一、引言
在实际的爬虫开发中,我们经常会遇到两个棘手问题:一是目标网站采用POST方式加载列表数据,二是网站对访问IP存在频率限制。这两个问题的叠加,往往会让简单的爬虫方案失效。
本文将深入分析一个针对 polymerupdate.com 新闻站点的爬虫设计案例。该爬虫巧妙解决了 "POST请求分页控制" 和 "代理IP协同工作" 两大技术难题,实现了稳定可靠的数据采集。
核心挑战:
- 如何控制POST请求的分页参数?
- 如何配置代理IP规避访问限制?
- 如何在同一个流程中协调列表抓取和详情抓取?
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用 "预处理 + POST分页 + 代理转发 + 增量去重" 的架构,整体流程如下:
是
否
否
是
开始
时间范围计算
查询数据库已有记录
是否有新数据?
POST请求列表页
结束流程
提取URL列表
循环处理每条新闻
是否已存在?
通过代理抓取详情
提取详情数据
存入数据库
2.2 数据流向图
增量处理层
POST列表抓取层
预处理层
新URL
已存在
开始
动态计算时间范围
查询数据库
获取已抓取URL
POST请求列表页
携带表单参数
从响应中提取
新闻URL列表
分页控制
page<=1
循环遍历
每个URL
数据库去重判断
通过代理
抓取详情页
提取结构化数据
存入数据库
三、关键技术难点与解决方案
难点一:POST请求的分页控制
问题描述:
与常见的GET请求分页不同,该网站的列表数据需要通过POST请求提交表单参数获取。分页参数SearchCriteria[Page]需要放在请求体中,而非URL中。如何控制分页循环成为一个难题。
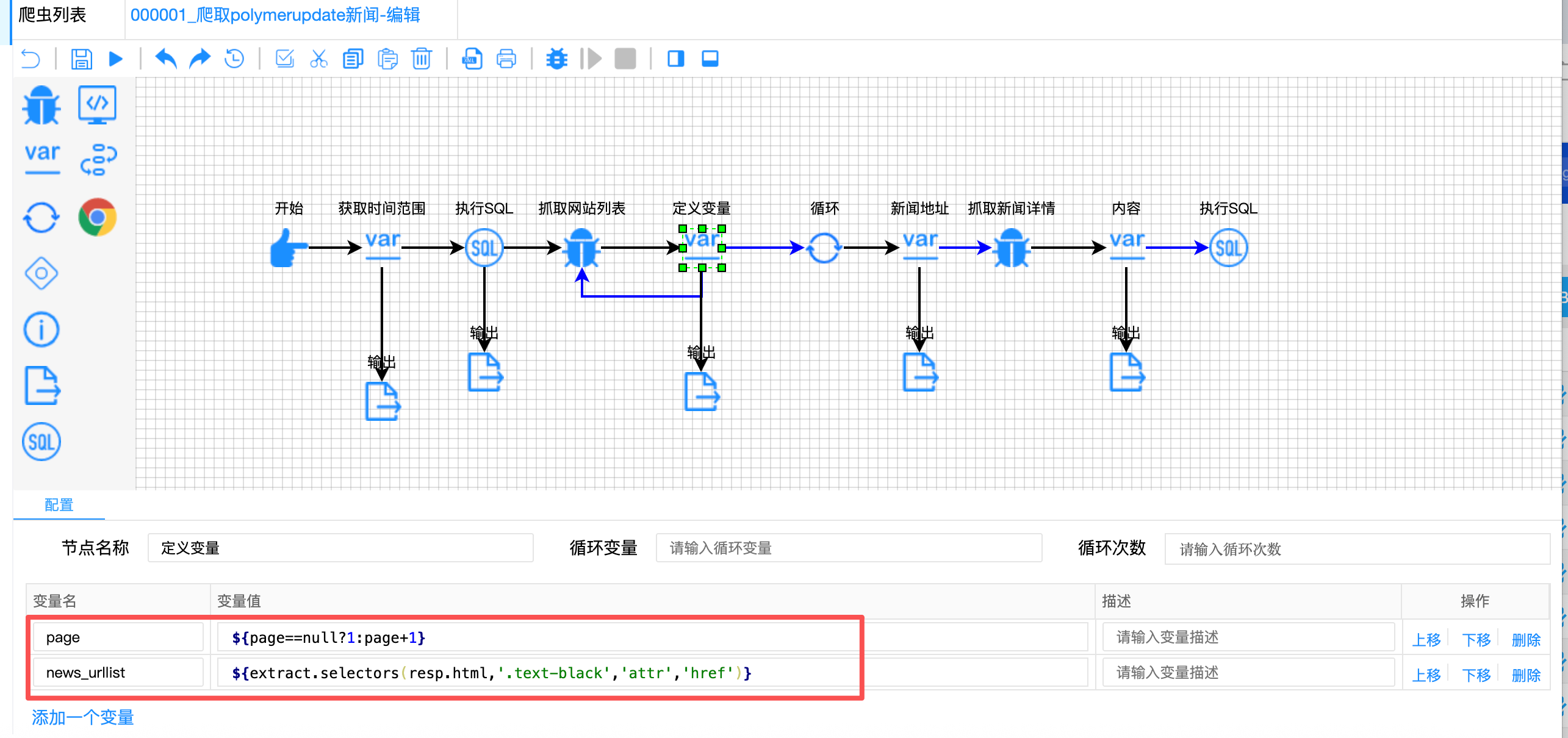
解决方案:
构建 "POST表单分页" 控制机制:
javascript
// 抓取网站列表节点配置
{
"value": "抓取网站列表",
"method": "POST",
"body-type": "form-data",
"parameter-form-name": ["SearchCriteria[Period]", "SearchCriteria[Page]"],
"parameter-form-value": ["180", "${page}"],
"url": "https://www.polymerupdate.com/PressRelease/Listing"
