写在前面:
在Dify Docker部署架构中,PostgreSQL作为核心依赖中间件,承担着整个系统所有结构化数据的存储职责------包括用户信息、应用配置、Prompt模板、知识库元数据、操作日志等关键内容,是Dify正常启动、稳定运行的基础支撑。
本教程适配特定部署环境:Windows系统通过Docker部署本地Dify,而PostgreSQL数据库部署在Linux服务器(非Docker容器化,为独立服务器部署)。
一、Dify Docker部署架构
Dify Docker 部署由5 个核心服务容器 + 6 个依赖组件容器 + 网络 / 存储 / 安全层组成,所有服务通过 Docker Compose 统一管理,默认使用内部网络通信,对外仅暴露 Nginx 端口Dify。
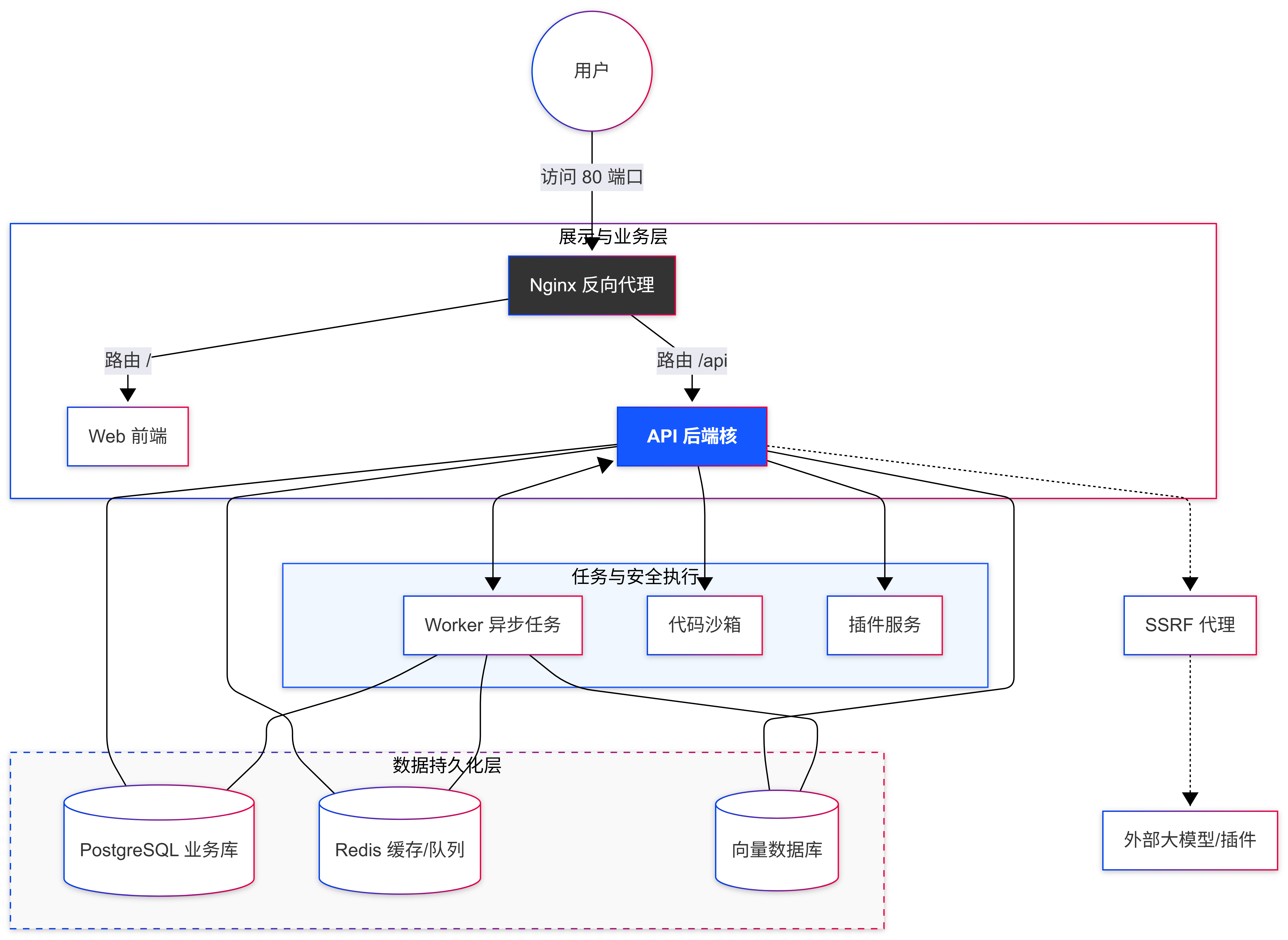
1、核心服务容器
(1)dify-web(前端)
-
镜像:langgenius/dify-web
-
技术栈:Next.js
-
端口:3000(内部)
-
职责:提供可视化管理控制台(应用编排、Prompt 编辑、知识库管理、插件配置),仅做页面渲染与 API 调用,无业务逻辑。
(2)dify-api(后端核心)
-
镜像:langgenius/dify-api
-
技术栈:Python/Flask/Gunicorn
-
端口:5001(内部)
-
职责:提供 RESTful API(应用 API、控制台 API、开放 API),处理认证授权、模型调用、文件管理、RAG 检索、应用运行时逻辑。
(3)dify-worker(异步任务)
-
镜像:同dify-api(langgenius/dify-api)
-
模式:MODE=worker
-
职责:基于 Celery 处理异步任务(文档解析、向量入库、LLM 批量调用、邮件发送、数据清理),与 API 共享数据库与配置。
(4)dify-worker-beat(定时任务)
-
镜像:同dify-api
-
模式:MODE=worker-beat
-
职责:Celery Beat 定时调度器,触发周期性任务(如知识库自动同步、日志清理)Dify。
(5)dify-plugin-daemon(插件守护进程)
-
镜像:langgenius/dify-plugin-daemon
-
端口:5002(内部)
-
职责:管理第三方插件生命周期(加载 / 卸载 / 运行),提供插件与核心服务的通信通道。
2、依赖容器组件
(1)PostgreSQL(主数据库)
-
端口:5432
-
用途:存储结构化数据(用户、应用、Prompt、插件配置、日志、元数据),数据持久化到docker/volumes/db/data。
(2)Redis(缓存 / 队列)
-
端口:6379
-
用途:会话缓存、Celery 任务队列、限流、分布式锁,数据持久化到docker/volumes/redis/data。
