好,第八章深入拆解 Structured Streaming,从设计哲学开始,逐层剖析。
- 先看第一张:流处理核心模型。核心模型清楚了。
- 接下来看微批次的执行引擎内部------每次触发时 Spark 到底做了什么:微批次执行机制和容错原理搞清楚了。
- 接下来是最难理解的部分------Watermark 事件时间处理:Watermark 和时间窗口搞透了。
- 接下来看 State Store 的工作机制和 Streaming 完整的读写体系:四张图把第八章完整覆盖。
下面是核心知识梳理:
核心模型(第一张) 是 Structured Streaming 最革命性的设计思想:把流抽象成一张不断追加行的无界表 。这意味着你写的代码和批处理完全一样------df.filter(...).groupBy(...).agg(...) 这套 API,批处理里能用,流处理里也能用,引擎自动把它转成增量计算。三种 Output Mode 控制每次触发后输出什么:Append 只追加新行(适合无状态或带 Watermark 的聚合),Complete 每次输出全量(全局聚合时用),Update 只输出变更行(最节省网络)。四种触发器则控制多久处理一次:ProcessingTime 固定间隔最常用,AvailableNow 用于一次性批量处理历史数据,Continuous 和 Real-Time Mode 则是追求毫秒级延迟的选项。

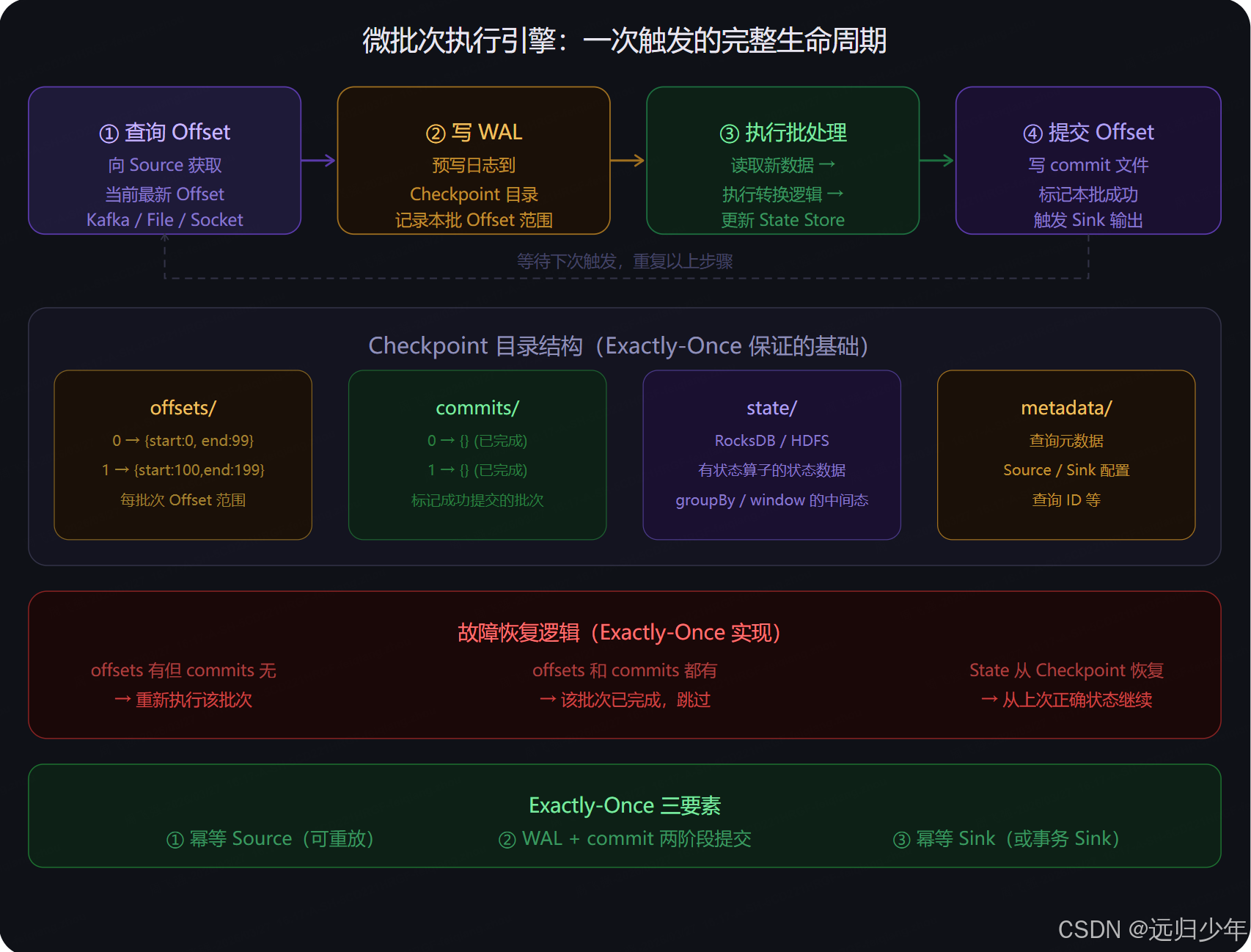
微批次执行周期(第二张) 是 Exactly-Once 的实现基础。每次触发分四步:查询 Source 最新 Offset → 写 WAL 日志(预先记录本批 Offset 范围)→ 执行批处理(读新数据、转换、更新 State Store)→ 写 commit 文件(确认本批完成)。Checkpoint 目录是整个容错机制的核心,offsets/ 记录每批的 Offset 范围,commits/ 记录哪些批次已完成,state/ 存储有状态算子的中间数据。恢复时的逻辑很直接:有 offset 没有 commit 说明上次失败了,重跑这批;两者都有说明已完成,跳过。
