第 8 章:B+ 树索引------MySQL 最重要的数据结构
⏱ 阅读时间:约 40 分钟 📖 前置知识:第 6 章(InnoDB 存储引擎概论)、第 7 章(InnoDB 的数据页结构) 🎯 读完本章你将:理解 B+ 树索引的完整结构,搞清楚聚簇索引和二级索引的区别,会用数据量推算树的高度
一个问题
假设你有一张用户表,里面存了 1000 万条数据。现在要查一个用户:
sql
SELECT * FROM user WHERE id = 8765432;如果没有索引,MySQL 怎么找到这条记录?
答案是:从头翻到尾,挨个看。
就像你在一本没有目录的 10000 页书里找一个电话号码------只能从第 1 页翻到第 10000 页。
1000 万条数据,假设每条占 200 字节,一个 16KB 的数据页能存 80 条,大约需要 125000 个数据页。每个数据页读一次磁盘......你品品这个 IO 量。
这就是没有索引的代价。
而有了索引呢?MySQL 只需要读 3~4 个页就能找到目标------就像你翻开书的目录,找到了"张三"在第 4321 页。
这个"目录"就是 B+ 树。
B+ 树是 MySQL(InnoDB)最重要的数据结构,没有之一。 你在面试中被问到的 90% 的索引问题,本质上都是在问 B+ 树。
