最近有一个概念"Harness Engineering" 开始兴起,看到很多堆砌概念的文章,读了没什么用。
我结合自己的经历来理解了下。总的来说,我的结论是:如果目标只是让模型在一轮对话里回答得更像样,Prompt Engineering 依然重要;但如果目标变成"让 Agent 连续几十分钟完成一个真实任务",只优化提示词通常是不够的。很多失败并不是模型不会写,而是它不知道该看什么、能用什么、错了以后怎样自我校正。它缺少了一些运行的环境和良好的规范。
算力 需求https://csdn.yijiayun.com,现在认证还有12小时4090直接用
这篇文章想回答三个更具体的问题:
Prompt Engineering、Context Engineering、Harness Engineering分别在解决什么问题?- 为什么在
coding agent场景里,后者会越来越重要? - 当 Agent 表现不好时,我应该怎么做?
首先,我的结论是:这三者不是替代关系,而是同一套 AI 工程系统的三个层次。
Prompt决定你如何发出任务Context决定模型在关键时刻能看到什么Harness决定模型在什么运行机制里完成任务
它们的外延其实是越来越大的。
当我们的目标从"答对一道题"变成"稳定完成一段工作流",系统重心就会自然外移。我们会先发现优化prompt 不够,再发现只补上下文也不够,最后不得不处理运行环境、反馈回路、权限边界和记录系统这些更工程化的问题。
所以,这篇文章表面上是在讲三次演化,真正落点其实是一个更实用的启示:在 coding agent 场景里,很多问题并不是"prompt 还不够好",而是我们没有把系统搭好。(我理解的harness工程的核心思想)
1. Prompt Engineering:先把任务说清楚
大多数人第一次接触 LLM,都是从 prompt 开始的。打开 ChatGPT、DeepSeek 或豆包,在输入框里写一句话,模型给你一段回答。比如,在输入框输入文字:"中国的首都是哪里" 答:"北京"。这种交互方式诞生了大量的ChatBot。它将模型的能力封装成了一个更高效的知识库、数据库、搜索引擎产品。这个阶段,AI的核心是问答任务,即如何更好的输出用户想要的答案。
这一阶段最常见的方法,基本都在解决同一件事:如何让模型更准确地理解我们的意图。所以大家都是在研究提示词技巧:
- 设定身份、背景、行为的格式化方法
- 举例子给模型,所谓one shot/few shot
- 让模型一步步思考的思维链方法
- 让模型推理行动观测的ReAct方法(这里已经初步演进到agent的概念了)
严格一点说,Prompt Engineering 不只是"写一句更有效的话",还包括测试、评估和迭代。它解决的是输入表达问题。
但它的边界也很明确。
- 它不能凭空给模型补进我们的私域知识
- 它不能让模型知道今天的外部世界发生了什么
- 它不能天然解决跨轮对话的持续记忆
- 它也不能代替权限控制、执行环境和错误恢复机制
我们对LLM的期待不是一个高级的数据库查询式的问答,我们希望它能处理上述事情。实际上,我们是在期待一个Agent,而Agent的任务是多步执行。
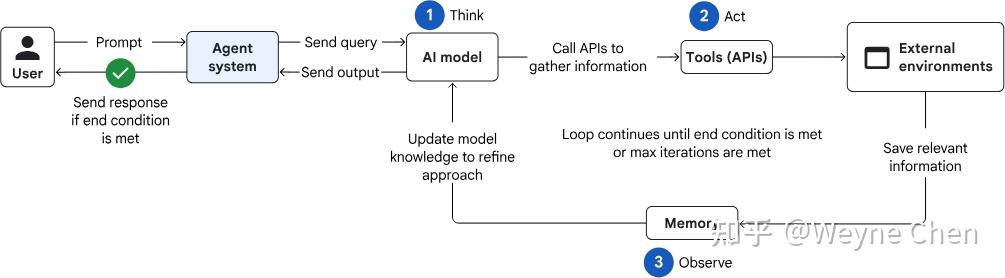
2. Context Engineering:决定模型在关键时刻能看到什么
模型是通过上下文窗口来工作的,prompt是其中的一部分。当任务从问答变成执行,问题的重心就从"如何提问"迁移成"如何组织上下文"。
这里的上下文,不只是 system prompt。凡是会进入模型视野、影响其下一步决策的信息,都可以算上下文,例如:
- 提示词
- 用户输入
- 工具定义
- 工具返回结果
- 历史对话
- 检索出的知识片段
- 长短期记忆
- 当前任务状态
那么如何才能有效的组织这些信息呢?还是机械的将它们填充进来吗?肯定不是。
2.1 RAG:解决"模型不知道的私有知识库"