}
// 定义变量节点 - 分页控制
{
"variable-name": ["page", "news_urllist"],
"variable-value": [
"${page==null?1:page+1}",
"${extract.selectors(resp.html, '.text-black', 'attr', 'href')}"
]
}
// 循环条件控制(蓝色连线)
"condition": "${page<=1}"技术亮点:
- 动态表单参数 :
${page}变量动态注入POST表单,实现分页控制 - 三目运算符初始化 :
${page==null?1:page+1}实现page变量的自动初始化与递增 - 有限分页控制 :
${page<=1}控制只抓取第一页(业务需求为最近7天新闻,第一页足够)
POST分页原理示意图:
目标网站 变量节点 爬虫 目标网站 变量节点 爬虫 首次请求 Body: Period=180, Page=1 提取数据 第二次请求 Body: Period=180, Page=2 循环控制 page是否为null? 是,page=1 POST /PressRelease/Listing 返回第一页数据 提取URL列表 page = 1+1 = 2 POST /PressRelease/Listing 返回第二页数据 判断 page<=1 ? 2<=1为false,停止循环
难点二:代理IP的协同配置
问题描述:
该网站对访问频率较为敏感,直接使用服务器IP抓取容易被封。需要在详情页抓取时使用代理IP,但列表页抓取可能不需要代理。
解决方案:
在详情页请求节点配置代理IP:
javascript
// 抓取新闻详情节点配置
{
"value": "抓取新闻详情",
"method": "GET",
"sleep": "5000",
"timeout": "30000",
"retryCount": "3",
"retryInterval": "5000",
"url": "${news_url}",
"proxy": "192.168.xx.xx:xxx" // 代理IP配置
}代理流转示意图:
代理请求
无代理请求
是
列表页请求
直接连接
目标服务器
获取列表数据
详情页请求
代理服务器
192.168.30.47:7897
代理转发请求
到目标服务器
目标服务器响应
返回给代理
爬虫获取详情数据
是否需要抓取详情?