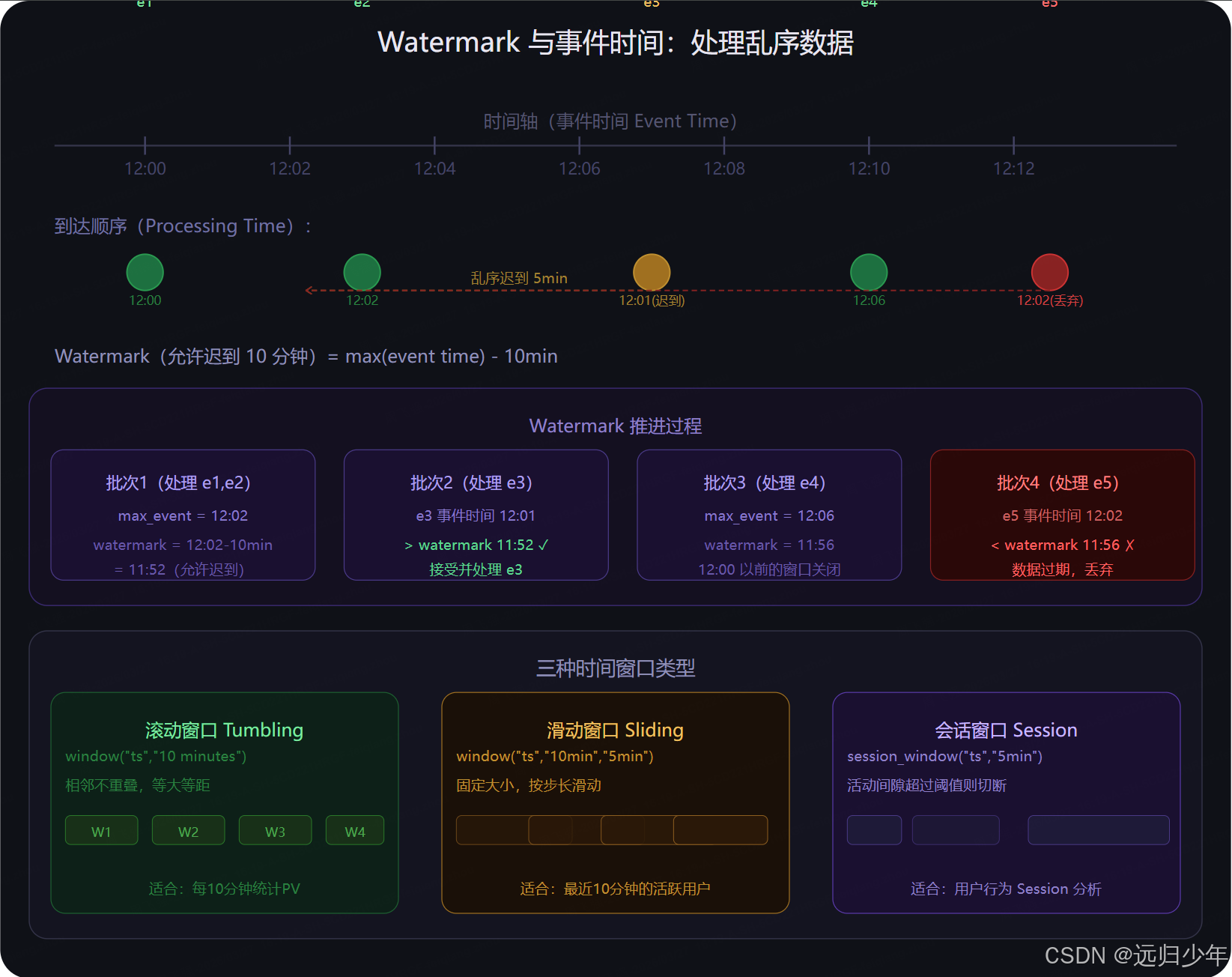
Watermark 与事件时间(第三张) 解决的是现实流处理的核心难题:网络延迟导致数据乱序到达。withWatermark("timestamp", "10 minutes") 告诉 Spark 允许最多 10 分钟的乱序延迟------Watermark 等于当前最大事件时间减去容忍值。事件时间落在 Watermark 之后的数据正常处理,落在 Watermark 之前的数据被直接丢弃。三种窗口类型的选择很清晰:滚动窗口用于每N分钟统计一次,滑动窗口用于"最近N分钟"类的实时指标,会话窗口用于用户行为分析(按活动间隙切割 Session)。
State Store 和读写体系(第四张) 是生产部署的关键。State Store 是有状态计算的存储引擎,默认的 HDFSBackedStateStore 状态存内存,适合中小状态;生产环境强烈推荐换成 RocksDBStateStore(Spark 3.2+),状态存本地磁盘,完全绕过 JVM GC,支持 TB 级超大状态,增量 Checkpoint 速度也更快。Source 端 Kafka 是生产首选,支持 Offset 回放保证 Exactly-Once;Sink 端推荐 Delta Lake,事务写入天然支持 Exactly-Once,其次是 File Sink。自定义 Sink 用 foreachBatch(推荐,批量写效率高)或 foreach(逐行,灵活但慢)。

最后附一段完整的生产级代码示例:
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import window, count, col, from_json
from pyspark.sql.types import StructType, StringType, TimestampType
spark = SparkSession.builder \
.config("spark.sql.streaming.stateStore.providerClass",
"org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider") \
.getOrCreate()
schema = StructType() \
.add("user_id", StringType()) \
.add("city", StringType()) \
.add("event_time", TimestampType())
# 读取 Kafka
df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "broker:9092") \
.option("subscribe", "orders") \
.option("startingOffsets", "latest") \
.load() \
.select(from_json(col("value").cast("string"), schema).alias("d")) \
.select("d.*")
# 带 Watermark 的滑动窗口聚合
result = df \
.withWatermark("event_time", "10 minutes") \
.groupBy(window("event_time", "10 minutes", "5 minutes"), "city") \
.agg(count("*").alias("order_count"))
# 写入 Delta Lake(Exactly-Once)
query = result.writeStream \
.format("delta") \
.option("checkpointLocation", "s3://bucket/checkpoints/orders/") \
.outputMode("append") \
.trigger(processingTime="1 minute") \
.start("s3://bucket/delta/order_stats/")
query.awaitTermination()