文章目录
- [1. ETL 流水线](#1. ETL 流水线)
- [2. RAG Advisor](#2. RAG Advisor)
-
- [2.1 QuestionAnswerAdvisor 问答增强器](#2.1 QuestionAnswerAdvisor 问答增强器)
-
- [2.1.1 检索参数配置](#2.1.1 检索参数配置)
- [2.1.2 动态过滤表达式](#2.1.2 动态过滤表达式)
- [2.1.3 自定义提示词模板](#2.1.3 自定义提示词模板)
- [2.2 RetrievalAugmentationAdvisor 检索增强增强器](#2.2 RetrievalAugmentationAdvisor 检索增强增强器)
-
- [2.2.1 基础 RAG](#2.2.1 基础 RAG)
- [2.2.2 动态元数据过滤](#2.2.2 动态元数据过滤)
- [2.2.3 高阶 RAG](#2.2.3 高阶 RAG)
- [3. RAG 模块化架构](#3. RAG 模块化架构)
-
- [3.1 检索前处理(Pre-Retrieval)](#3.1 检索前处理(Pre-Retrieval))
-
- [3.1.1查询转换器 QueryTransformer](#3.1.1查询转换器 QueryTransformer)
- [3.1.2 查询扩展 Query Expansion](#3.1.2 查询扩展 Query Expansion)
- [3.2 检索层(Retrieval)](#3.2 检索层(Retrieval))
-
-
- [3.2.1 向量文档检索器 VectorStoreDocumentRetriever](#3.2.1 向量文档检索器 VectorStoreDocumentRetriever)
- [3.2.2 文档合并器 Document Join](#3.2.2 文档合并器 Document Join)
-
- [3.3 检索后处理(Post-Retrieval)](#3.3 检索后处理(Post-Retrieval))
- [3.4 生成层(Generation)](#3.4 生成层(Generation))
-
-
- [3.4.1上下文增强器 ContextualQueryAugmenter](#3.4.1上下文增强器 ContextualQueryAugmenter)
-
1. ETL 流水线
Spring AI 认为,从宏观架构来看,RAG 是一套标准的 ETL(抽取、转换、加载) 流水线,而向量数据库正是 RAG 技术中检索环节的核心载体。
ETL 流水线负责编排全流程:
- 从数据源抽取原始数据标准化,转换后持久化至结构化向量存储,确保数据格式适配检索逻辑,为后续大模型问答提供高质量上下文。
- 用户提问时,从向量存储中检索出相关数据,和用户问题一些整合到提示词中,由大模型生成最终答案
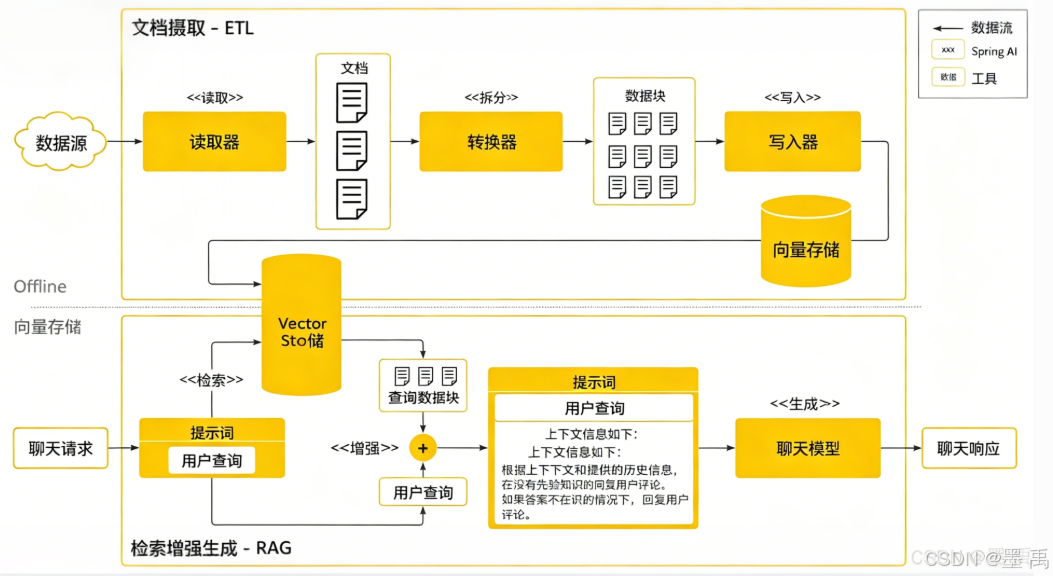
2. RAG Advisor
Spring AI 提供模块化架构全面支持 RAG 能力:
- 开发者既可自主搭建定制化
RAG流程 - 也能通过内置的
Advisor快速开箱即用标准RAG能力
Spring AI 基于 Advisor 组件,内置封装了通用 RAG 场景的开箱即用能力。
如需使用 QuestionAnswerAdvisor、VectorStoreChatMemoryAdvisor,需在项目中引入向量存储增强器依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>2.1 QuestionAnswerAdvisor 问答增强器
向量数据库中存储着大模型未知的外部私有数据 。当用户发起提问时,QuestionAnswerAdvisor 会根据用户问题,从向量数据库检索语义相关文档。
随后将检索到的文档上下文,追加到用户提问中,为大模型提供参考依据,辅助其生成精准回答。
假设已提前完成向量数据入库,只需为 ChatClient 注入 QuestionAnswerAdvisor,即可快速实现 RAG:
java
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(QuestionAnswerAdvisor.builder(vectorStore).build())
.user(userText)
.call()
