文章目录
- 一、理解参数化的本质
- [二、基础应用:`@pytest.mark.parametrize` 单参数](#二、基础应用:
@pytest.mark.parametrize单参数) - 三、多参数场景:实战常用模式
- [四、提升可读性:使用 `ids` 命名测试用例](#四、提升可读性:使用
ids命名测试用例) - 五、高级技巧:为特定数据组添加标记
-
- [核心应用场景:`xfail` 标记](#核心应用场景:
xfail标记)
- [核心应用场景:`xfail` 标记](#核心应用场景:
- [六、fixture 参数化:准备阶段的多样性](#六、fixture 参数化:准备阶段的多样性)
- 七、YAML:测试数据管理的理想选择
-
- [为何在测试中使用 YAML?](#为何在测试中使用 YAML?)
- [八、YAML 核心数据结构](#八、YAML 核心数据结构)
-
-
- [1. 映射(Mapping)- 类似字典](#1. 映射(Mapping)- 类似字典)
- [2. 序列(Sequence)- 类似列表](#2. 序列(Sequence)- 类似列表)
- [3. 嵌套结构](#3. 嵌套结构)
-
- [九、YAML 语法精要](#九、YAML 语法精要)
- [十、安全读取 YAML:PyYAML 最佳实践](#十、安全读取 YAML:PyYAML 最佳实践)
-
- 1)安全读取代码
- [2)为何必须使用 `safe_load`?](#2)为何必须使用
safe_load?)
- [十一、YAML 与 pytest 集成:数据驱动测试](#十一、YAML 与 pytest 集成:数据驱动测试)
- 十二、实战案例:登录接口数据驱动测试
- 十三、参数解构:从字典到独立参数
- [十四、工程级 YAML 设计:请求/验证分离模式](#十四、工程级 YAML 设计:请求/验证分离模式)
- [十五、综合应用:参数化与 Fixture 协同](#十五、综合应用:参数化与 Fixture 协同)
- [十六、避坑指南:6 个关键注意事项](#十六、避坑指南:6 个关键注意事项)
-
- [1️⃣ YAML 缩进问题](#1️⃣ YAML 缩进问题)
- [2️⃣ 结构混淆](#2️⃣ 结构混淆)
- [3️⃣ 安全风险](#3️⃣ 安全风险)
- [4️⃣ 参数不匹配](#4️⃣ 参数不匹配)
- [5️⃣ 缺少 IDs](#5️⃣ 缺少 IDs)
- [6️⃣ 逻辑混入](#6️⃣ 逻辑混入)
一、理解参数化的本质
参数化测试的核心价值在于:使用同一套测试逻辑,通过多组不同输入数据重复执行。pytest 框架提供了三种主要参数化方式:
@pytest.mark.parametrize装饰器:为测试函数定义多组参数- fixture 的
params参数:使 fixture 被多次调用 pytest_generate_tests钩子函数:自定义参数生成逻辑(pytest 文档1)
简言之,参数化实现了:
将"编写10个相似测试函数"的繁重工作,简化为"编写1个测试函数+提供10组测试数据"。
二、基础应用:@pytest.mark.parametrize 单参数
环境准备
bash
pip install -U pytest pyyamlpytest:执行测试的核心框架PyYAML:安全读写 YAML 文件,推荐使用safe_load/safe_dump等安全接口
1)代码示例
python
# test_single_param.py
import pytest
@pytest.mark.parametrize("num", [1, 2, 3, 4])
def test_num_is_positive(num):
assert num > 02)工作原理
