前言
本文是阅读论文《Conformer: Convolution-augmented Transformer for Speech Recognition》1 的笔记。Transformer 的自注意力能建模长程依赖,但对局部结构(如频谱的连续帧)建模能力一般。CNN 擅长局部建模,但感受野有限,长程依赖要靠堆叠很多层。所以 Conformer(Convolution + Transformer) 把两者结合,用 Transformer 做全局建模,用卷积做局部建模,从而更适配语音信号的时间局部性和长程依赖。
下面从卷积下采样层、多头自注意力模块、卷积模块、前馈模块和 Conformer 模块来介绍模型结构。
一、卷积下采样层
图 1 是 Conformer 的总体结构,左边是总的处理过程,语音特征(如 Fbank)每 10ms 一帧,经过下采样,变成 40ms 一帧。
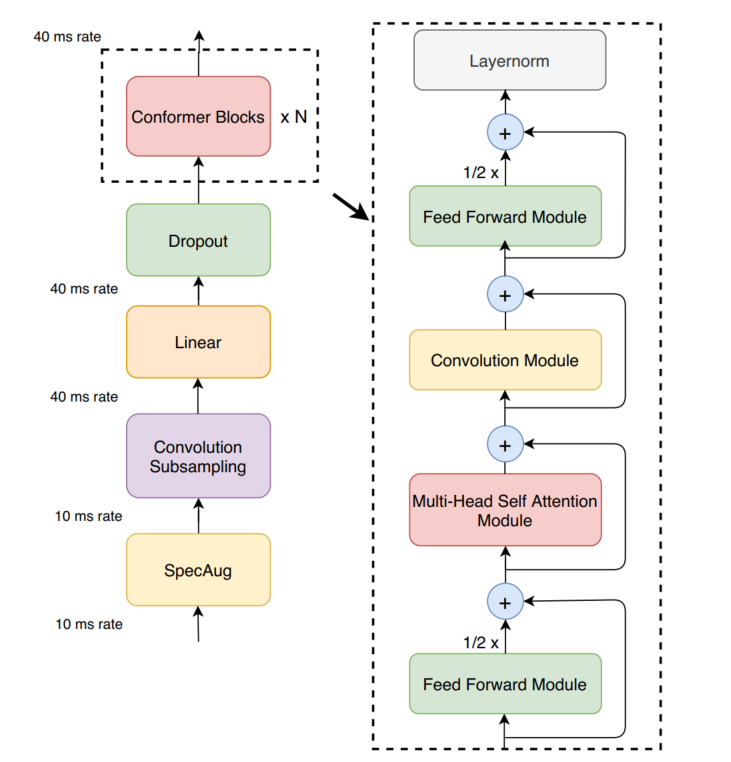
图 1 Conformer 结构图
为什么要做下采样?一段 10 秒的语音有 1000 帧,自注意力计算复杂度 O ( T 2 d ) O(T^2 d) O(T2d), 1000 帧就是 100 万量级的计算量,显存压力巨大。语音 10ms 级别信息冗余较高,普通人感知不到 10ms 的变化。通过 1 4 \frac{1}{4} 41 下采样,每帧看到约 40ms 的信息,仍然保留了足够的声学细节。
shell
输入: (Batch, 1, Time, Freq) # 单通道"图像"
↓
Conv2d(kernel=3×3, stride=2) # 时间 & 频率都做局部建模 + 下采样
↓
Conv2d(kernel=3×3, stride=2)
↓
输出: (Batch, C, T/4, Freq')这里用的是二维卷积(Conv2d),将语音特征当做图像来处理,时间轴的信息结合相邻频带之间的局部相关性(如共振峰、谐波结构),一同建模时间和频率的局部结构。
二、多头自注意力模块

图 2 多头自注意力模块
如图 2 所示,Conformer 采用 Pre-LN(Pre Layer Normalization,预层归一化),而原始 Transformer 采用 Post-LN(Post Layer Normalization,后层归一化)。
Post-LN 是在 SA(自注意力)模块和残差连接之后做 LayerNorm \text{LayerNorm} LayerNorm,即
y = LN ( x + SA ( x ) ) (1) \mathbf{y} = \text{LN} \left(\mathbf{x} + \text{SA}(\mathbf{x}) \right) \tag{1} y=LN(x+SA(x))(1)
设 h = x + SA ( x ) \mathbf{h} = \mathbf{x} + \text{SA}(\mathbf{x}) h=x+SA(x),梯度
∂ y ∂ x = ∂ LN ( h ) ∂ h ( I + ∂ SA ( x ) ∂ x ) (2) \frac{\partial{\mathbf{y}}}{\partial\mathbf{x}} = \frac{\partial\text{LN}(\mathbf{h})}{\partial\mathbf{h} } \left(\mathbf{I} + \frac{\partial\text{SA}(\mathbf{x})}{\partial\mathbf{x}} \right) \tag{2} ∂x∂y=∂h∂LN(h)(I+∂x∂SA(x))(2)