.chatResponse();该示例中,增强器会在向量库中执行相似度检索 。同时支持通过 SearchRequest 配置类 SQL 过滤表达式,实现多向量存储通用的文档筛选逻辑。
过滤规则支持两种配置方式:
- 初始化增强器时全局固定配置,对所有请求生效;
- 运行时单请求动态传入,灵活按需筛选。
2.1.1 检索参数配置
自定义相似度阈值、最大召回数量:
java
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.similarityThreshold(0.8d) // 相似度阈值
.topK(6) // 最多返回6条结果
.build())
.build();2.1.2 动态过滤表达式
通过内置上下文参数 FILTER_EXPRESSION,在运行时动态修改筛选条件:
java
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder().build())
.build())
.build();
// 运行时动态指定过滤条件
String content = this.chatClient.prompt()
.user("Please answer my question XYZ")
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'"))
.call()
.content();FILTER_EXPRESSION 参数可基于自定义规则,实时过滤检索结果。
2.1.3 自定义提示词模板
QuestionAnswerAdvisor 默认内置模板,用于拼接「用户问题+检索上下文」。开发者可通过 .promptTemplate() 自定义提示词规则,灵活控制上下文拼接逻辑。
重要区分:
- 增强器级模板:控制检索上下文与用户问题的拼接规则;
ChatClient全局模板:在增强器执行前,渲染全局系统提示、用户初始文案。
自定义模板必须包含两个固定占位符:
- 「用户问题」占位符:接收用户原始提问;
- 「
question_answer_context」占位符:接收检索到的文档上下文。
自定义模板完整示例:
java
PromptTemplate customPromptTemplate = PromptTemplate.builder()
.renderer(StTemplateRenderer.builder()
.startDelimiterToken('<')
.endDelimiterToken('>')
.build())
.template("""
<query>
以下为参考上下文信息:
---------------------
<question_answer_context>
---------------------
请严格依据上述上下文回答问题,禁止使用外部知识库。
遵循以下规则:
1. 上下文无答案时,直接回复「暂无相关答案」;
2. 禁止使用「根据上下文」「依据提供信息」等冗余话术。
""")
.build();
String question = "阿纳克莱图斯与比尔巴的冒险故事发生在哪里?";
QuestionAnswerAdvisor qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.promptTemplate(customPromptTemplate)
.build();
String response = ChatClient.builder(chatModel).build()
.prompt(question)
.advisors(qaAdvisor)
.call()
.content();废弃说明:
QuestionAnswerAdvisor.Builder.userTextAdvise()方法已废弃,推荐统一使用.promptTemplate()实现灵活定制。
2.2 RetrievalAugmentationAdvisor 检索增强增强器
Spring AI 提供全套模块化 RAG 组件库,支持开发者自主编排 RAG 流程。RetrievalAugmentationAdvisor 基于模块化设计,封装了通用标准 RAG 流程,开箱即用。
使用该组件需引入专属 RAG 依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>2.2.1 基础 RAG