(3)Weaviate(向量数据库,默认)
-
端口:8080
-
用途:RAG 知识库向量存储与检索,支持替换为 Qdrant、Milvus、Pinecone 等。
(4)dify-sandbox(代码沙箱)
-
端口:8194
-
用途:安全执行用户自定义代码(如函数调用、数据处理),隔离网络与文件系统,防止恶意代码攻击。
(5)dify-ssrf-proxy(SSRF 防护)
-
端口:3128
-
用途:代理 API 服务的外部请求,过滤危险地址,防止 SSRF 攻击。
(6)dify-nginx(反向代理)
-
端口:80(对外)
-
职责:统一入口,路由请求:
-
/ → dify-web(前端)
-
/api、/console/api、/v1 → dify-api(后端)
-
二、环境准备
1、检查Docker环境
(1)在命令行(Win+R输入cmd)中输入指令,检查Docker是否运行,看到"Up"即为运行状态:
docker ps
(2)查看Dify容器,看到"Up"即为运行状态:
docker ps | grep dify
2、检查PostgreSQL(服务器端)
(1)检查是否已安装PostgreSQL,显示版本号即可:
psql --version
(2)检查PostgreSQL是否运行:
sudo systemctl status postgresql出现active (running)即表示正在运行,如果是Ubuntu上的PostgreSQL就会出现如图所示active (exited), 这个状态表示PostgreSQL服务本身没有真正运行,active(exited)表示systemd的占位符服务已退出,Main PID: 3530508 (code=exited) 表示主进程已退出,没有正在运行的PostgreSQL进程,因此该命令对于Ubuntu上的PostgreSQL不准确。
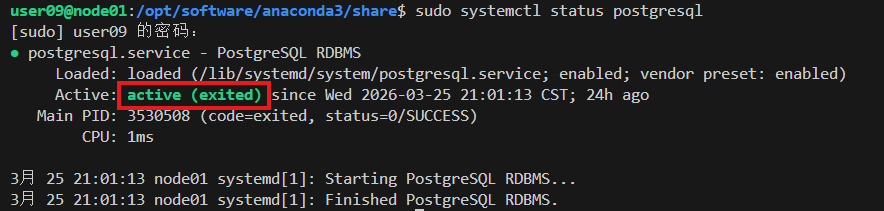
原因解释:
Ubuntu 的 PostgreSQL 包有两个服务单元:
- postgresql.service(占位符/元服务)
-
这是一个 wrapper 服务,只是用来触发集群启动
-
启动后立即退出,所以显示 active (exited)
-
它的作用是兼容旧版本和简化命令
- postgresql@15-main.service(实际服务)
-
这才是真正运行 PostgreSQL 的服务
-
状态会显示 active (running)
-
格式:postgresql@<版本>-<集群名>.service
不同Linux发行版的区别:
✅ 可以用sudo systemctl status postgresql的发行版
| 发行版 | 服务名 | 说明 |
|---|---|---|
| CentOS / RHEL / Fedora | postgresql.service | 单实例模式,直接管理 |
