界中的复杂应用流程。
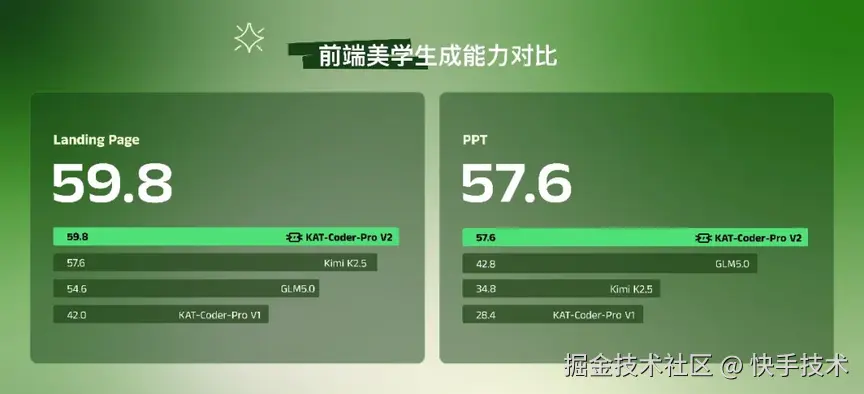
与此同时,KAT-Coder-Pro V2 在前端美学生成方向取得突破性进展------在 Landing Page 和 PPT 场景中,用户仅需口语化描述,即可获得接近结构化设计 spec 输入水平的高品质输出。这意味着模型的服务边界从过去仅 1% 量级的专业用户,真正扩展到亿级普通用户。
原生适配 OpenClaw,多 Agent 框架深度优化
在 AI Coding 的真实落地场景中,以 OpenClaw 为代表的 AI Agent 框架持续高频迭代,不断引入新工具与新协议,这对模型的脚手架泛化能力提出了巨大挑战。工具调用失败、多步任务中断、指令理解偏差,是模型在实际使用中频繁暴露的问题,而在高频使用场景下,这些问题会被成倍放大,直接影响用户体验。
模型能力的真正边界,不只是代码生成质量是否过关,更在于面对工具不断扩展、任务链路持续拉长的复杂环境时,能否在长程轨迹中始终准确理解用户意图,并在不同 Agent 框架下保持稳定、一致的表现。无论是 Claude Code 还是 OpenClaw,用户都应当能够无缝切换、放心使用,而不是在框架切换时重新踩坑。
为此,KAT-Coder 从数据构建到训练流程,围绕多脚手架泛化能力进行系统性设计,并针对 OpenClaw 使用场景从原生任务数据出发进行全链路专项优化------不仅覆盖脚手架协议理解与工具链调用,更在训练阶段对长链路执行稳定性进行深度强化。
最终评测结果显示,KAT-Coder 在复杂 Skills 遵循率与多步任务完成率上取得显著提升,在定时触发、高吞吐、长链路等高压场景下的执行效率与响应稳定性同步达到业界一流水平。

值得一提的是,KAT-Coder-Pro V2 的脚手架泛化能力并不局限于 OpenClaw 单一框架。我们同步在 Claude Code、OpenCode 等主流脚手架上进行了评测,结果表明模型在跨框架场景下同样具备出色的适配能力。
Web Coding - 当模型开始懂"美"

「打破旧共识:现有评测的系统性盲区」
当前主流的代码生成评测(如 WebArena 等),本质上都在玩"找不同"------给一张参考图,看 AI 照猫画虎还原得像不像。但这在"一句话生成网页"的场景里,存在严重的错位。
在商业化应用里: "代码跑得通"与"设计好看"是两码事。 代码还原度测的是"代码对不对"(有没有报错错位),靠算法就能算; 美学还原度测的是"页面好不好看",是高级的审美判断,代码跑通只是起跑线。
现有评测标准严重偏科,留下了六大盲区:
-
用户只给一句话,根本没有"标准答案"让 AI 去对比。
-