"num"作为参数名[1, 2, 3, 4]提供4组测试数据- pytest 自动执行4次测试函数,每次注入一个值
此机制允许我们高效地验证同一逻辑在不同输入下的行为,是 pytest 参数化能力的基础表现形式(pytest 文档1)。
3)执行流程
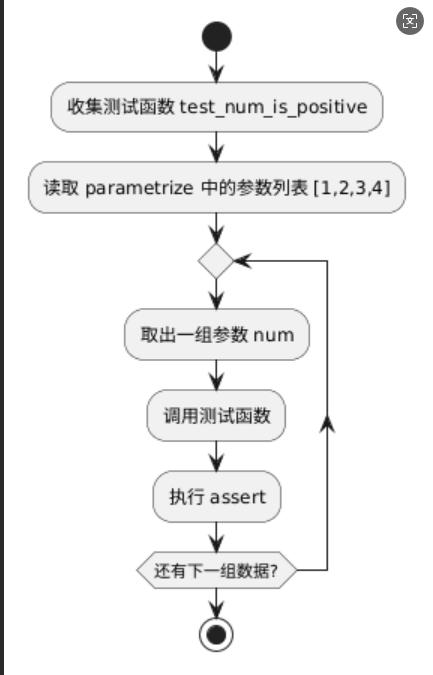
三、多参数场景:实战常用模式
1)代码示例
python
# test_multi_param.py
import pytest
@pytest.mark.parametrize(
"a,b,expected",
[
(1, 2, 3),
(2, 3, 5),
(10, 20, 30),
]
)
def test_add(a, b, expected):
assert a + b == expected2)机制解析
- 参数列表
"a,b,expected"定义了三个输入变量 - 每个元组代表一组完整的测试数据
- pytest 按顺序执行,每次使用一行数据
这种"多参数+多组值"的组合是自动化测试中最常见的参数化模式,能够高效覆盖多种测试场景(pytest 文档1)。
3)执行流程
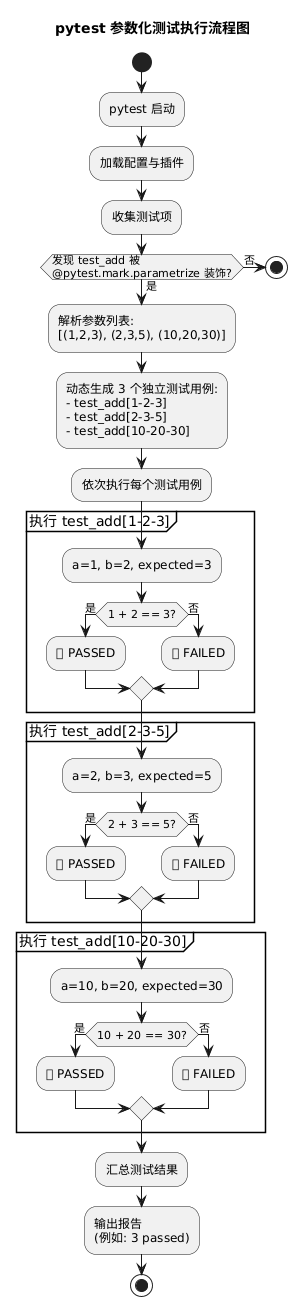
四、提升可读性:使用 ids 命名测试用例
当参数化测试增多时,自动生成的测试ID难以辨识。ids 参数允许为每组数据提供人类可读的标识,极大提升调试效率(pytest 文档2)。
1)代码示例
python
# test_ids.py
import pytest
@pytest.mark.parametrize(
"username,password,expected",
[
("admin", "123456", True),
("admin", "wrong", False),
("", "123456", False),
],
ids=["正确账号密码", "密码错误", "用户名为空"]
)
def test_login_check(username, password, expected):
result = (username == "admin" and password == "123456")
assert result == expected2)执行效果
bash
test_ids.py::test_login_check[正确账号密码]
test_ids.py::test_login_check[密码错误]
test_ids.py::test_login_check[用户名为空]相比默认ID(如[0]、[1]),这种命名方式显著提高了测试报告的可读性和问题定位效率(pytest 文档2)。
五、高级技巧:为特定数据组添加标记
pytest.param() 允许对单组测试数据设置专属标记或ID,适用于特殊场景(pytest 文档2)。
python
# test_pytest_param.py
import pytest
@pytest.mark.parametrize(
"num,expected",
[
(1, 1),
pytest.param(2, 4, id="平方校验"),
pytest.param(3, 10, marks=pytest.mark.xfail, id="故意失败样例"),
]
)
def test_square(num, expected):
assert num * num == expected核心应用场景:xfail 标记
xfail (expected to fail) 适用于已知缺陷但暂时不修复的情况:
- 标记为
xfail的测试失败时 :报告为XFAIL(预期失败)✅ - 标记为
xfail的测试意外通过时 :报告为XPASS(意外通过)⚠️ - 意义:当测试意外通过,可能表示相关bug已被无意修复,需要评估
