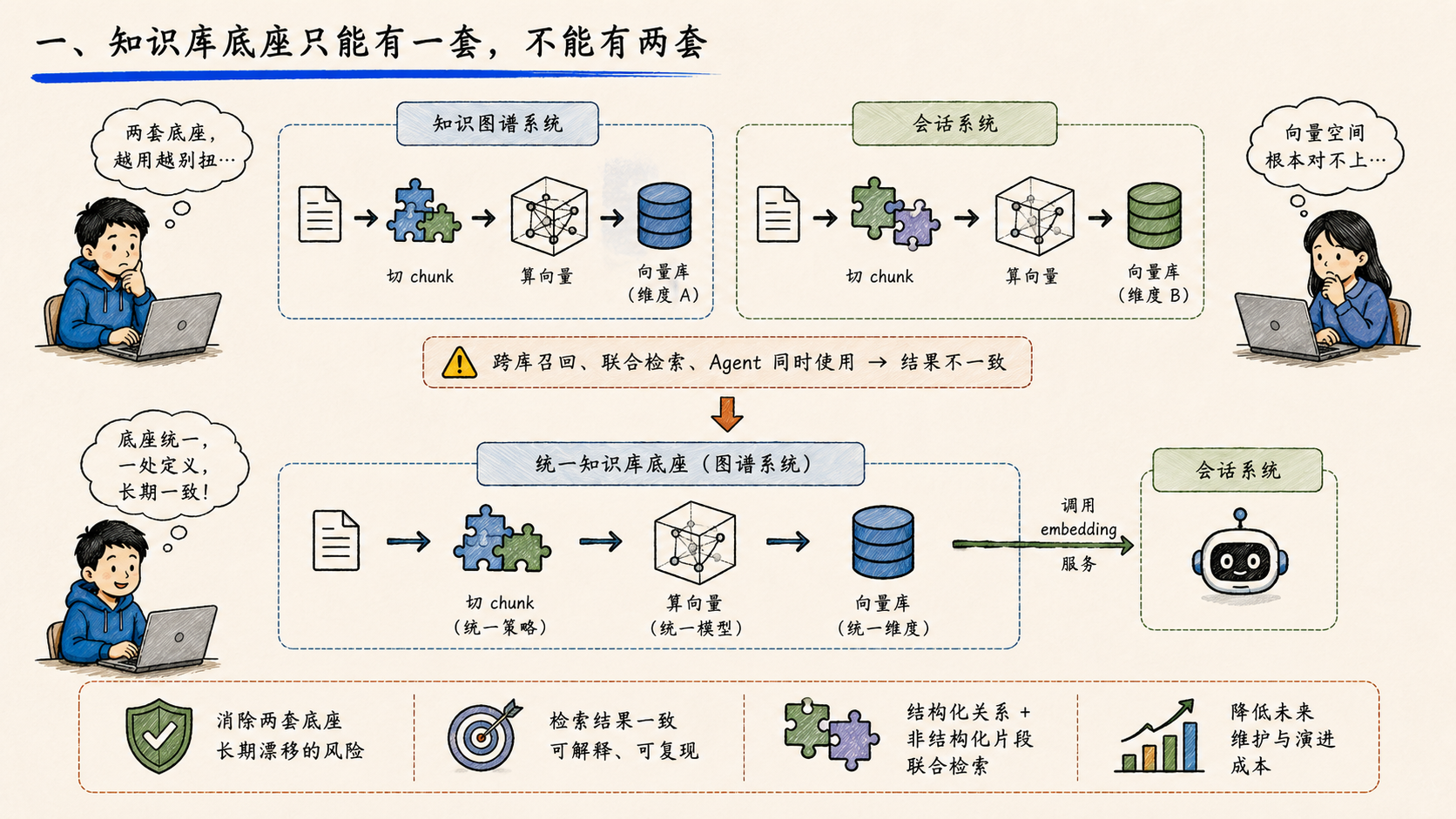
两个服务共用一套 embedding,不是为了省资源,是为了不让向量空间分裂。
这一周做的事,表面上是几个看起来不相关的修复------知识库底座、摄取链路、飞书回调、网关超时、用量入账。但把它们摆在一起会发现,全部都在回答同一个问题:当一个企业 AI 平台里同时跑着多个子系统时,谁该负责什么、谁不该重复造什么、谁的边界在哪里。
企业级和单体应用最大的差别,从来不是规模,是"职责归属"。
一、知识库底座只能有一套,不能有两套
知识图谱系统和会话系统,过去各自维护了一套 embedding 流水线。看起来都跑得通,但越往后越别扭------同一段文本,在两个系统里被切成不同的 chunk,过两套不同版本的模型,落到两套不同维度的向量库里。