想让开源语音识别扛住高并发?Qwen3-ASR + vLLM 是最优解!本文不讲虚的,直接给部署脚本、优化参数与压测数据,看完就能搭建低延迟、高可用的 ASR 服务,大幅提升业务承载能力。
Qwen3-ASR 系列包括 Qwen3-ASR-1.7B 和 Qwen3-ASR-0.6B,支持 52 种语言和方言的语言识别与语音识别(ASR)。两者均利用大规模语音训练数据以及其基础模型 Qwen3-Omni 强大的音频理解能力。实验表明,1.7B 版本在开源 ASR 模型中达到业界领先水平,并可与最强的商业闭源 API 相媲美。主要特性如下:

一,快速开始
1,安装conda 环境,并安装依赖
如果不会安装conda 环境的话,可以参考这一篇:
环境冲突?看完少走半年弯路,Conda 一行命令彻底解决。
1.1,安装conda环境。
bash
conda create -n qwen3-asr python=3.12 -y
conda activate qwen3-asr1.2,运行以下命令以最小化安装并启用 transformers 后端支持:
bash
pip install -U qwen-asr2,下载模型
2.1,下载模型
默认下载:这种下载的路径会默认下载到:
/home/admin1/.cache/modelscope/hub/models/
bash
#下载之前先安装ModelScope
pip install modelscope
#下载完整模型库
modelscope download --model Qwen/Qwen3-ASR-1.7B如果我们要下载到指定目录的话,就要指定目录
bash
#下载示例
modelscope download --model Qwen/Qwen3-ASR-1.7B README.md --local_dir ./dir
#下载模型到这个目录
modelscope download --model Qwen/Qwen3-ASR-1.7B --local_dir /home/aidata/qwen3-asr/Qwen3-ASR-1.7B 3,启动模型,简单验证
1,启动验证,本地文件和远程文件都可以。
bash
import torch
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.from_pretrained(
"/home/aidata/qwen3-asr/Qwen3-ASR-1.7B",
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
max_inference_batch_size=32, # Batch size limit for inference. -1 means unlimited. Smaller values can help avoid OOM.
max_new_tokens=256, # Maximum number of tokens to generate. Set a larger value for long audio input.
)
results = model.transcribe(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
language=None, # set "English" to force the language
)
print(results[0].language)
print(results[0].text)验证正常即可!
二,VLLM 部署Qwen3-ASR
1,dokcer 镜像
在进行vllm环境安装的时候,出现了一些依赖问题,这里就直接使用预置好的docker 镜像。
1,首先拉取镜像,如果无法顺利访问 Docker Hub,可以使用镜像加速器来加快镜像拉取速度。或者想其他办法。
bash
docker run --gpus all --name qwen3-asr \
-v /var/run/docker.sock:/var/run/docker.sock -p 6007:80 \
--mount type=bind,source=/home/aidata/shahsen/qwen3-asr/Qwen3-ASR-1.7B,target=/data/shared/Qwen3-ASR \
--shm-size=4gb \
-it qwenllm/qwen3-asr:latest注意:docker: Error response from daemon: could not select device driver "" with capabilities: \[gpu].如果出现报错是 NVIDIA Docker 运行时环境。
bash
#下载中科大NVIDIA源配置
sudo curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
#替换源地址(确保用中科大)
sudo sed -i 's#nvidia.github.io#mirrors.ustc.edu.cn#g' /etc/yum.repos.d/nvidia-container-toolkit.repo
#刷新缓存
sudo yum clean all && sudo yum makecache
#安装依赖+主包
