https://www.cnblogs.com/timlly/p/10463467.html#1-%E5%89%8D%E8%A8%80
Paul's point in Colossians 2:23 is a huge relief because it exposes a common trap: the idea that if a spiritual practice is painful or difficult, it must be "better" or "holier."
He calls this out as a "shadow" of the truth. Here is why that realization is so freeing:
- Behavior vs. Heart: You can punish your body or starve yourself of joy, but that doesn't fix the internal struggles like pride, anger, or greed.
- The "Look" of Wisdom: It's easy to impress others (or yourself) by being "hard-core," but God is interested in a transformed heart, not a bruised body.
- The Focus Shifts: When we treat ourselves harshly, the focus is on our effort . Paul wants the focus to be on Christ's finished work.
Essentially, you don't have to "pay" for your mistakes through self-mistreatment because the Bible teaches that the price has already been paid. You are allowed to be kind to yourself because God is kind to you.
In the biblical perspective,
God's kindness isn't a "right" granted to Him by someone else; rather, it is His very nature and identity as the Creator.
a Relationship of Provision.
anchoring your safety in something immovable rather than something fluctuating Present-Moment Living:
Matthew 6:34
advises, "Do not worry about tomorrow, for tomorrow will worry about itself". Much of our pain comes from "borrowing" trouble from a future that hasn't happened yet.
"My therapist gave me great advice: if you're worrying about all the bad in the world, look at your immediate surroundings and notice how life is still going on. It really brings everything into perspective and calms me down."
the Kingdom of God---a place where the "price" for your life has already been paid, and your needs are met by a Father, not a merchant.
the Bible is different---it's more like a mirror than a trophy case.