代理配置的关键考量:
- 精细化控制:只在详情页使用代理,列表页不使用,节省代理资源
- 请求间隔:5秒的sleep配合代理,有效规避封IP风险
- 重试机制:3次重试应对代理不稳定情况
难点三:动态时间范围的查询集成
问题描述:
爬虫需要抓取最近7天的新闻,但列表页本身没有时间过滤功能。需要结合数据库查询,只处理时间范围内的新闻。
解决方案:
集成动态时间范围查询:
javascript
// 获取时间范围节点
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-7),'yyyy-MM-dd')}",
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}"
]
}
// 执行SQL节点 - 查询已有数据
{
"statementType": "select",
"sql": "SELECT url FROM news\nwhere url like '%https://www.polymerupdate.com/PressRelease%' and \n(insert_date between '${start_date}' and '${end_date}');"
}时间范围与去重集成图:
动态计算 2024-01-08 start_date = now-7 2024-01-16 end_date = now+1 数据库查询 查询条件 between start_date and end_date 结果集rs 包含该时间范围内所有已抓取URL 去重应用 判断逻辑 !rs.contains(news_urlmap) 结果 新URL才抓取详情 时间范围与去重集成
难点四:URL提取与拼接的路径处理
问题描述:
列表页提取的href属性值是相对路径,需要拼接为完整的URL。同时,新闻ID需要从URL中提取。
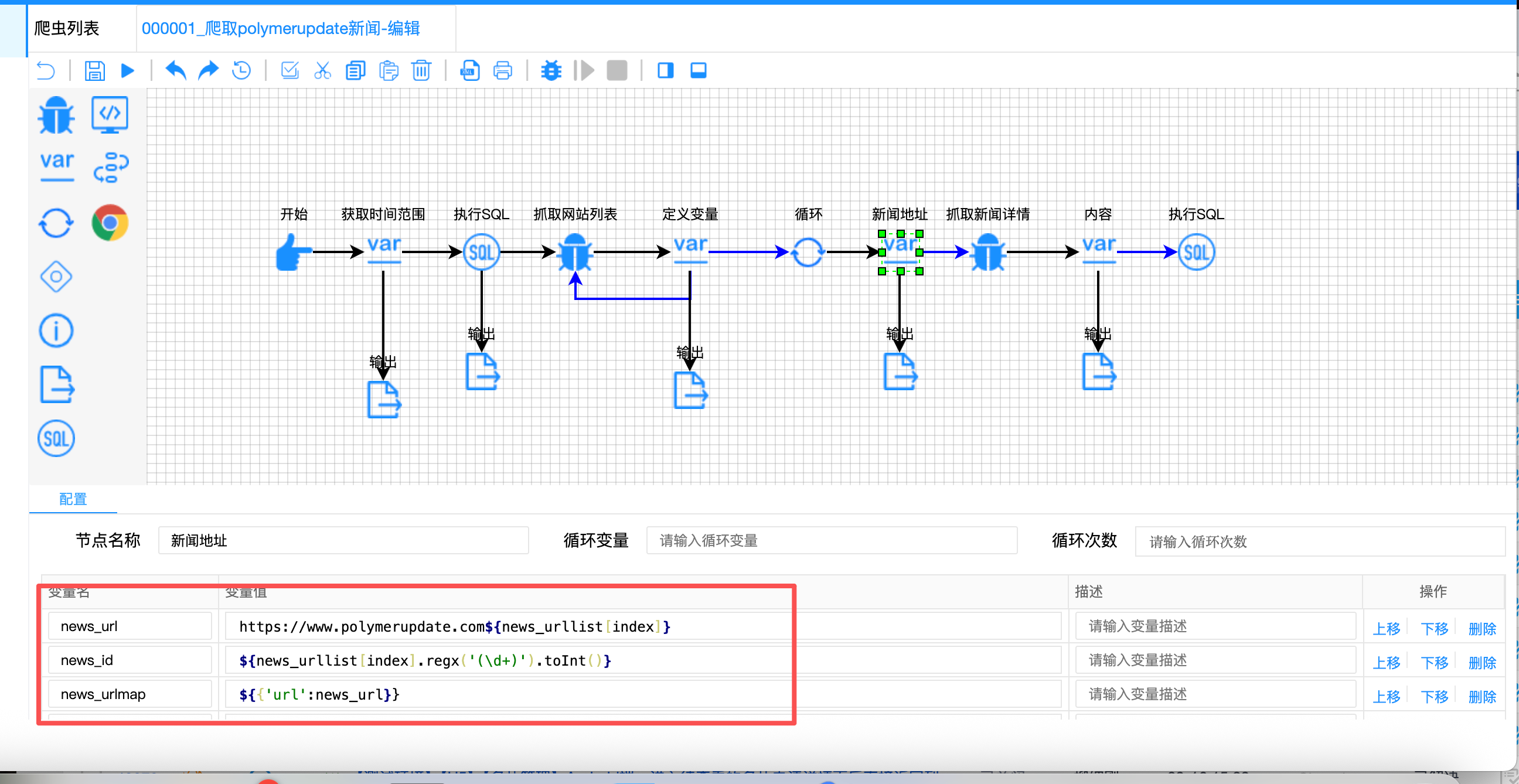
解决方案:
采用 "动态拼接 + 正则提取" 组合:
javascript
// 定义变量节点 - URL列表提取
{
"variable-value": [
"${page==null?1:page+1}",
"${extract.selectors(resp.html, '.text-black', 'attr', 'href')}" // 提取相对路径
]
}
// 新闻地址节点 - URL拼接与ID提取
{
"variable-name": ["news_url", "news_id", "news_urlmap", "query_result"],
