在企业数字化建设持续深入的今天,消息系统早已不只是基础组件,而是支撑日志采集、业务解耦、流式处理、实时分析等核心场景的重要底座。
随着业务规模不断扩大,传统 Kafka 架构在扩展效率、资源利用率以及消费积压场景下的稳定性方面,逐渐暴露出挑战。围绕这些问题,360 智汇云中间件团队基于AutoMQ,完成了 Kafka 消息服务的云原生架构演进。
这篇文章将结合 360 智汇云的实际落地经验,分享我们在 Kafka 云原生演进中的思考、选型与实践。
一、为什么传统 Kafka 架构越来越"吃力"?
Kafka 一直是业界最主流的消息中间件之一,生态成熟、协议稳定、应用广泛。但在超大规模场景下,传统 Kafka 架构的一些天然限制也会越来越明显。
1. 扩展性差,扩容周期长
当 Kafka 集群接近容量上限时,扩容往往不是"加几台机器"这么简单,而是一个跨团队、跨流程的系统工程:
容量评估、预算申请、资源协调、节点部署、副本迁移、运行观察,每一个环节都需要时间。现实中,一个完整扩容周期通常以"周"为单位。
问题的根源在于,传统 Kafka 是典型的有状态架构。Broker 本地磁盘存储了大量 Partition 数据,新增节点后必须进行跨网络数据迁移,才能实现负载均衡。数据规模越大,迁移耗时越长,少则数小时,多则数天。与此同时,迁移期间还可能引发性能抖动。
为了保障高峰期容量,很多集群还不得不长期预留较大冗余,这也进一步拉低了资源利用率。
2. 冷读拖垮集群写入
除了扩展性,另一个更容易在生产环境中放大的问题,是冷读对写入的影响。
以日志、埋点、实时处理等典型场景为例,业务经常会出现新增订阅、历史回溯、消费者故障恢复等情况。这类场景会触发大量历史数据读取,也就是常说的"追赶读"或"冷读"。
在传统 Kafka 架构下,冷读往往会带来两个连锁反应:
首先是 PageCache 污染。冷数据进入 PageCache 后,会挤占热点数据原本占用的内存空间,导致原本可以直接命中内存的实时消费,也开始频繁触发磁盘 I/O。
其次是网络线程阻塞。Kafka 的零拷贝机制依赖 sendfile 系统调用,在冷数据读取场景下,这一调用可能长时间阻塞网络线程。而 Kafka 的读写路径又共享同一套线程资源,于是冷读压力会进一步传导到写入侧,影响整个集群中其他 Topic 的生产性能。
这是 Kafka 已知的架构缺陷(KAFKA-7504),至今未被根本解决。很多团队都遇到过类似现象:高峰期消费积压增加,随后写入 P99 延迟飙升,甚至影响到无关业务。
对于企业来说,这不仅是架构问题,更是业务体验问题。
二、AutoMQ 的技术选型与架构优势
面对这些挑战,我们希望找到一种既能保持 Kafka 生态兼容性 ,又能真正发挥云原生弹性能力的新架构。
在调研过程中,基于对象存储的 Diskless Kafka 架构进入了我们的视野。AutoMQ 的核心特点,包括存算分离、读写路径隔离、分钟级扩缩容等,正好对应了传统 Kafka 在大规模场景下最突出的几个痛点。