a "hero" in the Bible who is actually a "coward," it gives you permission to stop pretending. It says: "You don't have to be hard on yourself to get God's attention; He's already in the mess with you."
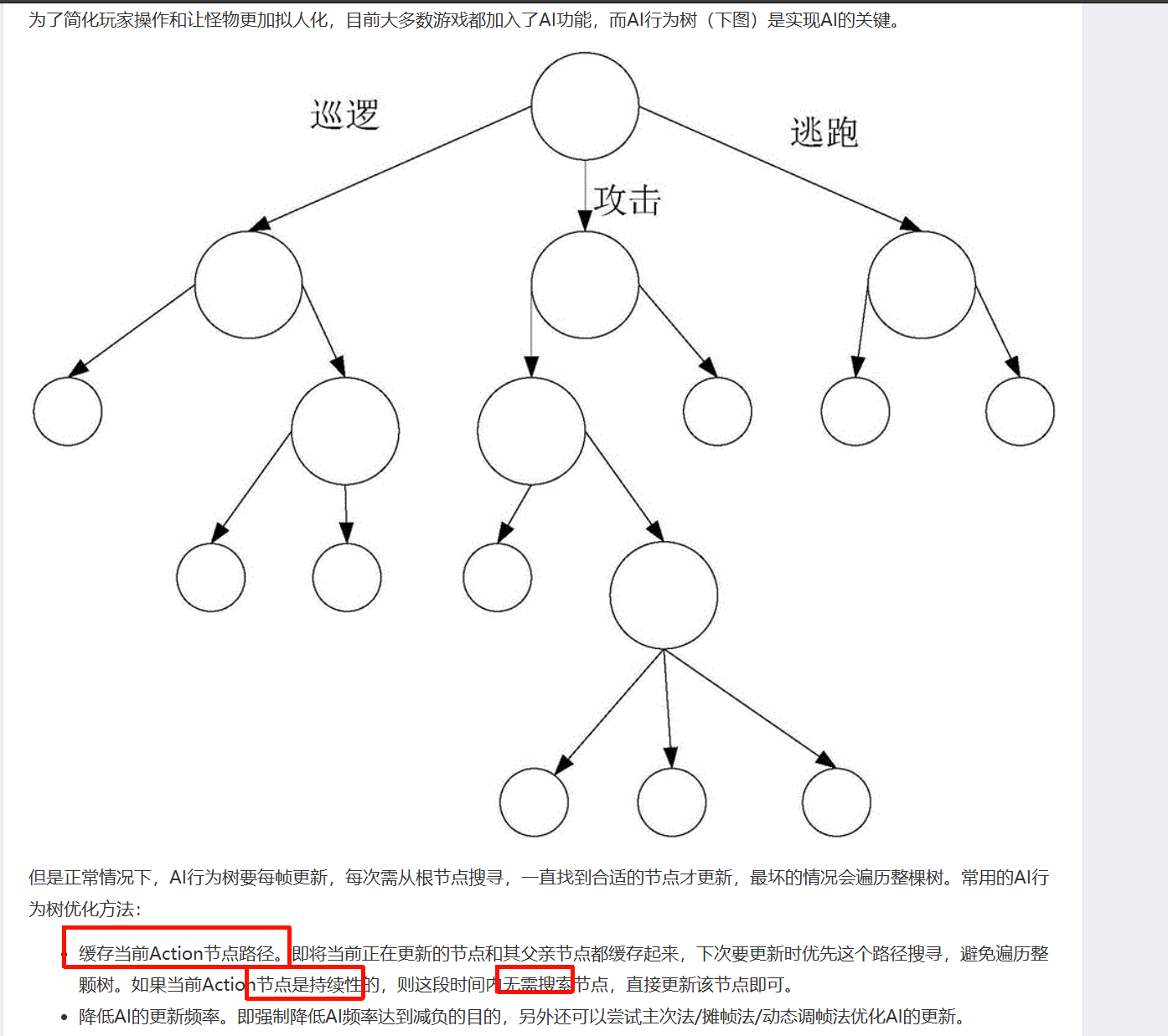
删除脚本内的空回调。即便脚本对象的回调函数为空,但也会产生引擎核心与脚本层的开销。
更高效的拼接方式,如C#的StringBuilder。
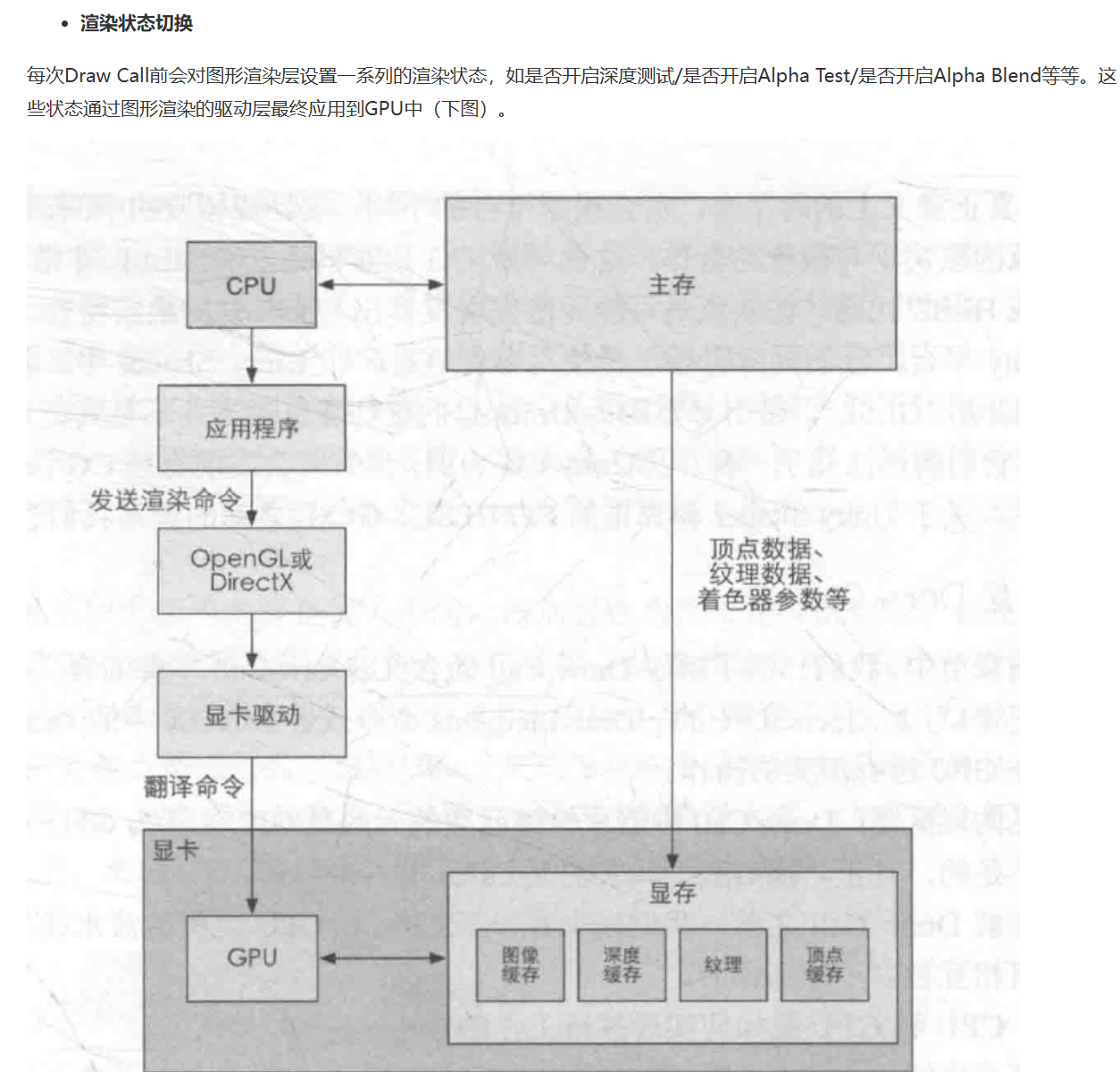
当代显卡驱动做了很多工作:状态管理/容错处理/逻辑计算/显存管理等等,属于重度封装
the people chase the star, act like star
看"链路两端 + 总线标准本身",不是只看某一个设备。PCIe 3.0 / 4.0 / 5.0,x4 / x8 / x16。
这决定了理论上限。
例如同样是显卡插槽,PCIe 4.0 x16 的带宽上限就高于 PCIe 3.0 x16。PCIe 控制器通常由 CPU 和主板平台共同决定。"CPU 提供车道能力,主板负责把这些车道正确接出来"。
-
CPU 支持几代 PCIe
-
主板插槽支持几代 PCIe
-
插槽实际跑的是 x16 还是被分成 x8 / x4 比如:
-
CPU 支持 PCIe 5.0
-
主板插槽支持 PCIe 5.0 x16
-
但显卡只支持 PCIe 4.0 x16
那最终就只能跑 PCIe 4.0 x16。
带宽上限:看 PCIe 代际 × lane 数Windows 的设备管理器里,你只能确认设备是否正常识别,基本看不到 PCIe 代际和 lane 宽度,在 Linux 上,可以用:
overflow-visible!Bash
lspci -vv | grep -A 20 VGA然后看里面类似:
-
LnkCap:链路最大能力 -
LnkSta:当前链路状态
例如会看到:
-
Speed 16GT/s对应 PCIe 4.0 -
Width x16对应 16 条 lane
判断逻辑很简单:
-
LnkCap看"这条链理论支持到哪" -
LnkSta看"现在实际跑在哪"
常见代际和速率大致对应关系是:
-
PCIe 3.0 ≈ 8 GT/s
-
PCIe 4.0 ≈ 16 GT/s
-
PCIe 5.0 ≈ 32 GT/s
你真要判断"总线是不是拖后腿",建议按这个顺序看:
先看 GPU-Z 或 HWiNFO 里的当前链路状态;再确认主板说明书里这个插槽是不是直连 CPU、是否会因为装了 M.2 / 其他扩展卡而降成 x8 或 x4;最后再结合压力场景判断是不是实际瓶颈。
GigaTransfers per second
也就是"每秒多少十亿次传输"。
它描述的是 PCIe 链路上的信号传输速率,不是最终有效数据吞吐量。
你可以这样理解:
-
GT/s= 总线线上"跳变/传输事件"的频率 -
GB/s= 真正对软件有意义的数据带宽
中间还隔着两层东西:
-
编码开销
PCIe 传输不是所有比特都拿来装有效数据。不同代际编码效率不同。
-
lane 数量
PCIe 通常是 x1 / x4 / x8 / x16,多条 lane 叠加后总带宽才高。
PCIe 3.0 开始用的是 128b/130b 编码 ,编码损耗很低。
所以:
-
PCIe 3.0:8 GT/s,单 lane 有效大约 0.985 GB/s
-
PCIe 4.0:16 GT/s,单 lane 有效大约 1.969 GB/s
-
PCIe 5.0:32 GT/s,单 lane 有效大约 3.938 GB/s
再乘 lane 数:
-
PCIe 5.0 x16 ≈ 63 GB/s 单向
-
双向同时算总吞吐,可以接近 126 GB/s
一个非常实用的工程近似值:
-
PCIe 3.0 x16 ≈ 16 GB/s
-
PCIe 4.0 x16 ≈ 32 GB/s
-
PCIe 5.0 x16 ≈ 64 GB/s
1 秒最多传约 64GB 数据
-
-
1 秒 ≈ 64GB
-
0.5 秒 ≈ 32GB
-
0.1 秒 ≈ 6.4GB
-
1 ms ≈ 64MB 左右
-
64 GB/s 是单向 。
也就是 CPU -> GPU 方向大约 64 GB/s,GPU -> CPU 方向也各自有自己的带宽预算。 -
PCIe 带宽:决定 CPU 和 GPU 之间"搬运数据进去/出来"的速度
-
显存带宽:决定 GPU 在显存内部"读写工作数据"的速度
显存带宽则是数据已经进了 VRAM 之后,GPU 自己在里面高速访问:
-
采样纹理
-
读写 color/depth
-
访问 G-buffer
-
compute shader 读写 buffer
-
ray tracing 访问 BVH / geometry / material data
第二,量级通常差很多。
PCIe 是 CPU 和显卡之间的外部链路。
你往 GPU 上传:
-
texture
-
vertex/index buffer
-
animation data
-
compute input
-
readback result
这些先过 PCIe。
PCIe 不够时,常见现象是:
-
资源上传卡顿
-
streaming 跟不上
-
readback 很慢
-
dynamic buffer 每帧更新过大
-
CPU->GPU copy 过多
-
场景切换/首次加载抖动
-
ReBAR / upload heap / staging 路径不合理时更明显
显存带宽不够时,常见现象是:
-
高分辨率下 fillrate 压力大
-
大量纹理采样变慢
-
G-buffer / post-processing / TAA / SSR / SSGI / RT pass 很吃力
-
shader 本身不是算力瓶颈,而是 memory-bound
-
提高分辨率、提高贴图质量、增加 RT 数据访问后掉帧明显
大量纹理采样变慢
-
PCIe 瓶颈更像"送货送不进来"
-
显存带宽瓶颈更像"货已经在仓库里,但仓库内部搬运不够快"
-
你有一张显存带宽 800 GB/s 的卡,听起来非常大。
但如果你每帧都从 CPU 往 GPU 上传很多 MB 甚至上百 MB 的数据,那么真正卡住你的可能不是 800 GB/s,而是前面的 PCIe 32 GB/s 或 16 GB/s。显存再快,也救不了"数据还没进显存"这个问题。反过来,如果你的资源早就常驻显存里了,那么 PCIe 基本就不重要了;这时候性能更取决于:
-
显存带宽
-
cache 命中
-
shader 访存模式
-
ROP / texture unit / compute occupancy
这也是为什么图形程序都尽量做:
-
资源常驻
-
减少每帧 upload
-
大块 streaming,少碎片 copy
-
减少 readback
-
避免把 PCIe 当"实时内存总线"用
显存占用过高显存分配失败,导致画面异常甚至程序崩溃Shader过于复杂或者片元过多,会极大提高GPU计算量被合的所有模型都引用同一个材质离线合批的是静态模型美术利用专业建模工具合批。如3D Max/Maya等引擎插件或工具。如Unity的插件MeshBaker和DrawCallMinimizer,可以将静态物体进行合批。实时合批是游戏引擎在游戏运行期完成的。Unity引擎分为静态合批和动态合批。合静态合批的条件有两个:一是模型有Static标记(即物体是静态的,不能有移动/动画/物理等)引用同一个材质实例。为了提高静态合批的概率,尽可能将场景物件设为静态,并且类似的物件引用相同的材质。动态合批是针对可以运动的模型模型少于300个顶点,少于900个顶点属性。不能有镜像Transform。同一材质实例(注意:是实例,相同的材质不同的实例,也是不行的)合批优化虽能降低Draw Calls耗CPU计算将多个模型合成一个额外开辟内存存储合成的模型状态缓存减少渲染管线的切换开启Alpha Blend了一般会关闭深度测试,无法利用深度测试剔除多余片元禁用Alpha Test。现代部分移动端GPU采用了特殊的渲染优化方式,如PowerVR采用Tile Based Deferred Rendering方式(下图右),而Alpha Test会破坏Early-Z优化技术
https://www.jianshu.com/p/b32f4f70b4d0

不是因为 discard 这条指令本身特别贵,而是它让 GPU 很多本来能提前做、能批量做、能在片上完成的优化失效了。机制的关键前提是:
GPU 要尽早知道一个 fragment 会不会留下来。
是否丢弃,往往要等 fragment shader 跑到一半甚至跑完整个采样逻辑之后才知道意味着 GPU 不能在更早阶段稳定地说:
"这个片元肯定没用,别管它"