"variable-value": [
"https://www.polymerupdate.com${news_urllist[index]}", // 拼接完整URL
"${news_urllist[index].regx('(\\d+)').toInt()}", // 正则提取ID
"${{'url': news_url}}",
"${!rs.contains(news_urlmap)}"
]
}URL处理流程:
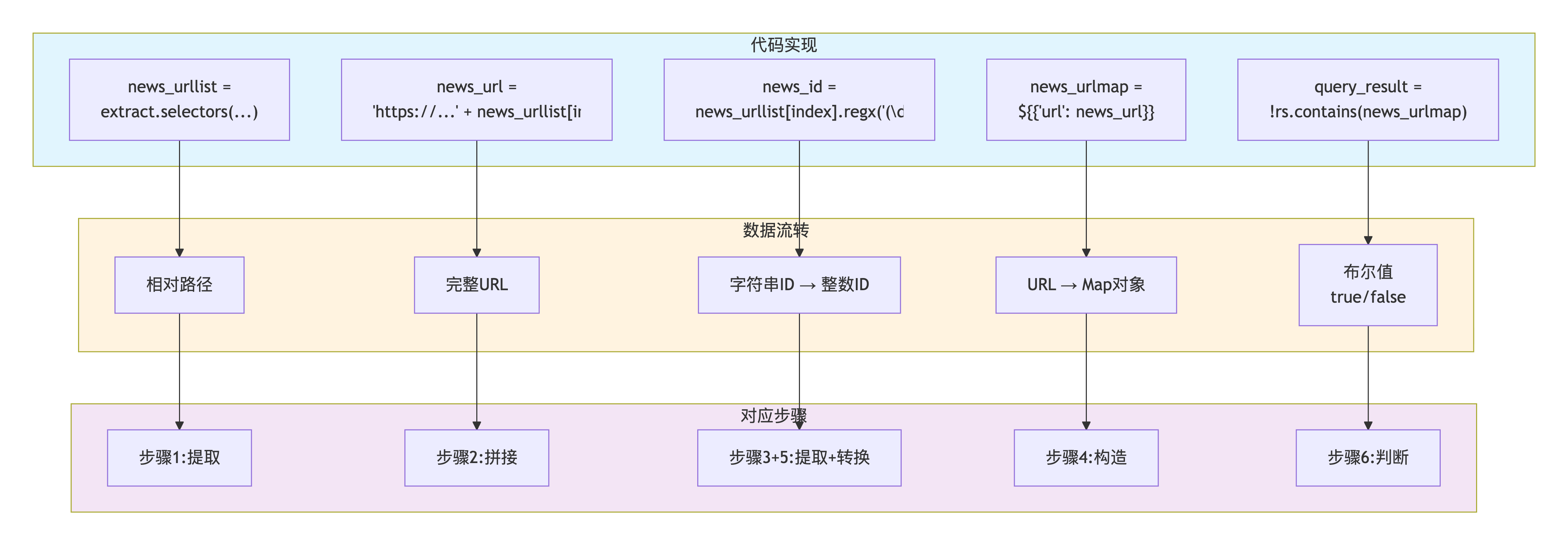
难点五:响应数据的结构化提取
问题描述:
新闻详情页的结构比较特殊,标题、时间、内容都位于.mt-3类下,但需要不同的选择器精确定位。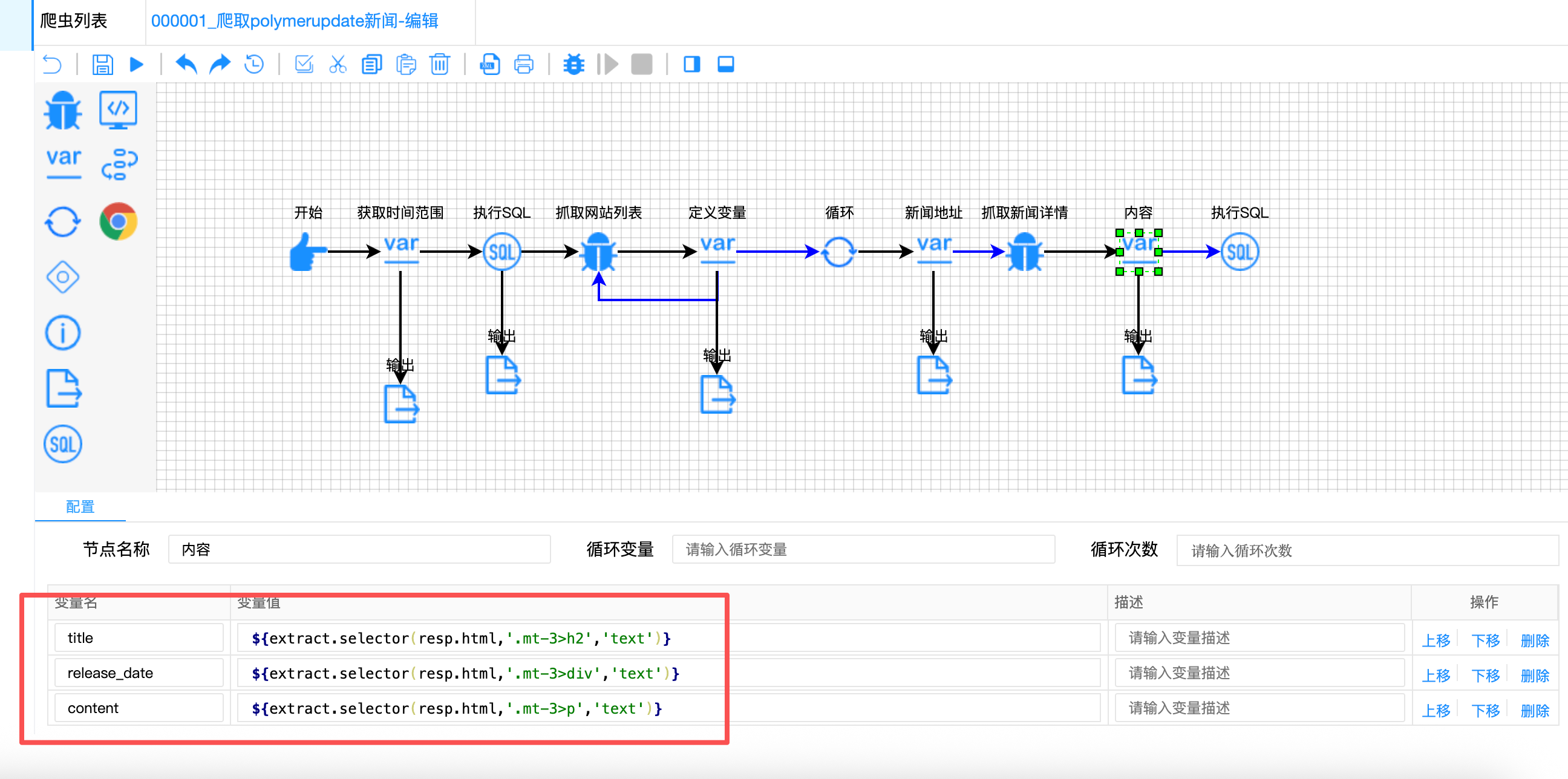
解决方案:
精细化的CSS选择器配置:
javascript
// 内容节点配置
{
"variable-name": ["title", "release_date", "content"],
"variable-value": [
"${extract.selector(resp.html, '.mt-3>h2', 'text')}", // 标题在h2中
"${extract.selector(resp.html, '.mt-3>div', 'text')}", // 时间在div中
"${extract.selector(resp.html, '.mt-3>p', 'text')}" // 内容在p中
]
}选择器定位示意图:
html
<div class="mt-3">
<h2>这里是新闻标题</h2> <!-- title -->
<div>Published on: 2024-01-15</div> <!-- release_date -->
<p>新闻正文第一段...</p> <!-- content -->
<p>新闻正文第二段...</p> <!-- content会被合并?注意:实际只提取第一个p -->
</div>注意 :当前配置只提取第一个p标签的内容,如果需要提取所有段落,可能需要使用selectors方法(复数形式)。
四、核心代码实现解析
4.1 POST分页控制的核心逻辑
javascript
// 伪代码:POST分页控制器
class PostPaginationController {
constructor() {
this.page = 1;
this.maxPage = 1; // 业务需求只抓取第一页
}
async fetchPage(page) {