| openSUSE / SLES | postgresql.service | 单实例模式 |
| Arch Linux | postgresql.service | 单实例模式 |
| Debian (新版) | postgresql.service | 部分版本已改 |
❌ 不能用sudo systemctl status postgresql的发行版
| 发行版 | 服务名 | 说明 |
|---|---|---|
| Ubuntu | postgresql@<版本>-< 集群名 >.service | 多集群模式 |
| Debian (旧版) | postgresql@<版本>-< 集群名 >.service | 多集群模式 |
所以,Ubuntu下的PostgreSQL的检查指令应该是(PostgreSQL版本是15):
sudo systemctl status postgresql@15-main
(3)检查端口监听:
sudo ss -tlnp | grep 5432
0.0.0.0:5432表示监听所有IPv4 地址,即任何IP都能连接这个5432端口。
:::5432表示监听所有IPv6地址,即兼容IPv6连接(不影响使用)。
users:(("postgres",pid=3536569...))表示这个端口由PostgreSQL进程占用,服务完全正常,没有被其他程序占用。
三、配置外部PostgreSQL数据库
1、创建Dify的专用数据库和用户
(1)创建Dify专用用户,密码设置为dify123456:
sudo -u postgres psql -c "CREATE USER dify WITH PASSWORD 'dify123456';" 
(2)创建名为dify的数据库,指定OWNER dify → 避免权限不足:
sudo -u postgres psql -c "CREATE DATABASE dify OWNER dify;" 
(3)授予权限:
sudo -u postgres psql -c "GRANT ALL PRIVILEGES ON DATABASE dify TO dify;" 
(4)切换到dify数据并授予schema权限:
sudo -u postgres psql -d dify -c "GRANT ALL ON SCHEMA public TO dify;" 
2、确认pg_hba.conf允许Dify容器访问
(1)pg_hba.conf是PostgreSQL客户端认证规则文件,控制哪些IP / 主机可以连接PostgreSQL,以及用什么密码方式登录。查看当前pg_hba.conf配置:
sudo tail -10 /etc/postgresql/15/main/pg_hba.conf规则格式固定:host 允许的库 允许的用户 允许的IP/网段 认证方式