私域知识、产品文档、内部规范、历史记录,往往比上下文窗口大得多,不能整包塞给模型。这时候就需要先查,再把最相关的片段喂进去。
RAG 的价值在于:它尽量让检索结果和任务语义相关,而不是只做字面匹配。比如同样搜索"苹果",一斤苹果5块钱和一部苹果手机8000块都可能命中,但对当前任务有帮助的内容其实完全不同。经典的笑话就是,女朋友说"我要买苹果,给我转点钱",你转了100块,想来买20斤总是够吃了吧。
不过,RAG的发生也是波折的,中间火热的时候,说"RAG for everything",模型上下文窗口一长,微调技术成熟的时候,又说"RAG is dead"。在实际的企业知识问答实践中,RAG 也总会遇到各种问题被抱怨。
但从我的观察来看:
- 在企业知识问答、流程文档检索、内部规范辅助这类场景里,
RAG仍然很重要 - 在代码仓库导航、局部文件定位这类强结构化场景里,
Grep、Glob、Read这类直接操作文件系统的方式,往往比向量检索更直接
不是 RAG 消失了,而是不同任务需要不同的增强方式。
我自己做 debug agent 时就踩过这个坑。我最初尝试过把代码仓库做索引,再让 Agent 通过语义检索去找崩溃相关代码,结果召回率很低。原因是很多调试任务依赖的不是"语义相似",而是术语、符号名、文件路径、调用链和历史改动,这些信息更适合用 grep、日志关键字和 git 记录去逼近。后来直接调用claude code sdk,准确率一下就上去了。
2.2 Tools:解决"模型不知道外部世界,也不能直接行动"
如果没有工具,LLM 很像一个"缸中之脑"。它能推理,但不知道现在几点,不知道今天发生了什么,也不能亲手执行动作。依然会给人"很蠢"的感觉。
所以我们给模型接工具:
- 要知道时间,就接时间工具
- 要知道现实世界信息,就接搜索或接口
- 要改文件、跑命令、查日志,就接代码与系统工具
这条路线持续在进化。早期很多系统靠正则匹配模型输出,再映射到某个函数;后来发展到更稳定的 function calling;再往后,为了把工具能力从某个模型服务或某个聊天客户端里解耦出来,又出现了像 MCP 这类协议层抽象。
工具一多,新的问题又来了:工具描述本身会占上下文,选择错误的工具也会带来执行成本。所以现在不少系统开始做按需加载,把工具和经验封装成 skills,避免一上来把所有能力都塞给模型。
2.3 Memory:解决"模型每次都像第一次见你"
LLM 天生不是持续有状态的。当前轮次的推理,不会自动继承上一次对话的内部状态。现实交互却不是这样,人类天然假设"前文还在"。
最简单的做法,就是把之前的对话一起放回上下文。这确实有效,而且现在依然是最常见的办法。但对话一长,窗口就会被迅速吃满,于是我们又不得不面对两个更细的问题:
- 哪些历史信息应该保留
- 哪些信息应该压缩、摘要或者外置存储
短期记忆解决连续对话,长期记忆解决跨任务偏好、固定约束和历史决策。到这里,会发现 Context Engineering 已经不是"多加几个字段",而是在做信息编排。
2.4 为什么只补上下文,很多 Agent 还是做不稳
上下文问题解决的是"模型看到什么",但它不直接解决下面这些问题:
- 它会不会误用高风险工具。典型的,我遇到openclaw把自己断网了,然后就再也联系不上了。
- 它改完代码以后如何验证
- 它失败了以后如何重试或回滚
- 它什么时候应该停下来汇报,而不是继续乱做,过早或者过晚都是不合适的
- 它怎样在长任务里留下可以追溯的过程记录
这些问题一出来,视角就必须继续外扩。我们研究的不再只是上下文,而是整个运行系统。这就是我理解的 Harness Engineering。
3. Harness Engineering:把模型放进一个可运行、可纠错、可追溯的系统
如何理解harness,我想到一个合适的例子。一个新入职的经验丰富的工程师,我们需要怎样才能保证它的产出呢?
