
目录
HTTP协议简介
HTTP(HyperText Transfer Protocol,超文本传输协议)是网络中一个至关重要的协议,它定义了客户端(如浏览器)与服务器之间的通信,以交换或传输超文本。
HTTP协议是客户端与服务器之间通信的基础。客户端通过HTTP协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP是一个无连接、无状态的协议,即每次请求都要建立新的连接,且服务器不会保存客服端的状态信息。
Http本质和浏览器底层,用的都是TcpSocket,用的都是ip+port的进程间通信机制。
URL和uri
在我们用网络进行资源搜索时,通常会用一个网址来进行搜索,这个网址其实就是URL,即统一资源定位符,如下所示:

首先,URL第一部分就是所用到的协议,这里为https。
第二部分"www.example.jp"为对应的域名,本质就是ip地址,访问目标服务器,只能用ip地址,这是因为计算机只认ip地址,浏览器只不过在这里向域名解析服务器发送DNS请求,域名解析服务器会将对应的ip地址返回给浏览器,然后再发起请求,同样的,向域名解析服务器发送请求,同样需要地址,因此,在浏览器内部,会内置一个域名解析服务器的地址,这个地址为8.8.8.8。
第三部分是服务器端口号,绑定的端口号为80,可以被省略。
第四部分是对应的文件路径,可以找到对应的文件并返回,HTTP本质就是为了获取服务器上的文件内容。通过IP+目标文件地址就能标识唯一,在全网中定位找到这个文件,随后再请求和指定端口绑定的服务器进程,得到数据。而uri为统一资源标识符,它更加强调资源的唯一性,URL是一特殊的uri。
第五部分是URL传参,这部分是要传送给服务器的参数。
Http请求和应答格式
请求
http的请求如下所示:

第一行为请求行,第二行到空行之前为请求报头,第三部分为空行,前三行为报头,第四部分为请求正文,该部分为有效载荷,该部分是可选的,通过空行,分离报头和有效载荷。如下所示:
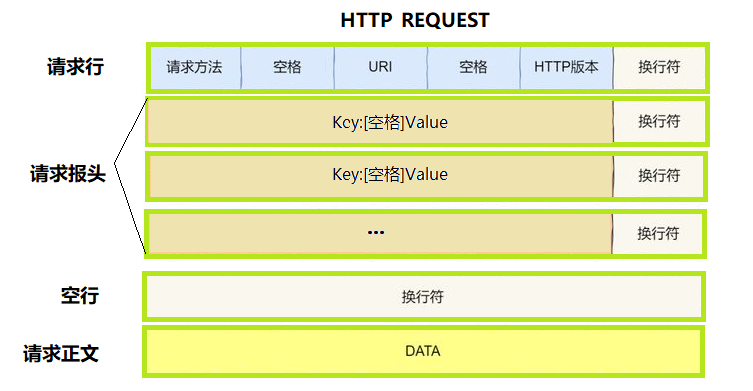
其中,前三部分都是以行为单位保存在Http的报文段中。
请求行以空格为单位被分成了三列,请求方法最常见的是get和post,get为从服务器中获取数据,post为向服务器推送数据;第二部分为URI,表示访问目标服务器目标端口号的特定的资源路径,第三个为客户端的HTTP的版本,最常用的为http/1.1。
第二行到空行之前,每一行都是Key:Value的形式,表示请求报头里涵盖的相关属性信息。
根据请求报文,接收方必须要解决两个问题,首先是如何确保请求报文读完,其次如何反序列化。对于第一个问题,接收方首先可以做到将报头读完,读到连续的两个换行符即可把报头读完,同时请求报头里面会包含一个属性------Content-Length,这里面记录着有效载荷的长度。反序列化以行做为分隔符进行反序列化即可。
请求报头的常见属性如下:
Host:所请求的主机,如果是域名就显示域名,如果是主机就显示主机
Content-Length:请求正文的长度
Content-Type:正文部分内容的类型
User-Agent:客户端类型,通常代表浏览器所对应的类型,通常在请求中携带,应答中没有
Referer:当前页面是从哪个页面跳转过来的
Location:搭配3xx状态码使用,告诉客户端接下来去哪里访问
