SWE-bench Verified 排行榜上,Claude Opus 4.6 拿了 80.8%。GPT-5.3-Codex?OpenAI 直接不交卷了------他们认为这个榜单存在训练数据污染,分数已经不能反映真实能力。
有意思。两家最强的编程 AI,一个考了高分,一个拒绝参考。
那我换个考法:让它们干同一件活------审计我手里这个十几年的 C++ 遗产项目------看看实战结果差多少。
结果差了十万八千里。
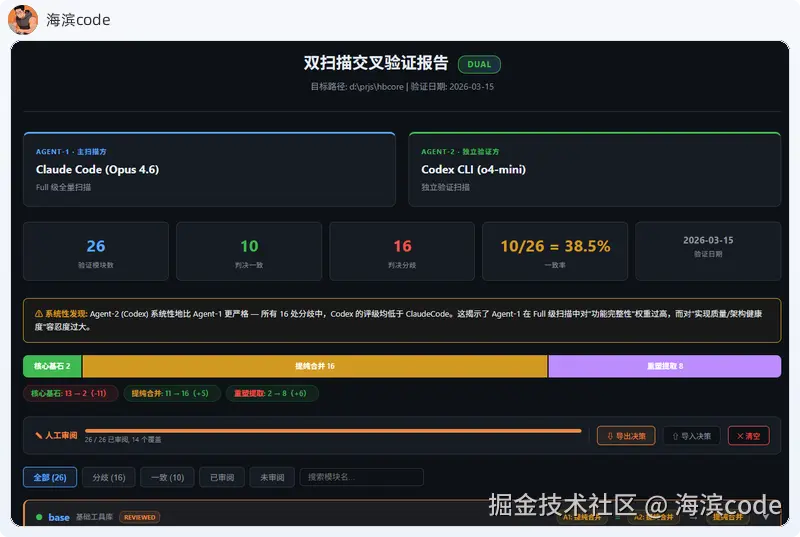
注:截图中 Agent-2 显示为 "o4-mini" 系报告渲染时的模型标识错误,实际调用的是 GPT-5.3-Codex。
26 个模块,两个 AI 只在 10 个上达成了共识。一致率 38.5%。
更离谱的是:Claude 说有 13 个模块是"核心基石、质量过关",Codex 只认 2 个。剩下 11 个,Codex 全给降了级------理由是它们虽然能跑,但藏着没爆的雷。
但这篇不是要分高下。我更想搞明白的是:同一份代码,两个最强的编程 AI 怎么能给出差这么远的结论?
实验怎么做的
项目背景:一个积累了十几年的 C++ 音视频基础库,26 个模块,几万个源文件。典型的"老同事走了新同事不敢动"的遗产代码。
我用 repo-scan 的交叉扫描功能,对这个项目做了一次双 Agent 审计:
- Agent-1:Claude Opus 4.6,执行全量扫描------逐模块分析代码结构、依赖关系、质量问题,给出四级判决
- Agent-2:GPT-5.3-Codex,执行独立验证------在不看 Agent-1 结论的前提下,对同一批模块做独立审计
四级判决体系:
| 判决 | 含义 | 行动 |
|---|---|---|
| 🟢 核心基石 | 质量可靠 | 直接保留,作为新架构基础 |
| 🔵 提纯合并 | 有价值但冗余 | 提取核心逻辑,合并同类模块 |
| 🟡 重塑提取 | 部分可用 | 大幅改造,仅保留算法/协议层 |
| 🔴 彻底淘汰 | 不值得修 | 删除重来,用现代方案替代 |
两个 Agent 独立跑完之后,我把结果摊在一起对比。
然后就炸了。
最明显的表现:一致率 38.5%
26 个模块,两个 AI 给出完全相同判决的只有 10 个。
下面这张截图是交叉扫描报告里的判决对比视图。左右两列分别是两个 Agent 的评级,颜色不一致的就是分歧模块:
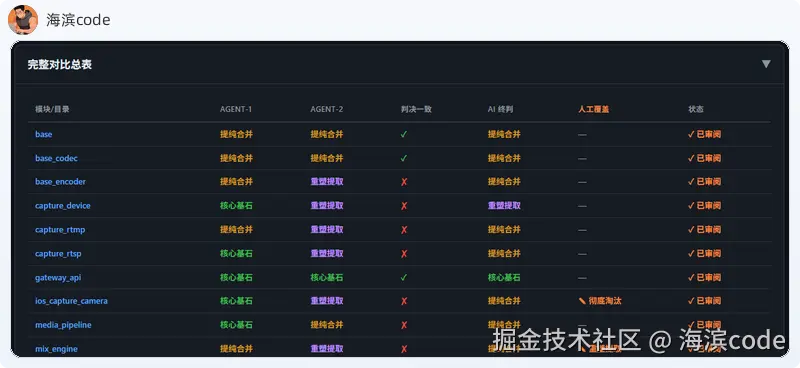
不一致的 16 个模块里,有一个惊人的规律:所有分歧中,Codex 的判决都比 Claude 更严格。
没有一次例外。
Claude 说"核心基石"的,Codex 最多给"提纯合并"。Claude 说"提纯合并"的,Codex 可能降到"重塑提取"。