更重要的是,360 智汇云本身已经具备较完善的云原生基础设施能力。
例如,PoleFS 是 360 自研的云原生分布式存储系统,兼容 POSIX 协议,支持 Kubernetes CSI 标准,可在容器环境中为有状态应用提供完整的 PVC 持久卷管理能力。与此同时,智汇云也具备标准 S3 对象存储服务。这意味着,从基础设施角度看,我们已经具备了支撑 AutoMQ 落地的关键条件。
1. 100% 兼容 Kafka 协议,客户端零改造
对于企业客户来说,替换消息系统最大的顾虑之一,往往不是性能,而是改造成本。
AutoMQ 基于 Apache Kafka 源码演进,在保留 Kafka 计算层与协议层的同时,对底层存储架构进行了云原生重构。这意味着:
各业务部门现有的所有客户端代码、自研 SDK、消费者组配置等无需任何改动。
从客户视角看,这种替换几乎是"无感"的;从平台视角看,则能在不牺牲生态兼容性的前提下,获得更强的弹性与更好的资源效率。
2. 按需扩容,理论吞吐无上限
AutoMQ 的核心架构变化是存算分离------数据持久化在对象存储中,Broker 变为无状态节点。
| 对比项 | Apache Kafka | AutoMQ |
|---|---|---|
| Broker 状态 | 有状态,数据在本地磁盘 | 无状态,数据在对象存储 |
| 扩缩容 | 数小时 ~ 数天(需迁移数据) | 分钟级(仅迁移元数据) |
| Partition 迁移 | 跨网络复制数据 | 秒级完成 |
| 负载均衡 | 手动 reassign | 内置自动重平衡 |
| 资源利用率 | 长期预留冗余 | 按需伸缩 |
对业务的直接影响:扩容不再需要跨部门沟通协调、等待机器到位和数据迁移,集群可以根据负载自动伸缩。
3. 冷热隔离,冷读不再影响写入
AutoMQ 在架构层面将数据路径拆分为三条独立通道:
| 路径 | 机制 | 说明 |
|---|---|---|
| 写入 | Direct IO 绕过 PageCache | 冷读无法干扰写入 |
| 实时消费(热读) | WAL + 内存缓存 | 低延迟,毫秒级 |
| 追赶读(冷读) | 对象存储 + Prefetch | 独立通道,不与写入争抢资源 |
这种设计的价值非常直接:即使下游消费者出现大规模积压、需要快速回补历史消息,生产写入仍然可以保持稳定,不会再出现"消费追赶把写入拖慢"的情况。
三、性能测试
**1.**基准性能测试
在 8 节点 Broker 集群上,使用业界标准的 OpenMessaging Benchmark 框架,分别以 100 MiB/s 和 500 MiB/s 两个负载级别进行压测(acks=all,确保数据持久化后再返回成功):
发送延迟(ms)