这一章,我们就把这个东西彻底搞明白。
没有索引会怎样?全表扫描的代价
在讲 B+ 树之前,先看看没有索引的世界有多惨。
全表扫描(Full Table Scan)
没有索引的时候,MySQL 只能逐页读取表中的数据,逐行检查是否满足 WHERE 条件。这个过程叫全表扫描。

当然,MySQL 不会每次都真去读磁盘------有 Buffer Pool 缓存着热数据。但即使全在内存里,逐行扫描 1000 万条记录的 CPU 开销也不小。
这就是索引存在的意义:用空间换时间,建一个"目录",让查找从 O(N) 变成 O(log N)。
从二叉树到 B 树到 B+ 树:一场问题驱动的进化
第一步:二叉搜索树(BST)
最直观的想法是:用二叉搜索树。
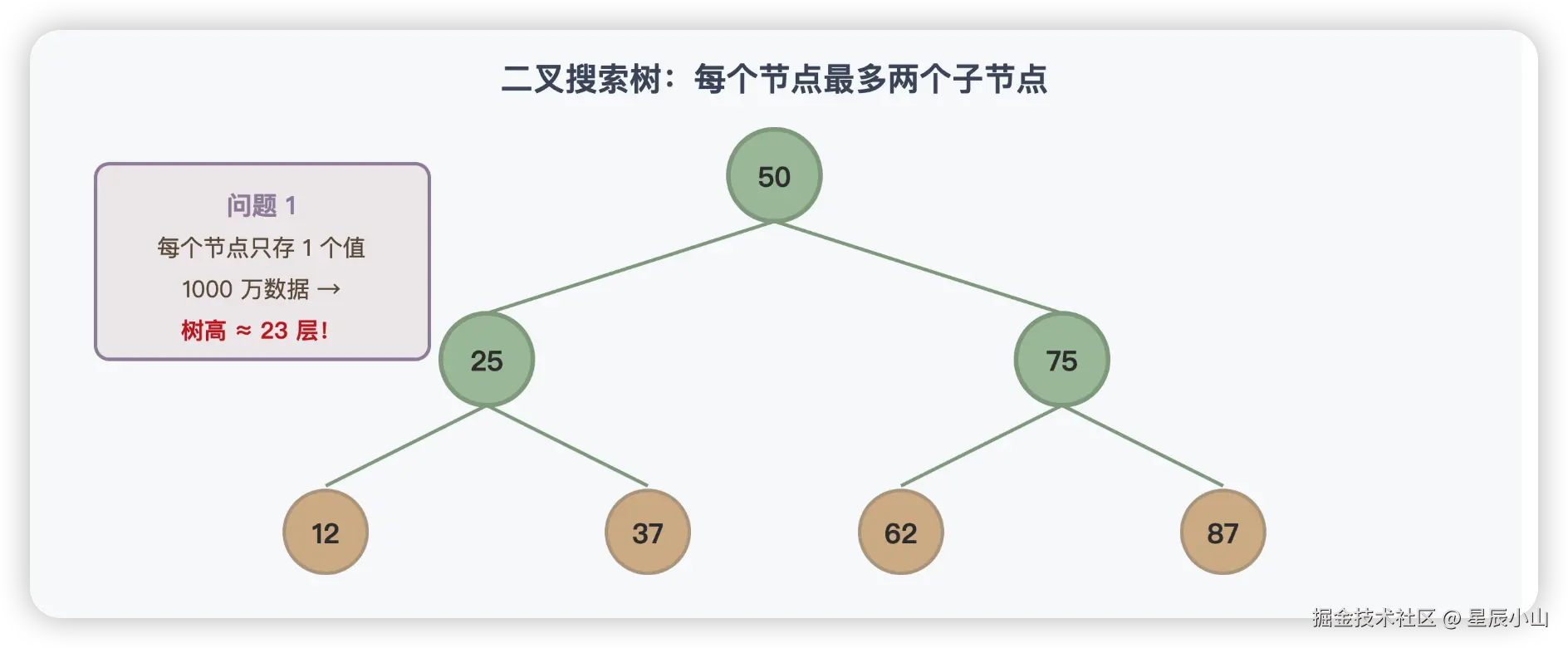
二叉搜索树的问题很严重:
- 树太高了 。1000 万个节点,平衡的情况下树高约 23 层。一次查询要访问 23 个节点------23 次磁盘 IO。
- 退化风险。如果插入的数据是有序的(比如自增 ID),二叉搜索树会退化成链表,查询变成 O(N)。
🤔 你可能会想:平衡二叉树(AVL)和红黑树能解决退化问题啊?没错,但它们解决不了"树太高"的问题------一个节点还是只能存一个值,树的深度由节点数量决定。