最夸张的对比:
| 维度 | Claude 判定 | Codex 判定 |
|---|---|---|
| 评为"核心基石"的模块数 | 13 | 2 |
| 评为"提纯合并"的模块数 | 11 | 16 |
| 评为"重塑提取"的模块数 | 2 | 8 |
Claude 认为半数模块质量过关可以直接用,Codex 觉得只有两个能放心用。
另一个关键发现:13 个 Claude 完全漏掉的 Bug
这才是真正让我后背发凉的。
Codex 在独立审计中,发现了 13 个关键问题是 Claude 完全没有提到的。不是"分析角度不同",是"Claude 看了代码但没发现问题"。
挑几个最有代表性的:
mp4_parser:写宽高写错了 4 个字节
模块里有一段写 MP4 tkhd box 的代码,宽高字段用的是 16.16 定点数格式(高16位整数 + 低16位小数)。
Codex 发现:代码写入了一个 16 位的值,但指针往后跳了 4 个字节。
结果就是高 16 位写对了,低 16 位被后面的数据覆盖。 生成的 MP4 文件在大多数播放器上看着正常------因为播放器容错能力强。但如果下游工具严格按规范解析,宽高就是错的。
Claude 看了同一段代码,给出的评价是"MP4 封装模块功能完整"。
video_encrypt:十行脚本就能破解的"加密"
Claude 的评价是"视频加密模块,功能可用,建议优化"。听起来还行对吧?
Codex 一看就怒了:整个加密逻辑就是 4 字节 XOR。 这玩意儿写个 Python 脚本十行就能逆向,根本称不上加密。更离谱的是里面还藏着一段时间炸弹代码,以及一个 ReadFrame 的空指针解引用------也就是说这个模块不光是形同虚设,它还会炸。
protocol_gb28181:God Class
这个最让我哭笑不得。Claude 给了"协议支持完善,是核心基石"的评价------听着像个表扬。
然后 Codex 翻出来:Server 和 Client 的代码 60% 是复制粘贴的。三组配对对象各自重新实现了一遍"SIP 会话 + RTP 媒体 + 业务控制"。一个类干三件不相关的事,改一件可能另外两件跟着崩。教科书级的 God Class。
你说它"功能完善"也没错------确实能跑。但谁要是敢在这上面改需求,大概率改出一堆回归 Bug。
其他 Codex 独立发现的问题
| 模块 | Codex 发现的问题 | 后果 |
|---|---|---|
| capture_device | COM 初始化顺序错误 | 多线程随机崩溃 |
| record_play | ThreadStart() 被注释掉 | 磁盘清理失效,无限吃盘 |
| web_wasm_player | 未声明全局变量 + signal 未传递 | 浏览器内存泄漏 |