| 百分位 | 100 MiB/s | 500 MiB/s |
|---|---|---|
| Avg | 1.28 | 1.51 |
| P50 | 0.99 | 0.84 |
| P95 | 1.55 | 2.83 |
| P99 | 11.98 | 19.13 |
端到端延迟(ms)
| 百分位 | 100 MiB/s | 500 MiB/s |
|---|---|---|
| Avg | 2.2 | 22.55 |
| P50 | 2.0 | 19.0 |
| P95 | 3.0 | 46.0 |
| P99 | 14.0 | 65.0 |
2. 追赶读隔离测试
我们在 2 节点 Broker 集群中,以 100 MiB/s 吞吐持续发送数据。在累计发送 100 GiB 数据后,待积压规模超过内存缓存,再启动消费者从最早位点开始消费。
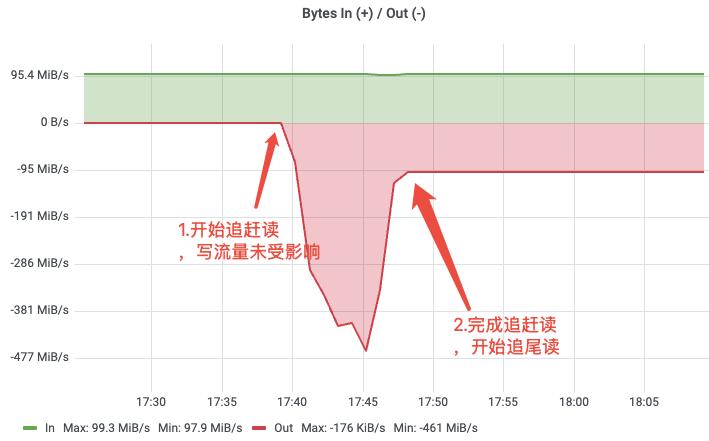
测试结果显示:
在追赶读发生过程中,生产侧吞吐与延迟基本保持稳定,没有出现明显抖动;与此同时,追赶读峰值速率达到约 461 MiB/s,能够较快完成积压消化。
这说明 AutoMQ 的读写隔离设计在实际场景中是有效的。
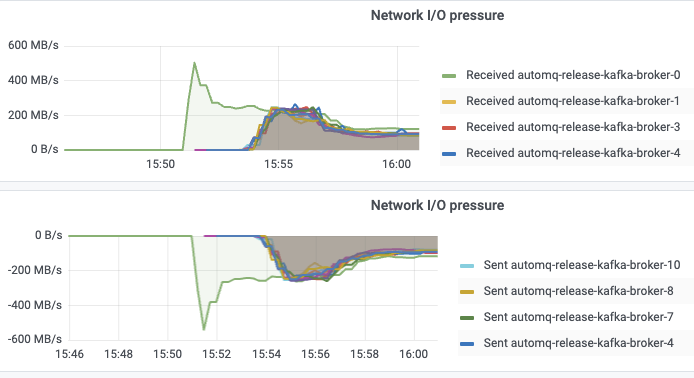
3. 弹性扩容测试
我们还验证了 AutoMQ 的应急弹性能力。具体的测试场景为:集群初始只有 1 个 Broker,启动 OpenMessaging 直接将发送流量设置为 1 GiB/s,此时应急扩容到 16 个 Broker,观察从扩容到新 Broker 到自动承载流量的耗时。测试结果表明,从应急扩容,到节点自动承担流量,大约耗时4分钟:
|--------------------|------|----------|--------------------|--------|
| 分析项 | 监控告警 | 批量扩容 | Auto Balancing | 总计 |
| 0 -> 1 GiB/s 弹性耗时 | 60s | 60s | 120s | 4 min |
四、落地案例
1. 生产部署架构
每个 AutoMQ 集群配备一个 HA 备用集群,定时同步集群元数据。生产集群通过实时写检测持续监控健康状态,一旦检测到异常,自动将集群 DNS 解析切换到备用集群,同时修改 Endpoint 服务返回的集群地址。备用集群无需预先承载数据,只需在切换时快速扩容即可。
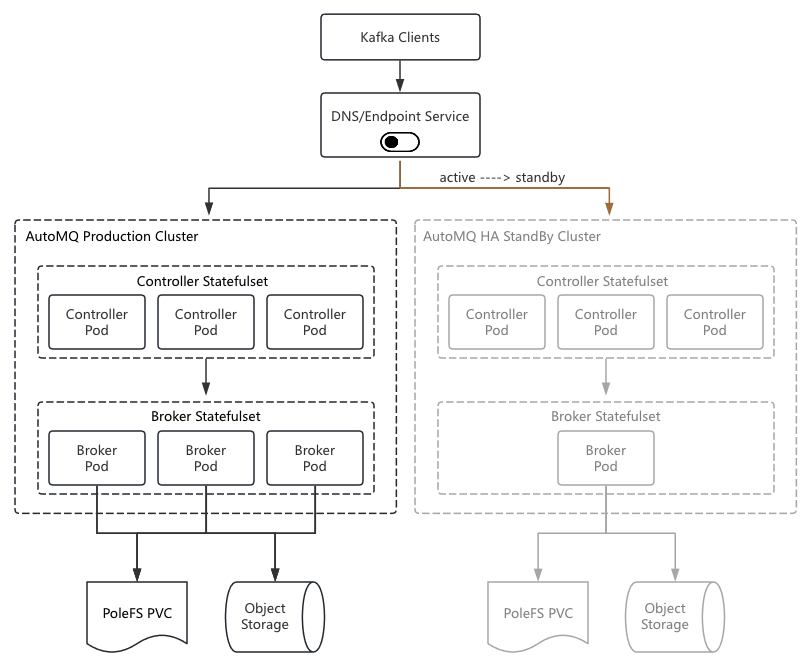
PoleFS 在容器环境中为有状态应用提供完整的 PVC 持久卷管理能力,具备多副本高可靠的特性,用于存储日志及 Controller 的 Checkpoint 元数据。
客户端有域名访问和 Endpoint 服务两种方式支持服务端的 HA 故障切换。
域名访问