等到要做跨库召回、要让 Agent 同时检索结构化关系和非结构化片段时,向量空间根本对不上。
这一周做的事情,是让会话系统的知识库流水线,直接调用图谱系统的 embedding 服务。底座只能有一份。 谁切 chunk、谁算向量、谁存索引、谁负责一致性------必须只有一处定义。
这不是节省算力的优化,是消除"两套底座长期漂移"的隐性风险。一旦两套向量空间在某一天被发现召回结果不一致,回头补刀的代价远远大于现在统一接口的代价。
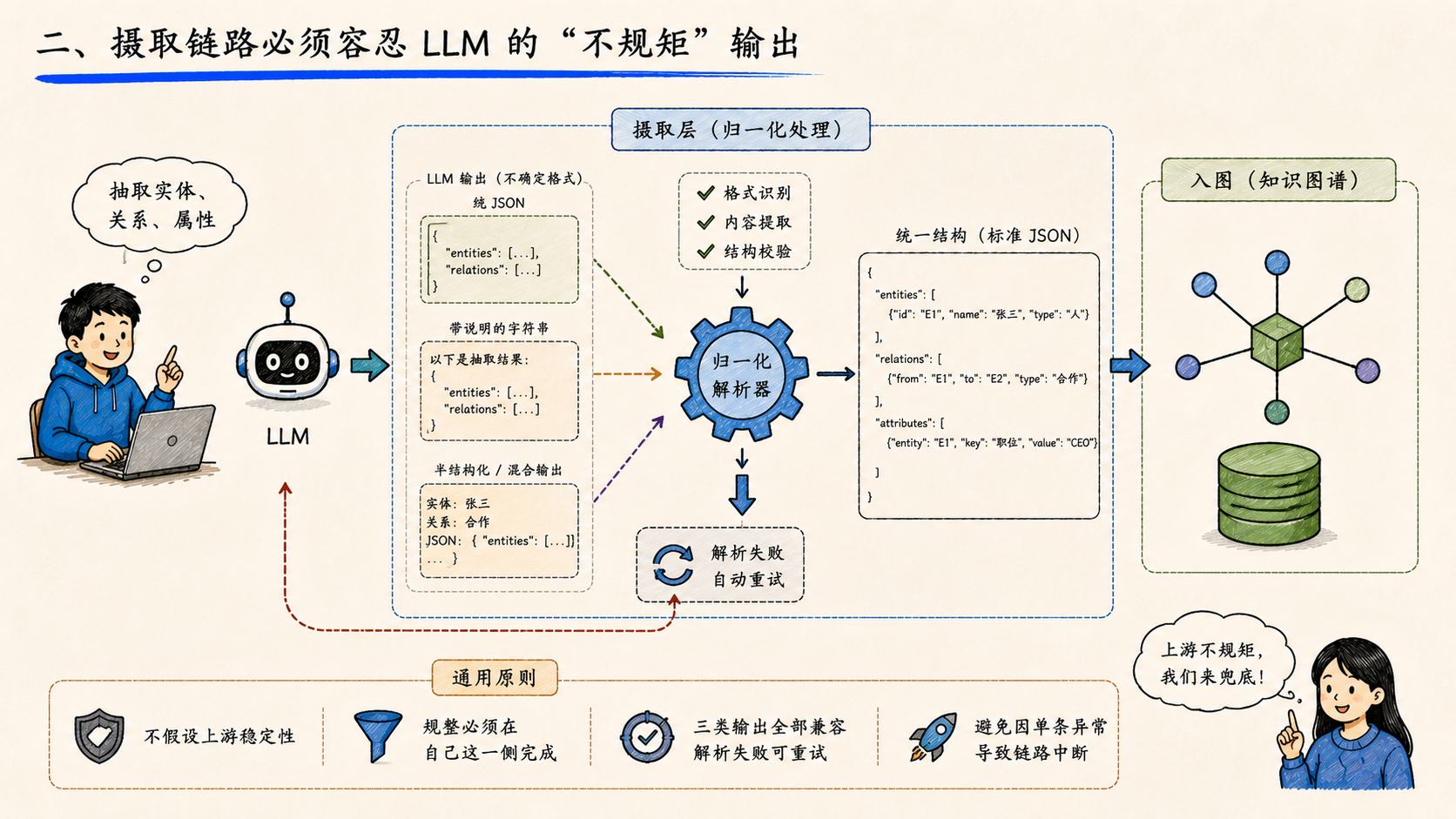
二、摄取链路必须容忍 LLM 的"不规矩"输出
知识图谱的构建链路里,要 LLM 抽取实体、关系、属性,期望它返回结构化 JSON。但 LLM 不是 SDK------它今天给你 JSON,明天可能给你带说明的字符串,后天可能在 JSON 前面加一句"以下是抽取结果:"。