第二步:B 树(多路搜索树)
让一个节点存多个值,这就是 B 树的核心思想。
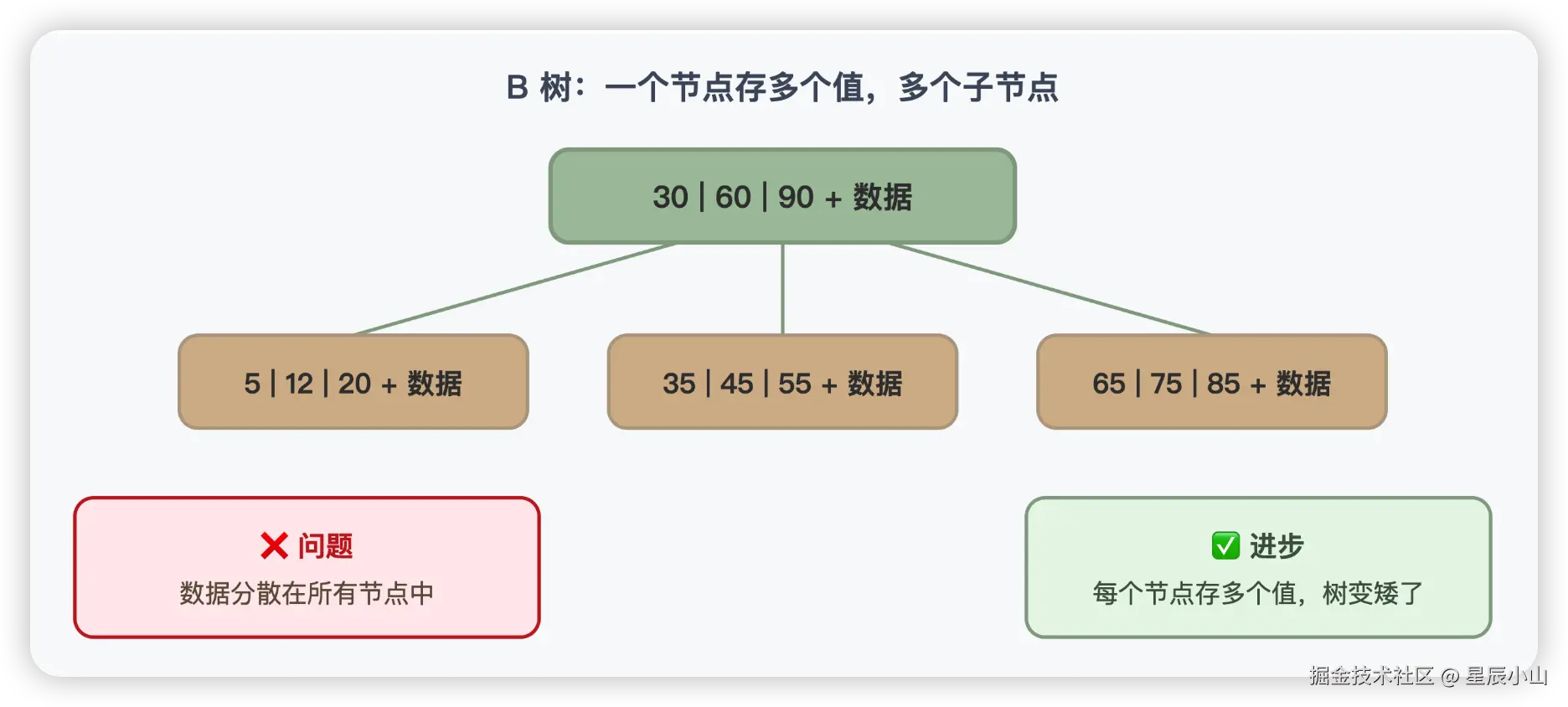
B 树的每个节点可以存多个键值和多个指针,树变矮了。但 B 树还有个问题:数据分散在所有节点中。范围查询时需要在各层之间反复跳转,效率不高。
第三步:B+ 树------数据库的终极选择
B+ 树在 B 树的基础上做了三个关键改进:

B+ 树的结构特点
特点一:非叶子节点只存键,不存数据
在 B+ 树中,只有叶子节点存完整数据,非叶子节点只存键 。同样大小的页(16KB),B+ 树的非叶子节点可以放更多的键。
放更多键 → 每个节点的子指针更多 → 树更矮 → 查询更快。
举个例子: 假设主键是 BIGINT(8 字节),一个指针占 6 字节。如果一个页不存数据,只存键和指针:
scss
(16 × 1024) / (8 + 6) ≈ 1170 个键1170 个键意味着一个节点最多有 1171 个子节点。那:
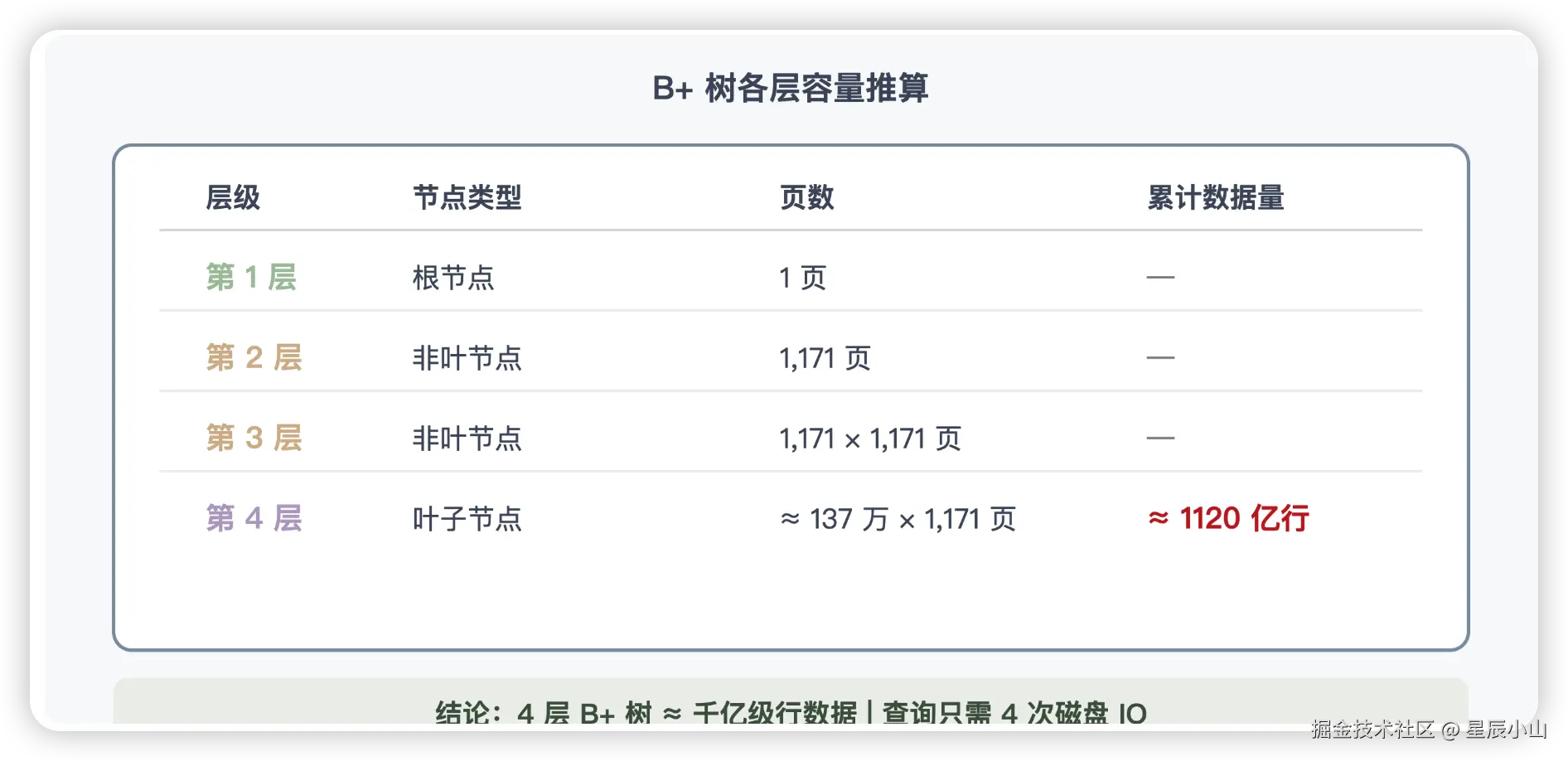
- 第 1 层(根节点):1 个页
- 第 2 层:1171 个页
- 第 3 层:1171 × 1171 ≈ 137 万个页
