一、整体架构概览
Dify 是一个强大的 LLM 应用开发平台,采用了模块化、分层的架构设计。我们可以将其类比为一家高级餐厅,以便更直观地理解其架构组成:
| 架构组件 | 餐厅类比 | 主要职责 |
|---|---|---|
| Web 前端 | 前厅 | 美观的用户界面,提供友好的操作体验 |
| API 后端 | 后厨 | 核心业务逻辑处理 |
| Worker | 配菜间 | 处理异步耗时任务 |
| 数据库 | 食材仓库 | 存储数据和配置 |
| Celery | 调度员 | 协调各部门工作流程 |
| Redis | 传菜员 | 快速传递消息和缓存数据 |
核心设计特征
1. 前后端完全分离
- 前端:纯 React 应用,专注用户体验
- 后端:RESTful API 服务,提供业务逻辑
- 优势:独立开发、测试和部署,提高开发效率
2. 领域驱动设计(DDD)架构
api/
├── core/ # 核心业务逻辑(领域层)
│ ├── workflow/ # 工作流引擎
│ ├── rag/ # RAG 检索增强
│ ├── agent/ # Agent 智能代理
│ └── app/ # 应用核心
├── controllers/ # 接口控制层
├── models/ # 数据模型层
├── services/ # 应用服务层
└── extensions/ # 基础设施扩展这种设计就像是建筑中的承重墙和装修分离:
-
core 是承重墙(核心业务逻辑)
-
controllers 是对外的门窗(API 接口)
-
services 是协调各个房间的管家
-
models 是房屋的结构图纸
3. 微服务架构风格 Dify 虽然不是完全的微服务架构,但采用了类似的设计理念:
二、技术栈详解
后端技术栈
| 技术 | 版本 | 用途 |
|---|---|---|
| Flask | 3.1.2 | 轻量级 Web 框架,灵活可扩展 |
| Python | 3.11-3.12 | 利用最新的性能优化和类型提示 |
| SQLAlchemy | 2.0.29 | 强大的 ORM,支持复杂查询 |
| Celery | 5.5.2 | 分布式任务队列,处理异步作业 |
| Pydantic | 2.11.4 | 数据验证和设置管理 |
| PostgreSQL | 15 | 主数据库,存储业务数据 |
| Redis | 6 | 缓存和消息队列 |
| Weaviate/Qdrant/Milvus | - | 向量数据库,支持语义搜索 |
前端技术栈
| 技术 | 版本 | 用途 |
|---|---|---|
| Next.js | 15.5.4 | React 全栈框架,支持 SSR 和 SSG |
| React | 19.1.1 | 最新的 React,带来更好的性能 |
| TypeScript | 5.8.3 | 类型安全,提升代码质量 |
| TailwindCSS | 3.4.14 | 实用优先的 CSS 框架 |
| ReactFlow | 11.11.3 | 构建工作流可视化编辑器 |
| Zustand | 4.5.2 | 轻量级状态管理 |
| React Query | 5.60.5 | 强大的数据获取和缓存 |
三、核心组件详解
1. 工作流引擎 (Workflow)
工作流引擎是 Dify 的核心组件之一,它允许用户通过可视化界面创建复杂的 AI 应用逻辑。
主要功能:
-
拖拽式可视化编辑器
-
支持条件分支、循环等复杂逻辑
-
集成各种 AI 模型和工具
-
实时预览和测试
示例:创建一个客户支持机器人的工作流
python
# 工作流定义示例
workflow = {
"nodes": [
{
"id": "start",
"type": "start",
"data": {"label": "开始"},
"position": {"x": 100, "y": 100}
},
{
"id": "llm",
"type": "llm",
"data": {
"model": "gpt-3.5-turbo",
"prompt": "你是一个客户支持机器人,请友好地回答用户问题"
},