这种机制使测试套件保持绿色状态,同时不掩盖已知问题,是测试工程中的重要实践。
六、fixture 参数化:准备阶段的多样性
fixture 同样支持参数化,适用于测试前置条件多样化的场景(pytest 文档3)。
1)代码示例
python
# test_fixture_params.py
import pytest
@pytest.fixture(
params=["管理员", "普通用户", "游客"],
ids=["admin", "user", "guest"]
)
def role(request):
return request.param
def test_role_permission(role):
assert role in ["管理员", "普通用户", "游客"]2)适用场景
fixture 参数化特别适合以下情况:
- 需创建不同测试账号/权限级别
- 需要不同浏览器/设备环境
- 依赖不同外部服务配置
与函数参数化相比,当资源准备逻辑复杂时,fixture 参数化能更好地组织代码,分离关注点(pytest 文档1)。
七、YAML:测试数据管理的理想选择
YAML(YAML Ain't Markup Language)是一种人类可读的数据序列化标准。YAML 1.2 规范增强了与 JSON 的兼容性,使其成为测试数据管理的理想格式(YAML4)。
为何在测试中使用 YAML?
将测试数据从代码中分离带来三大核心优势:
- 关注点分离:测试逻辑与测试数据各自独立
- 维护效率:修改测试数据无需变更代码
- 资源复用:同一份数据可被多个测试用例共享
这些优势源于 YAML 的简洁语法与 PyYAML 库的强大解析能力(PyYAML5)。
八、YAML 核心数据结构
YAML 支持三种基础数据结构(YAML6):
1. 映射(Mapping)- 类似字典
yaml
name: 张三
age: 18
city: 上海解析结果:
python
{"name": "张三", "age": 18, "city": "上海"}2. 序列(Sequence)- 类似列表
yaml
- 苹果
- 香蕉
- 葡萄解析结果:
python
["苹果", "香蕉", "葡萄"]3. 嵌套结构
yaml
user:
name: admin
password: 123456
roles:
- 管理员
- 测试员解析结果:
python
{
"user": {"name": "admin", "password": "123456"},
"roles": ["管理员", "测试员"]
}九、YAML 语法精要
测试数据编写只需掌握以下核心规则(YAML6):
key: value:键值对(注意冒号后需有空格)-:列表项前缀#:单行注释- 缩进表示层级(必须使用空格,禁止Tab)
- 支持流式写法:
[1,2,3]、{name: admin}
实用示例
yaml
# 登录测试数据
login_cases:
- title: 正确登录
username: admin
password: 123456
expected: true
- title: 密码错误
username: admin
password: wrong
expected: false关键提示:YAML 对缩进极其敏感,不一致的缩进是常见错误根源。
十、安全读取 YAML:PyYAML 最佳实践
1)安全读取代码
python
# yaml_demo.py
import yaml
with open("login_data.yml", "r", encoding="utf-8") as f:
data = yaml.safe_load(f)
print(data)
print(type(data)) # 通常返回 dict 或 list2)为何必须使用 safe_load?