- 第 4 层(叶子节点):137 万 × 1171 ≈ 16 亿个页
每个叶子页大约存 70 行数据,所以一棵 4 层 B+ 树总共能存:
markdown
16 亿 × 70 ≈ **1120 亿**条记录💡 面试回答技巧 :不需要精确计算,记住数量级就够了。3 层约 9600 万行,4 层约千亿级,5 层可以存到万亿级。实际业务中绝大多数表 3-4 层就足够了。
特点二:叶子节点存所有数据
无论你查找什么数据,最终都要到达叶子节点才能拿到。非叶子节点只负责"指路"。
好处是查询性能稳定------每次查询的磁盘 IO 次数都等于树的高度。
特点三:叶子节点形成双向链表
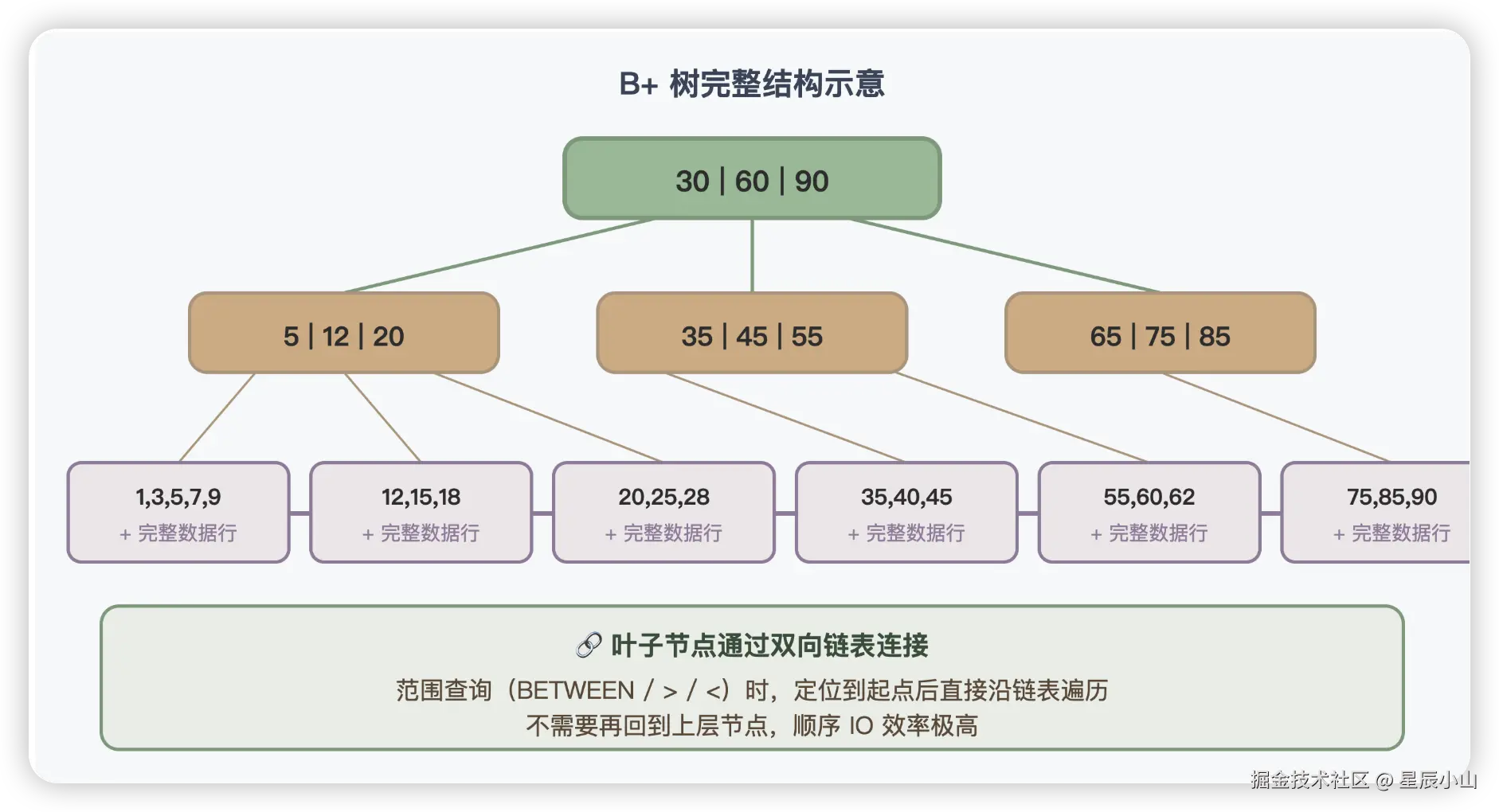
这个双向链表是 B+ 树的"杀手锏"。范围查询 WHERE id BETWEEN 100 AND 200,只需要:从根找到 id=100 所在叶子节点,然后沿链表向右遍历到 id=200。一次"从根到叶子"的查找 + 一段链表遍历,搞定。
💡 记住这一句就够了: B+ 树的三个特点------非叶节点只存键(树更矮)、叶子存全部数据(性能稳定)、叶子串成双向链表(范围查询快)。这三点让它成为数据库索引的终极选择。
聚簇索引的 B+ 树长什么样?