- 给他配好的电脑
- 告诉他规则和权利
- 给它工作用的软件和运行环境
- 告诉它本领域的知识 同理,如果把一个能力不错的 Agent 看作新入职的工程师,那么 prompt 只是任务说明,context 只是你递给他的材料,而 harness 更像他所处的工作环境。
真正决定他能不能稳定交付的,通常不是"会不会写代码"这一件事(也就是我们默认模型的能力足够强了),而是下面这些工程条件是否存在:
- 有没有明确的目标、边界和停止条件
- 有没有合适的权限和运行环境
- 有没有足够的领域知识和工具入口
- 有没有日志、测试、页面反馈这类可观测信号
- 有没有文档、记录和版本系统让它在长任务里不至于失忆
所以,Harness Engineering 是在回答一个问题:如何把模型放进一个能持续做事的工程闭环环境里。
3.1 确定任务目标
很多 Agent 失控,不是因为它听不懂,而是因为系统没有给它清晰的"完成条件"和"禁止动作"。
比如在代码任务里,至少要让它知道:
- 什么叫完成
- 哪些目录、分支、环境不能碰
- 失败后是继续尝试、回退,还是停下来请求确认
- 什么时候必须先汇报,再进入下一步
这类约束看起来不像 AI 技术,实际上却直接决定产出质量。因为 Agent 一旦进入多步执行,没有约束的系统,天然更容易出现过度行动。这和对待人类程序原是一样的。
3.2 暴露隐性知识,而不是默认模型自己会懂
实践里,coding agent 最常见的跑偏原因,是它不知道团队那些"默认不言自明"的规则导致的。
比如"做一个上新的功能",在人类团队里可能隐含了很多前置约束:
- 哪些指标必须埋点
- 哪些埋点字段有历史兼容要求
- 哪些 UI 改动要同步改文案和活动配置
- 哪个目录下的脚本才是正式发布链路
在需求层面,我们人类程序员已经和前端营销、产品讨论过很多轮,我们听起来是非常的自然,但模型并不理解它的细节。我们可能提供了只言片语,但完全不充分。我们人类的沟通中,大量使用了语音、视觉等多模态的信息。这些信息的密度非常的高,如果没有清晰的呈现出来,agent的幻觉就会将其放大。
所以我更愿意把这件事理解成:不要只给 Agent 一个需求,而要补给它"一个新人第一周会被老员工口头交代的那些东西"。
3.3 给足够但不过载的工具
这不是说,工具越多越好,太多工具会带来两个副作用:
- 模型选择成本变高
- 工具说明本身开始挤占上下文
所以更合理的做法,往往不是"无限加工具",而是让工具可发现、可按需加载。 很多优秀的 coding agent 其实都不追求"为每个动作发明一个专用工具",而是优先提供一小组通用能力,例如:
ReadWriteGrepGlobBash
典型的如claude code , pi-mono。这套设计的好处,是看似给了很少的工具,但实际覆盖面很大。前四个让它高效操作代码和文件,Bash 则提供兜底能力。剩下的空间,交给具体项目里的 CLI、脚本和工作流。
隐含的逻辑是"我相信Agent足够的智能,可以找到自己合适的工具"。
3.4 提供可观测的反馈回路
没有反馈,Agent 就很难自我纠错。它做了一步动作,却不知道结果好坏,下一步只能继续猜。
在软件开发里,最典型的反馈源包括:
- 测试结果
lint和类型检查(很多coding agent工具会搭LSP)- 结构化日志
- 页面或接口的真实运行输出
- 调试信息、浏览器行为、硬件或串口回传
很多人觉得 Agent 输出质量差,第一反应是继续改 prompt尝试。可如果系统根本没有把这些反馈暴露出来,再好的 prompt 也无法替代观测能力。一个不会看结果的 Agent,很难进入稳定迭代。
从另一个层面说,这也是某些岗位的壁垒所在。越是依赖真实世界给予反馈的,越晚被替代。比如嵌入式开发,需要通过调试器等将信号接回到agent系统。反之则越快被替代,今年已经开始出现前端部门被整锅端掉了。
3.5 提供渐进式披露的记录系统
上下文窗口很宝贵,但长程任务天然需要大量记录。人类做项目时也不是把全部细节背在脑子里,而是把信息外化到文档、代码、日志和版本历史里,需要时再检索回来。没见过做项目要先背下整个需求的吧。
Agent 也一样。好的记录系统,不是把百科全书塞进 AGENTS.md,而是给它一张地图,再把细节拆到真正可维护的位置:
AGENTS.md负责告诉它规则、入口和知识分布docs/负责沉淀领域文档、流程说明、排障记录git负责保存每一步代码变化和提交语义