| nserver | TLS 1.0 残留,接口对不上 | 安全隐患 + 运行时报错 |
这些不是什么"代码风格问题"或"最佳实践建议"。是真的会在生产环境炸的 Bug。
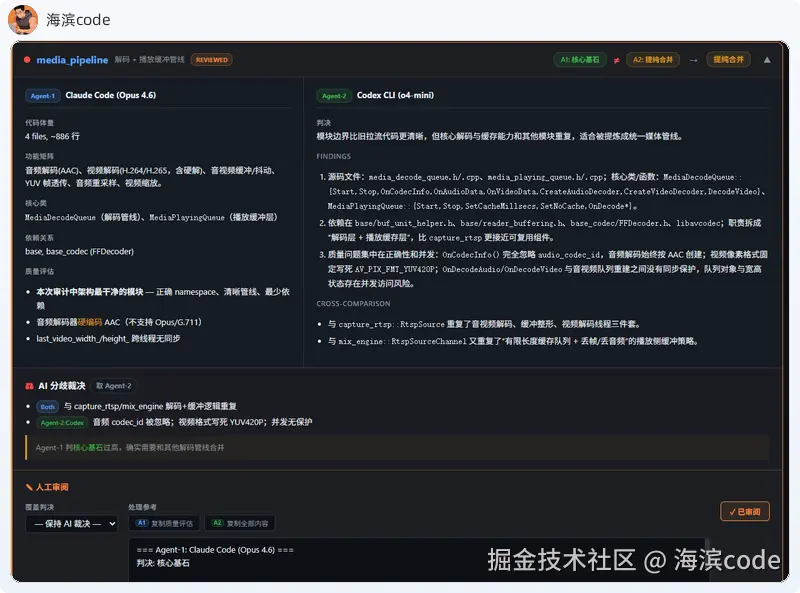
下面是交叉扫描报告中,某个分歧模块的详情页面。左右并排展示两个 Agent 各自的分析,红色高亮的就是分歧点:
为什么同一份代码,两个 AI 的判断差这么多?
翻完 16 个分歧模块的详细报告之后,我大概摸到了规律。
Claude 看代码像项目经理看周报。 这个模块声明了哪些接口?实现了没有?能编译能跑吗?能跑就行,给个"核心基石"。它关心的是功能覆盖度------东西齐不齐、跑不跑得通。
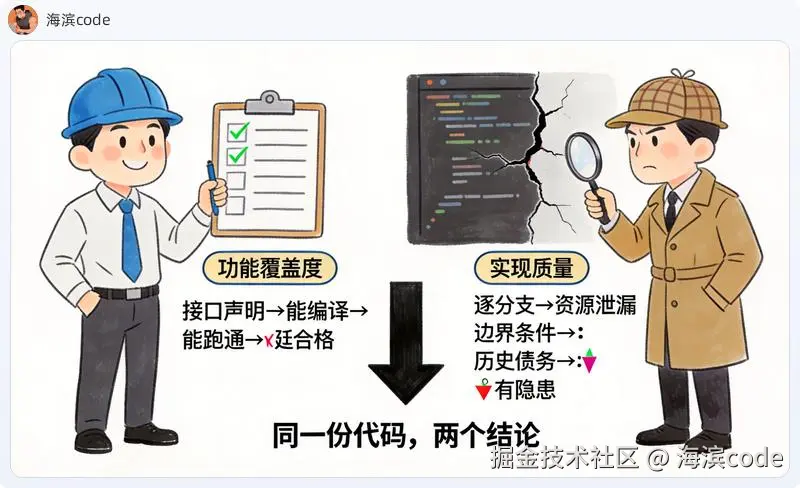
Codex 不一样,它更像那种会在 Code Review 里给你写三屏 comment 的同事。 能跑?能跑不代表没问题。这个分支你考虑过吗?资源释放了吗?这个 API 2019 年就废弃了你知道吗?它盯的是实现质量------每一行代码的健壮性。
哪个对?说实话我觉得都对,但也都有盲区。接手一个陌生项目想快速搞清楚全局,Claude 几分钟就能给你一张清晰的模块地图。但你要是拿着这张地图就去做重构决策------Codex 会告诉你地图上标着"安全"的地方,有 11 个埋着雷。
最让我后怕的是:如果我只跑了 Claude 那一轮,我会觉得"还好嘛,半数以上是核心基石,剩下的重构一下就行"。报告看起来完整、有理有据。我根本不会意识到自己漏掉了什么。
跑分高不等于适合你的场景
回头看跑分这件事。
Claude Opus 4.6 在 SWE-bench Verified 上拿了 80.8%。OpenAI 拒绝提交 GPT-5.3-Codex 的成绩,理由是数据污染。在更抗污染的 SWE-bench Pro 上,GPT-5.3-Codex 拿了 56.8%,目前领先。
但即使是 SWE-bench Pro,也只是在测"给一个 GitHub Issue,能不能生成正确的 Patch"。这和"审计一个 26 模块的遗产项目、判断哪些代码有隐患"是完全不同的任务。
跑分衡量的是"做题能力"。代码审计需要的是"怀疑一切的能力"。
我的 dual-scan 实验恰好说明了这一点:Claude 做题可能更稳,但 Codex 更会"找茬"。
订阅价格和使用体验
| 维度 | Claude Code | Codex CLI |
|---|---|---|
| 基础订阅 | Pro $20/月 | Plus $20/月 |
| 高级订阅 | Max $100-200/月 | Pro $200/月 |
| 默认模型 | Opus 4.6 | GPT-5.4 Thinking(可切 5.3-Codex) |