InnoDB 中有两种索引:聚簇索引 (Clustered Index)和二级索引(Secondary Index)。
聚簇索引就是表本身。 它的叶子节点存的是完整的行数据。
sql
CREATE TABLE user (
id BIGINT PRIMARY KEY, -- 聚簇索引的键
name VARCHAR(50),
age INT,
city VARCHAR(50)
);上面这张表,id 是主键,InnoDB 会自动用 id 建一棵 B+ 树,这棵 B+ 树就是表本身------数据和索引是一体的。
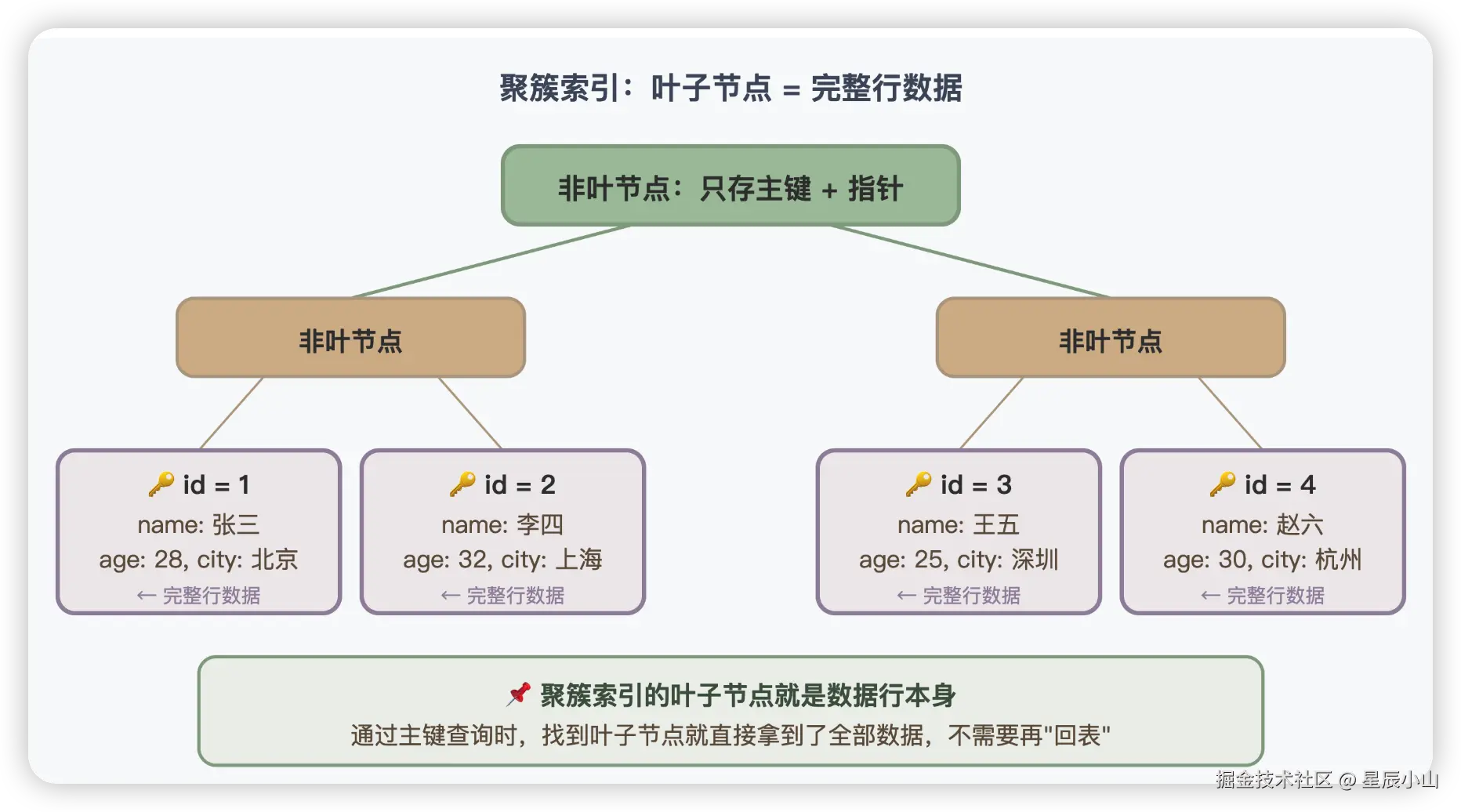
几个关键点:
- 每张 InnoDB 表有且仅有一个聚簇索引。因为你不可能把同一份数据按两种不同的顺序物理存储。
- 聚簇索引的键就是主键 。如果你建表时没有指定主键,InnoDB 会自动找一个非空唯一索引作为聚簇索引;如果也没有,它会自动生成一个 6 字节的隐藏列
row_id作为聚簇索引。 - 聚簇索引决定了数据的物理存储顺序。这就是为什么你用自增 ID 做主键时,插入数据是追加写入的(顺序 IO),性能很好。如果你用 UUID 做主键,插入时需要频繁移动数据页中的记录(随机 IO),性能会差很多。
💡 记住这一句就够了: 聚簇索引就是表本身,叶子节点存完整行数据。一张表只有一个聚簇索引,通常就是主键索引。用自增 ID 做主键可以让数据顺序写入,性能最好。
