2026年必然是多模态视觉算法应用爆发的一年
或者一键直达 猛戳 【零样本缺陷检测学习 资料都在这里】
第一重 CNN分类与分割
核心目标:
解决"有没有缺陷"以及"缺陷在哪里"的问题。
技术栈:
cpp
图像分类(CNN)、目标检测(YOLO, Faster R-CNN)、语义分割(U-Net, DeepLab)。在这一阶段,工程师将工业问题转化为标准的深度学习任务:实现从数据清洗、数据标注、模型训练、微调、导出部署、加速推理等环节。

其中模型训练绝大多数都是直接套用成熟的CNN架构如YOLOv8\YOLO11\YOLO26等,利用迁移学习在预训练模型上进行微调。
缺点跟局限性:
在实验室环境(打光完美、样本均衡)下准确率很高,但一旦遇到成像噪声、光照变化、未见过的缺陷形态,模型会表现出极度的不确定性,容易出现严重的误检(将灰尘误判为划痕)或漏检。
金句: 初入此境,以为深度学习即"万能特征提取器",追求的是Loss曲线的收敛,却往往困于"过拟合"与"泛化性"的囚笼。
第二重 异常检测与小样本学习
技术栈:
cpp
异常检测(PatchCore, PaDiM, DRAEM)、生成对抗网络(AnoGAN)。在这一阶段,从业者意识到工业场景的特殊性:
正负样本失衡: 工厂里99.9%是良品,缺陷品凤毛麟角,且缺陷形态千奇百怪。
语义鸿沟: 传统的分类模型会把"没有见过的东西"(如机器上的油污、新的划痕类型)强行归类为"良品"或"某类缺陷",导致逻辑错误。
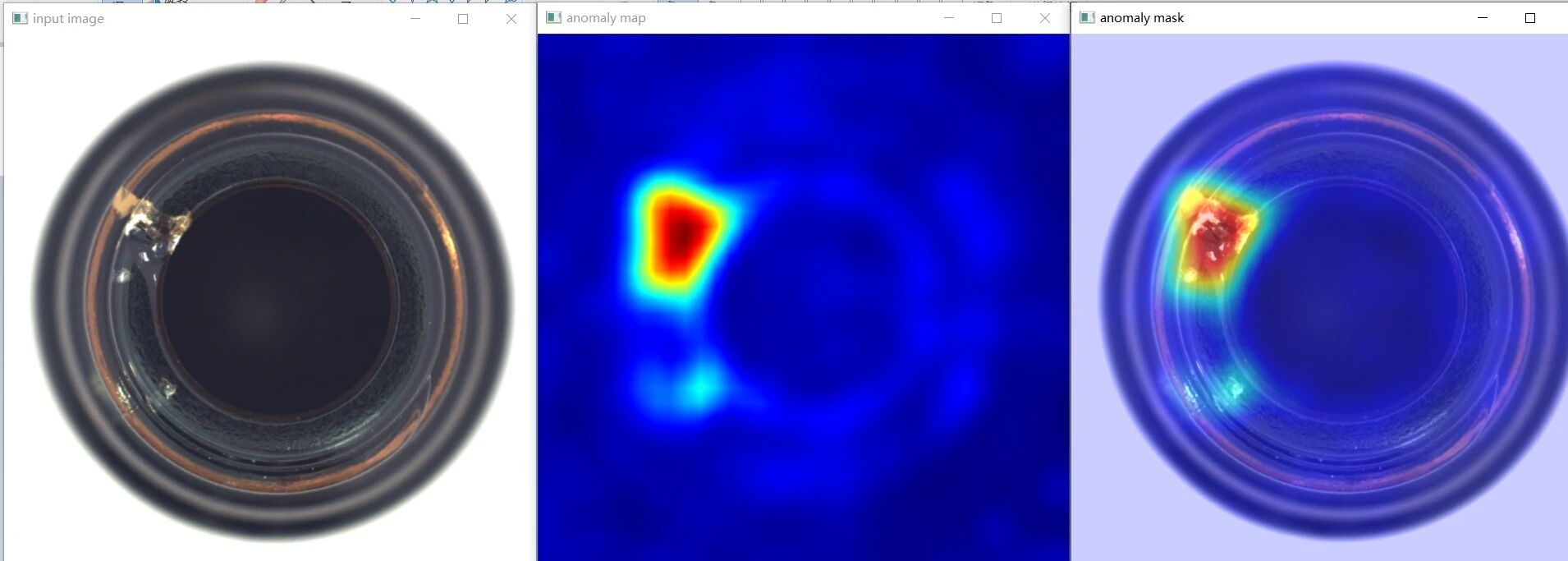
异常检测范式:
看山不是山,不再试图学习"什么是缺陷",而是让模型深刻学习"什么是正常"。在推理时,任何偏离"正常流形"的特征都被判定为缺陷。这种方法天然解决了"未知缺陷"的问题。
小样本学习: 仅需几张带有模拟缺陷(通过数字合成)的图像,就能让模型学会识别真实缺陷。
域适应: 解决"仿真数据"与"真实数据"之间的Domain Gap,或者解决不同产线之间由于光照、传感器差异导致的模型失效问题。
工业界做法通常是基于成熟的框架异常缺陷检测框架Anomalib即可完成