用了 discard 后,很多 fragment 得先执行 shader 才知道死不死。主流移动 GPU 仍然主要是这几家:Arm Mali、Qualcomm Adreno、Imagination PowerVR;Android GPU Inspector 现在也还是围绕这三类 GPU 提供计数器和分析支持,说明它们仍然是当前移动图形优化的主战场。PowerVR 仍明确是 TBDR;Arm 的当前 best practices 也还在强调 discard 会把片元推到 late ZS 路径。现代硬件、驱动、编译器比早年强很多,很多 case 不再是"一开 clip 就直接崩"。现在更准确的说法是:只要 shader instruction stream 里包含 discard,硬件就更难提前判定 fragment 是否保留,early-z/hidden-surface-rejection 的空间会缩小;但实际损失大小取决于 overdraw、shader 重度、draw ordering、depth prepass、alpha coverage、目标 GPU 架构和驱动实现。 Arm 现在的文档就是这种表述:discard/alpha-to-coverage 会强制 late ZS updates,并可能带来冗余 shading 或流水线饥饿;并不是说所有场景损失都一样大。但它往往会把问题从"是否可见"延后到 shader 执行后才知道,所以 overdraw 高、shader 又重时,代价会很明显。Arm 现在仍建议"minimize your use of shader discard and alpha-to-coverage"。不是说透明混合本身便宜。透明仍然有排序、overdraw、不能像 opaque 那样激进 early reject 的问题。
也就是说:
blend和clip往往是在不同代价之间折中,不存在统一赢家。While Deferred Rendering definitely benefits from Z-prepasses to minimize G-buffer bloat, Early-Z is a hardware-level optimization that functions in both forward and deferred pipelines to reduce overdraw. is the hardware capability, while Z-Prepass Early-Z is a hardware feature that automatically performs the depth test before the fragment shader runs.Z-Prepass is a rendering pass where you draw geometry (usually just positions) to "prime" the Z-buffer.The Synergy: Hardware Early-Z only works if it has a "target" to test against. A Z-Prepass ensures that the Z-buffer is already filled with the closest surfaces, so the subsequent main shading pass can use Early-Z to instantly discard occluded pixels with near 100% accuracy.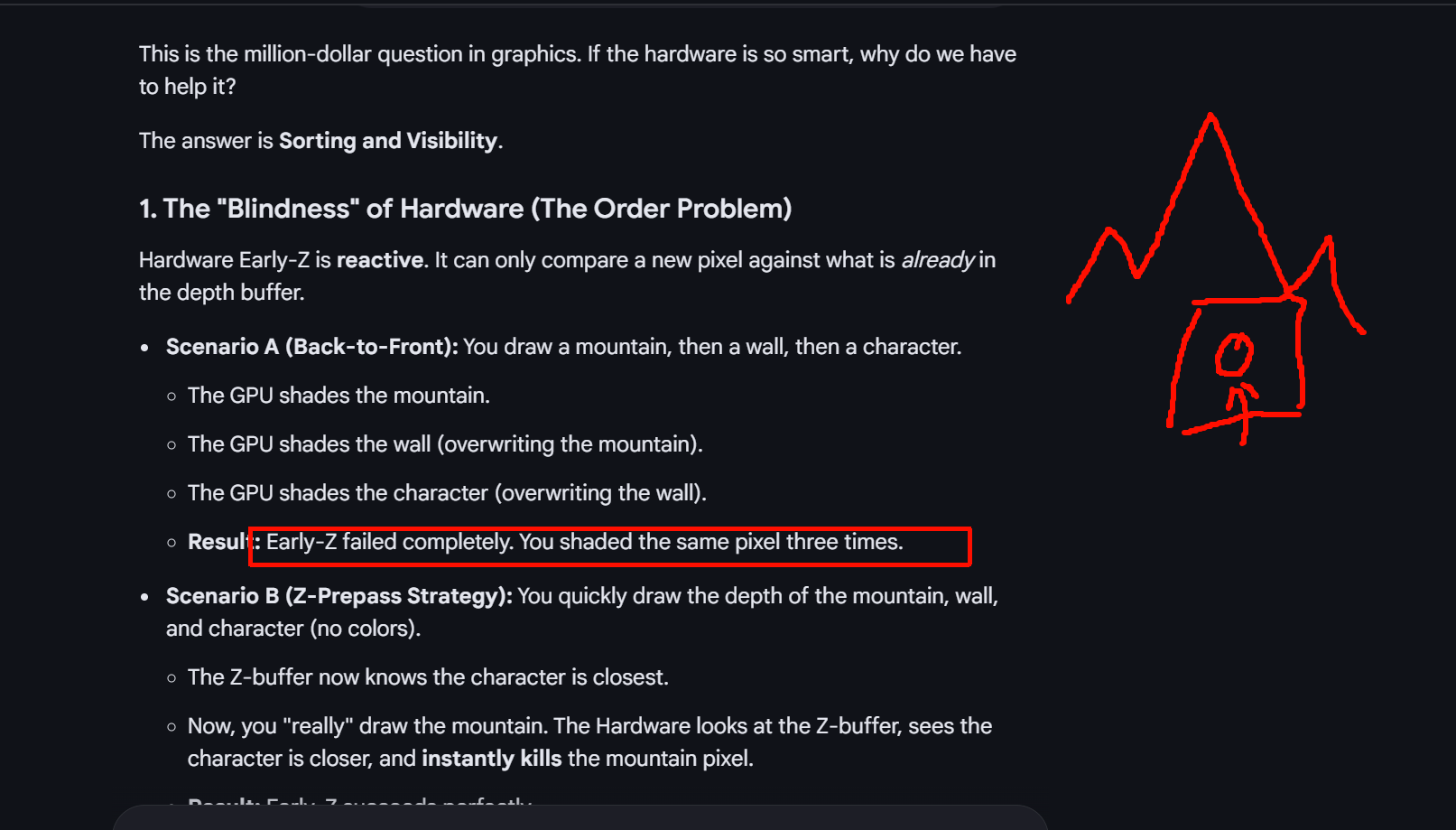
earlyz是order的自然做法,意思是渲染顺序
这里是山,墙,人,earlyz是没有发挥作用的,
如果这里是人,墙,山,那earlyz才是硬件上的发挥了作用
It can't work in that specific order (People → Walls → Mountains ) because Early-Z is reactive , not proactive.
Scenario B (Z-Prepass Strategy): You quickly draw the depth of the mountain, wall, and character (no colors).
- The Z-buffer now knows the character is closest.
- Now, you "really" draw the mountain. The Hardware looks at the Z-buffer, sees the character is closer, and instantly kills the mountain pixel.
- Result: Early-Z succeeds perfectly.