如果层数叠多了, ∂ LN ( h ) ∂ h \frac{\partial \text{LN} (\mathbf{h})}{\partial\mathbf{h}} ∂h∂LN(h) 多次回传容易造成梯度消失,训练不稳定。
而 Pre-LN 是先做 LayerNorm \text{LayerNorm} LayerNorm, 再 SA,之后再残差连接,
y = x + SA ( LN ( x ) ) (3) \mathbf{y} = \mathbf{x} + \text{SA}(\mathbf{\text{LN}(x)}) \tag{3} y=x+SA(LN(x))(3)
梯度
∂ y ∂ x = I + ∂ SA ( LN ( x ) ) ∂ x (4) \frac{\partial{\mathbf{y}}}{\partial\mathbf{x}} = \mathbf{I} + \frac{\partial \text{SA}(\mathbf{\text{LN}(x)}) }{\partial\mathbf{x}} \tag{4} ∂x∂y=I+∂x∂SA(LN(x))(4)
恒等路径一直存在,层数叠多,梯度不会消失。所以 Pre-LN 在训练层数多的大模型时更加稳定一些。
个人经验来说,如果没有梯度消失,归一化后的数据更易拟合,所以对于浅层模型(小于 12 层),有时候 Post-LN 性能会更好。
如图 2 所示,多头注意力机制(MHSA)用的是相对位置编码。语音是强时序信号,模型真正需要的是「帧与帧之间的相对距离 / 时序关系」,而非「这是第几个绝对位置」,相对位置编码能让注意力解耦内容与位置、支持任意长序列外推、保持时序平移不变性、和卷积模块天然兼容。
三、卷积模块

图 3 卷积模块
卷积模块的设计逻辑是 轻量、拟合局部特征、训练稳定。
拟合局部特征的轻量卷积,首选深度可分离一维卷积(DSTCN),如图 3 所示,从 1D-Depthwise-Conv 到 Pointwise-Conv 就是用 Swish 激活替换了 Relu 的 DSTCN。深度可分离卷积相比普通一维卷积,参数量算力大幅减少,且性能降低很少。如公式(5), σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 Sigmoid \text{Sigmoid} Sigmoid 函数。Swish 相较 Relu 更加平滑,在更深的模型中表现较好2。
Swish ( x ) = x ⋅ σ ( x ) (5) \text{Swish}(\mathbf{x}) = \mathbf{x} \cdot \sigma(\mathbf{x}) \tag{5} Swish(x)=x⋅σ(x)(5)
Conformer 全局架构全都是 Pre-LN,FFN、MHSA、Conv 全部遵循 LN → 子模块 → Add,保证梯度恒等路径、深层不崩。
LN 后面接了 Pointwise-Conv + Glu 激活。Pointwise-Conv 是 1 × 1 1×1 1×1 卷积,沿通道维度将输入拆成两半,比如输入 x ∈ R T × C \mathbf{x} \in \mathbb{R}^{T \times C} x∈RT×C,经过 1 × 1 1×1 1×1 卷积扩张 2 倍,得到 x 1 , x 2 ∈ R T × C \mathbf{x_1}, \mathbf{x_2} \in \mathbb{R}^{T \times C} x1,x2∈RT×C。Glu 激活如式(6)所示