最简 RAG 实现,直接检索向量文档并注入上下文:
java
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();默认规则:检索上下文为空时,禁止大模型作答。
如需允许空上下文、强制模型回复,可手动开启配置:
java
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true) // 允许空上下文
.build())
.build();2.2.2 动态元数据过滤
支持静态固定过滤、运行时动态过滤,适配多租户、分类文档等场景:
java
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
// 单请求动态过滤
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.advisors(a -> a.param(VectorStoreDocumentRetriever.FILTER_EXPRESSION, "type == 'Spring'"))
.user(question)
.call()
.content();2.2.3 高阶 RAG
集成查询重写能力,优化模糊、口语化、歧义问题,提升检索精准度:
java
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build())
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();同时支持文档后处理接口:对检索结果进行二次加工,例如:结果重排序、冗余文档过滤、内容压缩降噪等。
3. RAG 模块化架构
Spring AI 参考《模块化 RAG:将 RAG 系统改造为乐高式可重组框架》论文理念,实现解耦式、可自由组合 的 RAG 分层架构,分为四大核心模块:
3.1 检索前处理(Pre-Retrieval)
负责优化用户原始提问,为高质量检索奠定基础。
3.1.1查询转换器 QueryTransformer
优化输入问题结构,解决语句不通顺、语义模糊、专业词汇复杂、多语言适配等问题。
-
对话压缩转换器 CompressionQueryTransformer: 压缩超长对话历史+后续追问,合并为独立完整问题,保留核心上下文,适合多轮对话场景。
-
查询重写转换器 RewriteQueryTransformer: 简化冗长口语化提问、消除语义歧义、剔除无效信息,提升向量检索与搜索引擎匹配精度。
-
翻译转换器 TranslationQueryTransformer: 将用户提问翻译为向量模型训练语种,解决跨语言检索问题;语种匹配/未知时原样返回。
最佳实践:使用查询转换能力时,建议将模型
temperature设为0.0,保证结果稳定、可复现。
3.1.2 查询扩展 Query Expansion
将单个问题拆解、衍生为多条语义差异化子问题,覆盖更多检索维度,提升召回率。
- 多查询扩展器 MultiQueryExpander: 基于大模型生成多条异构问题,多角度检索文档;默认包含原始问题,可手动关闭。
3.2 检索层(Retrieval)
对接向量库、搜索引擎、数据库、知识图谱等数据源,召回高相关文档。
3.2.1 向量文档检索器 VectorStoreDocumentRetriever
核心检索组件,基于语义相似度召回文档,支持:相似度阈值、TopK 限制、元数据过滤。
- 支持静态过滤:初始化时固定筛选条件;
- 支持动态过滤 :运行时通过
Lambda、请求参数动态传递规则; - 优先级:单请求动态过滤 > 检索器全局固定过滤。
3.2.2 文档合并器 Document Join
聚合多查询、多数据源的检索结果,自动去重、统一排序,合并为一份标准化文档集合。
3.3 检索后处理(Post-Retrieval)
优化原始检索文档,解决「中间信息丢失」、模型上下文长度限制、内容冗余噪音等问题。
常见能力:相关性重排序、无效文档剔除、文本压缩精简。
3.4 生成层(Generation)
结合用户提问+优化后的检索上下文,最终生成合规、精准的回答内容。
3.4.1上下文增强器 ContextualQueryAugmenter
将检索文档的上下文信息注入用户提问,为大模型提供回答依据。
- 默认禁止空上下文作答;
- 可配置
allowEmptyContext开启兜底回复; - 支持自定义正常场景、空上下文场景双套提示词模板。