对于不透明物体 ,通常应该尽量前往后 ,这样最能利用 Early-Z 和层级深度剔除。
对于透明物体 ,通常才要后往前 ,原因不是 Early-Z,而是混合正确性 。透明往往不开深度写入,只做深度测试并进行 alpha blending;这时为了得到正确叠加结果,必须按后往前排序。从远到近渲染则优化效果甚微。为了达到最佳顺序,通常需要在CPU端对物体进行排序,但这在复杂场景中会带来额外的CPU开销一个额外的渲染通道(Pass),专门用于生成场景的深度图,从而"引导"后续的Early-Z高效工作。主要目的是解决Early-Z对渲染顺序的依赖问题,并在Early-Z可能失效的情况下(如使用Alpha Test)提供一个替代方案
DirectX and modern graphics APIs,
Shader Resource Views (SRV) and Unordered Access Views (UAV) are "wrappers" (descriptors) that tell the GPU how to interpret and access a memory resource (like a texture or buffer).Shader Resource View (SRV)Unordered Access View (UAV) Primary Function : Provides read-only access to a resource within a shader.Primary Function : Provides read and write access to a resource, allowing shaders to modify data arbitrarily.PS指 Pixel Shader,也就是 Fragment Shader,对应光栅化后每个片元执行的着色程序。
CS指 Compute Shader。它不走传统图形管线,不依附于三角形光栅化,通常更常见地读写 UAV。
UAV
是 Unordered Access View。意思是 shader 可以对某个资源做"随机读写/无序写入",而不只是像 render target 那样按固定像素位置输出。常见可写对象包括:
-
RWTexture2D
-
RWStructuredBuffer
-
Append/Consume buffer
在 D3D 语境里,PS 写 UAV 就是"pixel shader 在执行时顺便往某个可读写资源里写数据"。
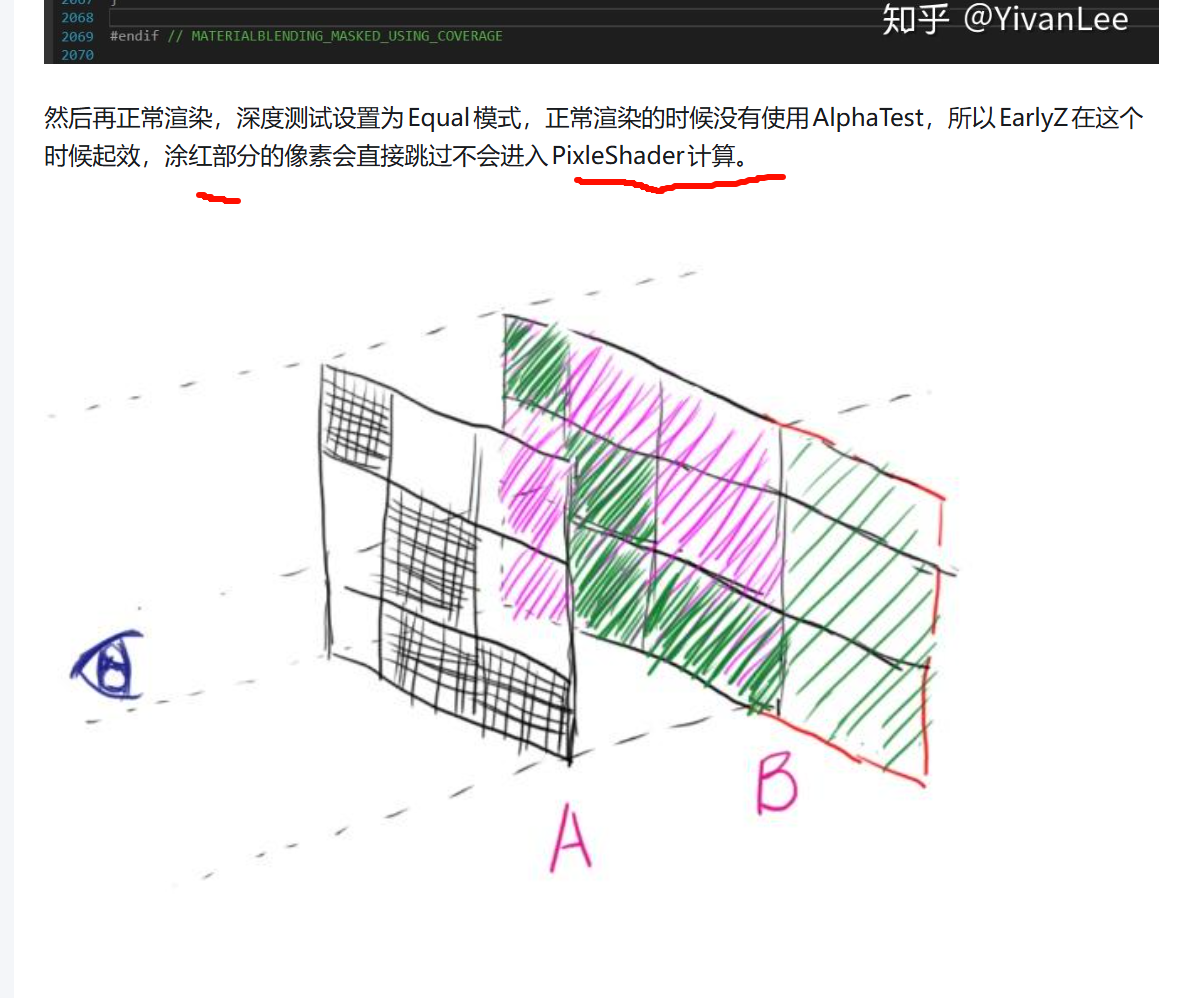
最原始的渲染流程中,会先渲染A。再渲染B,在渲染B的时候会比较当前渲染的像素的深度和深度Buffer的值,如果通过深度测试则保留,没有通过深度测试则会被丢弃,这时就会带来浪费。当PixleShader计算量越大的时候,这个浪费就会越明显,所以显卡商把深度比较这个事情放到PixleShader前面进行,这个新的阶段取名叫EarlyZ(当然还有其它方法技术名字就是其它的了)Alpha Test或者Depth modify都会使early z失效,把AlphaTest这个操作转移到其它地方去,比如PreDepthPass。
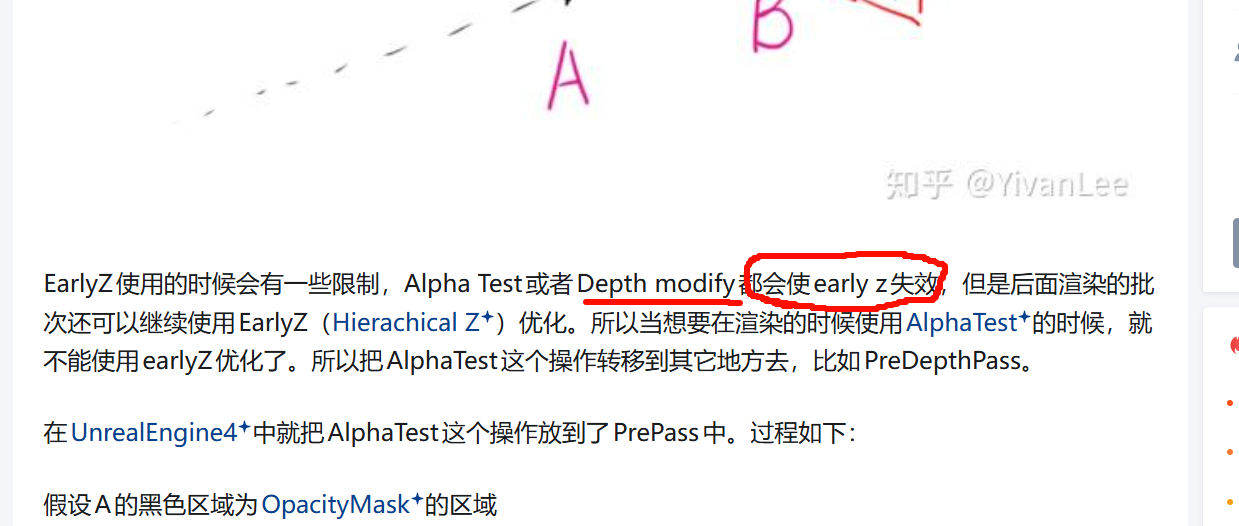
所以gpu内部有自己的检测机制,消耗很小,如果改了东西就自动关掉,
会自动关掉