图像算法会给具有突破性的原创设计打低分。
-
静态截图根本抓不到交互动画的好坏。
-
算法无法量化"高端商务感"这类抽象词。
-
只看单个按钮好不好,不管整体排版搭不搭。
-
现有的算法打分反而会逼迫 AI 走向最平庸、最安全的设计。
「KAT Benchmark:立足专业设计的行业新标杆」
基于快手研发设计团队深厚的人文视觉与前端积淀,我们填补了空白,推出由专业设计师与合作团队校准完成的「KAT 美学 Benchmark」。
作为业界唯一针对"无参考图创作"的纯美学标准,它有四大优势:
-
坚持设计师人工盲测,拒绝唯算法论------真正的审美不可被机器替代。
-
首创 10 大独立评估维度,颗粒度远超学术界现有标准。
-
"出彩无瑕疵"才是满分,而不是"最像参考图",鼓励原创,惩罚平庸。
-
严苛的设计与评审机制,专业设计师团队在统一的标准屏幕下执行深度交互盲测
「拿数据说话」
在最严苛的尺子下,KAT 展现出统治力:
-
PPT 场景碾压 :总分 57.6,领先竞品 14~22 分,配色项高达 78 分;图片得分更是竞品的 5~8 倍。
-
Landing Page 霸榜 :总分 59.8 拿下第一,在配色、元素、布局建立起坚不可摧的优势。
-
震撼跃升 :对比上代基线,PPT 均分翻倍( +103% ),LP 提升 +42% ,元素单项暴增 +300% 。
在 Benchmark 上的每一次跨越,都在让"一句话生成专业级商业页面"一步步走向现实。
更强大的基座能力
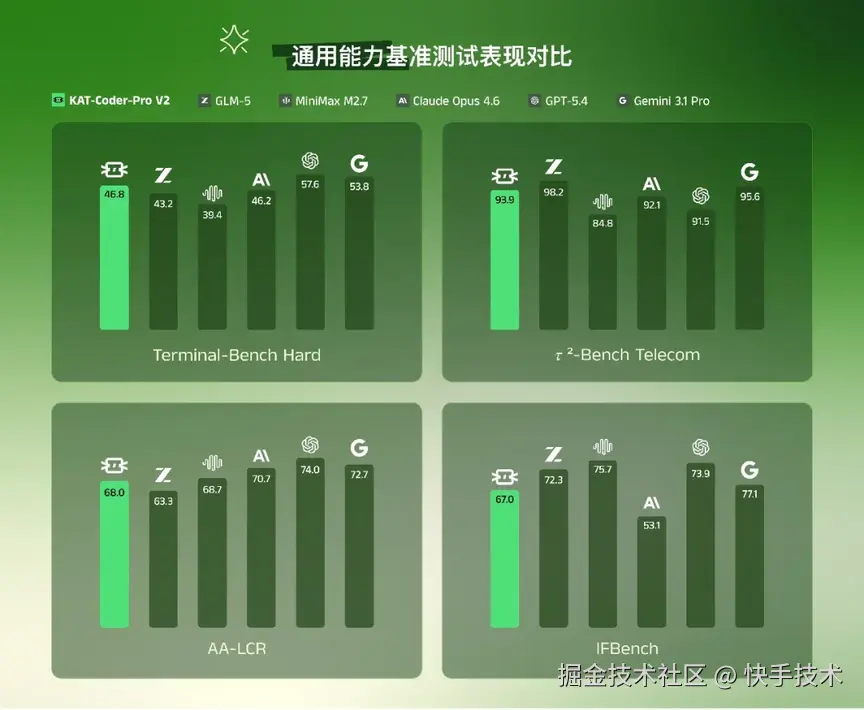
Agentic 场景下的复杂推理,离不开扎实的通用基座能力作为支撑。KAT-Coder-Pro V2 的基础模型在 Terminal-Bench Hard(46.8)、𝜏²-Bench Telecom(93.9)等主流基准上全面进入全球第一梯队,为上层 Coding 能力提供了坚实的底层保障。
现在开始
KAT-Coder-Pro V2 现已全量上线,用户可以通过以下方式立即体验:
方式一:API 调用
通过 StreamLake.com 平台直接调用模型 API,灵活集成到你的工作流中。
API KEY 申请:
方式二:Coding Plan 订阅
KAT-Coder-Pro V2 已纳入 Coding Plan 套餐,开箱即用。我们提供四档方案,你可以根据自己的使用频率按需选择:
Coding Plan 订阅:
www.streamlake.com/marketing/c...
开发工具接入指南:
www.streamlake.com/document/WA...
期待与开发者朋友们碰撞出更多火花。扫码即可进入「KwaiKAT 交流群」获取最新资讯!