摄取链路如果只接受一种格式,就只能等下次模型版本迭代时崩一次、修一次、再崩一次。
这一次的处理逻辑是:让摄取层做归一化------上游不管返回什么形态,到下游入图之前必须被矫正成统一结构。字符串、半结构化、纯 JSON,三类全部能解析。失败的样本走重试,不让整个项目卡死在一个格式异常上。
这是处理 LLM 输出的通用原则:永远不要假设上游的稳定性,规整必须在自己这一侧完成。
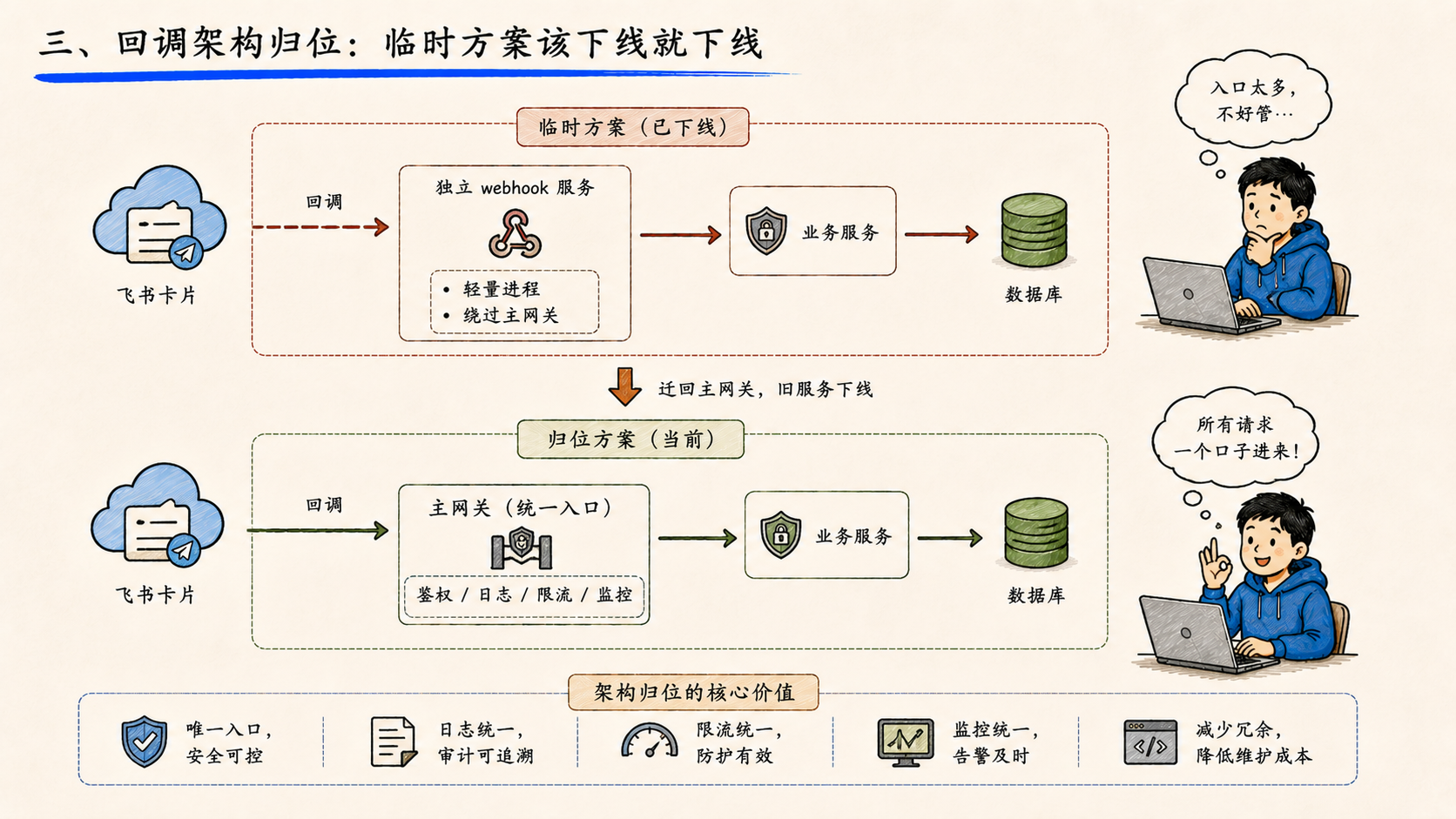
三、回调架构归位:临时方案该下线就下线
飞书的交互卡片回调,最早是另起一个 webhook 服务接的。当时图快,绕过主网关,单独跑一个轻量进程。