这样做有两个直接好处:
- 上下文不需要永久背着所有细节
- 需要追溯时,可以沿着文档和版本历史反查
从这个角度看,git 本身就是很适合 Agent 的外部记忆。它天然和代码关联,又鼓励小步迭代,检索成本也低。
这块经验来自OpenAI 在 2026 年 2 月 11 日发布的文章《工程技术:在智能体优先的世界中利用 Codex》,他们后来不再把 AGENTS.md 当百科全书,而是把它当作内容目录,真正的知识沉淀在结构化的 docs/ 里。这个判断和我自己的实践是一致的:长任务需要的是可检索的记录系统,而不是一段越来越长的总提示词。
我在做一个语音agent vixio 工程时,对"记录系统"还有一个更强的感受:如果不强制 Agent 把关键决策写下来,长任务一定会越来越漂。
我的做法是:
- 每次开始实现前,先要求 Agent 完成设计并存到文档里
- 后续实现一旦有更新,必须同步更新这份设计文档
- 后面遇到关联任务时,要求 Agent 先回看并引用这份文档,再继续实现
回想起来,这件事看起来像文档习惯,实际上是 harness 的一部分。因为它解决的不是"当前回答得好不好",而是"多轮、多阶段任务里,Agent 能不能保留稳定的项目记忆"。
这里我越来越认同一个判断:长期任务里的记忆,不能只寄希望于上下文窗口自动维持,而要外置到文档、git、任务记录这些系统里。窗口里放的是当前阶段最相关的片段,真正的长期记忆应该在窗口外有可检索的落点。
4. 回想我在做 Debug Agent 时的经验
4.1 第一版:只有 prompt、问题描述、日志和仓库
一般解决一个BUG,都是如下的步骤,给出任务要求:
解决这个崩溃问题。
然后补上三类材料:
- 问题描述
- 崩溃日志
- 代码仓库
从"信息已经不少"的角度看,这似乎已经够了。但实际效果很差。Agent 会执行很久,读很多文件,尝试很多方向,却很难稳定定位到真正相关的代码段。它不是完全不能做事,而是一直在低效搜索。 最主要的问题在于:不稳定。能不能找到问题点所在,完全看运气。最典型的就是,找崩溃问题,找到memory 空指针,然后就围绕着这个空指针一直去自我证明。实际上,这里不会空指针,只是写法没有那么规范,导致它容易误判。
这时候如果只从 Prompt Engineering 的角度思考,很容易得出一个错误结论:是不是 prompt 还不够细?
4.2 我当时的误判:先去做代码 RAG
我第一反应其实不是做 harness,而是继续补 context。我试过把代码做索引,让 Agent 通过语义检索找与崩溃相关的代码。
这一步没有带来预期收益,核心问题是召回率很低。
调试类任务和知识问答不太一样。很多关键线索并不体现为自然语言语义相近,而体现为:
- 崩溃堆栈里的特定符号
- 日志中的关键字
- 仓库里的历史术语
- 某次改动引入的调用链变化
也就是说,这个问题表面上像"信息不够",本质上却是"信息组织方式不对"。代码语义检索在这里不是完全没用,但不是最有效的入口。
4.3 真正起作用的改动:给它一个崩溃分析技能
后面效果明显改善,是因为我不再继续堆 prompt,而是补了一套更接近工程经验的运行支架。
我给 Agent 增加了一个"崩溃分析技能",里面不是抽象原则,而是非常具体的工作方法:
- 遇到这类崩溃,先搜哪些关键字
- 应该优先调用电脑上的哪个分析工具
- 可以参考一份过去解决过的类似问题分析
- 遇到术语不理解时,要通过
git记录理解术语含义,并反查对应代码段
这次改动以后,执行效果就明显好了很多。因为 Agent 不再是在整个仓库里盲目游走,而是开始沿着一条更像资深工程师排障的路径推进。
这件事对我最大的提醒是:很多时候,Agent 缺的不是"再解释一遍任务",而是"给它一条可执行的调查路径"。
4.4 这个案例里,三层分别发挥了什么作用
如果用本文的三层框架回看这次调试过程,大概可以这样归因:
Prompt负责定义目标,比如"解决这个崩溃问题"Context负责提供材料,比如日志、代码仓库、过去案例和关键字Harness负责把排查流程固定下来,让它知道先做什么、用什么工具、如何通过git和记忆系统持续逼近答案
实际上,它能成功运行分析工具,也是我实现准备好了运行环境。 也正因为这样,我现在对很多 Agent 失败场景的第一反应,已经不是"把 prompt 再写长一点",而是先问一句:它到底缺的是目标表达、任务材料,还是工程支架?