图中host all all 172.27.0.0/16 scram-sha-256表示我们已经开放了一整段Docker可能用到的内网网段,不管Docker用 172.17、172.18、172.27......Docker容器全部都能连接PostgreSQL。
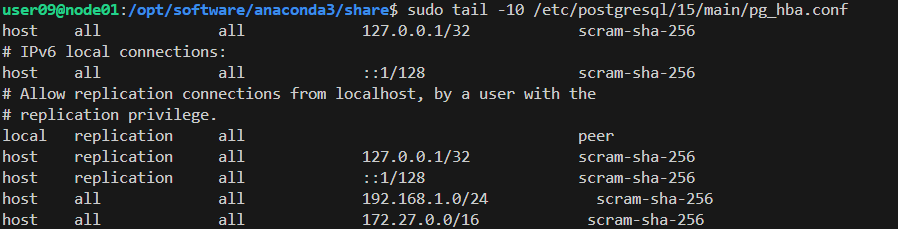
如果需要,添加允许Docker网段访问的规则,Docker默认网段通常是172.17.0.0/16:
echo "host all all 172.17.0.0/16 scram-sha-256" | sudo tee -a /etc/postgresql/15/main/pg_hba.conf(2)重载PostgreSQL配置,输出 t 则表示配置重载成功,刚刚加入的Docker网段权限已经生效:
sudo -u postgres psql -c "SELECT pg_reload_conf();"
(3)验证配置:
sudo tail -5 /etc/postgresql/15/main/pg_hba.conf
3、测试从Docker容器连接
从任意Docker容器测试连接(172.27.XX.XX替换为你的服务器IP,PGPASSWORD=你设置的密码):
E:\Dify\dify-main\docker>docker run --rm -e PGPASSWORD=dify123456 postgres:15 psql -h 172.27.XX.XX -U dify -d dify -c "SELECT 1;"
四、在Dify中配置数据库连接
1、修改Dify数据库配置
找到Dify的docker-compose.yaml或.env 文件,一般在安装位置的\dify-main\docker文件夹里。
命令行进入这个目录E:\Dify\dify-main\docker,备份配置:
copy .env .env.bak
编辑.env文件,输入以下指令打开文件:
notepad .env找到这一部分:
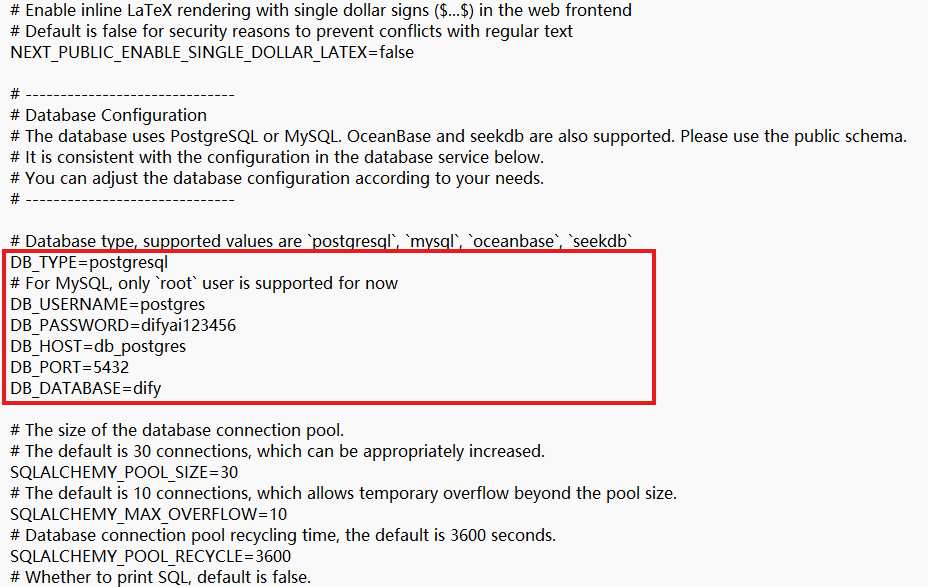
把他改成以下内容,修改DB_USERNAME、DB_PASSWORD、DB_HOST:
DB_TYPE=postgresql
DB_USERNAME=dify
DB_PASSWORD=dify123456
DB_HOST=172.27.XX.XX
DB_PORT=5432
DB_DATABASE=dify-
DB_USERNAME从postgres→ 改成dify(你之前设置的数据库用户名)
-
DB_PASSWORD从默认密码 → 改成你设置的安全密码dify123456
-
**DB_HOST(最重要)**从db_postgres(内部容器)→ 改成你的PostgreSQL的真实IP:172.27.XX.XX
修改后保存并关闭记事本。
2、重启Dify容器