在UnrealEngine4中就把AlphaTest这个操作放到了PrePass中在渲染Depth的时候就用AlphaTest把OpacityMask的区域像素的深度剔除掉。PPrePass写深度的时候因为使用了AlphaTest,所以EarlyZ这个时候失效。不是 CPU 在逐像素控制。你看到的这段本质上是 shader 代码的模板/宏展开结果,最终会被编译成 GPU 上执行的着色器程序。虽然源码长得像 C/C++ 宏风格,但语义上是在描述 pixel shader 的逻辑。UE 自己那套 shader 生成系统里的 shader 源码。
UE 的 shader 源码经常混合了:
-
HLSL 风格语义
-
大量 C 预处理宏
-
引擎自定义 include / permutation 宏
-
针对不同平台的条件编译
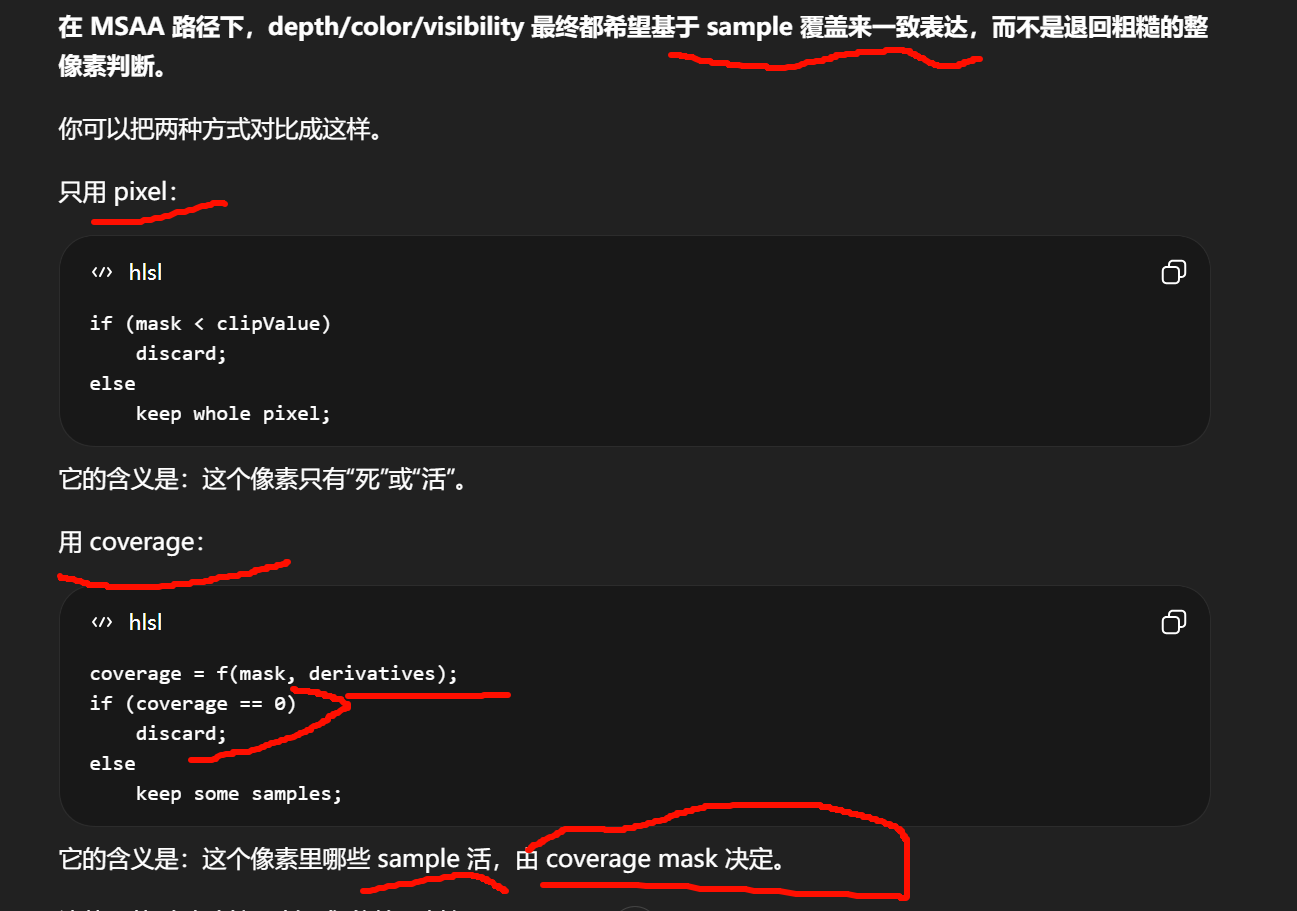
pixel是像素级二值决策,coverage是采样级部分覆盖决策。普通单采样渲染里,一个屏幕像素通常只有一个采样结果。那你只能做这种判断:
-
留下这个像素
-
丢弃这个像素
这就是典型的:
overflow-visible!hlsl
clip(mask - threshold);结果是 0 或 1,没有中间态。
所以它是 pixel 级控制。
MSAA 不是这样。一个像素里可能有 2/4/8 个 sample。这个时候真实情况常常是:
-
这个像素并不是"全被物体覆盖"
-
而是只覆盖了其中一部分 sample
例如树叶边缘、铁丝网边缘、草叶边缘。
如果你还用 pixel 级二值判断,就只能二选一:
-
要么整个像素都算叶子
-
要么整个像素都不算叶子
边缘会非常硬,闪烁也会重。
而 coverage 允许你表达成:
-
4 个 sample 里命中 1 个
-
4 个 sample 里命中 2 个
-
4 个 sample 里命中 3 个
-
4 个 sample 里全命中
这就接近"部分覆盖"。
coverage 的好处就在这里:
它不需要把像素粗暴地二值化,而是可以把 mask 强度映射成 sample 覆盖率。
于是边缘从"整像素跳变"变成"sample 数量渐变"。
比如 4x MSAA 下可以近似成:
-
mask 很低:0000
-
稍高一点:0001
-
再高:0011
-
更高:0111
-
很高:1111
视觉上就会更平滑。
函数名为什么叫
GetDerivativeCoverageFromMask。这里不是随便从 mask 值直接映射 sample 数,而是通常会结合导数
边缘的真实覆盖比例和"当前像素内 mask 的变化率"有关。在 PrePass 里,目标往往是尽量准确地建立后续可见性。
对于 opaque 几何,整像素写深度没问题,因为轮廓就是三角形轮廓。
但对 masked 几何,真正轮廓来自 mask 纹理,不是几何边界。pixel 级保留/丢弃:coverage:
-
某些 sample 写深度,某些不写
-
深度边缘可以跟 sample 级覆盖一致
-
比较典型的"动作 + 对象 + 方式/条件"的命名法。
DiscardMaterial
表示这个函数的核心目的,是把当前材质对应的片元丢弃掉,或者至少决定是否丢弃。WithPixelCoverage
表示它不是普通的直接 discard,而是"借助 pixel coverage 这个机制来做"。也就是:它在做 discard 决策时,会顺带产出 sample/pixel coverage 相关结果。会顺带产出 sample/pixel coverage 相关结果。更倾向于这种风格:
-
GetMaterialOpacityMaskClipValue -
ApplyPixelDepthOffsetToMaterialParameters -
GetDerivativeCoverageFromMask
特点都是:
先说动作,再说对象,再把修饰条件全挂后面。