PyYAML 文档明确警示:yaml.load() 可能执行任意代码,而 safe_load():
- 仅解析标准 YAML 标签
- 无法构造任意 Python 对象
- 有效防止反序列化漏洞
安全原则 :除非有特殊需求且完全信任数据源,否则一律使用 safe_load()(PyYAML5)。
十一、YAML 与 pytest 集成:数据驱动测试
集成思路
- 将测试数据存储在 YAML 文件中
- 使用 Python 读取并解析 YAML
- 将解析后的数据传递给
@pytest.mark.parametrize
这种模式本质是将参数来源从硬编码转变为外部数据文件,符合 pytest 的设计哲学------参数可来自任何合法 Python 对象(pytest 文档1)。
核心优势
- 维护性提升:测试数据变更无需修改代码
- 可读性增强:YAML 格式比硬编码列表更直观
- 协作效率:非技术人员也能理解/修改测试数据
十二、实战案例:登录接口数据驱动测试
项目结构
text
project_demo/
├─ data/
│ └─ login_data.yml # 测试数据
├─ common/
│ └─ yaml_util.py # 工具函数
└─ tests/
└─ test_login.py # 测试用例1)YAML 测试数据
yaml
# data/login_data.yml
login_cases:
- title: 正确登录
username: admin
password: 123456
expected_code: 200
expected_msg: 登录成功
- title: 密码错误
username: admin
password: wrong
expected_code: 401
expected_msg: 密码错误
- title: 用户名为空
username: ""
password: 123456
expected_code: 400
expected_msg: 用户名不能为空2)YAML 读取工具
python
# common/yaml_util.py
import yaml
def read_yaml(path):
"""安全读取YAML文件,返回Python对象"""
with open(path, "r", encoding="utf-8") as f:
return yaml.safe_load(f)3)测试实现
python
# tests/test_login.py
import pytest
from common.yaml_util import read_yaml
def fake_login(username, password):
"""模拟登录接口,实际项目中替换为真实API调用"""
if not username:
return {"code": 400, "msg": "用户名不能为空"}
if username == "admin" and password == "123456":
return {"code": 200, "msg": "登录成功"}
return {"code": 401, "msg": "密码错误"}
# 读取并准备测试数据
data = read_yaml("data/login_data.yml")
cases = data["login_cases"]
@pytest.mark.parametrize(
"case",
cases,
ids=[case["title"] for case in cases] # 使用标题作为测试ID
)
def test_login(case):
"""参数化登录测试"""
result = fake_login(case["username"], case["password"])
assert result["code"] == case["expected_code"]
assert result["msg"] == case["expected_msg"]4)执行流程
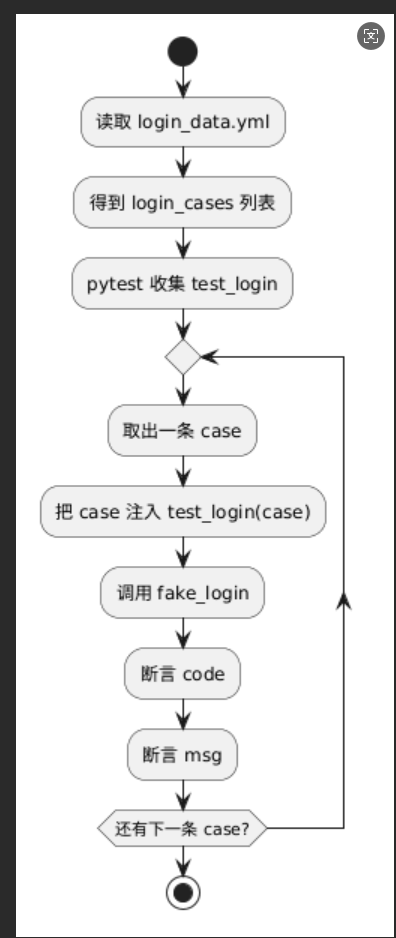
十三、参数解构:从字典到独立参数
某些场景下,直接使用独立参数比通过字典访问更清晰:
python
# tests/test_login_split.py
import pytest
from common.yaml_util import read_yaml
# [fake_login 函数定义同上]
# 读取测试数据
data = read_yaml("data/login_data.yml")
cases = data["login_cases"]
# 将case字典拆分为独立参数
@pytest.mark.parametrize(
"title,username,password,expected_code,expected_msg",
[
(
case["title"],
case["username"],
case["password"],
case["expected_code"],
case["expected_msg"],
)
for case in cases
],
ids=[case["title"] for case in cases]
)
def test_login_split(title, username, password, expected_code, expected_msg):
"""使用解构参数的测试方式"""
result = fake_login(username, password)
assert result["code"] == expected_code
assert result["msg"] == expected_msg这种写法在参数数量固定且较少时更具可读性,本质仍是标准的多参数参数化(pytest 文档1)。
十四、工程级 YAML 设计:请求/验证分离模式
