一、KenLM 简介
KenLM 是一个开源、高性能 N-Gram LM 库
支持:
1~5 Gram LM
字符级或词级 N-Gram
高速概率查询,适合大词表(中文大字表 V≈7000)
优势:
查询快(C++ 或 Python wrapper)
内存占用优化,支持二进制 LM 文件(.bin)
二、使用场景
1.CTC 手写识别
CRNN+CTC 输出概率矩阵 T, C
Beam Search 生成候选序列
用 KenLM 对候选序列打分
2.解码阶段
对每条候选序列:
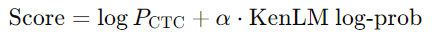
α 为权重,可调
三、KenLM LM 构建步骤
3.1 语料准备
文本语料最好和手写场景匹配(中文长文本或英文句子)
语料格式:
python
今天天气真好,我们去公园散步。
今天上午上课内容包括...3.2 构建 LM
python
# 安装 KenLM(Linux/macOS 示例)
git clone https://github.com/kpu/kenlm.git
cd kenlm
mkdir build && cd build
cmake ..
make -j
# 构建 trigram LM
# 假设语料文件:train_corpus.txt
# 输出二进制 LM
./lmplz -o 3 < train_corpus.txt > trigram.arpa
build/bin/build_binary trigram.arpa trigram.bin-o 3 → trigram
.arpa → 原始文本 LM
.bin → KenLM 二进制 LM,高速查询
四、Python 使用 KenLM
python
import kenlm
# 加载 LM
lm = kenlm.LanguageModel("trigram.bin")
# 计算序列 log 概率
seq = "今天的天气真好"
log_prob = lm.score(seq, bos=True, eos=True) # 包括句首/句尾概率
print(log_prob)五、CTC + Beam Search + KenLM 解码流程
1.CTC 模型输出
T, C logits → softmax → 概率矩阵
Beam Search
beam width = K(5~10)
2.每条候选序列记录累计 CTC log probability
KenLM 打分
3.对每条候选序列:
python
total_score = ctc_log_prob + alpha * lm.score(seq, bos=True, eos=True)4.选分数最高序列 → 最终识别结果
六、安装kenlm编译遇到问题:
python
/home/anaconda3/lib/libboost_program_options.so.1.82.0:对'std::__throw_bad_array_new_length()@GLIBCXX_3.4.29'未定义的引用1.问题原因:
a.你的系统可能是 GCC < 11,但 libboost_program_options.so.1.82.0 是用 GCC 11+ 编译的
b.Boost 库和系统 C++ 标准库 (libstdc++.so) ABI 不一致
c.典型表现:
KenLM CMake 默认使用系统 GCC
Anaconda 自带 Boost 或 libstdc++ 与系统不一致 → 链接失败
2.解决方案
使用系统自带 Boost 而不是 Anaconda 的
python
# 移除 Anaconda Boost 路径对编译器的影响
export LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH
export CPLUS_INCLUDE_PATH=/usr/include:$CPLUS_INCLUDE_PATH或者
python
cmake .. -DBOOST_ROOT=/usr -DBoost_NO_SYSTEM_PATHS=ON