"position": {"x": 300, "y": 100}
},
{
"id": "end",
"type": "end",
"data": {"label": "结束"},
"position": {"x": 500, "y": 100}
}
],
"edges": [
{"id": "e1-2", "source": "start", "target": "llm"},
{"id": "e2-3", "source": "llm", "target": "end"}
]
}2. RAG 检索增强
RAG (Retrieval-Augmented Generation) 是 Dify 的另一个核心功能,它将检索和生成相结合,提高 AI 模型的回答质量。
主要组件:
-
文档处理管道
-
向量索引和检索
-
上下文构建
-
提示词工程
工作流程:
-
用户提问
-
系统检索相关文档
-
将文档和问题一起发送给 LLM
-
LLM 基于检索到的信息生成回答
示例:
python
# RAG 处理流程
def rag_pipeline(question, documents):
# 1. 向量化问题
question_embedding = embedder.embed(question)
# 2. 检索相关文档
relevant_docs = vector_db.search(question_embedding, top_k=5)
# 3. 构建上下文
context = "\n".join([doc.content for doc in relevant_docs])
# 4. 构建提示词
prompt = f"""
基于以下上下文回答问题:
{context}
问题:{question}
"""
# 5. 调用 LLM
answer = llm.generate(prompt)
return answer3. Agent 智能代理
Agent 是 Dify 中具有自主决策能力的组件,它可以根据任务需求选择合适的工具和步骤。
核心功能:
-
工具使用和管理
-
任务规划和执行
-
记忆和学习
-
多轮对话管理
示例:
python
# Agent 执行流程
class Agent:
def __init__(self, tools):
self.tools = tools
self.memory = []
def run(self, task):
# 1. 分析任务
plan = self.plan_task(task)
# 2. 执行计划
result = self.execute_plan(plan)
# 3. 存储记忆
self.memory.append({"task": task, "result": result})
return result
def plan_task(self, task):
# 基于任务和工具能力生成执行计划
pass
def execute_plan(self, plan):
# 执行计划并返回结果
pass4. 应用核心 (App)
应用核心是 Dify 中管理应用生命周期的组件,包括应用的创建、部署、监控等。
主要功能:
-
应用配置管理
-
版本控制
-
部署和发布
-
性能监控
-
用户权限管理
四、数据表结构
Dify 使用 PostgreSQL 作为主数据库,存储各种业务数据。以下是主要的数据表结构:
1. 应用表 (apps)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| id | UUID | 应用唯一标识 |
| name | VARCHAR | 应用名称 |
| description | TEXT | 应用描述 |
| type | VARCHAR | 应用类型 (chatbot, workflow, etc.) |
| status | VARCHAR | 应用状态 (draft, published) |
| created_at | TIMESTAMP | 创建时间 |
| updated_at | TIMESTAMP | 更新时间 |
2. 工作流表 (workflows)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| id | UUID | 工作流唯一标识 |