但企业级系统不能长期养"绕过主网关的入口"。每多一条独立入口,鉴权、日志、限流、监控就要多维护一份。临时方案存在的时间越长,越容易变成事实上的主路径,最后没人敢动。
这一周把卡片回调迁回主网关,旧 webhook 服务彻底下线。架构归位的核心不是合并代码,是合并"入站路径"------所有外部请求只能从一个口子进来,鉴权和审计才有意义。
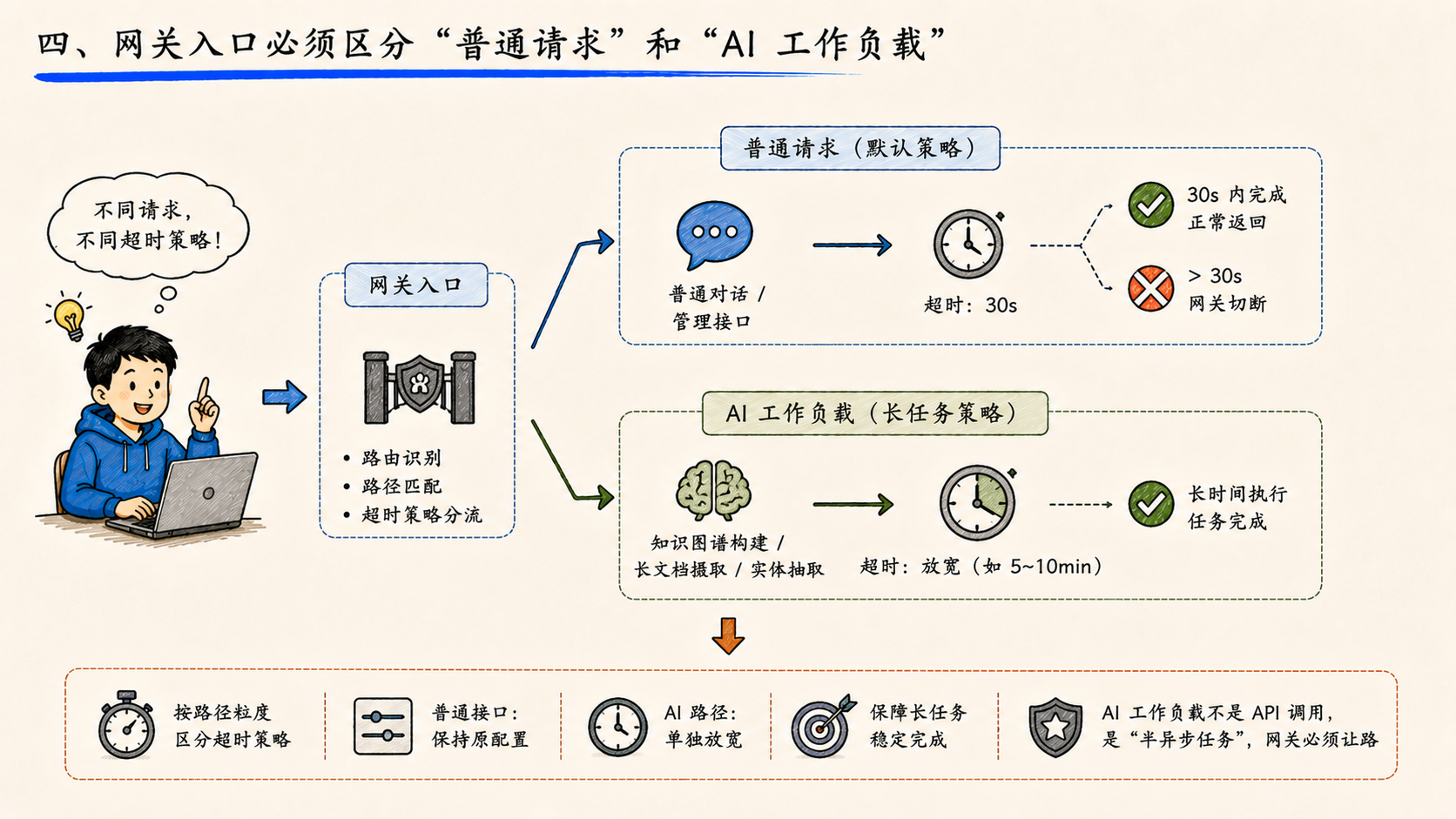
四、网关入口必须区分"普通请求"和"AI 工作负载"
知识库新建项目时,要做实体抽取、本体生成、图谱构建,单次请求可能跑几十秒甚至更久。这种请求和普通 API 调用不能共享同一套超时配置------网关默认 30 秒切断,AI 工作负载就永远跑不完。