Cookie:用于在客户端存储少量信息,通常用于实现会话(session)的功能
在用http请求时,如果在端口号后面什么路径都不加,uri默认为"/",这个为web根目录,后面的路径表示该主机唯一的一个文件资源,域名表示主机唯一性,路径表明文件唯一性。通常网络服务,有自己的web根目录,在项目源代码对应的同级目录下,还会有默认的首页,这个首页的文件名默认为index.html。http超文本请求的本质,其实就是通过网络服务器把Linux机器上,特定目录下的文件以http应答的方式返回给client(浏览器或者app)。
应答
响应报文如下所示:

响应报文的结构和请求报文类似,第一行状态行中HTTP版本的表示的是服务端的HTTP版本,状态码为服务器的一个应答,HTTP中规定,发起请求获得应答时,不管成功还是失败,如果网络没问题,服务器没有挂掉,都必须有应答,如果请求成功,就会返回2xx状态码,如果请求失败,就会返回对应的错误码,如404。应答中没有Content-Length属性,这是因为响应正文是有比较确定的格式的,格式内部就会有对应的相关属性,浏览器可以进行解析,但请求中上传的文件时多样的,长度不是定长的,也没有格式,所以必须要有Content-Length。
状态码
状态码描述就是对状态码含义对应的解释。HTTP常见的状态码如下表:
|-----|-------------------------|---------------|
| | 类别 | 原因短句 |
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
重定向
在Http中,存在一种特殊的状态码,这种特殊的状态码为重定向,重定向就是从一个页面跳转到另外一个页面的过程,重定向状态码有301,302还有307等。301为Moved Permanently,代表永久重定向,302为Found,为临时重定向,临时重定向不会修改客户端的认识,只是会进行额外的页面跳转;永久重定向会改变客户端的认识。
客户端向服务器发送请求时,服务器会给客户端返回一个3xx状态码,同时会添加一个Location的报头,这个报头为要重定向到的新的网址,客户端收到对应的状态码和Location,浏览器识别到状态码为3xx,会向对应的站点发送新的二次请求。客户端每次对于新的地址不做记录,就是临时重定向,如果客户端若更新本地书签,下一次访问时直接去访问新的网站,此时就为永久重定向。
302临时重定向往往会在网站登录成功或注册成功时出现,301永久重定向通常会在老网站域名改变时出现。报头里面会有一个属性Location,通常搭配3xx状态码使用,告诉客户端接下来要去哪里访问。
请求方法
HTTP中有很多的请求方法,但是最常用的就是get和post方法,如果想获取资源,则使用get方法,如果想将客户端的数据推送到服务器端,如登录时将用户的账号密码推送到服务器进行验证,常见的方法为post。
当用户要和服务器进行交互时,前端网页中会有一个表单,如下所示:
html
<form action="#" method="GET">
<label for="username">用户名:</label><br>
<input type="text" id="fname" name="name"><br>
<label for="passwd">密码:</label><br>