在专业自动化测试项目中,YAML 通常采用分层设计:
yaml
login_cases:
- title: 正确登录
request:
username: admin
password: 123456
validate:
code: 200
msg: 登录成功
- title: 密码错误
request:
username: admin
password: wrong
validate:
code: 401
msg: 密码错误设计优势
- 清晰分离关注点:明确区分输入(request)与预期(validate)
- 扩展性强:易于添加headers、cookies等请求参数
- 维护成本低:验证逻辑变更不影响请求结构
对应测试代码
python
# tests/test_login_request_validate.py
import pytest
from common.yaml_util import read_yaml
# [fake_login 函数定义同上]
cases = read_yaml("data/login_request_validate.yml")["login_cases"]
@pytest.mark.parametrize("case", cases, ids=[c["title"] for c in cases])
def test_login_request_validate(case):
"""分层结构的数据驱动测试"""
req = case["request"]
expected = case["validate"]
# 执行测试
result = fake_login(req["username"], req["password"])
# 验证结果
assert result["code"] == expected["code"]
assert result["msg"] == expected["msg"]这种结构更贴近真实API测试场景,是企业级自动化测试的常见模式。
十五、综合应用:参数化与 Fixture 协同
在复杂测试场景中,参数化与 fixture 常协同工作:参数化提供测试数据,fixture 提供共享资源(pytest 文档3)。
python
# tests/test_login_with_fixture.py
import pytest
from common.yaml_util import read_yaml
# 共享资源:基础URL
@pytest.fixture
def base_url():
"""提供API基础URL,可被多个测试用例复用"""
return "https://api.demo.com"
def fake_post(base_url, username, password):
"""模拟带基础URL的API调用"""
# 实际项目中这里会使用 requests.post(f"{base_url}/login", ...)
if not username:
return {"code": 400, "msg": "用户名不能为空"}
if username == "admin" and password == "123456":
return {"code": 200, "msg": "登录成功"}
return {"code": 401, "msg": "密码错误"}
# 获取测试数据
cases = read_yaml("data/login_data.yml")["login_cases"]
# 结合fixture与参数化
@pytest.mark.parametrize("case", cases, ids=[c["title"] for c in cases])
def test_login_with_fixture(base_url, case):
"""使用fixture提供共享资源,参数化提供测试数据"""
result = fake_post(base_url, case["username"], case["password"])
assert result["code"] == case["expected_code"]
assert result["msg"] == case["expected_msg"]这种模式实现了:
- 资源复用 :
base_url由 fixture 统一管理 - 数据驱动:测试用例通过 YAML 参数化
- 关注点分离:测试逻辑、测试数据、共享资源各自独立
十六、避坑指南:6 个关键注意事项
1️⃣ YAML 缩进问题
- 问题:YAML 依赖缩进表示层级,不一致缩进导致解析失败
- 解决方案:统一使用2或4空格缩进,禁用Tab,使用IDE的YAML验证插件
2️⃣ 结构混淆
- 问题 :混淆序列(带
-)与映射(key: value)结构 - 解决方案 :牢记
- item表示列表项key: value表示键值对- 混合使用时注意层级对齐
3️⃣ 安全风险
- 问题 :使用
yaml.load()导致潜在代码执行漏洞 - 解决方案 :永远优先使用
yaml.safe_load()
4️⃣ 参数不匹配
- 问题:参数化名称数量与数据列数不一致
- 解决方案:严格检查参数列表与数据结构匹配度
5️⃣ 缺少 IDs
- 问题:大量参数化测试时,失败用例难以定位
- 解决方案 :始终 为参数化测试提供有意义的
ids
6️⃣ 逻辑混入
- 问题:在YAML中尝试编写业务逻辑(如条件判断)
- 解决方案 :牢记 YAML 只是数据载体,复杂逻辑应保留在Python代码中
黄金法则 :当不确定YAML写法时,先用Python构造数据,再转换为YAML格式,最后用
safe_load验证解析结果是否符合预期。
通过系统掌握参数化测试与YAML数据驱动,你已具备构建可维护、可扩展自动化测试体系的核心能力。这些技术不仅是pytest的进阶用法,更是工程化测试思维的重要体现。