命名的优点是,单看函数名就知道大概干什么;
Material其实也不一定是"整个材质对象"那个意思,更接近"当前材质片元求值过程"。在 shader 代码语境里,它实际处理的是"当前 fragment 的材质结果",不是 CPU 侧那个UMaterial资源对象。"根据当前材质像素输入,利用 coverage 规则决定是否丢弃当前片元,并返回 coverage mask"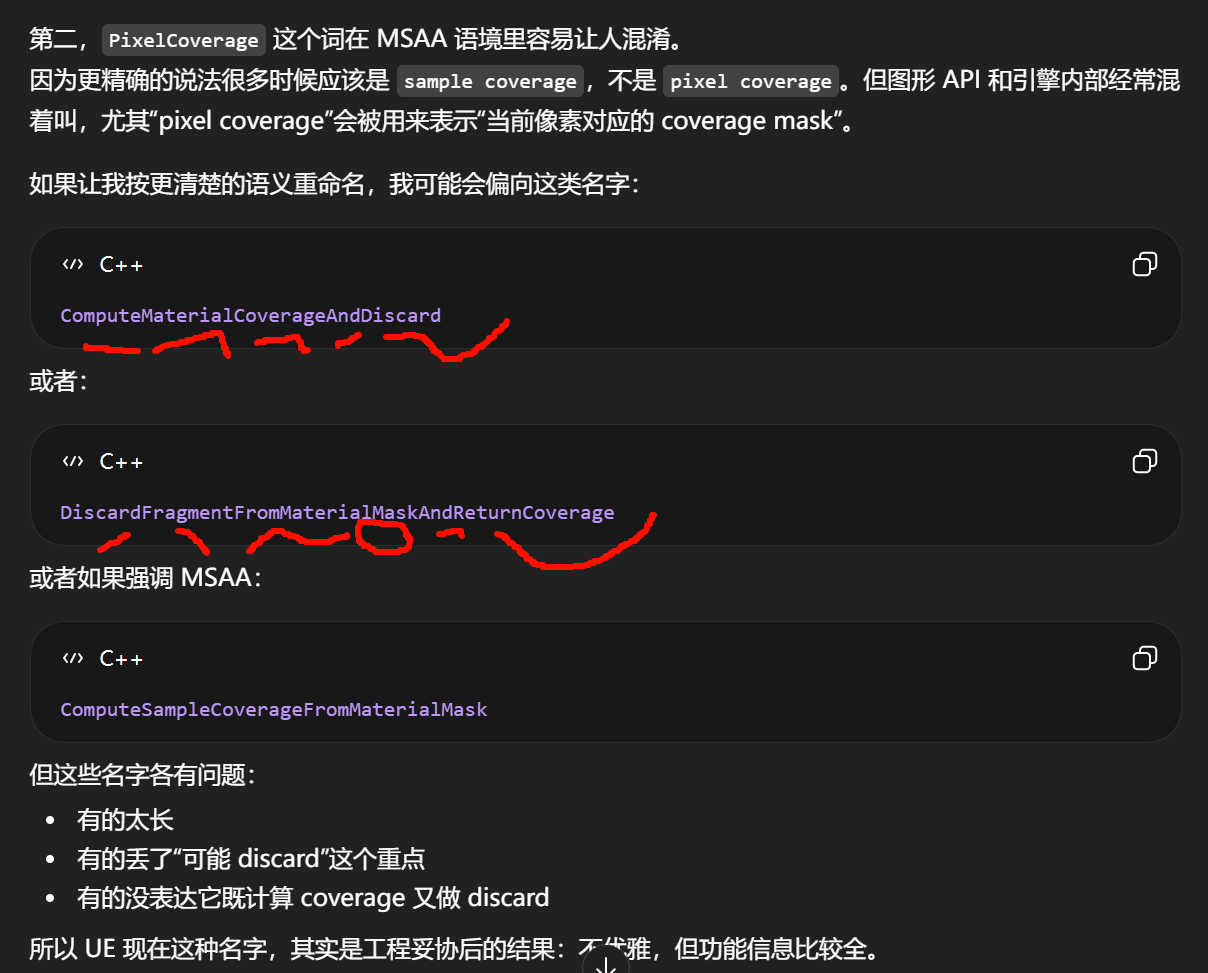
大量重叠物体,使用PrePass+EarlyZ优化的方案能节省大量性能,比如绝地求生中的大量草丛。
BasePass关键处理步骤
-
初始化与清除
首先清除GBuffer,为新帧渲染准备空白数据缓冲区。
-
顶点着色器处理
顶点阶段通过BasePassVertexShader.usf实现,完成世界坐标变换、雾效计算(高度雾、大气透视)、顶点光照(体积光照、预计算辐照度体积)及运动模糊速度向量生成。例如,函数CalculateHeightFog()和GetAerialPerspectiveLuminanceTransmittanceWithFogOver()负责雾效与大气透视,而GetVolumetricLightmapSH1()则采样预计算光照数据。
-
像素着色器处理
像素阶段通过BasePassPixelShader.usf执行,核心函数FPixelShaderInOut_MainPS将材质属性(如WorldNormal、Metallic、Roughness)编码为GBuffer辅助结构体,并输出到MRT的0-7通道。此时深度测试已通过PrePass优化,仅对可见像素计算,避免Overdraw。
-
多材质混合支持
通过宏定义区分半透明、加法、调制等混合模式,确保不同材质访问正确的场景纹理缓冲区。例如,半透明材质会重定向SceneTexturesStruct至TranslucentBasePass.SceneTextures。
BasePass与PrePass、Lighting Pass形成流水线:
- PrePass:提前写入深度缓冲,处理AlphaTest,为BasePass提供遮挡信息;
- BasePass:输出GBuffer数据;
- Lighting Pass:基于GBuffer计算光照,实现延迟渲染。
BasePass 并非延迟渲染独有的概念,而是在不同渲染架构中都存在的基础渲染阶段,在延迟渲染 中,BasePass 是核心环节,负责将几何体的深度、法线、材质属性(如金属度、粗糙度)等信息编码到 GBuffer(几何缓冲区)中。例如在 Unreal Engine 中,BasePass 通过多目标渲染(MRT)将数据输出到多个纹理通道,为后续 Lighting Pass 提供像素级别的几何信息。而在前向渲染 中,BasePass 的功能则完全不同:它直接计算光照并输出最终颜色,无需依赖 GBuffer。例如 Unity 的前向渲染管线中,BasePass 处理主方向光和环境光,而 Additional Pass 处理其他逐像素光源。移动端 Unreal Engine 的前向渲染甚至会通过 MobileBasePassVertexShader.usf 直接在顶点阶段完成部分光照计算,以降低像素着色器开销。
-
先把机器码反汇编成汇编
-
再根据控制流、调用关系、栈布局、寄存器使用
-
尽量猜出 if / while / switch / function / local variable
-
最后拼成一份"看起来像 C"的伪代码
所以反编译器并不是"把源码存档拿回来",而是在猜原始高级结构。
为什么 Java / C# 反编译效果好,而 C++ 差很多。