还是在这个E:\Dify\dify-main\docker目录下,停止容器:
docker compose down
重新启动:
docker compose up -d
实时查看日志:
docker compose logs -f api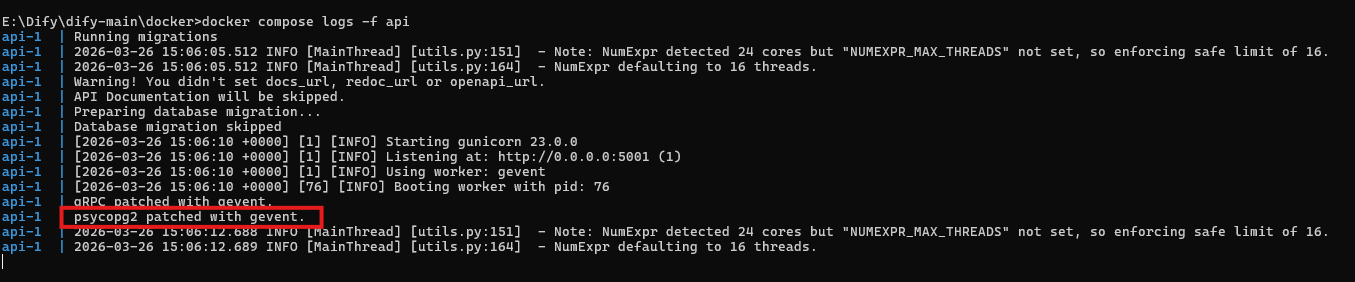
api-1 | psycopg2 patched with gevent.是PostgreSQL 连接驱动加载成功的标志,Ctrl+C退出日志。
3、验证数据库连接
首先输入以下指令查看一下容器的名字:
docker ps
如图所示容器的名字是:docker-api-1
查看连接日志,填入的是容器名字docker-api-1:
docker logs docker-api-1 2>&1 | findstr -i "database connected error"
Preparing database migration...表示Dify正在尝试连接数据库,并准备检查/更新表结构。如果连不上数据库,这里直接报错:connection failed。
Database migration skipped表示数据库表结构已是最新,无需更新,连接正常!
五、配置向量数据库
Dify支持多种向量数据库,这里介绍常用的pgvector(使用PostgreSQL扩展)。
1、在PostgreSQL上安装pgvector扩展
(1)首先检查一下dify数据库是否已经安装了pgvector扩展:
sudo -u postgres psql -d dify -c "SELECT * FROM pg_extension WHERE extname = 'vector';" 如果显示(0行数据)那就是没有安装,因为PostgreSQL的扩展机制是:每个数据库独立安装、独立存在、互不共享的,如果我们在postgres库(默认库)安装了pgvector,但是新建的dify数据库中还是没有的,需要重新安装,每个数据库需要按需单独实行安装命令。
(2)安装编译依赖:
sudo apt update
sudo apt install -y postgresql-server-dev-15 build-essential git
(3)下载并编译pgvector:
cd /tmp
git clone https://github.com/pgvector/pgvector.git
cd pgvector
make
sudo make install(4)在dify数据库中启用扩展:
sudo -u postgres psql -d dify -c "CREATE EXTENSION IF NOT EXISTS vector;"
(5)验证安装:
sudo -u postgres psql -d dify -c "\dx" 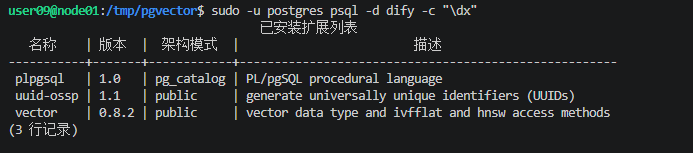