const formData = new FormData();
formData.append('SearchCriteria[Period]', '180');
formData.append('SearchCriteria[Page]', page.toString());
const response = await fetch(
'https://www.polymerupdate.com/PressRelease/Listing',
{
method: 'POST',
body: formData
}
);
return response.text();
}
async extractUrls(html) {
// 使用CSS选择器提取所有.text-black元素的href属性
const regex = /<a[^>]+class="[^"]*text-black[^"]*"[^>]+href="([^"]+)"/g;
const urls = [];
let match;
while ((match = regex.exec(html)) !== null) {
urls.push(match[1]);
}
return urls;
}
async run() {
let hasMore = true;
while (hasMore) {
const html = await this.fetchPage(this.page);
const urls = await this.extractUrls(html);
// 处理当前页的URL
await this.processUrls(urls);
// 分页控制
hasMore = this.page < this.maxPage;
this.page++;
}
}
}4.2 代理请求的实现
javascript
// 伪代码:代理请求处理器
class ProxyRequestHandler {
constructor(proxyConfig) {
this.proxy = proxyConfig;
this.retryCount = 3;
this.retryInterval = 5000;
}
async requestWithProxy(url) {
for (let i = 0; i < this.retryCount; i++) {
try {
const response = await fetch(url, {
proxy: this.proxy, // 设置代理
timeout: 30000
});
if (response.ok) {
return await response.text();