二级索引的 B+ 树长什么样?(回表过程)
如果你要按 name 查用户怎么办?name 不是主键,聚簇索引帮不上忙。
这时候就需要二级索引(也叫辅助索引)。
sql
CREATE INDEX idx_name ON user(name);二级索引的 B+ 树和聚簇索引的结构一样,但有一个关键区别:叶子节点存的不是完整行数据,而是索引键 + 对应的主键值。
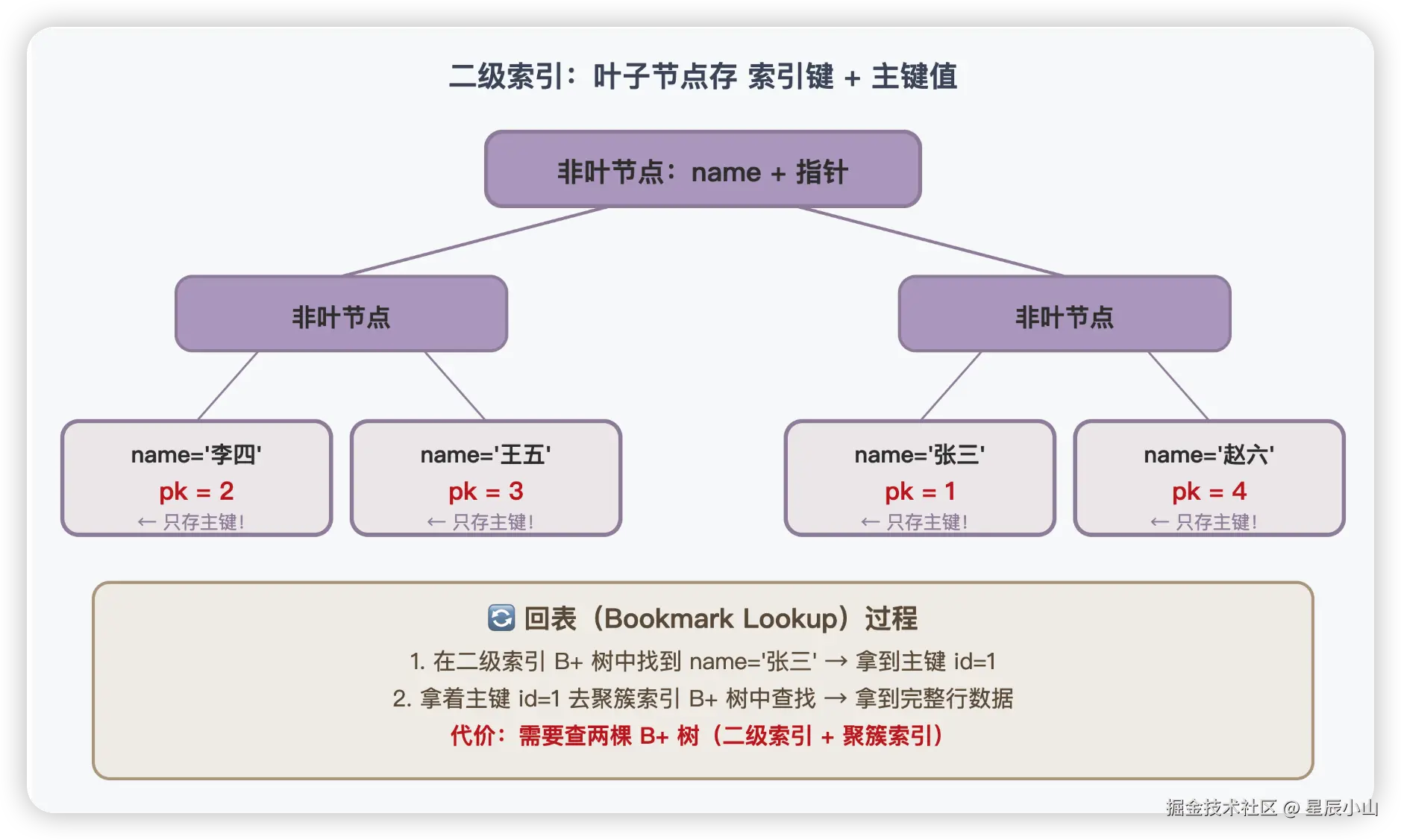
这个过程叫回表(Bookmark Lookup)。翻译成大白话就是:
你先查电话簿(二级索引),找到了"张三"的分机号是 1(主键),然后再拨分机号 1(查聚簇索引),才能找到张三的详细信息。
回表的代价
回表意味着你一次查询要走两棵 B+ 树:
二级索引查找:树高次 IO(假设 3 次)
聚簇索引查找:树高次 IO(假设 3 次)
总计:6 次 IO对比直接走聚簇索引只需要 3 次 IO,回表的代价翻了一倍。
如果二级索引匹配到了很多行,每一行都要回表,那代价就是 N × 3 次 IO------N 越大,越慢。这时候优化器可能觉得还不如直接全表扫描呢。
这就是为什么会有覆盖索引------如果查询的列都在二级索引里,就不需要回表了:
sql
-- 需要回表(SELECT * 超出了索引范围)
SELECT * FROM user WHERE name = '张三';