GLU ( x 1 , x 2 ) = x 1 ⊙ σ ( x 2 ) (6) \text{GLU}(\mathbf{x_1}, \mathbf{x_2}) = \mathbf{x_1} \odot \sigma(\mathbf{x_2}) \tag{6} GLU(x1,x2)=x1⊙σ(x2)(6)
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 Sigmoid \text{Sigmoid} Sigmoid 函数, ⊙ \odot ⊙ 是哈达玛积(逐元素相乘)。作用是门控线性单元对语音冗余帧的筛选。
所以总的来说,卷积模块是语音时序专用的门控深度可分离卷积。
四、前馈模块

图 4 前馈模块
前馈模块(FFN)还是经典的 2 层线性层,第 1 层将节点数扩大 4 倍,第 2 层将其投影回模型维度。激活函数用 Swish,并且使用了和MHSA、Conv 一样的 LN → 子模块 → Add 结构。
五、Conformer 模块
如图 1 所示,Conformer 与 Transformer 不同之处在于,FFN 不是单独一层,而是设计了 "马卡龙结构", 将 FFN 拆分成了两个独立的子模块,分别放在 Block 的开头和结尾。计算过程如(7)所示。
x ~ i = x i + 1 2 FFN ( x i ) x i ′ = x ~ i + MHSA ( x ~ i ) x i ′ ′ = x i ′ + Conv ( x i ′ ) y i = Layernorm ( x i ′ ′ + 1 2 FFN ( x i ′ ′ ) ) (7) \begin{align} \tilde{x}_i &= x_i + \frac{1}{2}\text{FFN}(x_i) \\ x'_i &= \tilde{x}_i + \text{MHSA}(\tilde{x}_i) \\ x''_i &= x'_i + \text{Conv}(x'_i) \\ y_i &= \text{Layernorm}\left(x''_i + \frac{1}{2}\text{FFN}(x''_i)\right) \end{align} \tag{7} x~ixi′xi′′yi=xi+21FFN(xi)=x~i+MHSA(x~i)=xi′+Conv(xi′)=Layernorm(xi′′+21FFN(xi′′))(7)
作者将 FFN 的系数 1 2 \frac{1}{2} 21 称为半步前馈层,也对单个 FFN 层和全步前馈层做了实验,证明马卡龙半步前馈层效果最好。
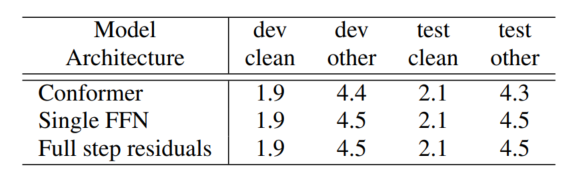
表1 马卡龙前馈模块的消融实验
总结
Conformer 是 2020 年提出,专为 ASR 量身设计的混合编码器架构,核心思想是融合 Transformer 的全局上下文建模能力与 CNN 的局部时序特征提取能力,解决了纯 Transformer 局部声学建模低效、纯 CNN 长距离依赖建模不足的双重痛点,是端到端语音识别的主流模型。
参考文献
1 Gulati A , Qin J , Chiu C C ,et al.Conformer: Convolution-augmented Transformer for Speech RecognitionJ. 2020.DOI:10.48550/arXiv.2005.08100.
2 Ramachandran P , Zoph B , Le Q V .Swish: a Self-Gated Activation FunctionJ. 2017.DOI:10.48550/arXiv.1710.05941.