| 上下文窗口 | 200K(Max 含 1M) | 256K(Pro 400K) |
| 安全机制 | 应用层 Hooks | 内核级沙箱隔离 |
基础价格一样,都是 20 刀。
用下来的感受:Claude Code 是那种你愿意一起做项目的搭档------理解力强,文档写得漂亮,重构代码时一致性很好。缺点是有时候太客气了,你明明写了一坨屎,它会说"架构清晰,建议小幅优化"。
Codex CLI 呢?就是那个 Code Review 会给你写三页 comment 的较真同事。抠细节、找隐患,有时候你觉得它小题大做------但这次实验证明了,它标记出来的那些"小题",真的有 13 个是你不知道的雷。

两个 20 刀加起来 40 刀/月。我现在的做法是两个都开着,让它们互相挑刺。这比花 200 刀只用一个高级版划算得多------因为一个 AI 再聪明,也只有一个视角。
所以怎么办
最直接的收获:重要的代码审计,别只用一个 AI。
不需要什么复杂工具。把同一段代码分别丢给 Claude 和 Codex(或任何两个不同家族的模型),对比输出。两个都说没问题------大概率真没问题。两个说法不一样------恭喜你,找到了最值得你亲自看的地方。
| 你的场景 | 推荐 | 原因 |
|---|---|---|
| 接手陌生项目,快速建立全局认知 | Claude | 功能覆盖视角,几分钟出全景 |
| 代码准备上生产,找隐患 | Codex | 实现质量视角,逐分支挖雷 |
| 两者结论冲突的模块 | 你亲自看 | 分歧点 = 最值得人工审查的地方 |
另一个感悟是,别太把跑分当回事了。SWE-bench 上的分数和"能不能在一个 26 模块的遗产项目里找到定时炸弹"完全是两码事。选工具得看它在你的具体任务上表现怎么样,而不是看它考了多少分。
这次交叉扫描用的是我自己做的agent skill,repo-scan。手上有大型老项目的话可以跑一个试试,大概 10-15 分钟出结果。
做完这个实验我想了挺久。以前我用 AI 审代码,看到报告说"没问题"就信了。现在不敢了------因为我亲眼看到同一份代码,一个 AI 说"核心基石",另一个说"里面埋着空指针和伪加密"。
到底谁说的对?我花了两天人工复核了那 16 个分歧模块。结论是 Codex 找到的 13 个问题确实存在,Claude 确实漏了。
所以现在我的习惯是:AI 的审计结论是参考意见,不是最终判断。 尤其是当它告诉你"一切正常"的时候。
作者:10年+码农,曾任某互联网大厂技术专家。常年专注于原生应用和高性能服务器开发、视频传输和处理技术以及AI个人生产力研究。热爱健身,情商为零
公众号:海滨code | 个人主页:https://haibindev.github.io/,转载请注明作者和出处