总结:Agent 时代,我们的重心在"Harness"
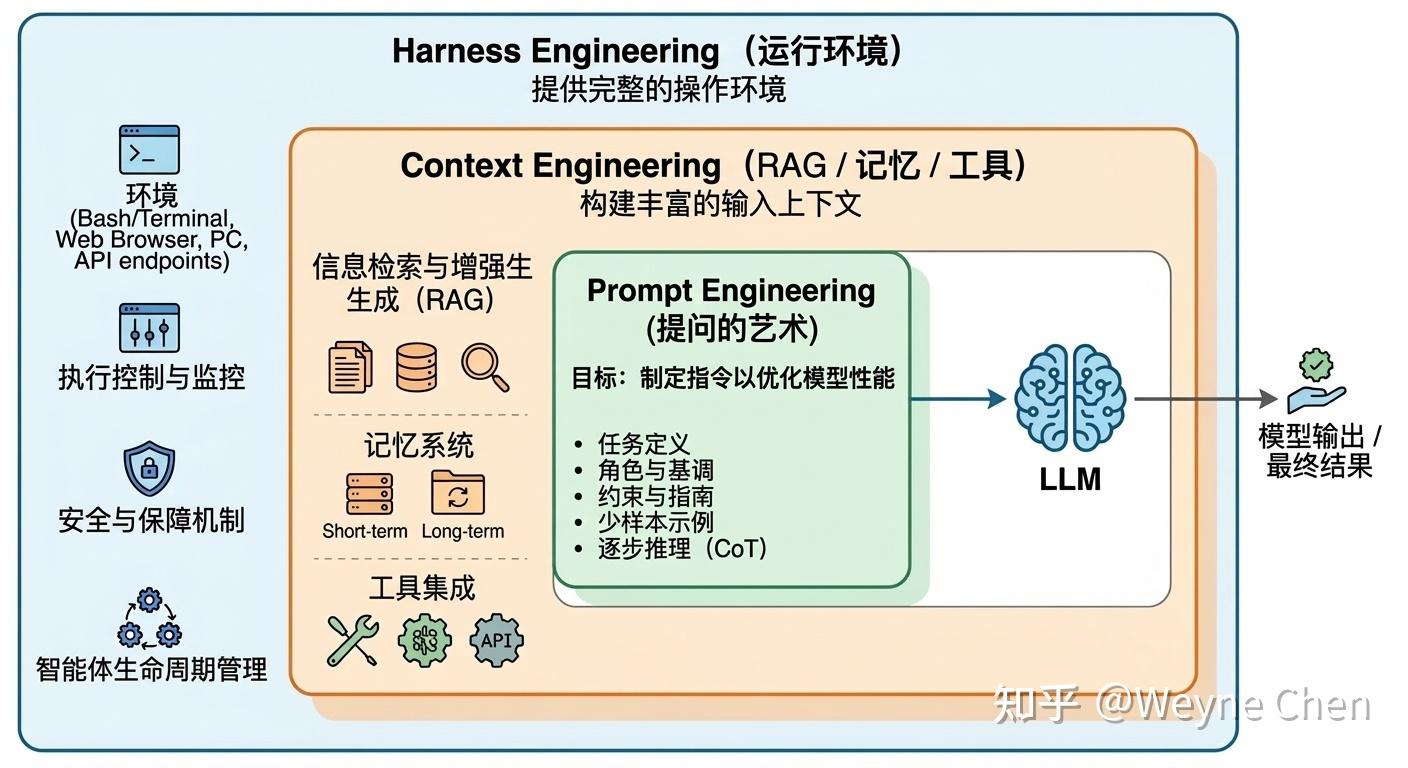
Prompt Engineering 解决的是如何把任务说明白,Context Engineering 解决的是如何把关键信息摆到模型眼前,Harness Engineering 解决的是如何让模型在真实环境里稳定做事。
三者并不是谁取代谁,而是抽象层次一层层向外扩展。任务越接近真实生产,后两者的重要性就越高。
模型能力越来越强,它所需要更多可能是"给他一个自由发挥的舞台",人类需要来协助它搭建舞台。而不是反过来,人类强烈的干预它的行为,却不给予它帮助。
如果你用了顶级模型,但 vibe coding 效果不好,大概率不是模型不够聪明,而是还没有给模型提供足够好的运行环境,从而充分发挥它的能力。