金句: 进阶此境,方知缺陷检测的本质不是"识别缺陷",而是"理解正常"。通过无监督与自监督学习,模型开始具备"常识",不再被表象迷惑。
第三重 多模态零样本质检智能体
核心目标:
解决"知其然并知其所以然",实现零漏检、极低误检,并反哺生产工艺。
技术栈:
多模态融合(2D+3D+光谱)、大视觉模型(LVM)、工艺知识库RAG + LLM + 智能体。
这是最难的境界,因为工业检测的最终目的不是"检测",而是"工艺控制"。单纯的数据驱动模型在此阶段会遇到瓶颈------它无法区分"结构性的纹理"和"致命的微裂纹",且无法解释为何产生缺陷。

大模型与语义理解:
利用视觉大模型(VLM)或多模态大模型,将检测从"分类"提升为"推理"。模型不仅能输出"划痕",还能输出"该划痕位于倒角边缘,深度0.1mm,属于工艺允许范围"或"该划痕贯穿功能区,必须报废"。甚至通过自然语言交互,动态调整检测标准。
端到端的闭环控制:
检测模型不再是产线的"质检员",而是"工艺师"。将检测结果(缺陷类型、位置、形态)实时反馈给前道的CNC(数控机床)或注塑机。当检测到某批次产品出现规律性划痕时,模型自动推断可能是刀具磨损或模具温度异常,并触发停机或参数修正。
金句:
大成之境,VLM+LLM构建缺陷检测专家智能体。此时已无"视觉"与"工艺"之分,算法从"事后拦截"升维至"事中控制"与"事前预防",真正实现了制造业的智能闭环。
总结
第一重模式识别过拟合、数据标注成本、光照敏感CNN, YOLO, U-Net, 迁移学习
第二重表征学习未知缺陷、正负样本失衡、跨域泛化异常检测 (PatchCore), DRAEM, 域自适应
第三重文本叠加图像,多模态数据输入,智能决策可解释,实时性与精度平衡,缺陷样本零收集、数据零标注,五分钟急速换型各种样品、任意切换领域数据,基于多模态(2D+3D)、VLM、LLM与工艺认知数据知识库,真正跟人类质检员一样做决策。
当前绝大多数工业落地项目停留在第一重跟第二重过阶段。很多企业误以为买几张GPU跑通YOLO就是"AI质检",结果在实际产线中因为过杀率(假阳性)过高而无法使用。
未来真正高价值的工业缺陷检测,必然从第一重跟第二重(监督学习与无监督学习)向终极目标第三重(零样本、零训练、对比学习)演进。