}
} catch (error) {
console.log(`请求失败,第${i+1}次重试`, error.message);
await sleep(this.retryInterval);
}
}
throw new Error('代理请求失败,已重试3次');
}
async sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
}4.3 去重机制的核心实现
javascript
// 伪代码:URL去重器
class UrlDeduplicator {
constructor(existingUrls) {
// 将数据库查询结果转换为Set
this.existingSet = new Set(existingUrls.map(item => item.url));
}
isDuplicate(url) {
return this.existingSet.has(url);
}
// 批量去重判断
filterNewUrls(urls) {
return urls.filter(url => !this.isDuplicate(url));
}
}
// 使用示例
const deduplicator = new UrlDeduplicator(rs);
const newUrls = deduplicator.filterNewUrls(allUrls);
for (const url of newUrls) {
await crawlDetail(url);
await sleep(5000); // 礼貌抓取
}五、性能优化与最佳实践
5.1 请求策略优化
| 策略 | 配置 | 目的 |
|---|---|---|
| 请求间隔 | sleep:5000 | 避免请求频率过高 |
| 超时控制 | timeout:30000 | 防止长时间阻塞 |
| 重试机制 | retryCount:3 | 应对临时网络问题 |
| 代理隔离 | 仅详情页使用 | 节省代理资源 |
5.2 数据处理优化
- 正则提取ID:比字符串分割更可靠,适应URL格式变化
- Map构造去重 :使用
${``{'url':news_url}}构造Map,便于集合操作 - 链式调用 :
extract.selector()直接处理响应,减少中间变量
5.3 异常处理机制
javascript
// 伪代码:异常处理包装器
async function safeCrawl(url, useProxy = false) {
try {
const html = useProxy ?