| app_id | UUID | 关联的应用 ID |
| name | VARCHAR | 工作流名称 |
| definition | JSONB | 工作流定义 (节点和边) |
| created_at | TIMESTAMP | 创建时间 |
| updated_at | TIMESTAMP | 更新时间 |
3. 模型配置表 (model_configs)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| id | UUID | 配置唯一标识 |
| name | VARCHAR | 配置名称 |
| provider | VARCHAR | 模型提供商 (openai, anthropic, etc.) |
| model | VARCHAR | 模型名称 |
| api_key | VARCHAR | API 密钥 (加密存储) |
| parameters | JSONB | 模型参数 |
| created_at | TIMESTAMP | 创建时间 |
| updated_at | TIMESTAMP | 更新时间 |
4. 对话表 (conversations)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| id | UUID | 对话唯一标识 |
| app_id | UUID | 关联的应用 ID |
| user_id | UUID | 用户 ID |
| status | VARCHAR | 对话状态 |
| created_at | TIMESTAMP | 创建时间 |
| updated_at | TIMESTAMP | 更新时间 |
5. 消息表 (messages)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| id | UUID | 消息唯一标识 |
| conversation_id | UUID | 关联的对话 ID |
| role | VARCHAR | 角色 (user, assistant) |
| content | TEXT | 消息内容 |
| created_at | TIMESTAMP | 创建时间 |
五、外部系统集成
Dify 集成了丰富的外部服务,使其功能更加完善:
1. AI 模型提供商
| 类型 | 提供商 | 示例模型 |
|---|---|---|
| 国际厂商 | OpenAI | GPT-3.5, GPT-4 |
| 国际厂商 | Anthropic | Claude 2 |
| 国际厂商 | Gemini | |
| 国内厂商 | 通义千问 | Qwen-Plus |
| 国内厂商 | 文心一言 | ERNIE Bot |
| 国内厂商 | 智谱 AI | GLM |
| 开源模型 | 通过 Ollama/LocalAI | Llama 2, Mistral, Qwen |
2. 向量数据库
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Weaviate | 开源,支持语义搜索 | 大规模生产环境 |
| Qdrant | 轻量级,易于部署 | 中小型应用 |
| Milvus | 高性能,可扩展 | 大规模向量数据 |
| Chroma | 内存型,快速原型 | 开发和测试 |
| PGVector | 基于 PostgreSQL | 已有 PostgreSQL 基础的项目 |
3. 存储服务
Dify 支持多种存储服务,用于存储文档、媒体文件等:
-
本地文件系统
-
Amazon S3
-
Azure Blob Storage
-
阿里云 OSS
-
腾讯云 COS
4. 监控和追踪
| 工具 | 用途 |
|---|---|
| Langfuse | LLM 应用监控和追踪 |
| LangSmith | LangChain 应用监控 |
| Sentry | 错误监控和追踪 |
| OpenTelemetry | 分布式追踪 |
六、架构流程示例