客户端通过域名访问集群,并在客户端配置 metadata.recovery.strategy=rebootstrap(Kafka KIP-899),当原集群故障后,客户端自动重新初始化连接地址完成集群切换。
Endpoint 访问
在域名访问的方式下,由于 DNS 缓存,存在分钟级别的故障恢复时间。客户端可以订阅 Endpoint 服务,定时请求或监听集群连接地址,当客户端监测到 Endpoint 服务返回的集群地址发生变更后,主动触发 Client 端重启。
2. 日志检索平台改造
**业务场景:**线上服务的统一日志检索平台,所有服务的运行日志通过 Kafka 收集,统一写入 Elasticsearch,业务基于 ES 做日志检索。
**业务痛点:**在业务高峰期时,消息积压达到 10 亿条、约 200 GB,集群写入 P99 飙升到约 10 秒,日志检索的及时性无法保障。
Kafka 常被用于削峰填谷,消息堆积本身是正常现象,关键在于消费者能否快速消化这些积压数据。Apache Kafka 的传统架构下,冷读会触发 Broker 磁盘 I/O,显著拖慢消费速率。
改造后带来的收益主要体现在两个方面。
第一是成本收益。
在业务高峰期,仅使用 30 个 4C 16GB Pod,就承载住了峰值 1.4 GB/s 的业务流量。综合统计后,硬件资源成本相比传统 Kafka 方案降低约 50%。
第二是性能收益。
切换前,业务高峰期峰值积压约为 10 亿条 消息、约 200 GB,生产 P99 延迟约 10s;切换后,峰值积压下降约 40 倍,降至约 5 GB,生产 P99 延迟下降至约 500ms。
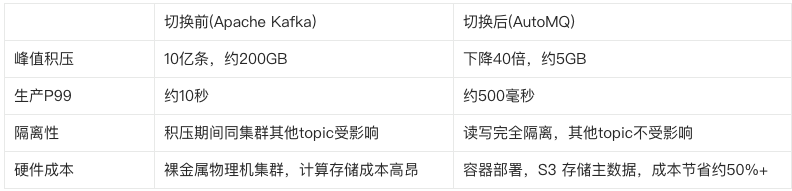
从吞吐监控可以看到,切换后的日志检索集群在业务高峰期峰值吞吐达到 1.4 GB/s,写入曲线平滑无毛刺。
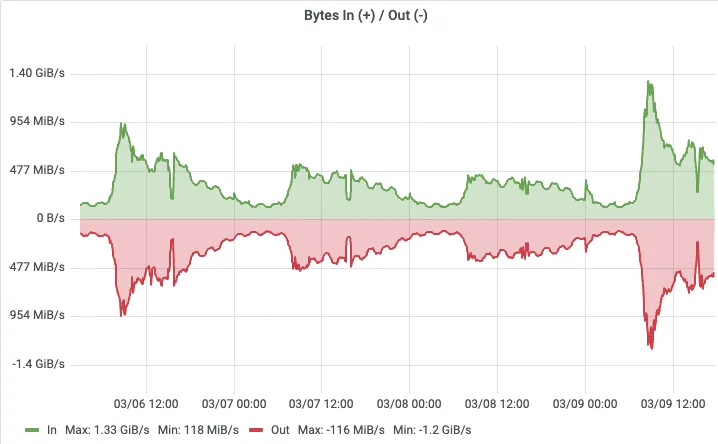
切换后的日志检索集群吞吐监控
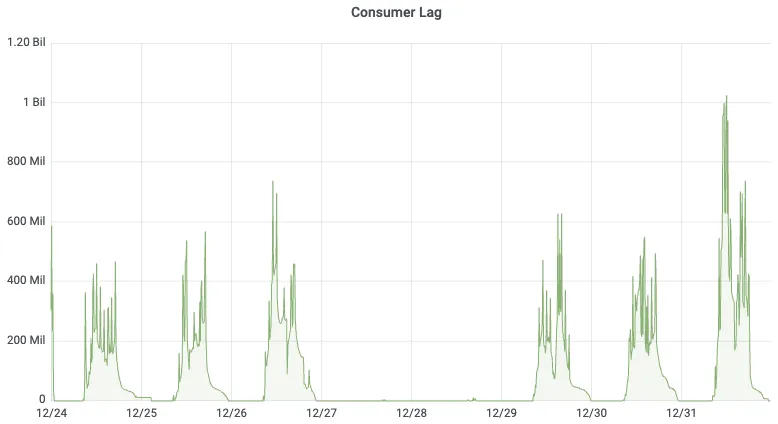
切换 AutoMQ 前的 Consumer Lag
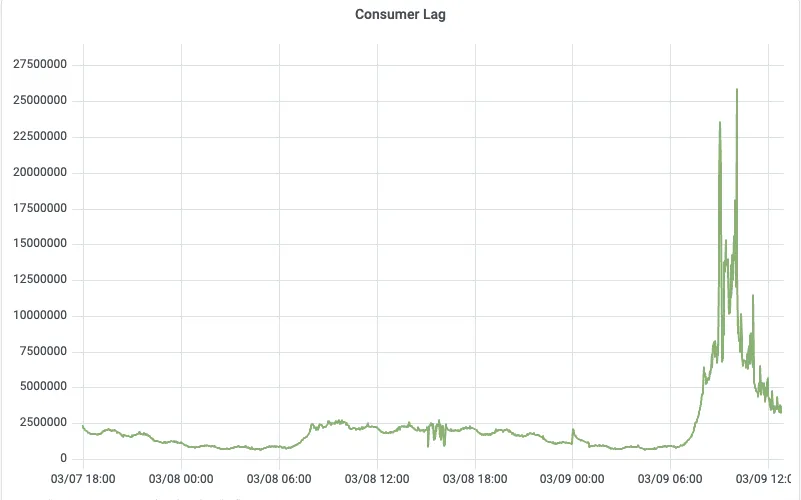
切换 AutoMQ 后的 Consumer Lag (积压下降 40 倍)
五、写在最后
从传统裸金属 Kafka 到云原生消息架构,这不仅是一次技术栈升级,更是消息服务能力的一次整体跃迁。
对技术团队来说,AutoMQ 带来了更高的弹性、更稳定的读写隔离能力,以及更轻量的运维模式。对企业客户来说,则意味着更低的接入门槛、更强的峰值承载能力,以及更具竞争力的资源成本。
360 智汇云已经在生产环境中验证了这一路线的可行性。未来,我们也将持续推动 AutoMQ 在更多业务场景中的落地,进一步释放云原生 Kafka 架构的价值,为企业提供更高性能、更高稳定性、更高性价比的消息服务能力。