await proxyRequest(url) :
await directRequest(url);
return html;
} catch (error) {
console.error(`抓取失败: ${url}`, error.message);
// 错误分类处理
if (error.message.includes('timeout')) {
// 超时错误,增加间隔后重试
await sleep(10000);
return safeCrawl(url, useProxy);
} else if (error.message.includes('proxy')) {
// 代理错误,尝试更换代理
return await retryWithNewProxy(url);
}
return null; // 致命错误,跳过
}
}六、与前一爬虫的对比分析
6.1 技术方案对比
| 维度 | polymerupdate爬虫 | chemanalyst爬虫 |
|---|---|---|
| 列表请求方式 | POST + FormData | GET + URL参数 |
| 分页控制 | page<=1(仅第一页) | page<=23(全量抓取) |
| 代理配置 | 详情页使用代理 | 未使用代理 |
| 提取字段 | 3个字段 | 4个字段 |
| 数据来源标记 | source='polymerupdate' | source='chemanalyst' |
6.2 核心差异点
- 请求方式差异:polymerupdate使用POST表单提交,chemanalyst使用GET URL参数
- 代理策略差异:polymerupdate需要代理保护,chemanalyst可能IP限制较松
- 分页范围差异:polymerupdate只抓第一页(最近新闻足够),chemanalyst抓23页
七、总结与经验分享
7.1 核心收获
- POST分页技巧:通过变量节点控制表单参数,实现POST请求的分页循环
- 代理精细化配置:只在详情页使用代理,平衡了反封禁和资源消耗
- 动态时间范围:结合数据库查询,实现精准的增量抓取
7.2 可复用经验
- 表单参数变量化:对于POST分页,将分页参数设计为变量,方便控制
- 代理分层策略:核心数据(详情页)使用代理,列表页直接访问
- 相对路径拼接 :统一使用
域名 + 相对路径的拼接模式
7.3 适用场景
该爬虫设计模式适用于:
- 使用POST方式加载列表的网站
- 对IP访问频率有限制的网站
- 需要精细化控制代理使用的场景
- 新闻资讯类网站的增量抓取
八、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算时间窗口 | date.addDays(), date.format() |
| 执行SQL(查询) | 获取已抓取记录 | between语句,like模糊匹配 |
| 抓取网站列表 | POST请求获取列表 | FormData表单,${page}变量 |
| 定义变量 | 分页控制与URL提取 | 三目运算符,selectors提取 |
| 循环 | 遍历每条新闻 | list.length()动态计算 |
| 新闻地址 | 数据处理与去重 | URL拼接,正则提取ID,Map构造 |
| 抓取新闻详情 | 代理请求详情页 | 代理IP配置,重试机制 |
| 内容 | 提取结构化数据 | 多选择器组合 |
| 执行SQL(插入) | 存储数据 | 参数化SQL,source标记 |
通过以上设计,该爬虫成功应对了POST分页和IP封禁的双重挑战,实现了对polymerupdate.com新闻网站的高效增量抓取。其中的POST表单变量控制、代理分层配置等思路,对于类似场景的爬虫开发具有很高的参考价值。