因为 Java / C# 编译后通常不是直接下沉到原生机器码,而是:
-
Java -> bytecode
-
C# -> IL
这些中间表示仍然保留了很多高级语言信息,比如:
-
类结构
-
方法边界
-
异常表
-
元数据
-
类型信息
-
命名信息的一部分
-
虚调用和对象模型的结构
所以反编译器看到的不是"裸机器码",而是"带高级语义的中间码"。
C++ 不一样。大多数发布版本最终是:
-
C++ 源码
-
编译器优化
-
直接变成机器码
-
再经过链接、内联、去符号、重排
最后留下的是"CPU 怎么执行",不是"程序员当初怎么写"。
所以 C++ 反编译的根本难点,不是不能做,而是:
输入信息太贫瘠。
第三层,C++ 编译后具体丢了什么。
这个最关键。
- 变量名基本没了
你源码里写:
overflow-visible!C++
float opacityMask = SampleMask(uv);编译后不会保留
opacityMask这个名字。反编译器最多给你起个:
overflow-visible!C++
v17
tmp_3
local_28- 类型信息大量丢失
比如这是
int、unsigned int、bool、enum、指针、自定义类,很多时候机器码里都不明显。特别是优化后,很多值只是在寄存器里流动,反编译器只能推断"这是个 32-bit 值"。
- 控制结构被改写了
你写的是:
overflow-visible!C++
if (...) { ... } else { ... }编译器可能会变成:
-
条件跳转
-
合并基本块
-
分支消除
-
cmov
-
predication
-
loop unrolling
反编译器再把它"猜回去",不一定还是你原来的结构。
- 函数边界可能被破坏
优化一开:
-
小函数被内联
-
尾调用被折叠
-
多个逻辑混在一起
-
未使用函数被删除
于是你源码里 5 个函数,机器码里可能只剩 2 块混合逻辑。
- 类和对象语义被压平
C++ 的:
-
继承
-
模板
-
inline
-
运算符重载
-
RAII
-
lambda
-
constexpr
-
SFINAE
-
宏展开
这些在编译后很多都变成普通函数调用、内存访问和跳转。
"这原来是个模板类成员函数"这种高级信息,机器码通常不直接告诉你。
1.你原来写:
overflow-visible!C++
x * 8最后可能变成移位。
你原来写一个循环,最后可能被展开成多段直线代码。
你原来分了好几个临时变量,最后全被寄存器合并。
所以反编译器看到的是"优化后的执行形态",不是"源码写法"。
这就是为什么大家常说:
原生代码能逆向出逻辑,不能可靠恢复源码。
说"UE4 资源可以提取,但 C++ 不行",大概率想表达的是:
-
资源文件、蓝图字节码、某些脚本数据,能提取、能分析
-
但 UE4 的 C++ 游戏逻辑编译成原生代码后,想恢复成项目源码级别,几乎不现实
这个说法在工程语境里是成立的。
因为"可逆向"不等于"可恢复工程"。
你把一个 UE 游戏 EXE 拿来逆向,确实可以:
-
反汇编
-
看函数调用
-
找字符串
-
找 UObject / UFunction / FName 相关符号
-
分析 gameplay 逻辑
-
做 hook、mod、patch
但你很难恢复出:
-
原始项目目录结构
-
类名和变量名的完整语义
-
模板代码原貌
-
宏展开前的写法
-
蓝图和 C++ 混合工程的真实组织方式
-
可直接重新编译通过的工程源码
所以"不能反编译"的民间说法,实际是在说:
不能高质量恢复成原工程源码。
和 Java/C# 那种高保真反编译完全不是一个级别。以Metal/Vulkan等架构出现为界限,将它们分成两个阶段。
-