yum install -y libnvidia-container1 libnvidia-container-tools nvidia-container-toolkit
#配置NVIDIA runtime
sudo nvidia-ctk runtime configure --runtime=docker
#编辑daemon.json(合并数据目录+GPU)
sudo vi /etc/docker/daemon.json
{
"data-root": "/mnt/data1/docker",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime":"nvidia" # 新增:默认使用nvidia运行时,适配CUDA 12.4
}
#重启验证
sudo systemctl daemon-reload
sudo systemctl restart docker
#检查是否有nvidia runtime
docker info | grep -i nvidia
#测试GPU
sudo docker run --rm --gpus all nvidia/cuda:11.8.0-base-centos8 nvidia-smi执行命令后,你将进入容器的 bash shell。你的本地工作目录(将/path/to/your/workspace替换为实际路径)将挂载到容器内的 /data/shared/Qwen3-ASR 路径下。主机的 8000 端口被映射到容器的 80 端口,因此你可以通过 http://:8000 访问容器内运行的服务。注意,容器内的服务必须绑定到 0.0.0.0(而非 127.0.0.1),端口转发才能生效。
如果你退出了容器,可以再次启动并重新进入:
bash
docker start qwen3-asr
docker exec -it qwen3-asr bash若要彻底删除容器,请运行:
bash
rm
-f
-asr2,进入dokcer 镜像启动vllm环境
2.1 启动vllm服务
注意:gpu-memory-utilization 根据自己的GPU来进行设置,Qwen3-ASR-1.7B 大概要4个G左右。
bash
启动 Qwen3-ASR 语音识别服务 API 服务器
核心功能:加载指定路径的模型,启动 HTTP 服务提供 ASR 接口
python -m qwen_asr.serve.api_server \
/data/shared/Qwen3-ASR \ # 必选:Qwen3-ASR 模型的本地存放路径
--gpu-memory-utilization 0.4 \ # 可选:GPU 显存利用率上限(0.4 表示占用 40% 显存)
--host 0.0.0.0 \ # 可选:服务绑定的 IP 地址(0.0.0.0 允许外部网络访问)
--max_model_len=2048 \ # 可选:模型最大处理序列长度(2048 适配长音频识别)
--port 80 # 可选:服务监听的端口(80 是 HTTP 默认端口)
# model_len = 2048 需要7个G
qwen-asr-serve /data/shared/Qwen3-ASR --gpu-memory-utilization 0.13 --host 0.0.0.0 --max_model_len=2048 --port 80
# 在后台运行
nohup qwen-asr-serve /data/shared/Qwen3-ASR --gpu-memory-utilization 0.13 --host 0.0.0.0 --max_model_len=2048 --port 80 > qwen-asr.log 2>&1 &3,服务启动后进行测试
3.1 使用url 进行访问测试
bash
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data =
{
"messages": [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio_url": {
"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav"
}
}
]
}
]
}4,PostMan进行访问传递From-data
1,URL 和 Header
bash
#URL
http://192.168.1.1:6007/v1/audio/transcriptions
#head:
Content-Type: application/json
Authorization: Bearer EMPTY2,body 中使用from-data
bash
#模型在镜像中的位置
model: /data/shared/Qwen3-ASR
#返回类型
response_format:json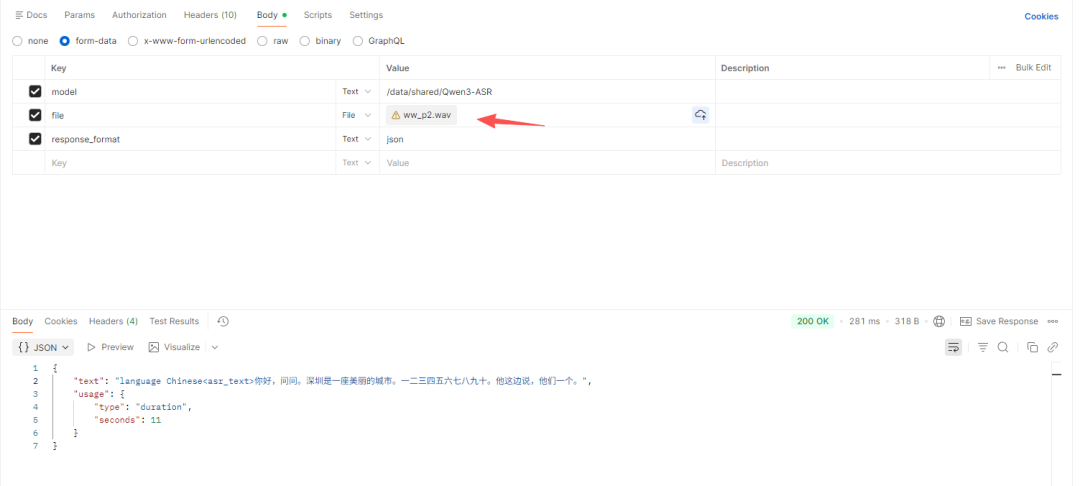
可以看见20多个字,只要300毫秒就识别成功。
三,测试结果
10秒的音频
4090显卡 sensevoice 在134/ms
T4显卡 qwen3-asr 在669/ms
异步请求 测试并发
100并发:1385/ms
300并发:最大4215/ms,最小2066/m,居中大概是 3000/ms左右。
理论4090是T4的4倍 所以应该能做到167毫秒
4090显卡
50并发:

100并发:

具体可进行实测,安装,有问题可沟通交流。