-- 不需要回表(name 和 id 都在二级索引里)
SELECT id, name FROM user WHERE name = '张三';💡 记住这一句就够了: 二级索引的叶子节点存的是索引键+主键值。通过二级索引查询时,需要先在二级索引树中找到主键,再拿主键去聚簇索引树中查找完整数据------这个过程叫回表。覆盖索引可以避免回表。
B+ 树的插入和删除过程(简化版)
插入过程
往 B+ 树中插入一条新记录,大致流程是:
- 从根节点出发,找到合适的叶子节点
- 在叶子节点中插入(叶子节点内部是有序的,需要找到正确的位置)
- 检查叶子节点是否满了
如果叶子节点没满,直接插入,完事。
如果叶子节点满了,就需要分裂:
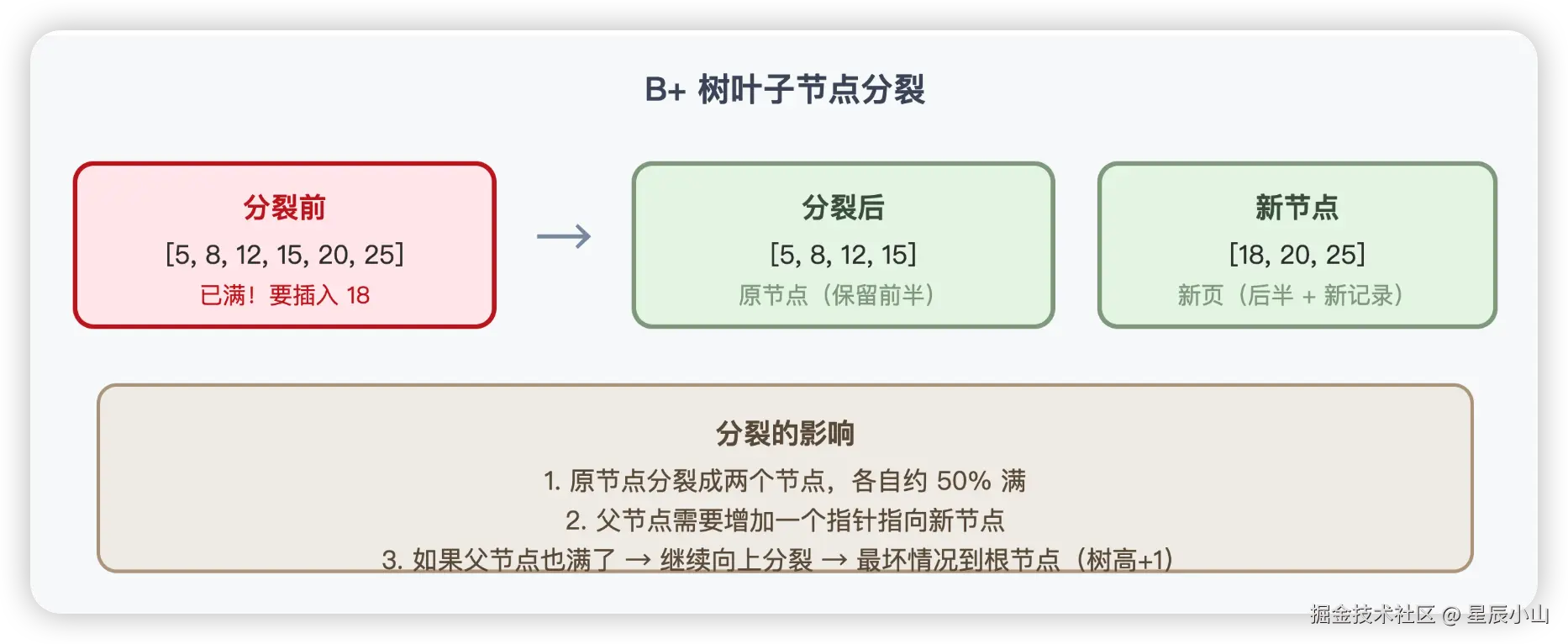
这就是为什么用自增 ID 做主键更好------新插入的数据总是追加到叶子节点的末尾,不会触发分裂(或者说分裂频率极低)。如果用 UUID 做主键,插入位置是随机的,频繁触发页分裂,性能会大打折扣。
删除过程
删除相对简单:找到叶子节点,删除对应记录。
如果删除后叶子节点太"空"了(低于某个阈值),可能会和相邻节点合并------分裂的逆过程。
📖 更详细的 B+ 树维护机制(包括页分裂、页合并、缓冲池的 Change Buffer 机制等),我们会在第 10 章(索引的底层维护机制)中深入展开。
为什么 B+ 树的层级一般不超过 4 层?