显示存在vector表示安装成功。
2、修改Dify向量数据库配置
(1)编辑.env文件:
还是在E:\Dify\dify-main\docker目录下,打开.env文件找到pgvector设置:
notepad .env
改成以下内容,修改PGVECTOR_HOST、PGVECTOR_USER、PGVECTOR_PASSWORD,改成你的IP地址和数据库名称密码:
PGVECTOR_HOST=172.27.XX.XX
PGVECTOR_PORT=5432
PGVECTOR_USER=dify
PGVECTOR_PASSWORD=dify123456
PGVECTOR_DATABASE=dify保存后关闭记事本。
3、重启Dify
还是在这个E:\Dify\dify-main\docker目录下,停止容器再重新启动:
docker compose down
docker compose up -d检查日志是否正常运行:
docker logs -f docker-api-1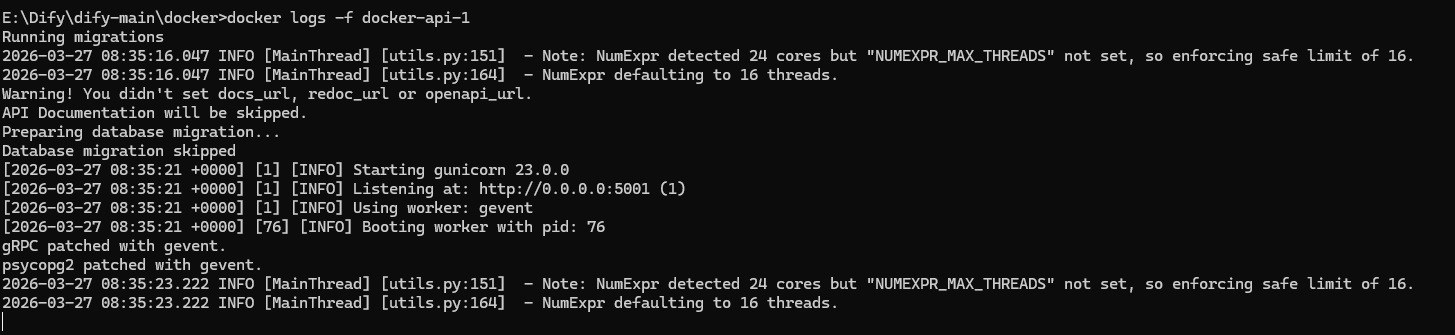
没有报错则配置成功。
六、创建知识库并测试
1、在Dify上创建知识库
打开浏览器访问:http://localhost:8080
选择知识库→创建知识库,上传文件作为知识库内容。
2、pgAdmin连接服务器的PostgreSQL数据库
右键Servers,选择Register→Server,填写名称为test,在"Connection"里面填写服务器IP名称,数据库名称和数据库用户。

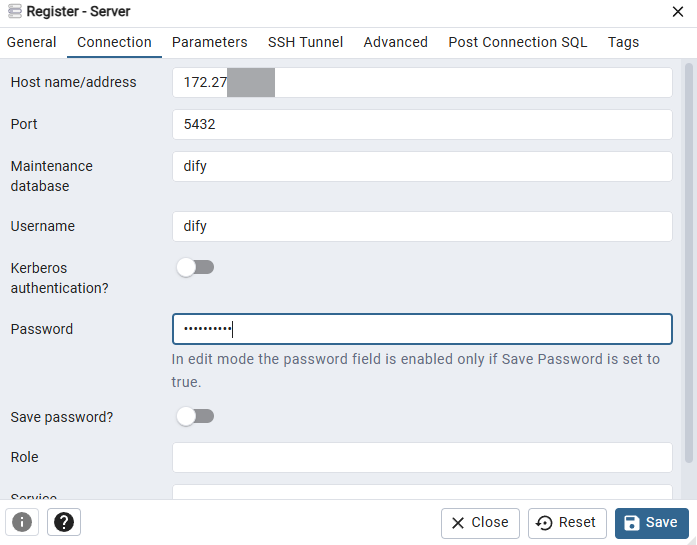
| 字段 | 填写内容 | 说明 |
|---|---|---|
| Host name/address | 172.27.XX.XX | 你的 PostgreSQL 服务器 IP |
| Port | 5432 | PostgreSQL 默认端口(如修改过按实际填写) |
| Maintenance database | dify | 主数据库 |
| Username | dify | 数据库用户 |
| Password | dify123456 | 你在 .env 中配置的 DB_PASSWORD |
| SSL mode | prefer 或 disable | 内网通常用 disable |
连接后打开dify→Schemas→Tables,找到存储知识库的数据表。
数据流转说明:
- 文件元数据 → documents 表
└── 文件名、类型、状态、总字数
- 文件被切分成片段 → document_segments 表
└── 每个片段的实际文本内容 (content 字段)
- 每个片段生成向量 → embeddings 表
└── 向量的哈希值、二进制向量数据
- 知识库配置 → datasets 表
└── 知识库名称、描述、检索配置
欢迎交流!🌹🌹