调整后的做法是按路径粒度区分超时策略:知识图谱构建、长文档摄取这类路径单独放宽;普通对话和管理接口保持原配置。
这条路径不是配错了,是企业 AI 平台必须正视的事实------AI 工作负载不是 API 调用,是"半异步任务",网关层必须为这件事让路。
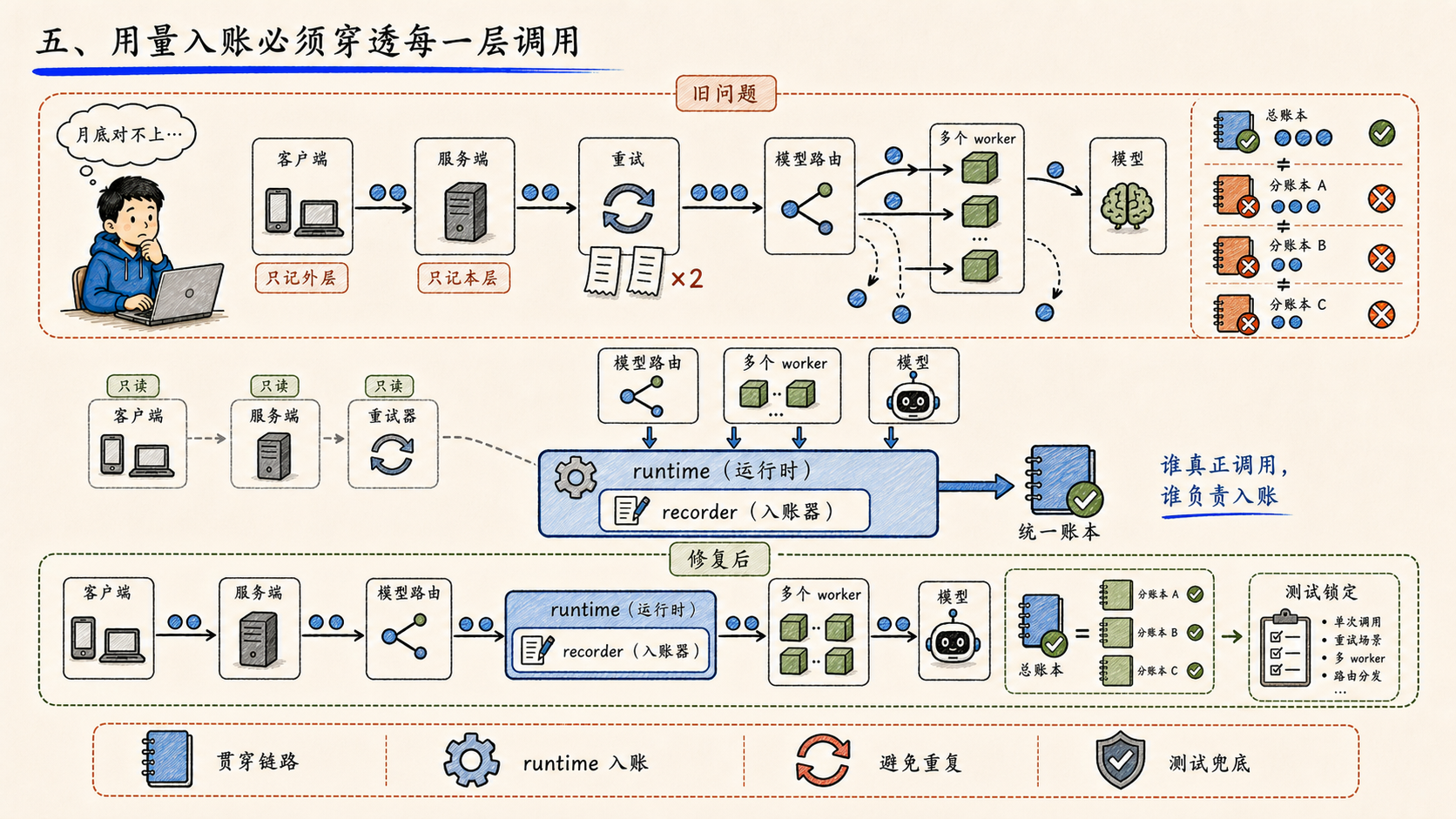
五、用量入账必须穿透每一层调用
token 入账链路修复的核心,不是少记了几次,是多 worker、多次重试、多模型路由场景下,谁负责把 usage_stats 串到底。
模型调用链里,每一层都可能丢失上一层的 token 计数:客户端只统计最外层、服务端只统计本进程、重试逻辑可能把同一个调用算两遍。结果是月底对账时,总账和分账永远对不上。
这次的修法是把 recorder 下沉到 runtime 层------谁真正发起对模型的调用,谁负责把 usage 入账。任何上层包装都只能"读取",不能"声明"。再加上一组单元测试锁定行为,避免后续被某个重构悄悄打回去。
企业级系统的用量统计不是一个加和功能,是一条贯穿调用链的"会计科目"------任何一处断点都会污染全局账本。
写到这里,会发现这一周做的事情,没有一项是"新功能"。全部都在重新厘清边界:谁该有自己的 embedding,谁不该;谁该接外部回调,谁不该;谁该负责入账,谁只是经过;哪些请求可以共用网关策略,哪些必须独立配置。
从 0 到 1 的早期,靠"先跑起来"撑过去;走到企业级阶段,每一次进步都来自一次**"职责重新归位"**。
这,是第三十六天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。