<input type="password" id="lname" name="passwd"><br><br>
<input type="submit" value="Submit">
</form>在这个表单中,最重要的一个是action,另外一个是method,method默认为get方法,提交表单时,若方法为get方法,那么就是通过URL来传参的,另外一个为action,这个代表要将数据提交给http上的哪一个服务,用户填写表单后,浏览器会自动提取表单的内容并构建带参数的http request,如下所示:
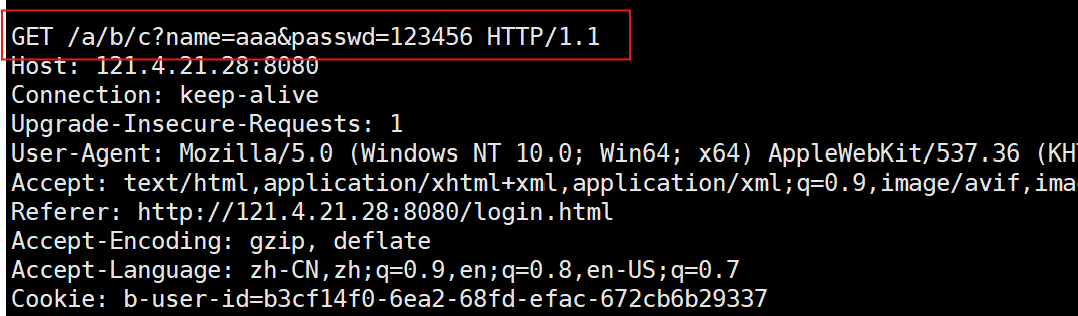
同时,浏览器端会形成121:4.21.28:8080/a/b/c?name=aaa&passwd=123456,形成新的URL后提交参数,资源和参数之前用?隔开,参数之间用&隔开,相当于浏览器将后面的参数提交到对应的服务中去。因此,get方法可以用来进行静态资源的获取,同时也可以向目标服务器传递参数。
若采用post方法,请求信息如下所示:
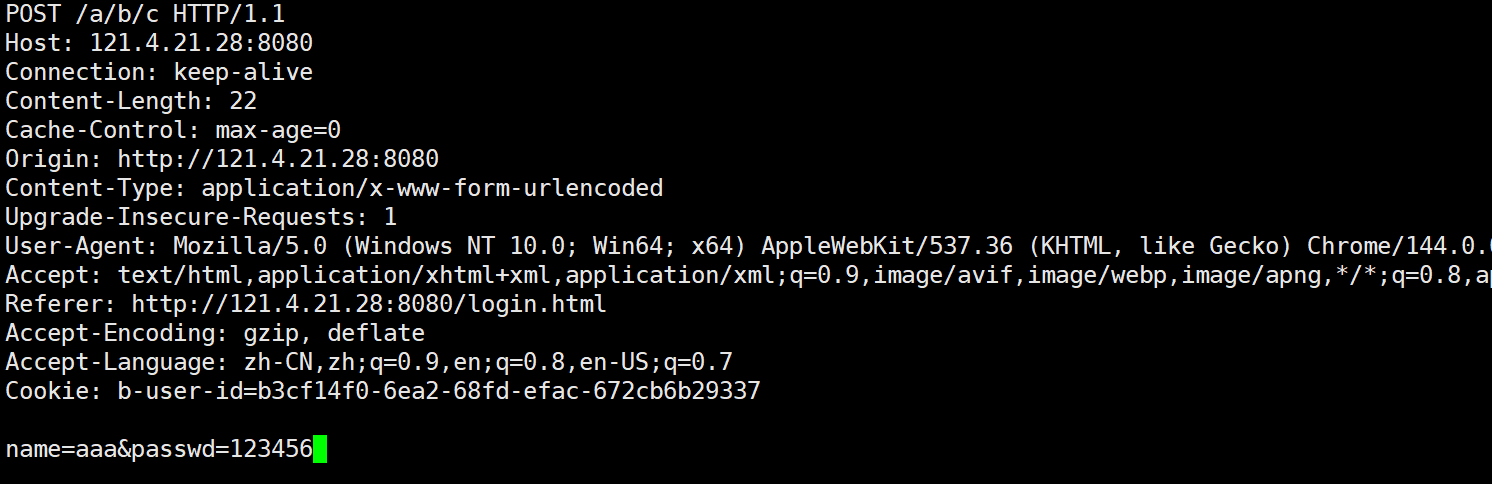
此时,参数放在了正文部分,浏览器端会形成121:4.21.28:8080/a/b/c,POST方式可以用来向目标服务器传参,传参的方式是通过正文部分传参。
因此,HTTP中的URI可以是Linux Web根目录下存在的一个文件路径(静态资源访问),如视频、音频、html等,也可以把它当做一个字符串,用来请求http server中对应的服务,这个字符串往往以路径形式体现,只不过,这个路径不能在web根目录下存在,这种服务为动态服务。
会话管理
当我们登录网站时,在很长时间内,都会在线,这种方式可以减少用户频繁登录的功能。但HTTP是无状态、无连接的,那么是怎么记住用户的信息的呢?
其中一种方案,在用户登录成功时,服务器在应答的报头中添加属性:Set-Cookie,其基本的格式如下:
Set-Cookie: <name>=<value>
其中name是Cookie的名称,<value>是Cookie的值这里面包含了用户名和密码,客户端会在特定目录中保存用户名和密码,相当于向客户端写入数据,这个数据就是cookie,当用户再次发送请求时,或自动携带Cookie属性中的信息,服务器解析HTTP请求时,会得到cookie中的用户名和密码,并自动进行认证。cookie的保存方式,通常有两种,一种是写入到文件中,这种可以持久化存储;另外一种方式是保存在内存中。同时,Set-Cookie中也存在一个过期时间,当过期时间到了,将相关的cookie移除。
但是这种问题存在一个问题,如果黑客获取到了用户的Cookie信息,就会存在"盗号"问题,或者其它安全问题。第二种方案是将相关的结构化信息保存在服务端,保存方式就是将以文件形式保存,并将文件命名成一个唯一的数字,用户的基本信息此时称为session,对应的文件名为session id,应答时的Set-Cookie属性对应的值为session id,浏览器将session id保存下来,每次请求时会自动携带session id。该方案解决的用户数据泄露问题,但是冒充用户身份的问题还没有彻底解决,这个问题光靠http无法彻底解决,而应该靠更上层来解决,可以通过让sessionid失效方式来解决,这种方式的主动权就在服务端,可以更快地发现问题并解决问题。