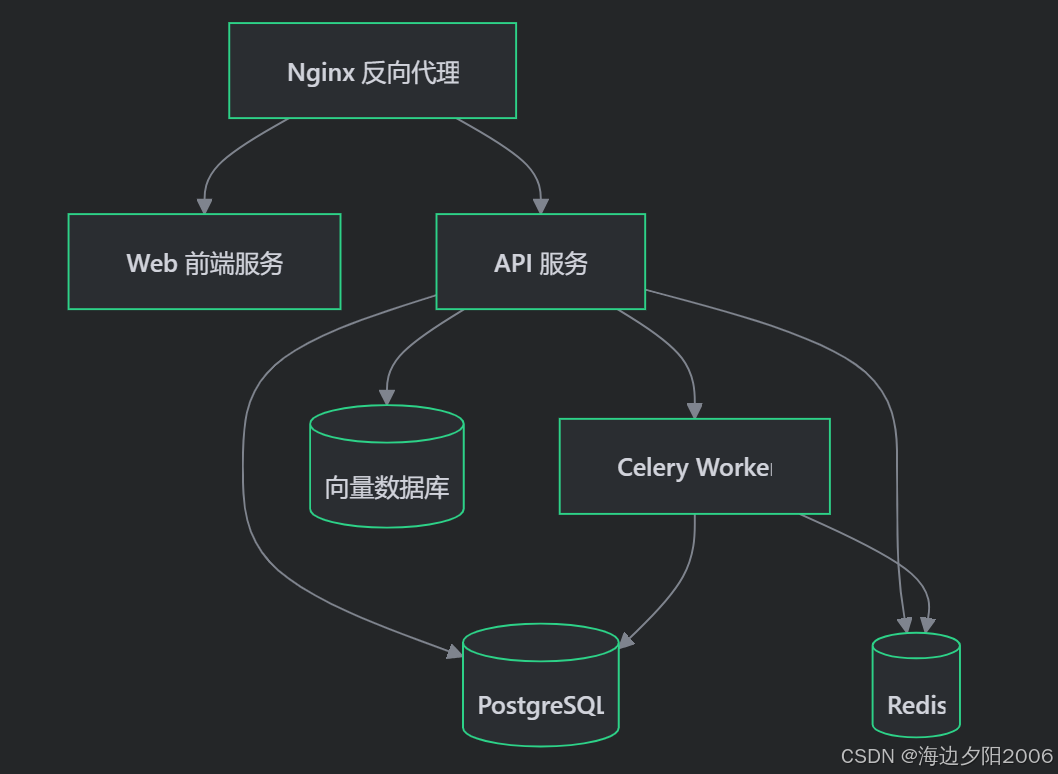
让我们通过一个具体场景来了解 Dify 的架构流程:用户在聊天应用中发送一条消息。
详细流程
1. 用户发送消息
-
用户在浏览器中输入消息并发送
-
前端将消息通过 API 发送给后端
2. 请求处理
-
Nginx 作为反向代理接收请求
-
请求被转发到 Flask API 服务
3. 业务逻辑处理
-
API 服务接收到消息
-
检查用户权限和应用状态
-
创建或更新对话记录
4. RAG 处理
-
如果启用了 RAG,系统会:
-
向量化用户问题
-
在向量数据库中检索相关文档
-
构建上下文
-
5. 调用 LLM
-
将用户问题和上下文发送给配置的 LLM
-
处理 LLM 的响应
6. 异步任务处理
-
对于耗时操作,如文档处理,会:
-
将任务发送到 Celery 队列
-
Worker 处理任务
-
结果存储到数据库
-
7. 响应返回
-
API 服务将 LLM 的回答返回给前端
-
前端显示回答给用户
8. 数据存储
-
对话和消息记录存储到 PostgreSQL
-
临时数据和缓存存储到 Redis
七、Dify 的独特优势
相比 LangChain、LlamaIndex 等框架,Dify 具有以下独特优势:
1. 开箱即用的完整产品
-
不只是代码库,而是完整的 SaaS 级应用
-
提供完整的用户界面和管理功能
2. 可视化工作流编辑器
-
拖拽式构建 AI 应用,降低开发门槛
-
实时预览和测试功能
3. 企业级特性
-
多租户架构
-
细粒度权限管理
-
完整的审计日志
-
数据隔离
4. 丰富的集成能力
-
支持 50+ 内置工具
-
支持 100+ 模型提供商
-
多种向量数据库集成
5. LLMOps 能力
-
提示词管理和版本控制
-
详细的日志追踪
-
性能监控和分析
八、实践应用场景
Dify 适用于多种 AI 应用场景,以下是几个典型示例:
1. 智能客服机器人
功能:
-
自动回答用户常见问题
-
处理简单的业务咨询
-
转接复杂问题给人工客服
实现:
-
使用工作流引擎构建对话流程
-
利用 RAG 检索产品文档和常见问题
-
集成客服系统 API
2. 内容生成工具
功能:
-
生成文章、报告、邮件等
-
基于模板和示例生成内容
-
支持多种格式输出
实现:
-
使用 LLM 生成内容
-
利用工作流引擎处理不同类型的生成任务
-
集成内容管理系统
3. 数据分析助手
功能:
-
分析和可视化数据
-
生成数据报告
-
回答关于数据的问题
实现:
-
集成数据分析工具
-
使用 RAG 检索相关数据
-
利用 LLM 生成分析结果
4. 个人助手
功能:
-
日程管理和提醒
-
信息查询和汇总
-
任务管理
实现:
-
集成日历和任务系统
-
使用 RAG 检索个人信息
-
构建个性化工作流
九、技术架构的扩展性
Dify 的架构设计具有良好的扩展性,主要体现在以下几个方面:
1. 模块化设计
-
核心业务逻辑与基础设施分离
-
各模块之间通过明确的接口通信
2. 插件系统
-
支持自定义工具和集成
-
可扩展的模型提供商接口
3. 水平扩展
-
API 服务可以水平扩展以处理更多请求
-
Worker 可以根据任务量动态调整
4. 多环境部署
-
支持开发、测试、生产环境
-
容器化部署支持
十、总结
Dify 是一个功能强大、架构清晰的 LLM 应用开发平台,它通过模块化设计、可视化工具和丰富的集成能力,大大降低了 AI 应用的开发门槛。其核心优势在于:
-
完整的产品体验 - 从开发到部署的全流程支持
-
可视化开发 - 降低技术门槛,提高开发效率
-
企业级特性 - 满足企业应用的安全和管理需求
-
丰富的集成 - 支持多种模型和服务
-
可扩展架构 - 适应不同规模和场景的需求
Dify 不仅是一个开发工具,更是一个完整的 AI 应用平台,它为开发者提供了构建智能应用的全套解决方案,使 AI 技术能够更广泛地应用到各个领域。
通过本文的详细解析,相信您对 Dify 的架构设计、核心组件和应用场景有了更全面的了解。Dify 的出现,为 AI 应用开发带来了新的思路和方法,也为企业和开发者提供了一个构建智能系统的强大工具。