这是一个非常经典的面试题。答案是:因为 InnoDB 的页大小是 16KB,这个"盘子"足够大,能装下足够多的"菜"。
我们用数据来推算一下。
用数据量推算树的高度
假设:
- 页大小:16KB = 16384 字节
- 主键类型:BIGINT,占 8 字节
- 指针大小:6 字节(InnoDB 中页内指针占 6 字节)
非叶子节点:能存多少个键?
非叶子节点只存键 + 指针,不存数据:
yaml
每个键值对占:8(键)+ 6(指针)= 14 字节
每个页能存:16384 / 14 ≈ 1170 个键值对一个有 1170 个键的节点,有 1171 个子指针(比键多一个)。
叶子节点:能存多少条记录?
叶子节点存的是完整行数据。假设一行数据大约 200 字节:
每行占:200 字节(含记录头信息等开销,算 220 字节)
每个页能存:16384 / 220 ≈ 74 条记录保守取 70 条记录/页。
推算各层能存多少数据
这个推算说明了什么?
- 绝大多数表的 B+ 树高度是 2~3 层。1000 万行数据只需要 3 层。
- 即使数据量达到百亿级别,树高也不过 4 层。这意味着任何一条记录的查询,最多只需要 4 次磁盘 IO。
- 根节点通常常驻内存。所以实际上只需要 3 次磁盘 IO(第 2 层 + 第 3 层 + 第 4 层)。
这就是 B+ 树的厉害之处------用极其有限的 IO 次数,支撑起海量的数据查找。

💡 记住这一句就够了: InnoDB 的 B+ 树高度一般不超过 4 层。1000 万行数据只需要 3 层。这是因为 16KB 的页能装下约 1170 个键值对,指数增长使得树高极低。这就是为什么 MySQL 单表存几千万甚至上亿行数据,查询依然很快。
聚簇索引 vs 二级索引:一张图看懂区别

本章小结
你学到了什么
| # | 知识点 | 一句话总结 |
|---|---|---|
| 1 | 全表扫描 | 没有索引时逐页扫描,1000 万行 ≈ 125000 次 IO |
| 2 | 二叉搜索树 | 每个节点存一个值,树太高(23 层),不适合数据库 |
| 3 | B 树 | 多路搜索树,节点存多个值,树变矮,但数据分散在所有层级 |
| 4 | B+ 树三大特点 | 非叶只存键、叶子存全部数据、叶子串成双向链表 |
| 5 | 聚簇索引 | 就是表本身,叶子存完整行数据,一张表只有一个 |
| 6 | 二级索引 | 叶子存索引键+主键值,查询需要回表到聚簇索引 |
| 7 | 回表 | 二级索引 → 拿主键 → 聚簇索引,IO 翻倍,覆盖索引可避免 |
| 8 | 树高推算 | 16KB 页存 1170 个键,4 层 B+ 树可存约 1120 亿行 |
| 9 | 页分裂 | 节点满时分裂为两个,自增主键可减少分裂频率 |
后续章节预告
| 你刚学到的 | 后面在哪章深入展开 |
|---|---|
| 覆盖索引、索引下推 | 第 9 章(索引的多种类型) |
| 页分裂、页合并、Change Buffer | 第 10 章(索引的底层维护机制) |
| 联合索引、最左前缀 | 第 11 章(索引设计实战) |
| 索引优化器如何选择索引 | 第 16 章(执行计划与 optimizer_trace) |
🎯 面试必问 TOP 5
Q1:为什么 MySQL 用 B+ 树而不是 B 树、红黑树或哈希?
B+ 树相比 B 树:非叶节点不存数据,一个页能存更多键,树更矮;叶子节点形成链表,范围查询高效。相比红黑树:红黑树每个节点只存一个值,树太高(23 层 vs 3~4 层),磁盘 IO 次数多。相比哈希:哈希不支持范围查询和排序。
Q2:聚簇索引和二级索引有什么区别?
聚簇索引的叶子节点存完整行数据,一张表只有一个(通常是主键)。二级索引的叶子节点存索引键+主键值,可以有多个。通过二级索引查询需要回表到聚簇索引获取完整数据。
Q3:什么是回表?如何避免?
回表是通过二级索引查到主键后,再拿主键去聚簇索引查完整数据的过程。避免方式:使用覆盖索引------让查询的列都在二级索引中,这样就不需要回表了。
Q4:一棵 B+ 树能存多少数据?为什么一般不超过 4 层?
假设主键 BIGINT(8字节),指针 6 字节,一个 16KB 页能存 1170 个键。4 层 B+ 树可存约 1170 × 1170 × 1170 × 70 ≈ 1120 亿行。因为指数增长,即使海量数据树高也很低。
Q5:为什么建议用自增 ID 做主键?
自增 ID 保证新数据总是追加到叶子节点末尾,是顺序写入,不会触发页分裂,性能好。UUID 等随机主键会导致插入位置随机,频繁触发页分裂,降低写入性能,也会导致二级索引更大(因为二级索引存的是主键值)。
📌 下一章预告: 第 9 章:索引使用策略------知道有索引还不够,还得会用 我们会看到 InnoDB 中各种索引类型的区别和适用场景,搞清楚什么时候该用什么索引。